

大規模言語モデル(LLM)とは?仕組み・種類・活用サービス・課題をわかりやすく解説
最終更新日:2026/01/16
 大規模言語モデル(LLM)とは?
大規模言語モデル(LLM)とは?
ChatGPTを筆頭に生成系AIサービスが世界的に浸透するとともに、個人だけでなくビジネスシーンにおける利用も増加の一途を辿っています。文章や画像、動画などさまざまな生成AIサービスが登場する中、テキスト向けAIモデルにおいて欠かせないのが大規模言語モデル(LLM)です。
生成系AIサービスの登場に伴い、AI技術が専門の域を超えて社会生活に浸透している現在、LLMの基本的な情報や課題を押さえておくことはAIサービスを活用する上で重要です。
本記事では、大規模言語モデル(LLM)の概要や種類、LLMでできること、代表的なLLM製品などについて解説します。
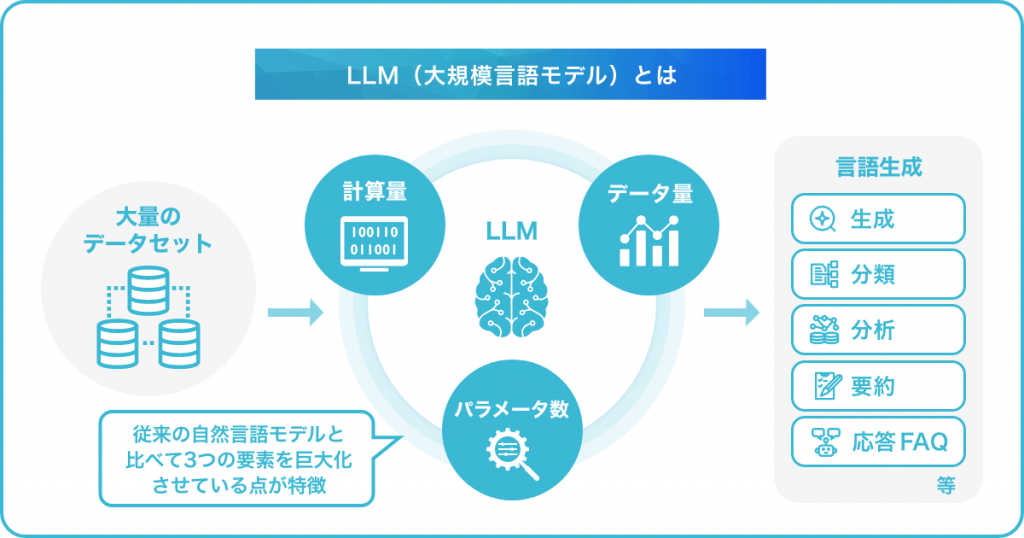
LLM(Large Language Models:大規模言語モデル)とは、大量のデータセットとディープラーニング技術を用いて構築された、機械学習の自然言語処理モデルのことです。一般的には、特定のタスクでトレーニングする「ファインチューニング」と呼ばれる手法を用いて、テキスト分類・生成や感情分析、文章要約、質問応答といったさまざまな自然言語処理(NLP)タスクに適応させます。
大規模言語モデルでは、従来の自然言語モデルと比べて「計算量(コンピュータが処理する仕事量)」「データ量(入力された情報量)」「パラメータ数(ディープラーニング技術に特有の係数の集合体)」という3つの要素を巨大化させている点が特徴です。
そのため人間の自然な会話に近い流暢なやり取りや、自然言語のさまざまな処理を高精度で行うことができます。大規模言語モデルの代表例には、Googleによる「Gemini」やOpenAIの「GPT」などがあります。
そもそも言語モデルとは
そもそも「言語モデル」とは、文章や単語の出現確率を用いてモデル化したものです。言語モデルでは、人間が使う言い回しや意味を理解した上で、次にどの単語が続くのかを推測します。
人間の自然な会話や文章に対して高い確率を割り当て、文章として成立しない単語の並びには低い確率を割り当てます。選択肢の中から最も高い確率の単語の並びを採用することで、違和感の少ない文章を出力する仕組みです。
大規模言語モデルは、言語モデルにおける種別の1つです。近年では、ニューラルネットワークを用いた言語モデル(ニューラル言語モデル)が自然言語処理の分野で広く使われています。
LLMとChatGPTの違い
LLMは、大量のデータセットと深層学習技術を採用したAIモデルで、自然言語処理タスクを実行します。ChatGPTとは、OpenAI社が開発したGPT(Generative Pre-trained Transformer)アーキテクチャに基づくAIモデルであり、LLMの事例の1つがChatGPTです。
LLMが特定のパラメータや条件に基づいて文章を生成するのに対し、ChatGPTではより自然な会話や人間らしい文章を生成することを得意としています。
LLMと生成AIの違い
生成AIとは、テキストや画像、動画、音声など新しいデータやアイデアを生成するAI技術の総称です。一方、LLMは自然言語処理に特化した言語モデルであり、生成AIの種類の1つです。
また、テキストの理解や生成を担うLLMであるChatGPTも生成AIです。
大規模言語モデル(LLM)の仕組み
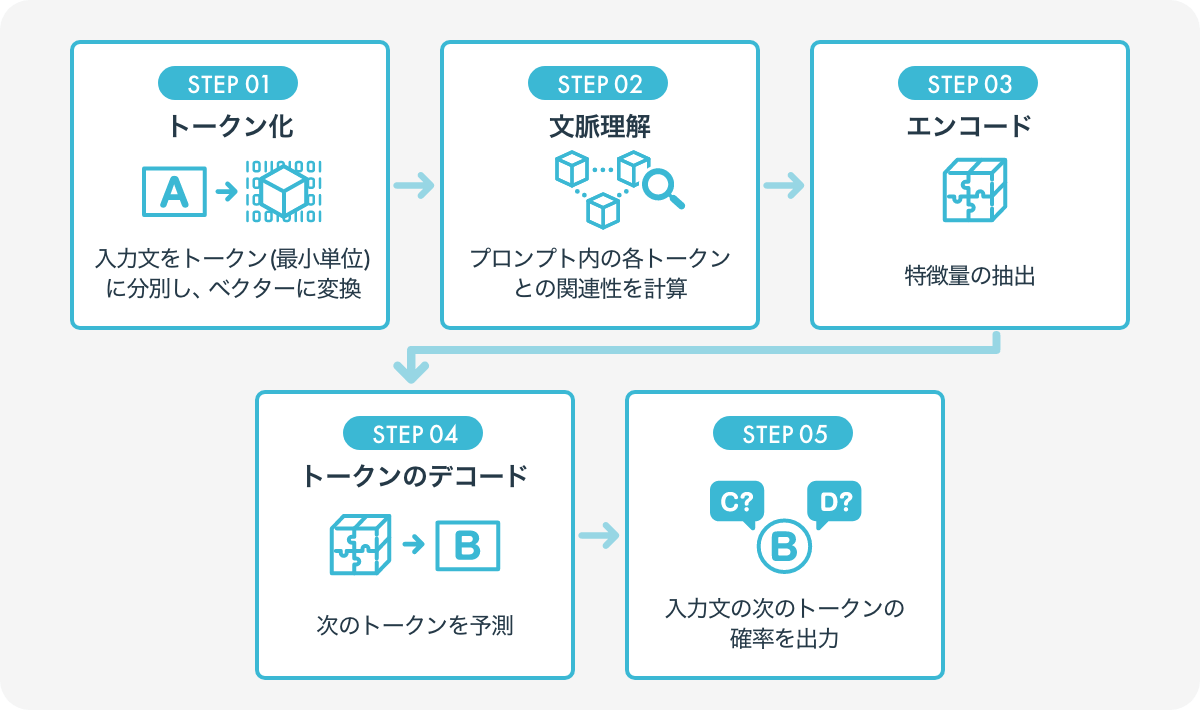
