

Open AIのSoraとは?できることや使い方、今後の課題も解説
最終更新日:2025/10/15
 Open AIのSoraとは?
Open AIのSoraとは?
OpenAI社は2024年2月15日、「Sora」という最新動画生成AIモデルを発表しました。Soraは、テキストのプロンプト(指示文)を入力するだけで、高品質の動画を生成できるツールです。現時点では一般公開されていないものの、正式にリリースされれば動画コンテンツの制作や編集に変革をもたらすと期待されています。
2025年9月30日:最新モデルの「 Sora 2」が発表されました。
【Sora 2】OpenAIの次世代動画生成AIとは?進化点、使い方、企業導入事例を徹底解説
本記事では、Open AI社の最新AIモデル「Sora」の概要から仕組み、Soraを使ってできること、現時点での課題などについて解説します。いち早くSoraの特徴を掴み、生成AIを自社の事業やコンテンツに活かしていくために、ぜひお役立てください。
「Sora」とはOpenAIが開発した動画生成AI
「Sora」は、生成AIサービスのChatGPTを開発したOpenAI社が、2024年2月15日に発表した最先端の動画生成AIモデルです。ユーザーはテキストでプロンプトを入力するだけで、最長1分間の高品質な動画を生成できます。
動画には、詳細なシーンや多様なキャラクター、カメラの動作といった複雑な要素も繊細に表現することが可能です。SoraのWebサイト上ではすでに50以上のサンプル動画が公開されており、実際にドローンやカメラワークで撮影したものと見分けがつかないほどのクオリティを実現しています。
Soraでは、プロンプトとして何を要求されているかだけでなく、プロンプトの内容が物理世界でどのように存在するのかも理解できます。被写体と背景の正確な詳細を含めた複雑な内容を理解し、動画に反映できる技術は、OpenAI社が長期的な研究を通して得た成果の1つです。
なお、Soraという名前は、日本語の「空」にちなんで付けられたという説明があります。
Soraで生成されたプロンプトで動く動画の例
Soraの公式サイト上では、すでにプロンプトから生成された動画の事例が多数紹介されています。例えば、以下の動画です。
「Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.」
引用元:Sora|Open AI
「女性がネオンが煌々と光る東京の街中を歩く動画」では、背景のネオンサインや道路、行き交う人々といった多様な要素を、ごく自然に映し出しています。人の動きや、映し出される影にも違和感は少なく、滑らかに動画が進んでいきます。
