

Stable Diffusionとは?話題の画像生成AIの使い方・初心者向けのコツも徹底解説!
最終更新日:2026/07/13
 Stable Diffusionについて解説
Stable Diffusionについて解説
2022年8月頃を皮切りに日本にも上陸した画像生成AI。巷では話題になっているものの、「時代のスピードについていけない」「英文を使うから自分には画像は作れない」といった声もお聞きします。
そこで今回はアイスマイリーの編集部が画像生成AI「Stable Diffusion」をHugging Face、DreamStudio、Mageを使って体験してみましたので、ぜひ画像生成AI体験の参考にしてください。
生成AIについて詳しく知りたい方は以下の記事もご覧ください。
生成AI(ジェネレーティブAI)とは?種類・使い方・できることをわかりやすく解説
\ 導入前に、料金と機能をまとめてチェック /

画像生成AIとは?
画像生成AIとは、ユーザーが入力したテキストを頼りに、AIがオリジナルの画像を数秒~数十秒程度で自動生成するシステムを指します。
日本でよく知られている画像生成AIには「Stable Diffusion(ステーブルディフュージョン)」や「Midjourney(ミッドジャーニー)」があり、デザイン業界の常識を覆す存在として注目を浴びています。
これまで自分自身で画像を作成できなかったユーザーや、画像素材サイト等で月額利用料を払って高品質な画像をダウンロードしていたユーザーにとって、画像生成AIは大きなメリットがあります。
しかし、画像や絵を作り出してきたクリエイターや、風景や人物を撮影してきたカメラマンにとっては脅威と認識されており、今後のデジタルクリエイティブに大きな影響を与える存在となっています。
画像生成AIで作成した画像の商用利用について
画像生成AIで作成された画像を巡り、AIイラストメーカーの「mimic」は、サービス提供のわずか1日後にサービス停止に追い込まれる事態に発展するなど、画像生成AIを取り巻く著作権問題も話題となりました。
基本的に画像生成AIで作成される画像の著作権は「画像を生成したユーザー」に帰属するため、作成する画像の元となるイラストの作者にとっては「自身が作ったイラストとそっくりな画像が大量にWeb上で作成される事態」となり、既にクリエイターの領域を脅かしてしまっています。
関連:イラストを自動生成するAI「mimic」は違法なのか。画像生成AIモデルと著作権
AIイラストメーカーの「mimic」のように、クリエイターの批判を受けてサービス停止に追い込まれる画像生成AIもあれば、今回紹介する「Stable Diffusion」のように、オープンソースAIとして世の中に広く普及した画像生成AIもあります。
あくまで現段階での考察になりますが、両者の差は「搭載された訓練済AIモデルの違い」や「画像生成AIに読み込ませるデータの違い」にあると考えられます。
実際、広く普及しているStable DiffusionやMidjourneyはテキスト(prompt)を利用して画像を生成しており、ユーザーが入力する文字列から幅広い画像を生み出せる性質から、上述の「mimic」で指摘された著作権の問題を回避できているといえます。
ただしStable Diffusionでも、商用利用が認められていない画像を読み込ませた場合や、商用利用が認められていないAIモデルを追加学習させた場合などは、著作権侵害や利益侵害などのリスクを負ってしまいます。
Stable Diffusionにテキストを入力して画像を出力・生成する場合は問題ありませんが、後述する「Stable Diffusion web UI」のimg2imgに画像を読み込ませて新たに画像を生成する機能を使った場合は商用利用ができないケースがあることを覚えておきましょう。
画像生成AIの特徴
そして、Stable Diffusionに限らず、画像生成AIの多くは「入力する文字列が長ければ長いほど」、また「単語の数が多ければ多いほど」、ユーザーのイメージに近い画像を生成します。
そうした事情から「画像生成AIに高品質な画像を作成させるためのプロンプト(呪文)」を専門に作成・研究する「プロンプトエンジニアリング」とよばれる仕事も登場し、日々様々なタイプの画像が作り出されている状況が生まれています。
「Stable Diffusion」とは?