LLMの仕組みを見ていきましょう。まず、LLMでは、巨大テキストデータセットを用いた事前学習(Pre-Training)と、性能を最適化する微調整(Fine-Tuning)の2段階のプロセスがあります。
その後、LLMが入力(プロンプト)を受け取り、適切な回答を出力するまでの主な流れは、以下の通りです。
- トークン化:入力文をトークン(最小単位)に分割し、ベクトルに変換
- 文脈理解:プロンプト内の各トークン間の関連性を計算
- エンコード:特徴量の抽出
- トークンのデコード:次のトークンを予測
- 入力文の次のトークンの確率を出力
LLMでは、基本的に上記の手順を繰り返し、文書生成が実行されます。LLMのモデルにより細かな点は異なりますが、多くのLLMでは単語や部分単語をトークンとして扱っています。
以下に、詳しい手順を解説します。
1. トークン化:言語の基本単位への分割
LLMの最初のステップは「トークン化」です。ユーザーから入力された生のテキストを、モデルが処理可能なデータ形式へと変換します。テキストが小さな単位(トークン)に分割され、単語、サブワード(単語の一部)、あるいは記号まで分解されます。
2.文脈理解:トークンの意味を捉える
文脈理解のステップでは、モデルがトークン化された単語やフレーズの意味だけでなく、それらがどのように互いに関連しているかを学習します。このプロセスには、共参照解析や依存関係解析といった高度な技術が用いられます。
- 共参照解析:この技術は、文章中の代名詞や指示詞が実際に何を指しているのかを特定します。たとえば、「彼は彼女に本を渡した」という文では、「彼」と「彼女」が誰を指しているのかをモデルが理解する必要があります。
- 依存関係解析:文中の各単語間の文法的な依存関係を分析します。これにより、動詞がどの名詞に影響を与えているのか、形容詞がどの名詞を修飾しているのかなど、文の構造を正確に把握します。
これらの解析を通じて、モデルは入力されたプロンプト内の各トークンがどのように相互作用するかを理解し、文全体の意味を正確に捉えることができます。
3. エンコード:特徴量の抽出
エンコードの段階では、文の意味をコンピュータが理解できる形、つまり数値のデータに変換します。この過程は次のように進められます。
- ベクトル化:: まず、文を構成する各単語やフレーズを数値の並び(ベクトル)に変換します。このベクトルは単語の意味や文脈を表していて、コンピュータが計算できる形です。
- 文脈の把握: 次に、これらのベクトルを特別なニューラルネットワークを使って処理します。このネットワークは文の中で単語がどのように関連しているかを見て、文全体の意味を捉えます。
- 重要な情報の選択: アテンションメカニズムという技術が重要な単語やフレーズに注目します。このモデルは文中の重要な情報を優先的に扱い、文の意味を正しく理解します。
このようにして、モデルは文の意味を数値の形で正確に把握し、その情報を基に次のステップへ進みます。このステップが、言語モデルが言葉を正確に理解するための基礎となります。
4. トークンのデコード:次のトークンの予測
デコードの段階では、モデルがこれまでに集めた情報を使って新しい言葉を生成します。文の流れに基づいて何が自然に続くかを予測して過去の文脈から得た知識を活用して、次に最適な単語やフレーズを選び出します。
5.出力:ユーザーへの応答
最終ステップでは、モデルが選択したトークンをユーザーにとって理解しやすい形式のテキストに変換し、出力します。
