

生成AI

最終更新日:2025/01/08
 マルチモーダルとは?
マルチモーダルとは?
ChatGPTを筆頭に生成AIが浸透する中で、マルチモーダルAIにも注目が集まっています。音声や画像、動画といった異なる情報を総合的に処理できるマルチモーダルは、生成AIの進化・発展を大きく後押ししています。
本記事では、マルチモーダルの基本情報やメリット、マルチモーダルAIでできること、代表的な生成AIなどを解説します。分野別のマルチモーダルAI活用や企業の導入事例についても説明しますので、自社のAI活用に向けてぜひお役立てください。
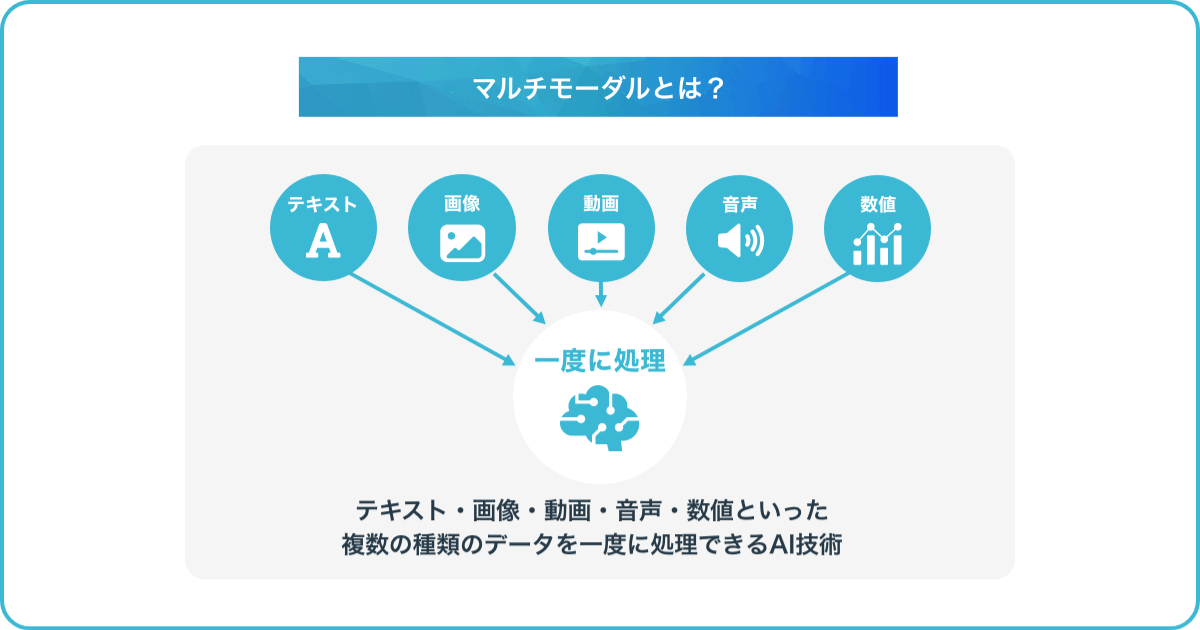
マルチモーダル(Multimodal)とは、直訳すると「複数の形式・手段」という意味です。マルチモーダルな人工知能は「マルチモーダルAI(Multimodal Artitificial Intelligence)」と言い、テキスト・画像・動画・音声・数値といった複数の種類のデータを一度に処理できるAI技術を指します。
なお、複数のモダリティから学習することを、「マルチモーダル学習(Multimodal Learning)」といいます。
マルチモーダルの対照は「シングルモーダル」で、「単一の形式・手段」という意味です。シングルモーダルは、各データ種別を個別に処理します。人間が視覚だけ、あるいは聴覚だけで状況や情報を分析しようとする状態に例えられます。
一方、マルチモーダルでは異なるデータ種別を総合的に理解し、文字と画像、文字と音声といった複数のデータ種別を同時に扱うことが可能です。
シングルモーダルは単純でシンプルなタスク処理に向いていて、複雑な関係性を伴う情報の処理にはマルチモーダルが適しています。
マルチモーダルAIは、LLM(大規模言語モデル)の進化・発展を大きく後押ししました。従来のLLMへの入力はテキストが中心でしたが、マルチモーダルAIでは文字の他にも、画像や動画、音声といった複数のデータを同時入力できるため、より高精度なタスク処理が可能です。