今回ご紹介する画像生成AIは「Stable Diffusion」です。Stable Diffusionは「入力されたテキスト」をもとに画像を生成する「訓練済のAIモデル(Diffusion Model)」を搭載した画像生成AIで、ユーザーは作成したい画像のイメージ(例えば、アマゾンのジャングル、高層ビルが建ち並ぶ都会、など)を英単語で区切って入力することで、様々な画像を作成できます。
Stable Diffusionで作られる画像は、システムに搭載された「潜在拡散モデル」というアルゴリズムによって生成されています。ユーザーはその潜在拡散モデルが訓練済モデルとして搭載されたシステムを利用するため、アルゴリズムを理解したり、Google Colaboratoryなどの環境でプログラムコードを記述したりすることなく、テキスト入力の操作だけで様々な画像を生み出せます。
ユーザーが行う基本操作は「Stable Diffusionを提供する各インターフェースでテキスト入力を行うだけ」です。インターフェースごとにテキスト以外の細かなカスタムオプションが搭載されていますが、画像生成の大部分が「入力するテキスト(prompt)」に依存しています。
そのため「英文作成が得意なユーザー」はより正確で高品質な画像を生み出せる可能性が高く、Stable Diffusionを使ってイメージに近い画像が生成できるでしょう。
Stable Diffusionの使い方は2通り
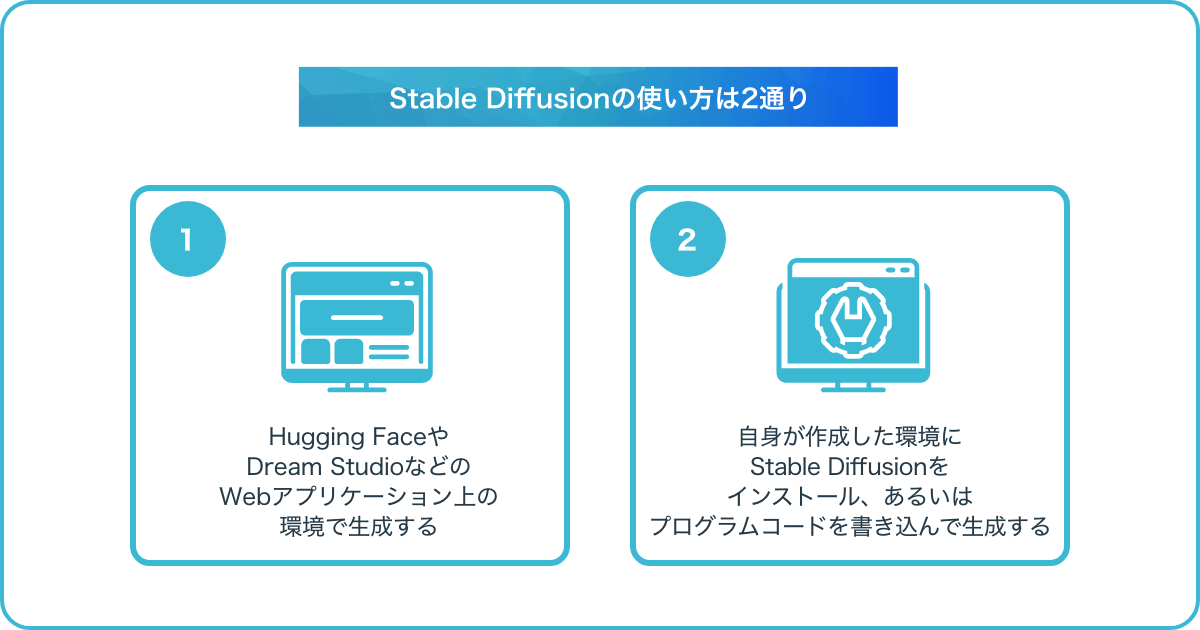
先述したように、Stable Diffusionは潜在拡散モデルが搭載されたシステムで、かつオープンソースAIであるため、Web上に構築された環境で動作させたり、ローカル環境で独自に動かしたりすることが可能です。
- Hugging FaceやDreamStudioなどのWebアプリケーション上の環境で生成する
- 自身が作成した環境にStable Diffusionをインストール、あるいはプログラムコードを書き込んで生成する
このあと使い方を実演する環境は「Webアプリケーション上の環境」(ブラウザ)です。Webアプリケーション上で公開されている環境を使うことで、誰でも簡単に画像生成AIを体験できるメリットがあります。
Stable Diffusionを提供している3つのWebサービス
Stable Diffusionを試しに使ってみたい方は、Webアプリケーション上に公開されている下記3つのサービスを活用すると効率的です。
Stable Diffusionをローカル環境やGoogle Colaboratoryで利用したい方はGitHubで公開されているコードを利用してください。
Stable Diffusionで実際に画像を生成してみた
ここからは実際にStable Diffusionを各Webアプリケーション上で利用したレビューを行っていきます。今回Stable Diffusionで画像を生成するにあたり、高品質な画像を生成するためのポイントもいくつか分かりましたので、応用編で整理していきます。
Hugging Face
まずはHugging Face上で「Stable Diffusion 2」のデモ版を動かしていきます。Hugging Faceは、自然言語処理のデータセットを共有・利用できるオープンソースコミュニティです。
様々な自然言語処理系のデータセットが提供されているなかに「Stable Diffusion 2 Demo」も含まれています。Hugging FaceのSpacesからStable Diffusionを提供する企業名「Stability AI」を検索し、「Stable Diffusion 2」を選択します。
そして下のような画面に遷移したら準備完了です。
基本操作
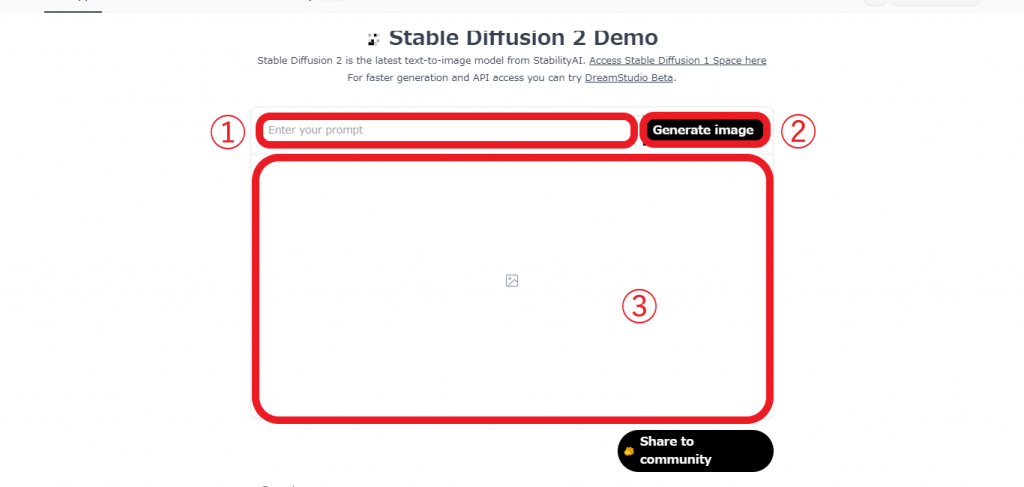
Hugging FaceでStable Diffusion 2を利用する操作手順は非常にシンプルで、①のテキスト入力エリアに生成したい画像を表すテキストを入力し、②の画像生成実行ボタンをクリックするだけです。生成された画像は③のエリアに表示されます。
生成したい画像の英文イメージが湧かない方は、ページ下部の英文例が記載されたエリア(Examples)から好みの英文を選択してください。
今回は「A pikachu fine dining with a view to the Eiffel Tower」(エッフェル塔を眺めながら高級料理を楽しむピカチュウ)を入力してみます。すると下記のような画像が30秒程で生成されました。