以上の過程を通じて、LLMは複雑な自然言語のテキストを効率的に処理し、新しいテキストを生成できるようになります。この技術は、質問応答、文章生成、翻訳など、多くの応用分野において重要な役割を果たしています。
大規模言語モデル(LLM)の種類一覧
ここ数年で多数の大規模言語モデルが発表されています。ここでは、代表的な製品を含むLLMの一覧を紹介します。
| 言語モデル名 | 概要 | 企業名 | パラメータ数 | 発表年 |
| BERT | データセットの規模を増やし精度を向上させた 初期の言語モデル |
3.4億 | 2018年 | |
| GPT-4 | GPT-3に、画像や音声などテキスト以外のデータを 学習させたモデル |
OpenAI | 非公開 | 2023年 |
| LaMDA(Language Model for Dialogue Applications) | Transformerをベースとし、対話に特化させたモデル。 1兆5,600億語のテキストコーパスで事前学習を実施 |
未公開 | 2021年 | |
| PaLM(Pathways Language Model) | 論文「Scaling Language Modeling with Pathways」を元にしたモデル。 Transformerのパラメータ数を大幅に拡大し、高性能を実現 |
5,400億 | 2022年 | |
| LLaMA(Large language Model Meta AI) | GPT-3と同等の性能を、圧倒的に少ないパラメータ数で実現。 GitHub上でオープンソースとして公開 |
Meta | 70~650億 | 2023年 |
| NEMO LLM | 独自の学習データで 多様なサイズにカスタマイズ可能 |
NVIDIA | 未公開 | 2022年 |
| Claude | GPT-2とGPT-3の開発に携わったエンジニアによるモデル | Anthropic | 未公開 | 2023年 |
| Alpaca 7B | LLaMAをベースとし、Instruction-following(指示実行)の結果を使って ファインチューニングしたモデル |
スタンフォード大学 | 70億 | 2023年 |
| Vicuna 13B | LLaMAをベースに、ChatGPTとユーザの会話を学習させた オープンソースのチャットボット |
カリフォルニア大学 | 未公開 | 2023年 |
| OpenFlamingo | DeepMindが開発したマルチモーダルモデル 「Flamingo」をオープンソース化 |
LAION | 未公開 | 2023年 |
| Llama 3 | Metaが開発したLLaMAの第3世代モデル。 4050億パラメータのモデルを含む複数のサイズで提供され、高度な言語理解と数学的問題解決能力を持つ |
Meta | 80億・700億・4050億 | 2024年 |
| Gemini 1.5 | Google DeepMindが開発したマルチモーダルモデル。 長いコンテキスト理解能力を強化し、1,000,000トークンのコンテキストウィンドウを実現 |
未公開 | 2024年 | |
| OpenELM | Appleが開発した効率的な言語モデルファミリー。 レイヤーごとのスケーリング戦略を採用し、各層内のパラメータを効率的に配置することで精度を向上 |
Apple | 約10億 | 2024年 |
| Llama 4 | AMetaが開発した最新のマルチモーダルAIモデル群で、テキスト、画像、音声など多様なデータ形式を処理可能。 特に、社会的・政治的に議論のある質問にも対応できるよう設計されています。 |