また、異なるデータ種別の変換にも対応しています。近年ではディープラーニング技術も飛躍的な発展を遂げており、より人間に近い感覚で対応できるマルチモーダルAIの注目度が高まっています。
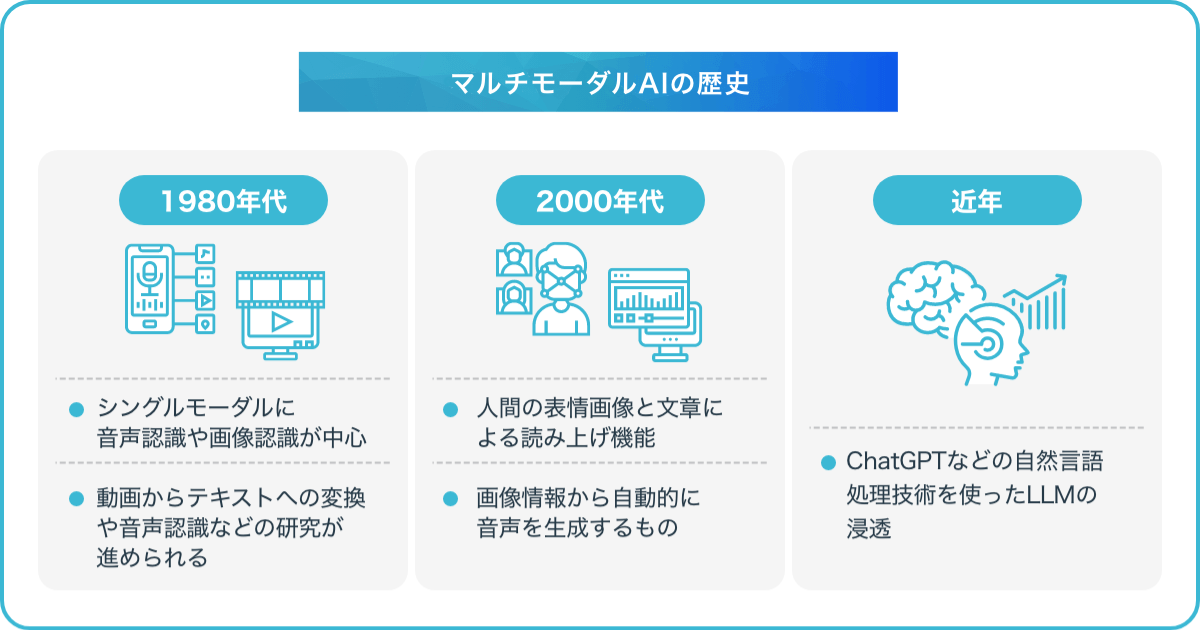
マルチモーダルAIにおける重要な学習方法である「マルチモーダル学習」の研究は、1980年代に遡ります。当初は、シングルモーダルに音声認識や画像認識が中心でしたが、複数のデータ形式を統合することの重要性が次第に認識されるようになりました。これを受けて、動画からテキストへの変換や音声認識などの研究が進められてきました。
2000年代に入り、ディープラーニングが広まると、マルチモーダルAIの研究が急速に発展していきます。2013年には、人間の表情画像と文章による読み上げ機能や、画像情報から自動的に音声を生成するものも登場しています。
そして近年、ChatGPTなどの自然言語処理技術を使ったLLMの浸透により、マルチモーダル技術の進歩がより一層促進されています。
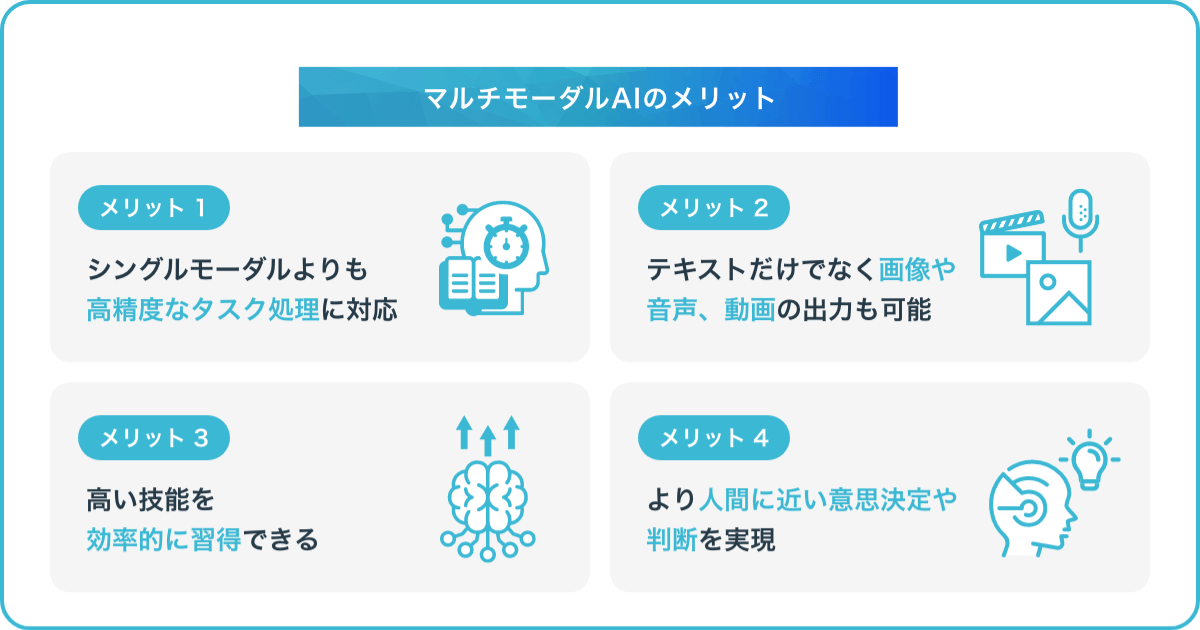
マルチモーダルAIのメリットをまとめると、以下のような点が挙げられます。
マルチモーダルAIでは複数のデータ種別を同時処理できるため、豊富なデータを使ったディープラーニングによる学習が効率的に進み、高精度なタスク処理が期待できます。また、学習そのものにおける効率性もアップしています。
また、複数の情報を扱えるマルチモーダルAIは、人間が五感を使って使って判断・認知する能力に近い性能を発揮できます。すでに人間との自然な会話を実現しているLLMモデルもありますが、マルチモーダルAIによってさらなる進化が実現すると予測されます。
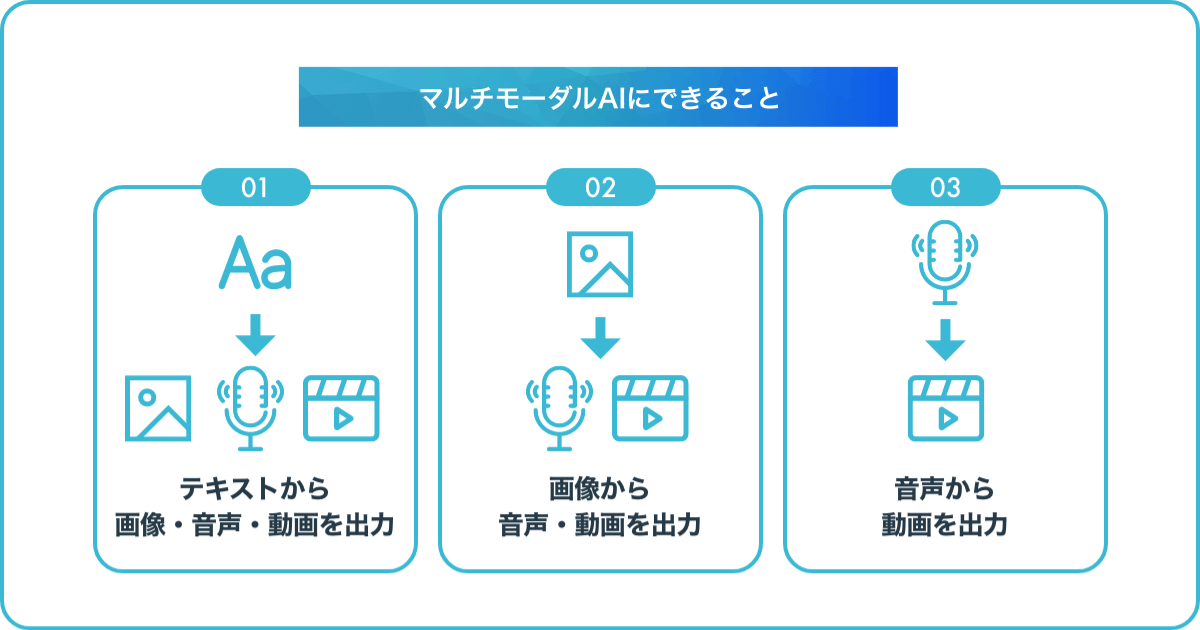
