

Claudeに学習させない設定方法と安全な使い方を徹底解説
最終更新日:2026/07/16

「Claudeに入力した内容がAIの学習に使われているかもしれない」と気になりながら使っている方は多いはずです。
この記事では、Claudeのデータ学習の仕組みから、プランごとの初期設定の違い、具体的なオプトアウト手順、企業が安全に運用するための対策まで順を追って解説します。
機密情報や個人情報をClaudeで扱う機会がある方、業務でAIを導入しようとしている担当者の方に特に役立つ内容です。
Claudeのデータ学習の仕組みと「学習させない」の意味

Claudeに何かを入力すると、その内容はAnthropicのサーバーに送信されます。この時点で「会話履歴の保存」と「AIモデルの学習への利用」という2つの処理が発生します。
会話履歴の保存とは、過去の会話を画面に表示したり、アカウントを横断して参照できるようにするための処理です。一方でAIモデルの学習とは、入力されたテキストや画像などのデータをAnthropicがAIの精度向上に活用することを指します。
Claudeに学習を許可しているユーザーが学習を止めるためには、設定画面から操作する必要があります(後述)。また、2026年現在、新規ユーザーは登録時に学習させるかどうか選択を求められるようになっています。
なお、学習利用を許可した場合はデータが最長5年間、許可しない場合は30日間保持されます。設定はプライバシー設定からいつでも変更できます。
一度学習されたデータは取り消せない
AIモデルは「重み(ウェイト)」と呼ばれる内部パラメータを調整しながら学習します。
この重みは無数のデータが複雑に絡み合って形成されるため、後から「この情報だけを削除する」「あるデータだけを上書きする」といった操作を技術的に行う手段がありません。焼き上がったケーキから卵だけを取り出せないのと同様です。
誤解されやすいのが、「会話履歴を削除する=学習も取り消される」という点です。履歴の削除は、画面上の表示を消す操作にすぎず、すでに学習に組み込まれたデータには影響しません。
設定を確認しないまま機密情報やプライバシー情報を入力してしまった場合、後からその情報を取り消す手段はありません。
唯一の対策は、入力する前に学習設定をオフにしておくことです。「入力してから設定を変える」では手遅れになります。
プランごとの学習設定とリスクの違い
2025年8月、Anthropicは個人向けのデータポリシーを変更し、会話データをAIモデルの改善に使用するかどうかについて、「オプトイン方式(許可しないと学習に使えない)」から「オプトアウト方式(拒否しないと学習に使われる)」に変更されました。
そのため、現在の新規ユーザーは登録時に学習させるかどうかを選べるようになっています。
対象はFree・Pro・Maxプランのユーザーです。Enterprise・Team・APIなどの商用プランを利用している企業ユーザーはもともと学習されないため、影響を受けません。
| プラン | 初期状態での学習 | 手動設定の要否 | 学習対象となるデータ | こんな人・用途に向いている |
| Free(無料版) | 登録時に、学習可否を確認 | 必要(登録後に変更する場合) | テキスト・添付ファイル・画像・チャット履歴すべて | 個人の趣味・学習目的。機密情報は入力しないことが前提 |
| Pro / Max(個人有料) | 登録時に、学習可否を確認 | 必要(登録後に変更する場合) | テキスト・添付ファイル・画像・チャット履歴すべて | 個人開発・フリーランス。業務利用の場合は必ず設定オフを確認 |
| Team(法人チーム) | オフ(学習なし) | 不要(契約レベルで学習除外が保証) | 基本的に学習対象外。不正利用検知目的での一時保存のみ | 企業内の共同開発・チーム利用。管理者が全メンバーの設定を一括管理可能 |
| Enterprise(大企業向け) | オフ(学習なし) | 不要(契約条件で完全保証) | 学習対象外。保持期間・削除タイミングも契約で調整可能 | 大規模組織・高度なセキュリティ要件が必要な企業。GDPR・個人情報保護法対応 |
| API経由の利用 | オフ(学習なし) | 不要(Anthropicの方針で明文化) | 原則学習対象外。ログ・エラーレポートは品質向上目的で参照される場合あり | 自社システム・アプリへの組み込み・商用サービス開発。最もセキュリティ管理が細かくできる |
なお、学習対象となるのはテキストだけでなく添付ファイルや画像データも含まれます。Claudeに入力するデータは基本的に学習対象になると理解しておきましょう。
Claudeが学習を行う目的と不正利用検知との違い
Anthropicがユーザーデータを学習に使う目的は、主に「AIの回答精度の向上」と「安全性の確保」のためです。たとえば、コーディングや論理推論の精度を高めたり、有害なコンテンツの検出システムを改善したりするために活用されます。
一方で、学習とは別に「不正利用の検知」を目的としたデータ保存も行われています。これは「利用規約に違反する使い方がないか」を確認するための処理です。
利用規約違反の疑いがある場合や、ユーザーが明示的にフィードバックを送信した場合(サムズアップ・サムズダウン)は、学習設定に関わらずデータが保存されるケースとして定められています。
つまり、学習をオフにしても「不正利用の監視のために一時的にデータが保存される」という処理は止められません。完全にデータを送らない設定にはならない点を理解したうえで利用することが大切です。
Claude・Claude Code・Coworkで学習させない設定手順