応用編
基本操作は非常にシンプルですが、テキストに含める英単語を変えたり、Hugging Face独自のカスタムオプションを調整することで、画像のテイストをイメージに近い雰囲気へと変化させることも可能です。
- 画質を上げる
今回は例として「人型のロボットが未来の街で、AIが搭載されたロボット犬を散歩させている絵。自動操縦の車が走っていて、空をドローンが飛んでいる。」という文章を英文に訳し、画質を上げて生成してみます。

現状でもかなりテキストのイメージに近い画像が生成されていますが、「画質」がやや粗い印象を受けるため、画像の品質を上げるために「quality8k」を含めてみます。

ロボットにツヤや光沢が見られ、背景とのぼかしも付与されてかなり画質が改善されたのが分かります。
画質を改善する英単語には「quality8k」の他に「quality4k」「realistic」「photorealistic」「Unreal Engine」などがありますので、色々なパターンを試してみてください。
DreamStudio
次にStable Diffusionを「DreamStudio」で実行していきます。DreamStudioはHugging Faceよりも早く画像を生成できるのが特徴で、素早くStable Diffusionを体験したい方におすすめです。
早速画像を生成してみましょう。上記のリンクを選択すると、下のようなログイン画面が表示されます。
Gmailアカウントを保有しているユーザーは、下部の「Continue with Google」から自身のGoogleアカウントを選択することでログインできます。次の画面が表示されたら画像生成の準備完了です。
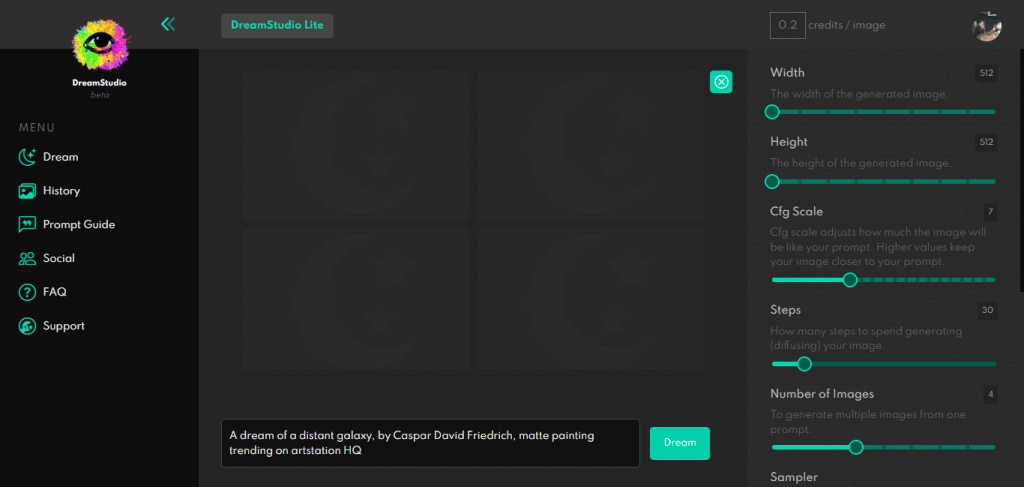
基本操作
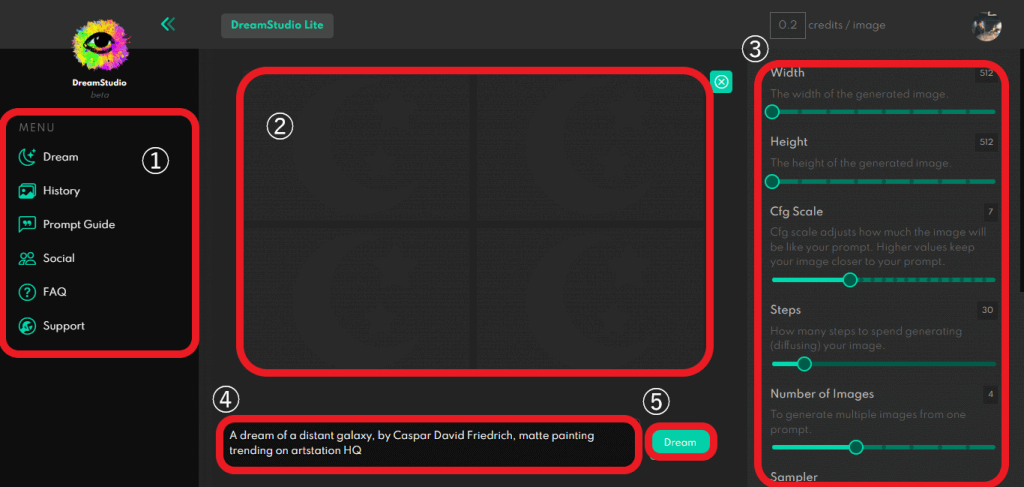
①「メニュー」では画像生成を行うタブ「Dream」に加え、過去に生成した画像を保存する「History」、初心者向けのテキスト生成のガイドが記載された「Prompt Guide」、よくある質問をまとめた「FAQ」などがあります。②は生成した画像が表示されるエリアです。
③のエリアは生成画像の細部(detail)を調整する機能です。それぞれ以下のような意味があります。
- 「Width」:画像の幅
- 「Height」:画像の高さ
- 「Cfg Scale」:テキストの再現度