看板の文字が不鮮明で、日本語ではない文字になっている点など、不完全な部分も残されていますが、動画としての精度は高く、一般向けにリリースされる日も近いでしょう。
Soraの公開日・料金
「Sora」は現時点ではまだ一般公開はされておらず、公開に向けた詳細なスケジュールについても正式な発表はありません。現段階では応用範囲などについて研究・開発中であり、しばらくは限られたグループのクリエイターや専門家から意見やフィードバックを受け、改良を続ける予定とされています。
また、利用条件に関しても未定であるため、OpenAI社のプレスリリースなどで最新情報を定期的にチェックしておく必要があります。
Soraの仕組み・搭載されている技術
Soraでは、テキスト指示からの動画生成を中心に、静止画からの動画生成や動画の拡張・編集などさまざまなタスクに対応しています。ここでは、Soraの高度な機能を実現する仕組みや、搭載されている技術について説明します。
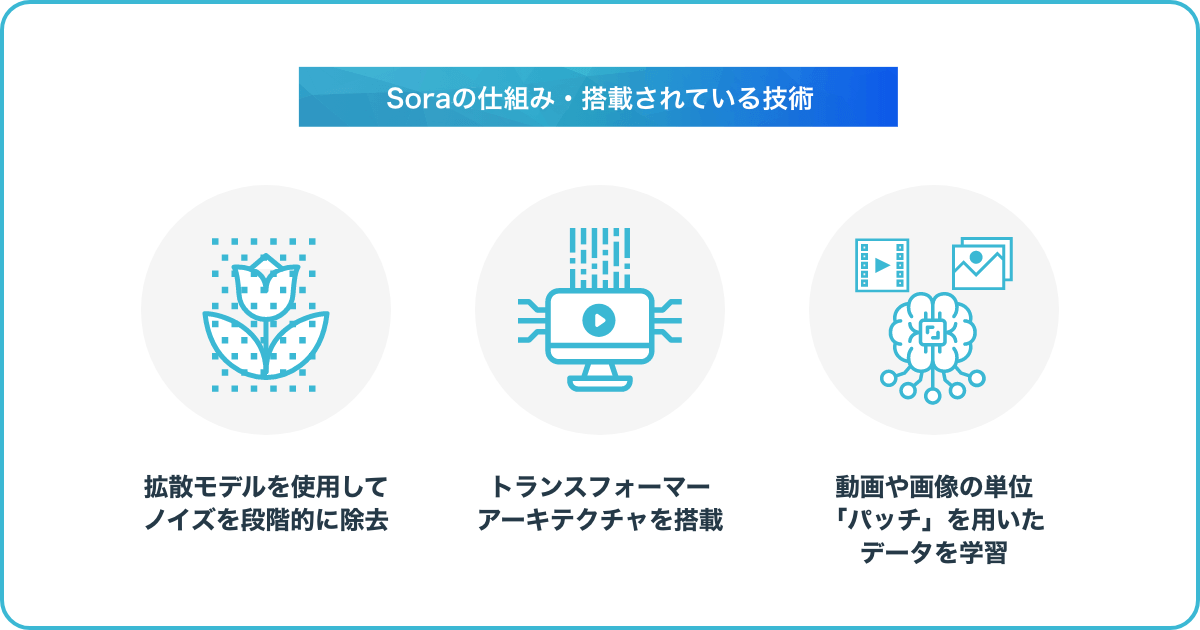
拡散モデルを使用してノイズを段階的に除去
Soraでは、ハイクオリティな動画生成を実現するために、拡散モデル(Diffusion Model)と呼ばれるAIモデルを採用しています。拡散モデルとは、画像やテキスト、音声といったコンテンツに一度ノイズを加えてから、プロセスをさかのぼるようにして段階的に再構築する過程を学習した生成AIモデルです。
対象となる動画は、まず膨大な量の静止ノイズを加えて、低品質の動画を生成した後で、段階的にノイズを除去していきます。最終的に求められる品質へと近づけていく過程を学習することで、プロンプトの内容を反映した動画を生成する仕組みです。
トランスフォーマーアーキテクチャを搭載
Open AI社のChatGPTモデルと同じように、Soraはトランスフォーマーアーキテクチャを搭載しています。Soraの拡張モデルは、言語処理や画像生成といったシーンでも優れたスケーリング性能を発揮したビデオ生成用のスケーリングトランスフォーマーです。
ノイズが多い情報が入力されると、元のきれいなパッチを予測するようにトレーニングされます。また、トレーニングの計算量が増えると品質も向上することがわかっています。
動画や画像の単位「パッチ」を用いたデータを学習
Soraでは、動画や画像を「パッチ」という小さな単位の集合として表現します。パッチは、LLM(大規模言語モデル)におけるテキストトークンと似たようなものです。先行研究において、各パッチが視覚データを効果的に表現するために役立つと示されています。