マルチモーダルAIを使ってできることは多数あります。ここでは、以下の代表的な機能3つについて解説します。
マルチモーダルでは、テキストから画像や音声、動画といったデータを出力可能です。例えば、テキストから画像への変換や画像データの分析、音声のテキスト出力などです。
最近では、テキストから動画を生成できるAI編集ツールも登場しています。また、複数のデータ種別を組み合わせて、多言語翻訳やデータ分析といった用途でも活用できます。
画像と音声・動画との間でスムーズなデータ変換が可能です。例えば、テキストで作成されたスクリプトと音声を組み合わせて、まるで人間が話しているかのような自然な音声を出力できます。
また、静止画像から動画の生成も可能です。現時点では、短時間の動画を生成できるAI動画生成ツールがメインですが、滑らかな動きを表現できる性能を持ち合わせており、広告などでの活用が見込まれています。
音声と動画を統合して解析することで、より複雑な状況や行動の認識が実現します。具体的な用途としては、防犯カメラにマルチモーダルAIを搭載し、音と映像の両方で情報を解析する方法などです。
マルチモーダルAIにより音声を合わせて解析することで、従来の映像だけの監視カメラに比べて的確な状況把握とトラブル回避につながります。
マルチモーダルモデルを採用した生成AIも次々と登場しています。ここでは、代表的なマルチモーダルAIとして、以下の3つを紹介します。
「ChatGPT-4o」は、OpenAI社が手がける「ChatGPT」の最新版として、2024年6月に発表されました。「ChatGPT」は、テキストによる対話型AIとして有名ですが、「ChatGPT-4o」の一つ前のモデル「GPT-4」の段階で画像や動画などの視覚情報の理解や、スピーディで高精度な回答を実現しています。