- 「Steps」:画像生成にかかるノイズ除去の回数
- 「Number of Images」:生成する画像の枚数
- 「Sampler」:ノイズ除去を行うアルゴリズムの指定
- 「Model」:Stable Diffusionのバージョン
- 「Seed」:画像生成に使用する乱数の初期値
④はテキスト入力エリア、⑤は画像生成を実行するボタンです。試しにデフォルト設定の「A dream of a distant galaxy, by Caspar David Friedrich, matte painting trending on artstation HQ」で生成してみましょう。

イメージ通り「遠くの銀河」や「夢」をイメージした画像が生成されました。画風に「カスパー・ダーヴィト・フリードリヒ」という作家を指定しているため、作家が描く「荒廃感」や「空虚さ」が上手く反映されています。
応用編
デフォルトの設定でも十分に高画質な画像が生成されましたが、今回は「画風の変化」を試してみたいと思います。Stable Diffusionに限らず、様々な画像生成AIで「浮世絵」の画風が流行っていますので、日本を代表する画家「葛飾北斎」のテイストを試してみます。
- 画風を変化させる

「a dream of a distant galaxy」のプロンプトはそのままに「葛飾北斎の浮世絵」をリクエストしてみました。使用したプロンプトは「An ukiyoe painting of a dream of a distant galaxy in Katsushika Hokusai style.」です。背景の山が「富士山」を彷彿させます。
- 「Cfg Scale」と「Steps」の値を増やしてみる
かなりエモーショナルな「葛飾北斎風の”遠い銀河の夢”」が生成されましたが、ここからさらにCfg ScaleとStepsの値を増やしていきます。まずはデフォルトの「Cfg Scale:7」を「Cfg Scale:15」に変更して生成します。
【Cfg Scale:15、Steps:50】

やや写実的な描写からかなり浮世絵のタッチへと変化しています。Cfg Scaleはプロンプトの再現度(忠実度)を調整する値になりますので、値の増加で一気に浮世絵らしくなりました。ここから「Steps(ノイズ除去の回数)」を増やしてみます。
【Cfg Scale:15、Steps:100】