まず、画像や動画を「低次元の潜在空間(Video compression network)」に圧縮し、続いてSoraが実際に理解できる単位としての「時空間パッチ(Spacetime Latent Patches)」へと分解することで、動画をパッチへと変換します。続いて、Soraが潜在空間内で動画を生成して最終的に成果物を得る仕組みです。
パッチを用いてデータの表現方法を統一することにより、異なる時間や解像度、アスペクト比を持つ幅広い視覚データに対して、拡散変換器を学習できます。
Soraでできること
Soraは、テキストのプロンプトを理解し、動画を生成すること以外にも、画像からの動画生成や動画の拡張といった幅広いタスクに対応可能です。2024年3月時点で公開されている情報をもとに、Soraを使ってできることについて紹介します。
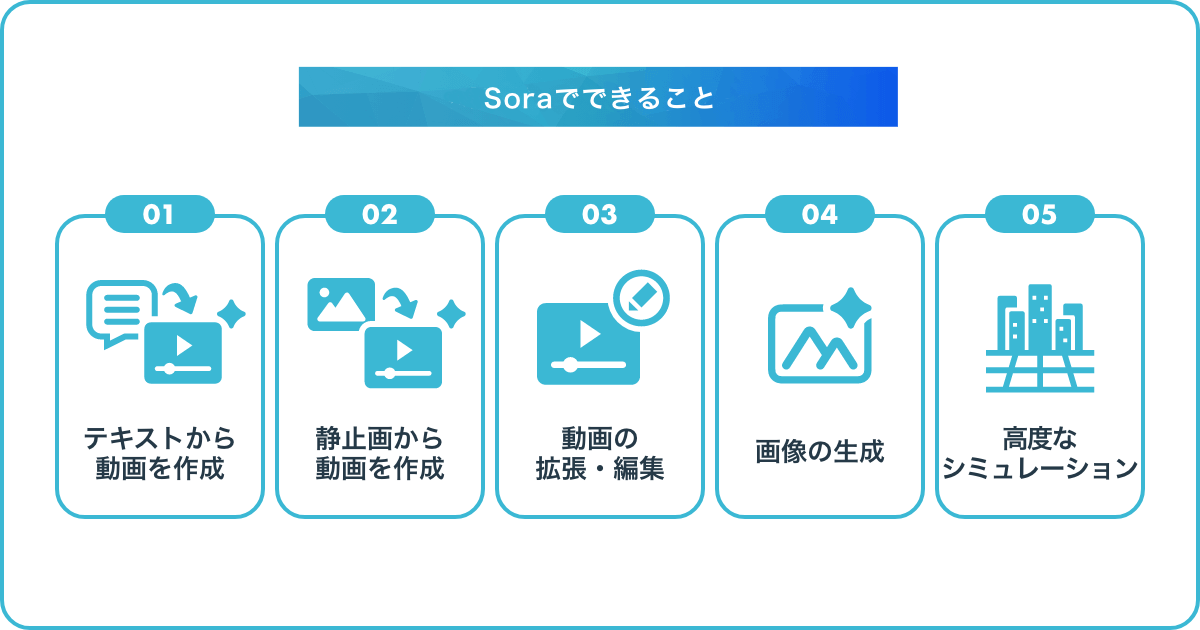
テキストから動画を作成(Text-To-Video)
Soraのメインとなる機能は、テキストから動画を生成する(Text-To-Video)機能です。プロンプトを正確に理解し、違和感の少ない高精度な動画を生成します。動画の尺は最長1分で、画期的な長さと言われています。
Soraはプロンプトの内容に加えて、物理的にどのように存在するかなども理解できます。そのため、複数のキャラクターや特定の動き、被写体と背景の詳細を含んだ複雑なシーンも自然な動画として生成することに成功しています。人物やキャラクターの生き生きとした感情を表現でき、まるで実際に撮影した動画に見えます。
静止画から動画を作成(Image-to-Video)
Soraは、テキストのプロンプトだけでなく、画像や動画の指示にも対応しています。静止画から動画(Image-to-Video)により、DALL・Eで生成された画像のアニメーション化などさまざまなタスクを実行可能です。
例えば、Soraに画像とテキストのプロンプトを合わせて入力することで、高精度な動画を生成できます。
動画の拡張・編集(Video-to-Video)
Soraは、動画の拡張や編集(Video-to-Video)も可能です。OpenAI社の公式サイトでは、生成された動画のセグメントから時間を逆方向に拡張した動画が公開されています。動画の前後両方を拡張して、異なる複数の動画を用いてループ動画を生成することも簡単です。
また、Soraでは、入力動画を徐々に補完しながらシームレスなトランジションを作成します。被写体や構図が異なる2つの動画を統合し、映画館で見るシーンの切り替えのような本格的な動画を誰でも作り出すことが可能です。
また、テキストから画像や動画を編集する方法(SDEdit)を活用することで、動画のスタイルや環境をすぐに変換できます。
画像の生成