最新モデルの「GPT-4o」の「o」は「Omnimodel(オムニモデル)」のことで、テキストや音声、画像、映像といった複数の異なるデータをシームレスに同時処理できます。従来までのモデルに比べて、特に音声認識や画像生成における進化がめざましく、人間のような流暢かつ最適な応答速度で音声会話が成立します。
また、「GPT-4o」では画像生成やOCR(画像読み取り)の技術も向上しています。テキストから高品質な画像を生成でき、デザインやコンテンツ制作で役立ちます。
参考:GPT-4oとは?ChatGPT最新AIモデルGPT-4oの使い方や料金を詳しく解説
「Gemini」はGoogleが開発したAIです。Google検索と連携し、インターネット上の情報検索や参照ソースの提示が可能です。また、マルチモーダルを用いた事前学習とファインチューニングにより、複数種類のデータ入力をシームレスに処理できます。
文章や画像の高精度な解析のほか、プログラミングコード生成や画像の解説、音声入力、画像生成など幅広いタスクに対応可能です。
「Gemini」には、「Nano・Pro・Ultra」の3つのモデルがあり、最高性能を備えた「Ultra」では人間の専門家レベルと同等のスコアを打ち出しています。
参考:Gemini(ジェミニ)とは?料金・使い方・活用事例、アプリ最新情報を紹介
「Bing」はMicrosoftが開発した検索エンジンです。2023年7月からマルチモーダル対応がスタートし、2024年4月にはテキストと画像に加えて、動画や音声による検索も可能になっています。
チャット形式での入力で、画像の認識や識別など幅広いタスクに対応しています。例えば、写真に映る犬の犬種やユーザーの現在地に基づく天気予報の表示などが可能です。
「Bing」では、回答モードの選択が可能で、「独創性」「バランス」「厳密」という3種類から選べます。独創性モードは、オリジナルの詩や小説など創造的な回答を実現しています。
参考:Bing AIとは?新機能やCopilot(旧Bing AIチャット)の使い方・生成のコツを丁寧に解説!