Stepsの回数を増やすと、月のような惑星の明かりがより細かく描かれました。元の画像と比較すると画風に大きく違いが出ています。以上のようにDreamStudioでは気に入った画像をCfg ScaleやStepsの値を増加させることで、イメージする画像・絵に近づけることが可能です。
Mage
最後にMage上でStable Diffusionを操作する方法を紹介します。Hugging FaceやDreamStudioと操作の要領は同じですが、Mageでは「避けたいイメージ」(Negative Prompt)を指定できる特徴を持っています。
応用編で紹介しますので、こちらも是非試してみてください。
基本操作
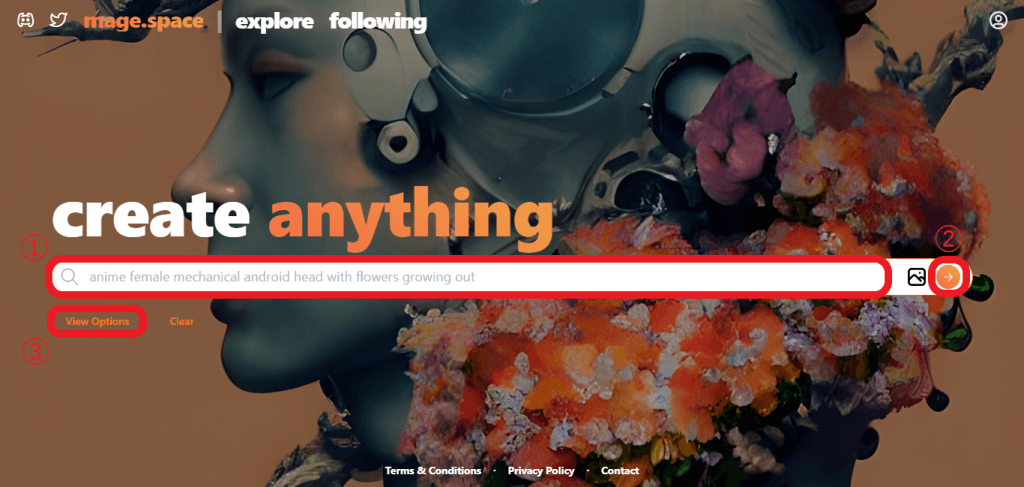
MageのUIもシンプルな作りで、①「テキスト入力エリア」、②「画像の生成ボタン」、③「オプション設定」に分かれています。
今回はDreamStudioとの差分を見たいため、プロンプトは「A dream of a distant galaxy, by Caspar David Friedrich, matte painting trending on artstation HQ」で設定してみます。
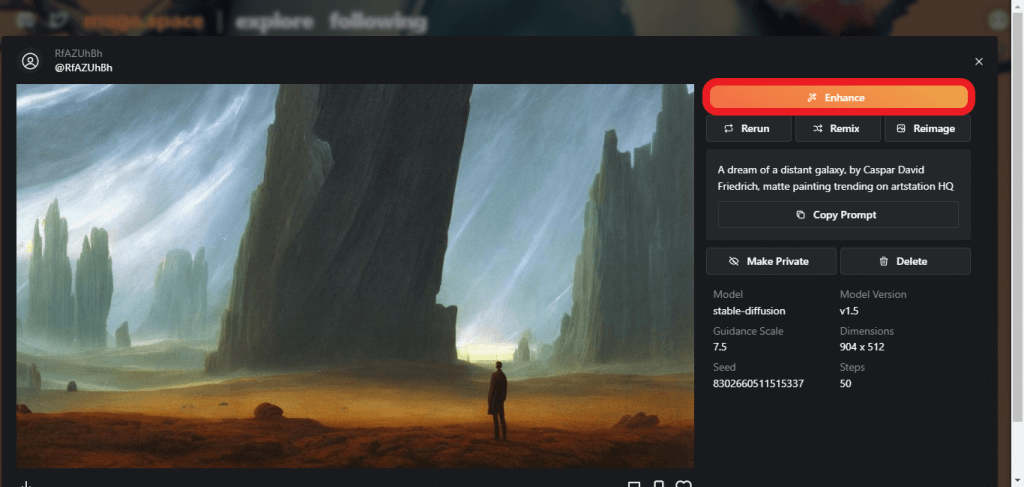
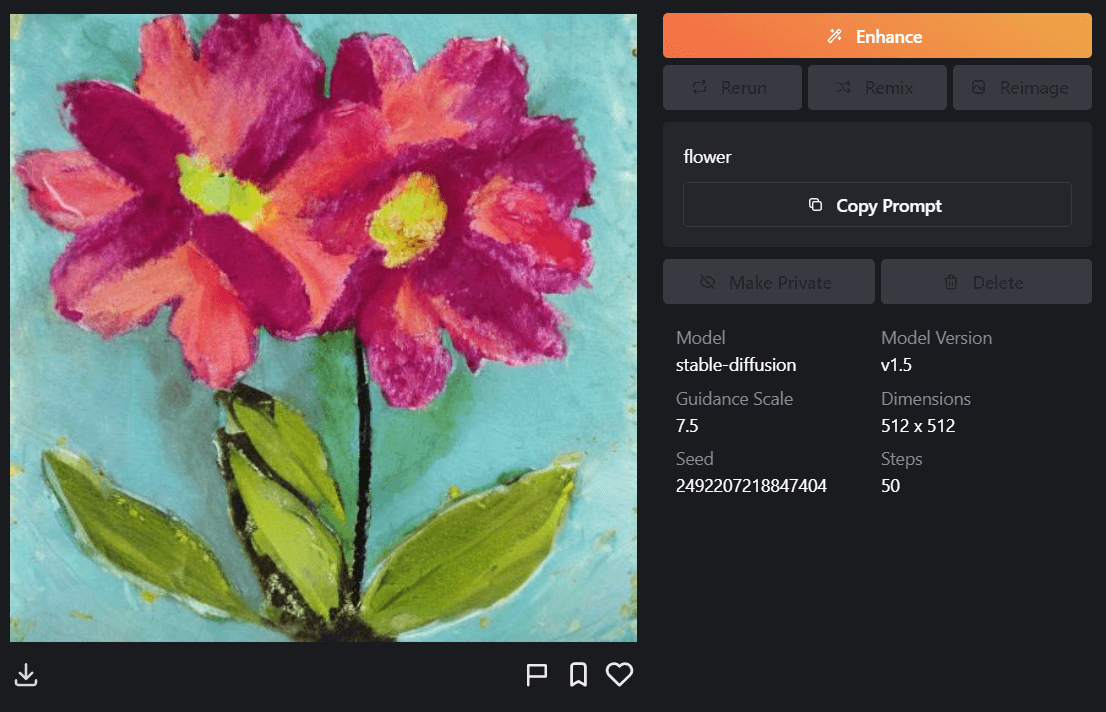
生成された画像を強化するために、右上の「Enhance」を選択します。