Claudeの学習オフ設定はアカウント全体に一律で適用されます。特定のチャットルームだけ設定を変えることはできません。
設定を変更した時点より前に入力済みのデータには、オプトアウトの効果は及ばないため、できるだけ早い段階で設定を確認することが重要です。
PC・スマホアプリでの学習オフの設定手順
PC版(ブラウザ版)での操作手順は次の通りです。
- 画面左下のプロフィールアイコンをクリック
- 「設定」を選択
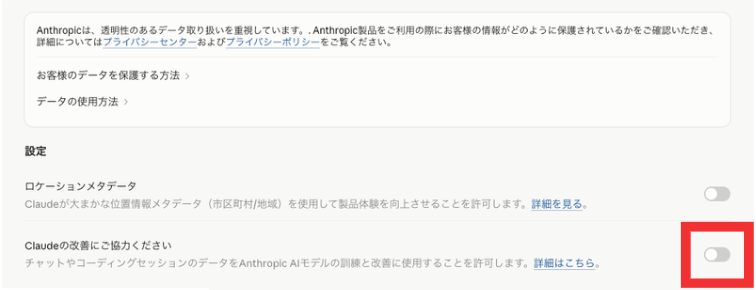
- 左メニューから「プライバシー」を選択

- 「Claudeの改善にご協力ください」というトグルをオフに
スマホアプリ(iOS・Android)の場合は、アプリ内の「設定」→「プライバシー」から同じ項目をオフにできます。
Claudeの学習設定はアカウント全体に適用される仕様であり、チャットルームごとの切り替えはできません。一度「学習させない」設定にすれば、すべての会話が対象になります。
PCとスマホの両方で確認することも推奨します。デバイスごとに設定が反映されているかを目で確認するためです。
Claude Code特有の学習防止設定と注意点
Claude Codeはターミナル(コマンドライン)上で動作するAIツールです。プロジェクトのソースコードを直接読み取るため、業務用コードが学習対象になるリスクへの対策が特に重要です。
個人プランを使っていてClaude Codeに学習させないようにするには、ブラウザからAnthropicアカウントの設定を変更する必要があります。
アカウント設定でのオフ操作に加えて、次の追加対策も有効です。
まず、/feedbackコマンドの使用を控えることです。Claude Code上でフィードバックを送信するこのコマンドを使うと、その時点の会話内容やコードが報告データとしてAnthropicに送信され、最長6ヶ月間保持されます。
次に、環境変数の設定です。CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1を設定することで、セッション品質サーベイなどを含む非必須トラフィックの大部分をオプトアウトできます。
API経由で利用する場合の学習無効化の設定
API経由での利用は、Claude Free・Pro・Maxのような一般ユーザー向けプランとは異なり、モデルのトレーニング利用の対象外とされています。自社システムやアプリにClaudeを組み込む開発者にとって、APIは学習リスクの観点から最もコントロールしやすい利用形態です。
ただし、API利用においても以下のセキュリティ設計は欠かせません。
- APIキーは厳重に管理します。GitHubなどの公開リポジトリにAPIキーをそのまま書くと、第三者に悪用されるリスクがあります。環境変数として保持し、ソースコードには直接記述しないことが鉄則です。
- 通信はすべてHTTPSで行います。HTTPの平文通信では、送受信されるデータが途中で盗み見られる可能性があります。
- 入力データのフィルタリングも検討します。APIに送信するテキストから個人情報や機密情報をあらかじめ取り除いてから送信する仕組みを設けることで、万が一の際のリスクを下げられます。
機密情報・個人情報・コードを入力する際のセキュリティリスク