マルチモーダルAIは高精度な情報処理が可能で、すでにさまざまなシーンで採用されています。ここでは、領域別にマルチモーダルAIの活用例として、以下の6つを紹介します。
自動車の分野において、自動運転技術はマルチモーダルAIの代表的な活用例の一つです。人間が自動車を運転する際には、五感を駆使して周囲の車や歩行者、信号などを同時進行的に認識し、危険予測やスピード調整を行います。
マルチモーダルAIでは、ドライブレコーダーや交通カメラの映像、マイク音声、GPSといった複数の情報を統合することが可能です。そして、人間に近いレベルで、刻一刻と変わる道路状況を的確に把握し、自動運転の安全性の向上と確保に貢献します。
海外のみならず国内でも、すでにマルチモーダルAIを搭載した自動運転車の導入や活用がスタートしています。
医療の現場においても、マルチモーダルAIの研究・開発が進められています。医療現場は、超音波検査やMRI、X線画像といった画像データのほか、心音データ、問診票、カルテといった様々な情報を扱います。
マルチモーダルAIを使って複数のデータを組み合わせることで、診断の精度向上を支援します。また、過去の膨大なデータとの照合も効率的に実行でき、病気や疾患の早期発見、早期予測につながります。
さらに、検査スピードの向上や早期治療の提供、病院における待ち時間の削減といった効果も期待できるでしょう。遠隔診断の精度が高まり、過疎地域の高齢者に対する定期診断や治療機会の提供も促すことができます。
マルチモーダルAIは、防犯シーンでも活用されています。ビルのセキュリティシステムや防犯カメラに搭載することで、映像と音声データを照らし合わせて分析でき、犯罪の回避や早期発見に役立ちます。
マルチモーダルAIによって、複数のデータを解析することで不審者の侵入防止や危険察知を促せるため、セキュリティレベルの向上が期待できます。監視すべき範囲が大きい大規模ショッピングセンターなど、人手が必要なシーンでは、マルチモーダルAIによる警備の強化や人員負担の軽減につながります。
また、オフィスや高層マンションでの生体認証は、本人の指紋や静脈などを使うセキュリティシステムです。マルチモーダルAI搭載のシステムでは、静脈認証に顔認証など他の手段を組み合わせており、簡単な操作でより高精度な防犯対策が実現します。
スポーツ業界でも、試合時の情報収集や選手の体調管理、チーム戦略の立案といった様々な用途でマルチモーダルAIの活用が進められています。サッカーでは、空中映像やGPS、選手のウェアラブルセンサーやフィールド上のセンサーなど多様なデータを収集、分析し、チームや選手のマネジメントに役立てています。
また、対戦相手の様々な情報を簡単に集められるようになり、分析や検証から的確な戦略を練ることが可能になります。パーソナライズされた指導や健康維持のためのトレーニングマルチモーダルAIデバイスを使うことで、必要な情報を効率的に入手可能です。
製造工場などでは、製品や設備の異常検知システムにマルチモーダルAIが活用されています。従来までも異常検知はシステムを使って行われてきましたが、画像データのみで分析するケースが多く、トラブルや故障の発見が遅れる可能性もありました。
マルチモーダルAIにより、複数のデータを組み合わせて分析できるため、異常の早期発見につながります。予期せぬ不具合を未然に防げるようになり、結果的に生産性の向上やコスト削減にも寄与します。
現在、マルチモーダルAI搭載の産業用ロボットの研究・開発が進められています。異常検知や検品以外の工場作業から従業員のシフト管理まで、幅広いシーンでマルチモーダルAIの活躍が見込まれています。
教育分野では、学習者の理解や知識の定着促進にマルチモーダルAIが役立ちます。現在、テキストや画像、音声や動画など複数の情報を組み合わせた教育支援ツールや教材が開発されています。
また、オンライン講義で受講者の表情を解析する機能や、講師の説明をテキスト化して記録する機能などにもマルチモーダルAIが採用されています。
ここからは、実際にマルチモーダルAIを導入・活用している企業の事例として、以下の3つを紹介します。
NTTレゾナント社の「AI suite」は、テキストや画像、映像情報に加え、人間の知性や感性を踏まえた解析を行うマルチモーダルな感情分析AIです。APIサービスでは、対話型AIやマルチモーダルAIをはじめ、音声合成AIなど多くの機能を備えています。