Enhanceを選択することで元の画像よりも全体的に画質が良くなり、色の濃淡や影の濃さが変化しています。生成した画像が気に入った際はEnhanceで強化してみましょう。
応用編
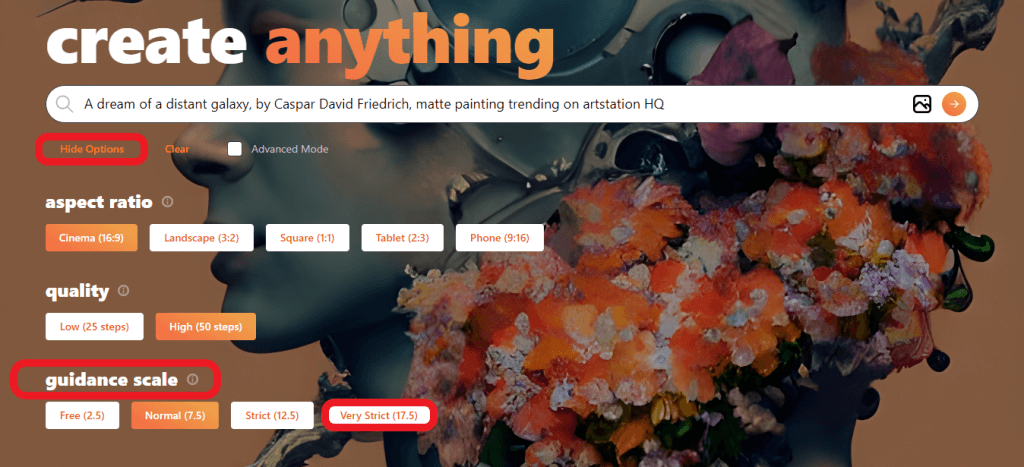
Mageでも画像を変化させていきます。トップページの「View Option」を選択し、「guidance scale」を「Very Strict」に設定します。guidance scaleはプロンプトの忠実度を表す値ですので、作家の画風に近づけていきます。
【Guidance Scale:17.5、Steps:50】