Meta | Scout: 17Bアクティブパラメータ(総計109B)、Maverick: 17Bアクティブパラメータ(総計400B)、Behemoth: 288Bアクティブパラメータ(総計約2T) | 2025年 |
| gemini 2.5 Pro | Google DeepMindが開発した最も高度なAIモデルで、推論能力が強化され、複雑な問題解決や分析が可能。 テキスト、画像、音声、ビデオなどのマルチモーダル入力に対応し、100万トークンのコンテキストウィンドウを持つ。 |
未公開 | 2025年 | |
| GPT-5 | 高速応答と複雑な推論の2つのモデルを備え、コーディング・数学、文章作成などあらゆる分野で利用可能 | OpenAI | 未公開 | 2025年 |
上記に挙げた主なLLMの多くは、「Transformer」と呼ばれるニューラルネットワークアーキテクチャをベースとしています。Transformerは、2017年に発表された「Attention Is All You Need」という論文で示されたディープラーニングのモデルです。
従来のニューラルネットワークより少ないレイヤーを使用する点がブレイクスルーとなり、「BERT」や「GPTシリーズ」の登場につながっています。
大規模言語モデル(LLM)にできること

大規模言語モデル(LLM)ができることは多岐にわたります。ここでは、その一部を以下にまとめます。
- 質問への回答
- 文章の要約
- 感情分析
- 機械翻訳
- プロンプト(入力)の続きを予測
- 文章の分類や言い換え
- キーワードの抽出
- 入力されたプログラムのバグチェック
最近では、画像や音声などテキスト以外のデータも学習させたLLMも登場しています。
LLMでは、指示を送る入力(プロンプト)により、さまざまな出力が可能です。ChatGPTなどのLLMを使いこなす上で欠かせないプロンプトの基礎知識や、出力精度の高め方については、下記記事にて解説しています。
ChatGPTを活用するためのプロンプトとは?例文を交えて精度が上がる命令方法を紹介
大規模言語モデル(LLM)を活用した代表的なサービス
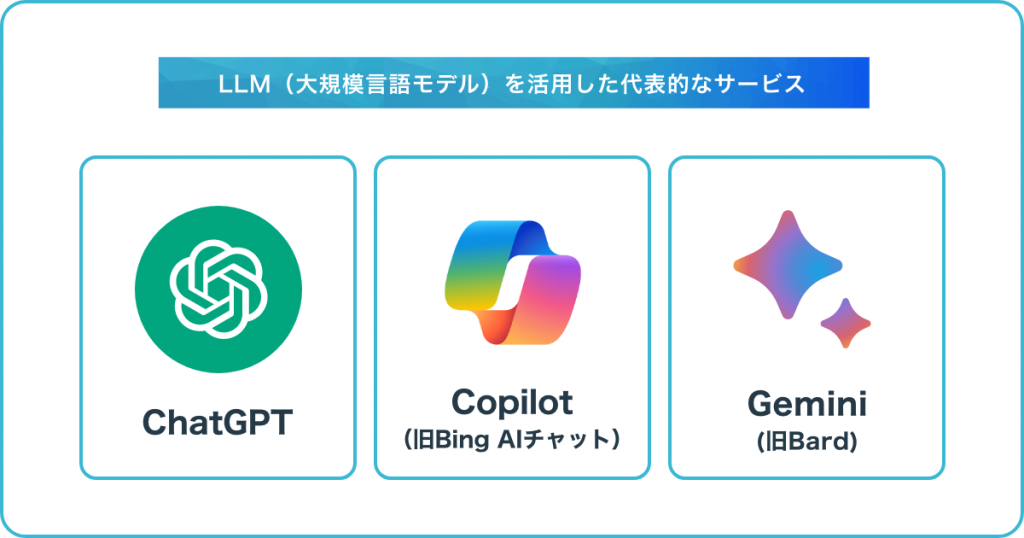
ここで、LLMの中でも知名度の高い「ChatGPT」とBingの「AIチャット」、そしてGoogleによる「Gemini」という3つのサービスについて、特徴をおおまかに紹介します。
ChatGPT
ChatGPTは、OpenAIが開発した自然な対話が可能なAIチャットサービスです。
2022年11月に公開され、わずか2か月で1億ユーザーを突破。文章生成の精度や人間味ある応答で大きな注目を集めました。
その後、GPT-4(2023年3月)や音声・画像認識対応(2023年9月)など機能が進化し、企業や個人による活用が拡大。2024年5月には「GPT-4o」が発表され、Macアプリ対応やリアルタイム対話性能の向上が話題に。さらに2024年9月には高性能モデル「o1」が登場し、学術分野での推論力も強化されました。2025年8月には「GPT-5」が発表され、さらに応答が速く、回答精度も高くなり、ハルシネーションのリスクも低くなったということです。
2025年現在、ChatGPTはテキスト・音声・画像を自在に扱えるマルチモーダルAIへと進化し、特に画像生成機能がSNSで大きな反響を呼んでいます。
ChatGPTの登録方法やアプリの詳細については、下記記事をご覧ください。
ChatGPTとは?使い方や始め方、日本語対応アプリでできることも紹介!