Soraは、動画だけでなく画像の生成にも対応しています。画像は最大2048×2048pxの解像度のため、多彩なサイズの画像を生成することが可能です。
動画と同じように、ディテールやスタイルを調整でき、汎用性の高いツールとして活用できます。
高度なシミュレーション
Soraには、従来の動画生成AIモデルとは異なる新しいシミュレーション能力を備えていると、OpenAI社は話しています。一度に多くのフレームの先読みを与えることで、被写体が一時的に視界から外れても、状況や被写体を記憶し続けて、一貫性をキープすることに成功しています。
例えば、カメラの移動や回転により、人物や背景の要素が物理的に一貫性を持って移動するような動画を生成できます。また、ゲームの世界など人工的なプロセスをシミュレートすることも可能で、ユーザーがゲームをプレイしているかのようなリアルな映像を作り出すことが可能です。
Soraの使い方
Soraは現時点でまだ公開されておらず、正式なリリースに関しても未定です。一般公開が決定し、具体的なスケジュールが発表される頃にはユーザー向けに案内が出ますので、公開までお待ちください。
現段階におけるSoraの課題や問題点
従来までの生成AIを超える動画生成モデルとして世に紹介されたSoraですが、課題が残されていることもわかっています。ここでは、現時点で考えられるSoraの課題や問題点について解説します。
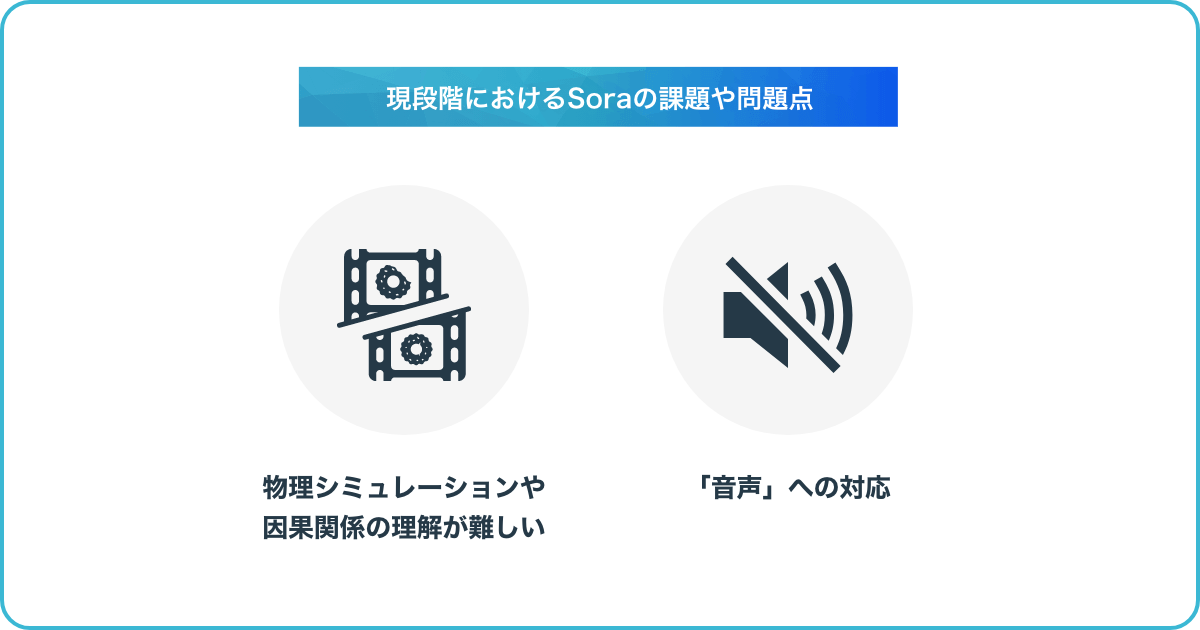
物理シミュレーションや因果関係の理解が難しい
OpenAI社は、現在のモデルが抱える弱点として「複雑な場面」や因果関係が含まれる状況において、物理的な特性を正確に理解し、再現できない場合があると話しています。現時点では、複数のキャラクター間の相互作用や物理的関係をシミュレートすることはSoraにとって困難であり、ときにエラーとなる可能性があると指摘しています。
同社は例として、キャラクターがクッキーを食べている動画を公開していますが、かじったクッキーはもとの形を維持しています。また、ガラスが粉々に砕ける場面もうまく記述できないことがあるようです。
これは、Soraがプロンプトに含まれる空間の詳細を的確に理解、表現しきれないために起こっている可能性が考えられます。また、特定のカメラの軌跡をたどることや、少しずつ時間をかけて起こる出来事も、正確なレンダリングに苦労する場合があります。
「音声」への対応
OpenAI社は、Soraの性能に音声が含まれていないことも指摘しています。
Soraを実際に使ってみた
こちらの章では、Soraを実際に使い、動画を生成する過程をご紹介します。
動画の設定とプロンプトの入力
Soraでは、画面下側にプロンプト入力欄があります。