カスパー・ダーヴィト・フリードリヒの作品『雲海の上の旅人』に登場する男性のような人物が風景画とともに描かれました。
ここから「negative prompt」にテキストを追加します。
- 「negative prompt」で「人間」を指定する
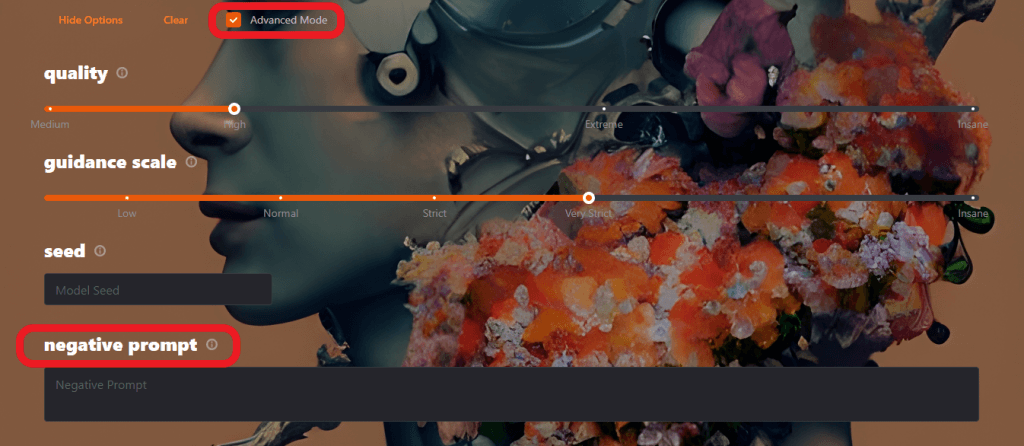
「Advanced Mode」を選択し、「negative prompt」を設定していきます。negative promptは「画像に必要のないもの」を指定する項目で、入力したプロンプトに画像を近づけないようAIが調整してくれます。
今回は「人間」(human)を指定してみます。
【negative prompt:human】

人物の居ない綺麗な風景画が描かれました。negative promptに指定したプロンプトが描かれないように生成画像が調整されています。
「日本語版Stable Diffusion」を「AIりんな」「キャラる」で試してみた
実はStable Diffusionは「日本語版」も公開されており、日本語のテキストを入力することでも画像を自動生成できます。日本語版のStable Diffusionを体験する方法として下記2つがあります。
- TwitterのAIりんなの「お絵描き会場」のリプライ欄にテキストを打ち込む
- 『キャラる』の公式Discordで画像を生成する
まずはTwitterのAIりんなのアカウントから「お絵描き会場」と書かれたツイートに遷移し、リプライ欄に「描いてほしい絵のイメージ」を記載しましょう。ツイート内容にもありますが、AIりんなに「Japanese Stable Diffusion」が搭載されたことで実現しているサービスです。
実際に様々な日本語を入力しましたが、全て「不適切なので自主規制します」と書かれた画像が表示され、生成された画像が確認できませんでした。
何度かテキストを打ち込むと、「キャラる」という画像生成AIサービスへと誘導されますので、そちらで日本語版のStable Diffusionを体験できます。
「キャラる」の招待リンクを選択すると、Discordの登録画面へと遷移しますので、登録を済ませてDiscordの画面に移りましょう。
※現在、「キャラる」のDiscord招待リンクは停止しています。
「キャラる」のDiscordでの画像生成手順は下記の通りです。
- チャンネルから「# |aiお絵描き 会場」を選択
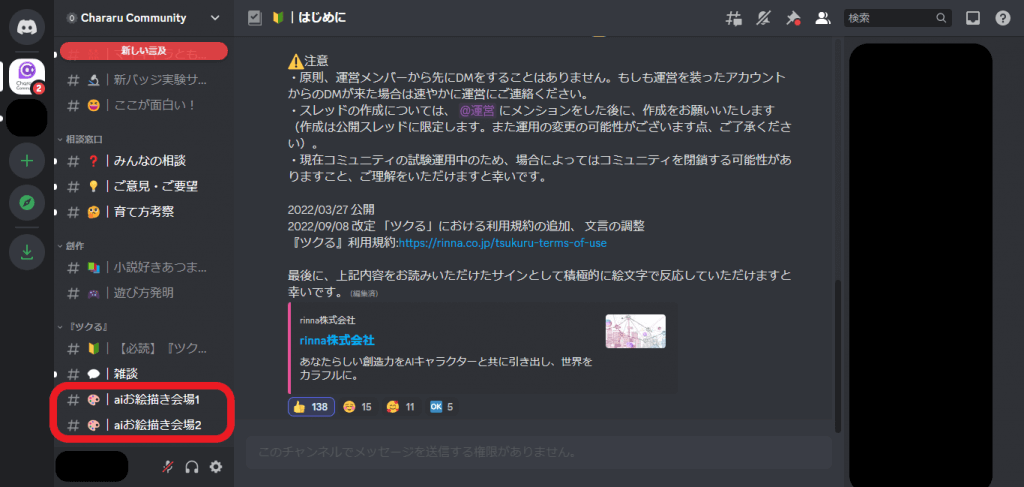
- 「/create」を入力し、「Tsukuru(ツクる)」を呼び出す