例えば、オンライン会議でのリアルタイム分析ツール「オンライン会議センシング」や、AIとの会話を通して感情の可視化と会話の定量化が可能な「AIロールプレイング診断」などです。
参考:人間とAIがともに生きる世界へ「AI suite」 【NTTレゾナントより新サービスが登場】
Brilliant Labs社は2024年5月、ChatGPT-4o対応のマルチモーダルAIメガネ「Frame」をリリースしました。本体は約39gと軽量な丸メガネ型で、ディスプレイ・カメラ・マイク・Bluetooth無線を内蔵しています。
スマホアプリと接続することで、レンズを通したAI言語翻訳や要約、道案内やメッセージの表示、時刻や天気予報などの通知といった多彩な機能を利用できます。
参考:ChatGPT-4o対応、マルチモーダルAIメガネ「Frame」が全世界で発売開始
「AimeFace」は、株式会社アイメソフト・ジャパンが手がける顔認証システムです。マルチモーダルAIをベースにした顔登録機能では、音声によるリアルタイムでの顔登録が可能です。
顔検出や顔認識、eKYC(オンライン本人確認)といった機能に対応しており、顔認識の精度は約99%と高い数値を打ち出しています。
実際の導入場所にはホテルの無人チェックイン機などで利用されてます。また、オフィスの入館管理やレジ決済などでは「AimeFace」搭載のバーチャルAI受付システムの活用が見込まれています。
製品ページ:マルチモーダルAI顔認証システム「AimeFace」
「顔パス勤怠&顔パスストレスチェッカー」は、株式会社TIGEREYEの顔認証システムで、従業員の勤怠打刻と健康管理を同時に行うソリューションです。
顔認証による勤怠打刻と同時に感情を読み取り、ウェルビーイング向上を実現します。
現場の安全を確保する建設業や、衛生管理が重要となる工場・製造業において最適です。また、様々な連携サービスと組み合わせることで、さらなる業務効率化と従業員満足度の向上が期待できます。
製品ページ:勤怠打刻と同時にストレスチェック「顔パス勤怠&顔パスストレスチェッカー」
マルチモーダルAIが更なる進化を目指す上で、現状に比べて対応力の高いモデルの開発が必要です。Webサイトや図解、グラフなどのデータ読み取りへの対応が実現すれば、より高精度なAIモデルの開発を促せるようになります。
同時に、学習に使うデータセットの増強も不可欠です。ただし、蓄積された知識を忘れてしまう「破滅的忘却」という課題を克服する必要があります。また、マルチモーダルAIを扱うプラットフォームの負荷を削減するために、モデルの軽量実装も必須です。
マルチモーダルは、テキスト以外の画像や音声、動画といった複数のデータ種別を同時処理できる性能のことです。マルチモーダルはすでにChatGPTやGeminiといった生成AIに導入されており、AI活用の幅が急速に拡大しています。
国内でもすでに様々な分野でマルチモーダルAIの活用が始まっています。マルチモーダルAIの今後の展開に注目です。
最新の生成AIサービス一覧を下記にて無料配布しています。自社の生成AI活用に向けてぜひご利用ください。
マルチモーダルとは、英語の「Multi」と「Modal」を組み合わせた単語で、日本語に訳すと「複数の形式・手段」という意味です。AI分野では、テキストや画像、音声、数値といった複数の異なるデータ種別(モダリティ)を扱える性能を指します。
マルチモーダルLLMでは、膨大なテキストデータに加えて、画像や動画、音声データを同時に認識できます。従来のシングルモーダルLLMに比べて、より高精度なテキスト生成やデータ変換を実現します。
交通分野で、エリア内における複数の移動手段をまとめて検索できる機能を「MaaS(Mobillity as a Service)」と言います。複数の交通機関が連携し、ユーザーニーズに対応した交通環境を提供することは「マルチモーダル交通」と呼ばれ、MaaSの概念と共通しています。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。













FOLLOW US
SNSをフォローして、最新情報をチェックできます!










AI製品・ソリューションの掲載を
希望される企業様はこちら