学習設定をオフにしても、入力内容そのものへのリスク管理は別途必要です。
機密情報が学習対象になった場合、主に3つのリスクが生じます。
- 顧客の氏名や連絡先が学習されると、「個人情報保護法」や「GDPR」違反に問われる可能性
- ソースコードや設計仕様が学習されると、競合他社へ技術情報が渡るリスク
- 顧客データがAnthropicの管理下に入ることで、同社のセキュリティインシデント発生時に情報漏洩へ巻き込まれるリスク
設定対応と並行して、入力する情報の中身を見直すことが欠かせません。
入力前にすべき個人情報・機密データのマスキング方法
「マスキング」とは、機密性の高い情報を別の文字列に置き換えてからAIに送ることです。たとえば次のような置き換えが実践的です。
- 顧客名:株式会社〇〇 田中部長 → A社 X氏
- 電話番号:000-1234-5678 → XXX-XXXX-XXXX
- メールアドレス:tanaka@example.com → [メールアドレス]
- APIキーや認証情報:[APIキー]
ソースコードを送る際も、データベースの接続情報や認証トークンなど実際の値が含まれていないかを確認してから送信します。「この部分だけ聞きたい」というコードの一部だけを切り出して送る方法も有効です。
また、チームで運用する場合は「Claudeに入力してはいけない情報の一覧」をルールとして文書化することで、担当者によってリスク管理の水準がばらつくことを防げます。
データ削除と履歴管理でリスクを低減する方法
会話履歴の削除は、画面左側の「チャット」から行います。「チャットを選択→削除」で実行できます。特定のチャットだけ削除することも、全履歴を一括削除(すべて選択→削除)することも可能です。
アカウントごと削除したい場合は、同じ設定画面の「アカウント→アカウントを削除」から手続きできます。
ただし、削除操作をしてもデータが即座に消えるわけではありません。
Anthropicの仕様では、削除後も30日から数ヶ月程度はバックアップとしてサーバーに保持される場合があります。削除=即時消去ではない点を理解したうえで運用することが必要です。
運用の習慣としては、プロジェクトが終わったタイミングで関連する会話履歴を削除すること、週に1回程度の定期的なクリーンアップを行うことが現実的な対策です。
削除前に、後から参照が必要になりそうな内容は、ローカル(自分のPCなど)に忘れず保存しておきましょう。
Claudeの安全性とChatGPT・Geminiとの学習ポリシーの違い