Copilot(旧Bing AIチャット)
Copilot(旧Bing AIチャット)とは、Microsoft(マイクロソフト)が提供する検索エンジン「Bing」に、GPT-4搭載のAIチャットを組み込んだ「Bing AI」内の機能です。
Copilotは、検索エンジンと連動しているため、リアルタイムの情報を反映しながら回答を行います。出力内容には参照ページURLが含まれており、ユーザーは参照ページにクリック1つで移行し、出力内容の効率的な事実確認を行うことが可能です。
また、AIチャットには「Bing Image Creator」とよばれる画像生成機能が搭載されており、チャットを使って画像の生成も可能です。さらにMicrsoft 365との連携により、WordやExcelなどのアプリケーション内のAI支援も可能にしています。ただ、応答回数の制限やBing自体のシェアの低さといった課題も残されています。
CopilotでできることやChatGPTとの違いなど、下記記事で解説していますのであわせてご覧ください。
Bing AIとは?新機能やCopilot(旧Bing AIチャット)の使い方・生成のコツを丁寧に解説!
Google「Gemini」

Googleが開発した「Gemini(旧Bard)」は、LaMDAと呼ばれる対話アプリケーション向けのモデルをベースにした対話型AIサービスです。世界中の幅広い知見を、LLMの知能や創造性と組み合わせることを目的として立ち上げられました。
人間のような自然な会話が可能なAIチャットシステムと、Googleの検索サービスを連携しており、インターネット上の最新情報を含む回答が可能です。
Gemini(ジェミニ)とは?料金・使い方・活用事例、アプリ最新情報を紹介
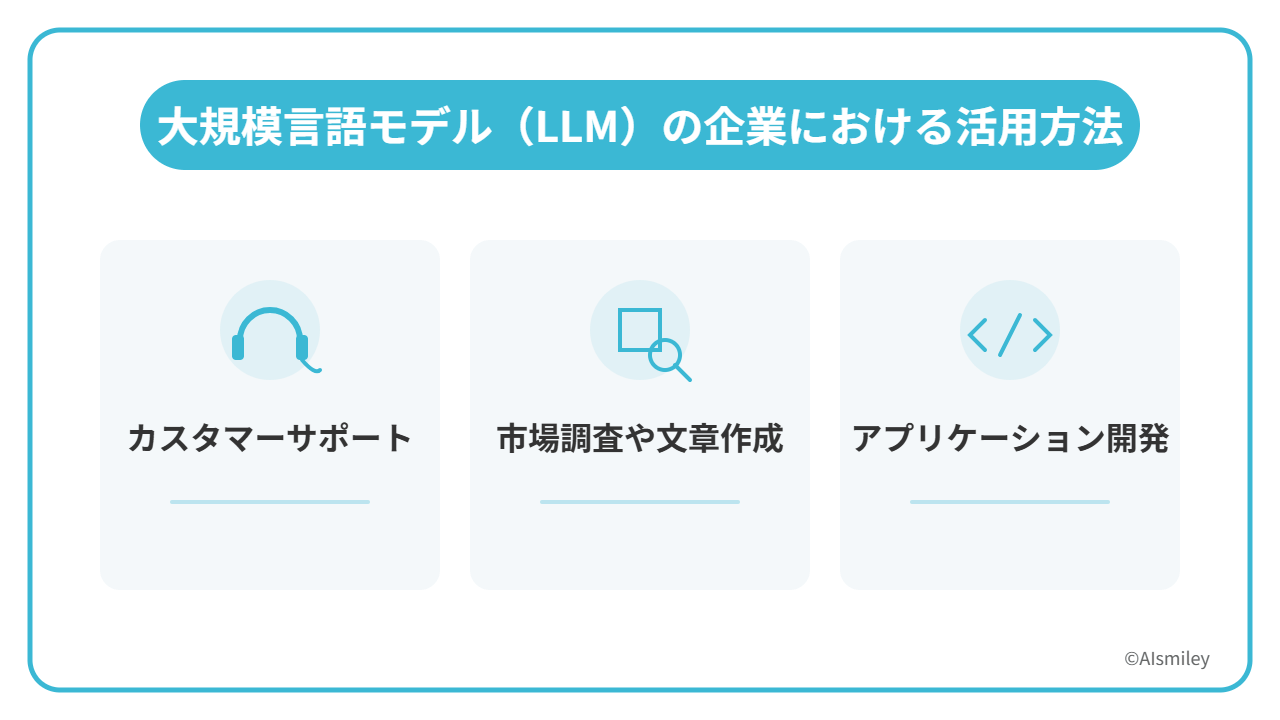
大規模言語モデル(LLM)の企業における活用方法
ここからは、企業におけるLLMの活用方法について解説します。
カスタマーサポート
LLMは、AIチャットボットとして顧客対応に活用することで、大きな効果を発揮します。
たとえば、Webサイトやアプリ上でよくある質問に自動対応することで、オペレーターの負担を軽減しつつ、迅速な対応が可能になります。
- 24時間対応: 人手では難しい深夜や休日の対応も自動で行えるため、顧客満足度の向上につながります。
- 対応品質の平準化: 感情に左右されない安定した応答が可能なため、企業ブランドの信頼性強化にも寄与します。
- コスト削減: 人的リソースの削減により、カスタマーサポート全体の運用コストを抑えることができます。
市場調査や文章作成
LLMを活用することで、情報収集から文章作成、要約、分析までを一貫して行えます。
- 調査レポートの要約: 大量のレポートやレビュー、SNS投稿などを高速で要約し、意思決定に必要な情報を瞬時に抽出できます。