入力欄の下のアイコンをクリックすることで、アスペクト比や、解像度、動画時間等を変更することができます。
- 画像のアップロード
自分の写真をアップロードし、それを元に動画を作成できます。例えば、風景写真を動くアニメーションに変換可能です。 - アスペクト比の選択
16:9(YouTube用)、1:1(Instagram用)、9:16(TikTok用)から画面比率を選べます。各プラットフォームに最適な動画を作成できます。 - 画質の設定
解像度を480p、720p、1080pから選択できます。高解像度ほど鮮明ですが、制作時間が長くなります。 - 動画の長さ
ChatGPT Plusでは5秒と10秒、Proに加入した方は15秒と20秒の動画を作成できます。 - 動画の生成数
一つのプロンプトで最大4本の動画を同時に作成でき、異なるバリエーションを一度に確認できます。

今回はこちらのプロンプトを試してみました。

このように、簡単なプロンプトを入力するだけで動画の生成ができました。
プリセットの登録
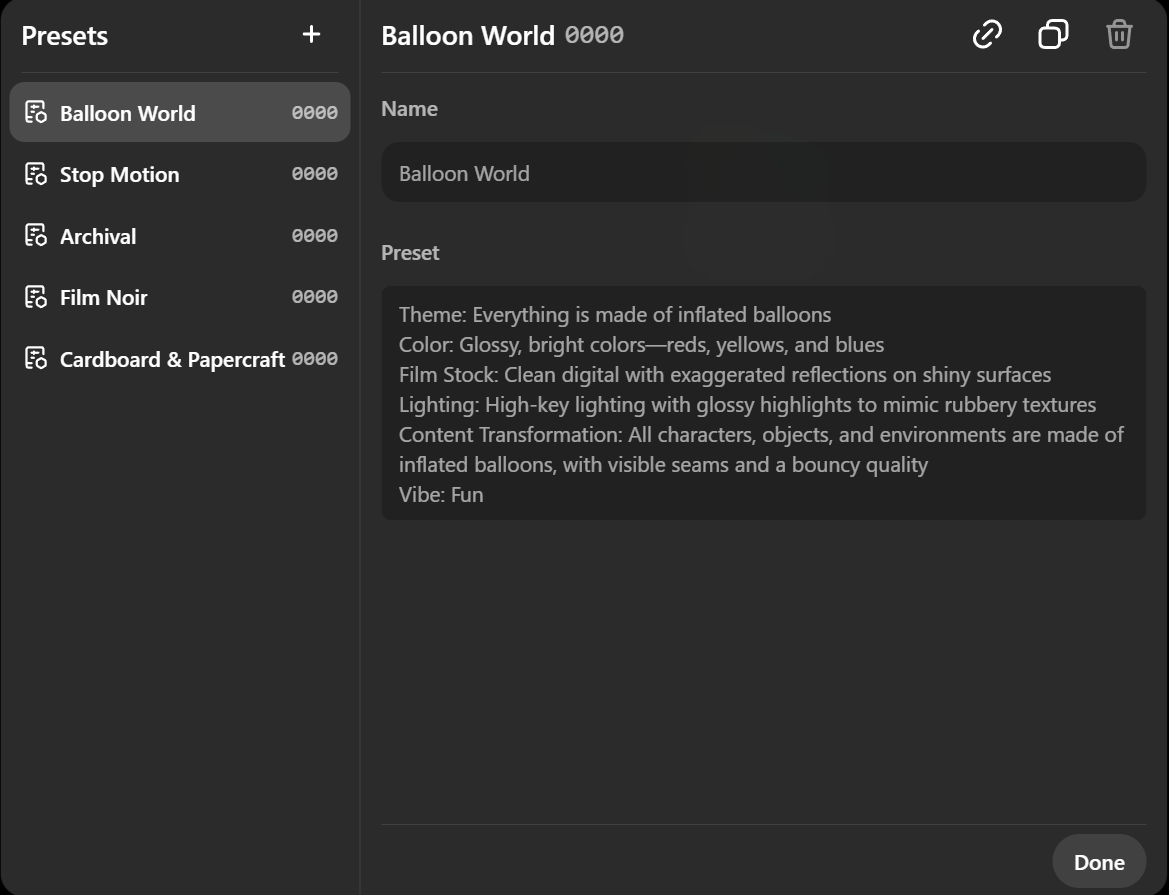
Soraでは、プリセットの登録ができます。
プリセットの登録でカメラの設定や色、照明、色調、テーマ等をあらかじめ設定することができます。これにより、一貫性のあるスタイルの動画を生成することができます。
ストーリーボード機能
続いて、Soraのストーリーボード機能について説明します。