- 生成したい画像イメージを日本語で入力する

入力したプロンプトは「犬を散歩している日本人女性、浮世絵風」で、下記の画像が生成されました。
「Stable Diffusion web UI」でも画像生成が可能に
「Stable Diffusion web UI」とは、AUTOMATIC1111氏によって提供されているツールで、Stable Diffusionをより手軽に・直感的にユーザーが使えるように開発されています。
Stable Diffusion web UIはローカル環境でも実行可能ですが、実行に必要なPCスペックがあるため、まずはクラウド環境で利用するのがおすすめです。いずれの環境で実行する場合もGitHubで公開されているソースコードをインストールする必要があります。
Stable Diffusion web UIには、txt2img(テキストを用いて画像を生成する方法)と、img2img(画像:imageを読み込んで新しい画像を生成する方法)の2つがあります。より直感的に画像生成を行いたいユーザーや、生成したい画像のイメージが決まっているユーザーにはimg2imgの利用がおすすめです。
生成画像のクオリティを左右するサンプリング回数やCFGスケールなどは日本語にも対応しているため、英語が苦手なユーザーでも自由に好みの画像へと調整できます。
まとめ
今回はHugging Face、DreamStudio、Mageを使ってStable Diffusionを体験してみましたが、デフォルトの設定でも高品質な画像を生成できた印象です。
カスタムオプションの各値を調整することで、入力したテキストのイメージを忠実に再現したり、ノイズ除去レベルを増減させることで、同じ画像でも画風に近づけたり、遠ざけたりできることが分かりました。
各アプリケーションはブラウザ上で動作するアプリケーションで操作も非常に単純ですので、適当に1つ英単語を入力するだけでも「技術の進歩」と「画像生成する楽しさ」が味わえます。
AIsmileyでは、他にも画像生成AIなど生成モデルに関連する話題を取り扱っておりますので、情報収集の場としてご活用ください。
画像認識について詳しく知りたい方は以下の記事もご覧ください。
画像認識とは?AIを使った仕組みと最新の活用事例
AIについて詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
よくある質問
Stable Diffusionってなに?
Stable Diffusionとは画像生成AIの1つです。ユーザーは作成したい画像のイメージ(例えば、アマゾンのジャングル、高層ビルが建ち並ぶ都会、など)を英単語で区切って入力することで、様々な画像を作成できます。
どのくらい細かい指示が出せる?
Stable Diffusionでは細かい設定の指示にも対応してくれます。例えば「A pikachu fine dining with a view to the Eiffel Tower」(エッフェル塔を眺めながら高級料理を楽しむピカチュウ)と入力すると、その条件にあった画像がしっかり生成されます。
日本語版のStable Diffusionを体験する方法は?
日本語版のStable Diffusionを体験する方法として下記2つがあります。
- TwitterのAIりんなの「お絵描き会場」のリプライ欄にテキストを打ち込む
- 『キャラる』の公式Discordで画像を生成する
Stable Diffusionは無料で使える?
Stable Diffusionは無料で利用できます。クラウド上で実行する場合は「Hugging Face」や「DreamStudio」などのWebアプリケーションを利用し、ローカル環境で実行する場合はソースコードをインストールするか、もしくはStable Diffusion web UIをインストールして利用します。
Stable Diffusion web UIとは?
「Stable Diffusion web UI」は、AUTOMATIC1111氏によって提供されている、Stable Diffusionをより手軽に・直感的にユーザーが使えるように開発されたツールです。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- 生成AI
- ChatGPT
- Gemini
- Claude
- LLM
- AI研究開発
- 画像生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
- GPU
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI














FOLLOW US
SNSをフォローして、最新情報をチェックできます!
清水建設、AIロボットの研究開発を本格化。現場巡回や塗装作業で実…

SpaceXAI、最新モデル「Grok 4.5」を提供開始。コー…

Cloverse、アパレル特化型AI「Clovia」提供開始。撮…
NEC、Anthropic協業による「NEC AIインサイトレポ…

「AI博覧会 Summer 2026」カンファレンス第1弾スピーカーを発表!二足歩行ヒューマノイドのドーナッツロボティクス、国産LLM「PLaMo」のPreferred Networksが登壇

キッセイコムテック、ペーパーレス会議システムに生成AI活用の資料検索・要約機能を搭載。ANAホールディングスの経営会議で導入

ソフトバンクと安川電機、「AIデータセンターGPUクラウド」を活用し、柔軟物体ハンドリングシステムを実証

Anthropic、Slack上で動作する新機能「Claude Tag」発表。チーム利用可能で自律的にタスクを処理

Noetra、国産マルチモーダル基盤モデルの研究開発を本格始動。ソニー・SB・NEC・ホンダなどと連携

Grokプロンプトの書き方完全ガイド|業務で使える例文集と作り方のコツ
AI製品・ソリューションの掲載を
希望される企業様はこちら