- 競合分析やトレンド把握: LLMが自然言語処理で非構造化データを読み解くことで、マーケティング戦略に活用できる知見を得られます。
- SEOライティング支援: キーワード選定や構成案作成、タイトル提案など、コンテンツ制作にも応用が進んでいます。
アプリケーション開発
ソフトウェア開発分野でも、LLMはエンジニアの業務を強力にサポートします。
- コード生成支援: 自然言語で指示を出すと、自動でプログラムコードを提案してくれるため、コーディングスピードが大幅に向上します。
- バグ検出・改善提案: 過去の学習データを活用し、コード内の問題点を洗い出すことも可能です。
- ナレッジ共有: 社内で蓄積された技術ドキュメントやFAQをLLMに学習させることで、社内の情報検索を劇的に効率化できます。
メルカリの大規模言語モデル(LLM)活用事例
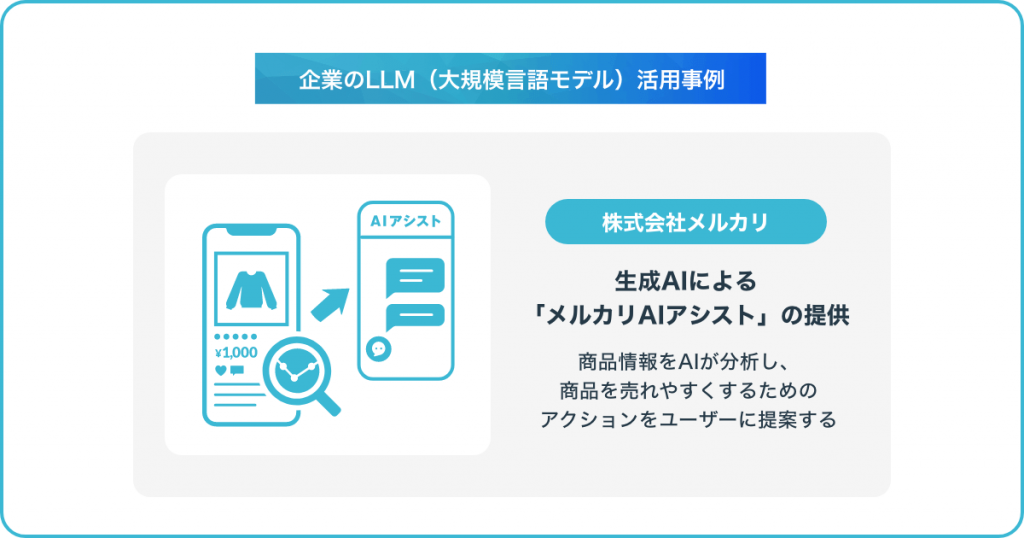
ここからは、実際に大規模言語モデル(LLM)を活用している企業の事例を紹介します。
フリマアプリで知られる株式会社メルカリでは、生成AIによる「メルカリAIアシスト」の提供を開始しました。機能の第一弾として、メルカリアプリ上の出品商品の改善提案を導入しています。
出品されている商品情報をAIが分析し、商品を売れやすくするためのアクションをユーザーに提案します。この機能により、購入者にとってより魅力的な商品情報が公開され、迅速な購入決断につながるというメリットも期待できます。
メルカリAIアシストでは、出品・購入だけでなく、メルカリを使用する際のさまざまな場面でAIによるサポートが受けられるよう機能のリリースが計画されています。
メルカリ、生成AI・LLMを活用した「メルカリAIアシスト」を提供開始
東京海上日動の大規模言語モデル(LLM)活用事例
東京海上日動火災保険は、対話型AIエージェント「スマートエージェント」を導入しました。
これまで損害保険業界では、商品の複雑さや多岐にわたる手続きにより顧客の困りごとが発生しやすく、問い合わせの途中で進め方がわからなくなり離脱する「サイレントカスタマー」への対応も課題となっています。
従来、サイレントカスタマーの存在を把握し、適切なサポートを提供することが困難であり、対応が遅れることで、売上減少やサービス改善機会の喪失につながる恐れもありました。そこで、スマートエージェントを導入し、24時間365日いつでも対応可能なサポート体制を実現。各種保険の名義変更、住所変更などの手続きフォームや契約内容確認ができるWebページ、問い合わせ窓口へ顧客を誘導します。
スマートエージェントは、顧客のWeb行動データやナレッジデータとLLMを利用して、顧客の困りごとを聞き出し、課題を理解します。それにより、適切なFAQ記事の提示や最適な問い合わせチャネルに誘導できます。
導入によって、問い合わせ対応を適切に削減でき、オペレーター負荷の軽減や、サイレントカスタマーを含む幅広い顧客からの問い合わせ傾向の正確な把握が可能となりました。また、改善すべきWebサイト導線やコンテンツ、手続きの特定、顧客課題・ニーズに基づくサービス改善の推進などの業務効率化が図れるということです。