ストーリーボード機能では、直感的な操作で動画の構成を作ることができます。
黒い枠のなかにプロンプトや画像、動画などをアップロードすることにより簡単にストーリーボードを作成できます。
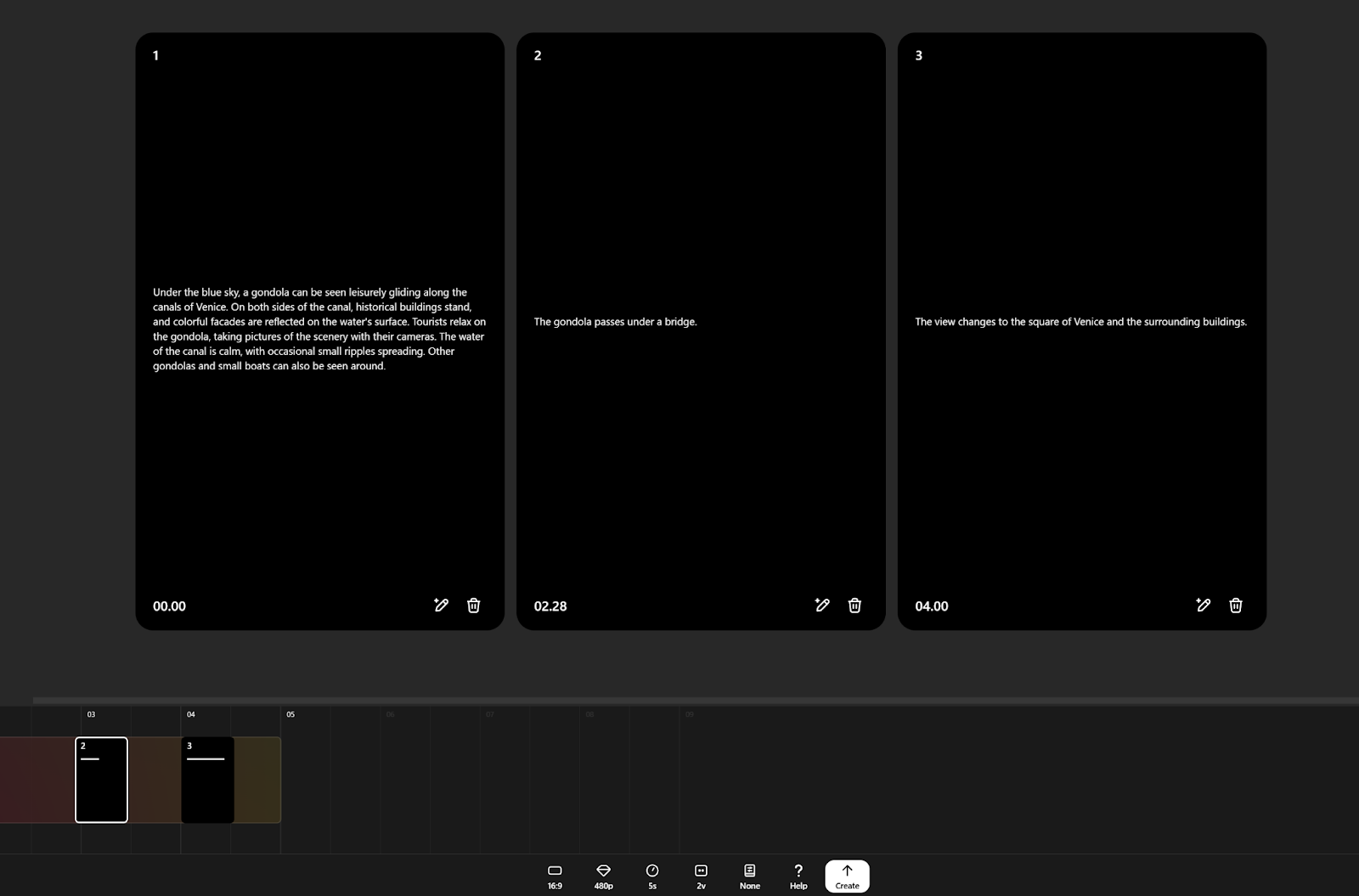
今回はベニス運河をゴンドラで旅する動画を作成してみました。
えんぴつマークをクリックすることで、より効果的なプロンプトに書き換えてくれます。
ストーリーボード上で以下のような流れでプロンプトを作成しました。
- 運河のゴンドラ風景(シーン1)
ベニスの運河で、歴史的な建物と色鮮やかな外観が水面に映る中、ゴンドラが穏やかに進む様子が描写されます。 - 橋の下を通過するゴンドラ(シーン2)
ゴンドラがエレガントなアーチ型の橋を滑らかにくぐり抜け、橋と建物の反射が運河の水面に踊るシーンです。 - ベニス広場の全景(シーン3)
壮大な歴史的建物に囲まれた広場が映し出され、人々が行き交う活気ある雰囲気とベニスの象徴的な景観が描かれます。
壮大な歴史的建物に囲まれた広場が映し出され、人々が行き交う活気ある雰囲気とベニスの象徴的な景観が描かれます。
Createボタンをクリックし、動画を作成します。