大規模言語モデル(LLM)まとめ
大規模言語モデル(LLM)は、言語モデルのうち、大規模なデータセットを使って学習させたモデルのことです。質問への回答や文章要約、機械翻訳など幅広いタスクに応用が可能で、教育や医療など幅広い場面ではすでに利用され始めています。
ChatGPTをはじめ、多くのLLMを活用したサービスが日々登場していますが、まだ完全とはいえず、課題もいくつか残されています。ユーザー側はそのことを念頭に置いた上で、適切な使い方をする必要があるでしょう。
現在、日本語での自然な対話ができ、総合的な使用感の高いChatGPTの活用が有用です。ChatGPTのAPI連携もスタートした今、自社に最適なサービスの比較検討に以下「ChatGPT連携サービス一覧」をご活用ください。
AIについて詳しく知りたい方はこちらの記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
LLM関連の最新ニュース
AIsmileyではAIに関連するニュースをほぼ毎日更新しております。本記事で紹介しきれなかった技術や最新情報を確認することができますので是非ご活用ください。
よくある質問
LLMとはどういう意味ですか?
LLMとは、大量のテキストデータセットとディープラーニング技術を用いて構築された、機械学習の自然言語処理モデルのことです。
LLMとは大規模言語モデルのことですか?
LLM(Large Languate Models)は日本語で大規模言語モデルと訳されます。大規模言語モデルは、言語モデルにおける種別の1つで、計算量・データ量・パラメータ数を巨大化させている点が特徴です。近年では、ニューラルネットワークを用いた言語モデル(ニューラル言語モデル)が自然言語処理の分野で広く使われています。
LLMと生成AIの違いは何ですか?
LLMと生成AIはどちらも人工知能の一種です。生成AIはテキスト、画像、音声、映像などのあらゆるデータを生成できる技術の総称で、LLMはテキストに特化した生成AIの一種です。膨大なテキストデータを学習する大規模言語モデル(LLM)は、人間のようにクリエイティブな成果物を生み出せます。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- 生成AI
- ChatGPT
- Gemini
- Claude
- LLM
- AI研究開発
- 画像生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
- GPU
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI
















FOLLOW US
SNSをフォローして、最新情報をチェックできます!
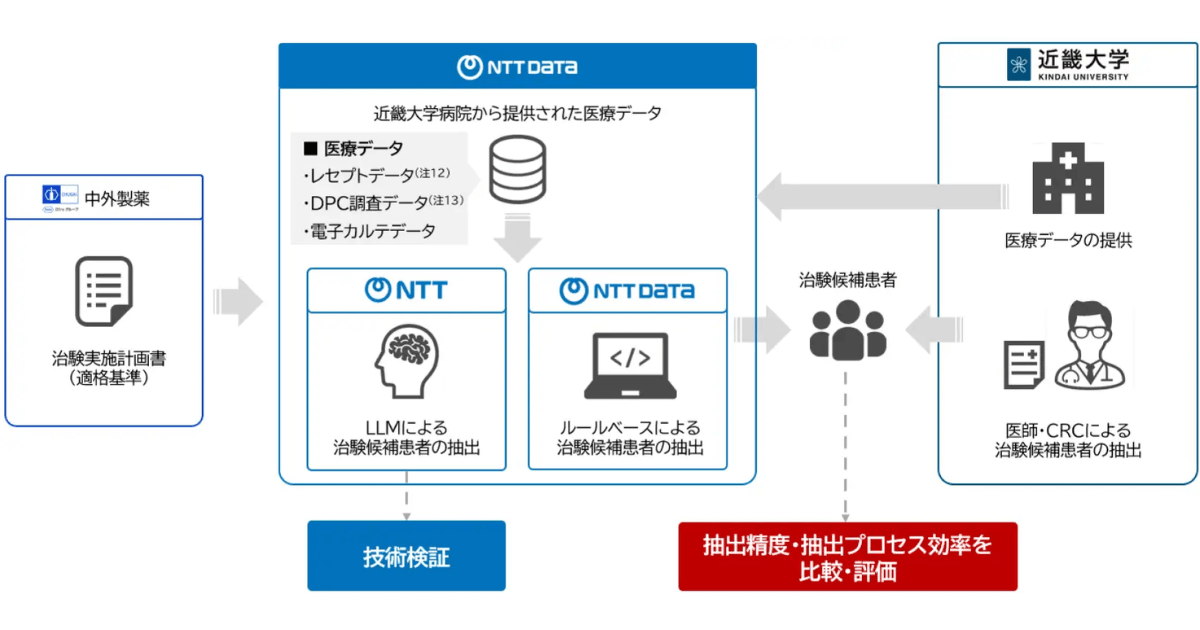
近畿大学病院など4者、リアルワールドデータとLLMを用いた共同研…

OpenAI、新世代音声モデル「GPT-Live」公開。全二重ア…

KUMON、AI活用学習サービスのatama plusをグループ…

Cloverse、アパレル特化型AI「Clovia」提供開始。撮…

ELYZA、三井住友カードで「入会審査自動判定AI」運用開始。従来審査の20%を自動化し対応時間を短縮
ノーベル賞受賞者16名含む経済学者ら200名超、AIによる経済変革への警告・対応求める声明発表

ちゅうぎんフィナンシャルグループ、「AI1,000人プロジェクト」を開始。Microsoft 365 Copilot活用で業務変革を推進

ChatGPTの共有リンクとは?作り方から削除・安全な使い方まで解説

ChatGPTでダイエットを成功させる使い方・プロンプト完全ガイド
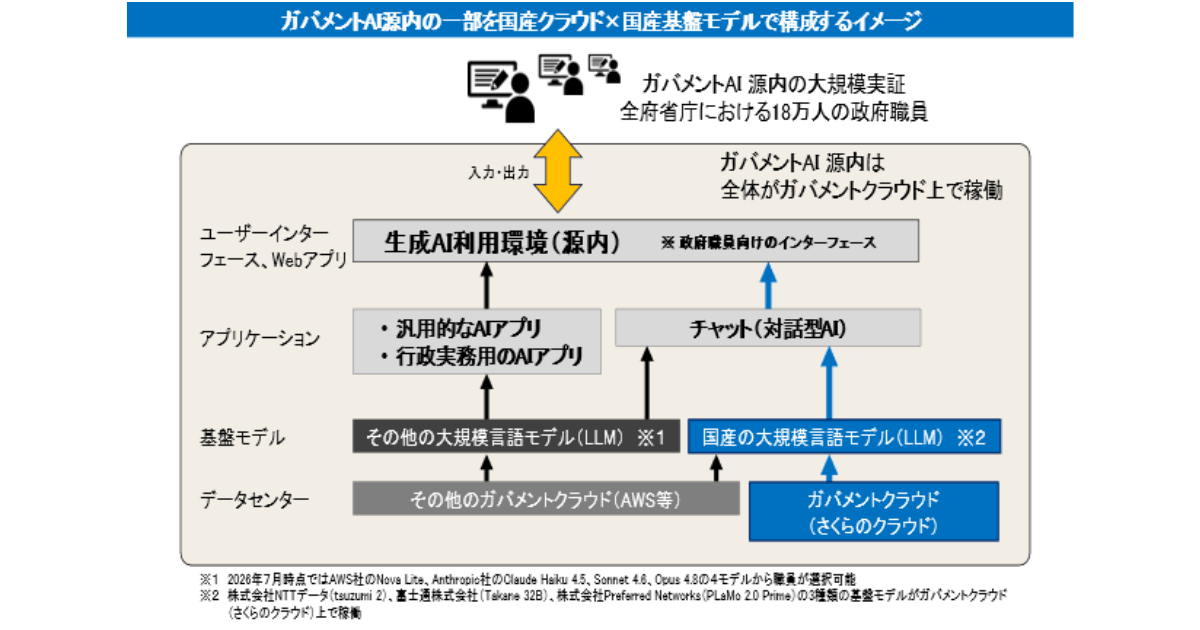
デジタル庁、ガバメントAI「源内」で国産AIの試用開始。「さくらのクラウド」で3種類の基盤モデルを検証
AI製品・ソリューションの掲載を
希望される企業様はこちら