こちらのような動画が作成できました。
このように、ストーリーボード機能を使うことにより、構成を指定した動画作成ができるようになります。
Soraの導入事例
トイざらス
トイザらスは、OpenAIの非公開生成AI動画モデル「Sora」を使用して最新のブランド動画を制作しました。広告代理店Native Foreignが手掛けたこの動画は、Toys R Us創業者であるCharles Lazarus氏の生い立ちを簡単にまとめています。動画では、Toys R Usのマスコットキャラクター「ジェフリー」と幼いLazarus氏がAIによって表現されています。
トイザらスのWEBcmはこちら
The Origin of Toys“R”Us: Brand Film Teaser | Toys”R”Us
Adobe Premiere Pro
2024年4月15日『Adobe Premiere Pro』に新たな動画生成機能を追加することを発表しました。これには「生成拡張」「オブジェクトの追加と削除」「テキストからの動画生成」などが含まれ、さらに複数のサードパーティ製モデルへの対応も発表されました。
アドビは、OpenAIやPika Labs、Runwayなど他社のAIモデルを『Adobe Premiere Pro』に統合することも発表しました。スニーク映像では、生成拡張においてAdobe Firefly以外のモデルや、テキストからの動画生成にOpenAIの「Sora」が使用されていました。さらに、コンテンツクレデンシャルへの対応も発表され、AIがどのように利用され、どのモデルを使用したのかの情報が付与される予定です。
今回発表された機能は「年内導入予定の機能」の先行公開です。導入時期は明らかにされていませんが、Murati氏の発言通りであれば、数ヶ月以内にAdobe製品で動画生成が可能になるでしょう。
まとめ
OpenAI社によるSoraの発表は、生成AI業界に大きな衝撃を与えました。ChatGPTのように、テキストで動画の内容を入力するだけで、簡単に高精度でリアルな映像ができ上がります。また、画像からの動画生成や動画の拡張、画像生成といった幅広いタスクにも対応可能です。
ただし、複雑な要素や因果関係の的確な理解が難しいなど、現時点のSoraにも課題はあります。とはいえ、正式なリリースとともに動画コンテンツの生成が大幅に効率化されるでしょう。現時点では、Soraの正式な一般公開の予定や利用対象者など条件は未定であり、一日でも早いアップデートが待ち望まれています。
AIsmileyでは、生成AIサービスの比較表や一覧をご請求いただけます。自社におけるAI活用の検討にぜひお役立てください。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- 生成AI
- ChatGPT
- Gemini
- Claude
- LLM
- AI研究開発
- 画像生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
- GPU
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI














FOLLOW US
SNSをフォローして、最新情報をチェックできます!
清水建設、AIロボットの研究開発を本格化。現場巡回や塗装作業で実…

SpaceXAI、最新モデル「Grok 4.5」を提供開始。コー…

Cloverse、アパレル特化型AI「Clovia」提供開始。撮…
NEC、Anthropic協業による「NEC AIインサイトレポ…

富士通、大規模言語モデルの大幅なコスト削減を実現するアーキテクチャ「PHOTON」開発。Transformerの最大475倍の出力トークン数を持つ

キッセイコムテック、ペーパーレス会議システムに生成AI活用の資料検索・要約機能を搭載。ANAホールディングスの経営会議で導入

Anthropic、Slack上で動作する新機能「Claude Tag」発表。チーム利用可能で自律的にタスクを処理

Noetra、国産マルチモーダル基盤モデルの研究開発を本格始動。ソニー・SB・NEC・ホンダなどと連携

Grokプロンプトの書き方完全ガイド|業務で使える例文集と作り方のコツ

サイバーセキュリティのAI自動化とは?メリット・セキュリティ戦略を解説
AI製品・ソリューションの掲載を
希望される企業様はこちら