Claudeは「Constitutional AI(憲法AI)」と呼ばれる設計思想をベースに開発されています。
これはAIが従うべきルールをあらかじめ明文化し、その原則に沿って回答を生成する仕組みです。有害な出力を減らすことや、安全性・倫理的な判断を優先することが設計の中心に置かれています。
そのため、データの取り扱い方針においても、この透明性重視の姿勢が反映されています。
ここでは、ChatGPTやGeminiとの学習ポリシーの違いについて確認しましょう。
| 比較項目 | Claude | ChatGPT | Gemini |
| 開発元 | Anthropic(アンソロピック) | OpenAI | |
| 設計の基本方針 | Constitutional AI(憲法AI)により安全性・倫理観を最優先に設計。有害な回答やバイアスを生成しにくい構造 | 幅広い用途への対応と自然な会話を重視した設計 | Google製品・サービスとの連携を重視した設計 |
| 無料プランの初期状態 | 学習への参加はユーザーが選択する。登録時に選択を求められる | 学習オン(設定でオフに変更可能) | 個人Googleアカウント利用ではGoogleのプライバシーポリシーに基づきデータが活用される |
| 学習オフの設定方法 | 設定→プライバシー→「Claudeの改善にご協力ください」をオフ | 設定→データコントロール→「すべての人のためにモデルを改善する」をオフ | Googleアカウント設定またはGeminiの設定から「アクティビティ」をオフに変更 |
| オフにした際の影響 | 全チャットが一律で学習対象外になる。チャット履歴は引き続き利用可能 | 全チャットが一律で学習対象外になる。チャット履歴は引き続き利用可能 | アクティビティ無効化で履歴が保存されなくなる |
| チャット単位での制御 | 不可(アカウント全体に一律適用) | 可(「Temporary Chat」機能で履歴を残さずに1回限りの会話が可能) | 不可(アカウント全体に適用) |
| 法人プランでの初期状態 | Team・Enterpriseは契約レベルで学習除外が保証。デフォルトで非学習 | ChatGPT Enterpriseは学習しないことが明確に保証 | Google Workspace有料版(Gemini Business/Enterprise/Education)は学習対象外が保証 |
| API利用時の学習 | 「原則として入力データをモデルの学習に使用しない」と明言 | 原則として学習対象外(APIリクエストは訓練に使用しない) | Google Cloud Vertex AI経由はデフォルトで学習対象外 |
| 企業導入時の安心感 | ◎ 最初から非学習を前提とした設計。API・法人プランで透明性が高い | ○ 法人プランで保証。個人プランは設定変更が必要 | ○ Workspace利用なら保証。個人アカウントでは注意が必要 |
| 特定のベンダー依存 | 低い(Amazon Bedrock・Google Vertex AI経由でも利用可能) | 中程度(OpenAI依存) | 高い(Googleサービスとの統合が前提) |
ChatGPTの学習設定との比較
ChatGPTの無料版および有料版のChatGPT Plusでは、デフォルト設定で入力データが保存され、OpenAIのモデル改善のために使用される可能性があります。ただし、ユーザー側で設定を変更することで学習をオフにできます。
ChatGPTでは設定画面から「データコントロール→すべての人のためにモデルを改善する」をオフにすることでオプトアウトが可能です。履歴を無効にすると過去のチャットも参照できなくなる仕様です。
Claudeでは会話履歴の表示と学習の設定が独立しているため、「過去の会話を見ながら学習だけオフにする」という使い方が可能です。
企業向けのChatGPT Enterprise・Team、およびAPI経由での利用はいずれも学習対象外とされており、この点はClaudeと共通しています。
GeminiおよびほかのAIとの学習ポリシーの比較
Geminiのアプリを利用する際、対象となるGoogle Workspaceエディションをお持ちでないユーザーのチャットは人間のレビュアーによって確認され、Googleのサービスや機械学習技術の改善のために使用される場合があります。
ただし、個人向けの無料版でもGeminiの設定から「Geminiアクティビティ」を、またはGoogleアカウントの設定から「Googleマイアクティビティ」の「ウェブとアプリのアクティビティ」をオフに変更すると、今後のチャットは学習に利用されなくなります。
一方、Gemini for Google Workspaceライセンスを持つユーザーがGeminiアプリを使用すると、エンタープライズグレードのデータ保護が適用され、送信されたデータはモデルのトレーニングには使用されず、人の目による審査も行われません。
3サービスを比較すると、個人向けの無料・有料プランはいずれもデフォルトで学習対象となるケースが多く、法人向けプランやAPI利用では学習対象外となる設計が共通しています。
「最初から非学習を前提」としているClaudeは導入時の安心感が高く、セキュリティポリシーが厳しい企業から選ばれやすいといえるでしょう。
企業がClaudeを安全に導入・運用するためのセキュリティ対策

個人利用であれば設定画面のトグルをオフにするだけでリスクを下げられますが、企業での導入はそうではありません。
社員一人ひとりの設定任せにすると、設定を知らない社員・設定を忘れた社員・退職後もアカウントが残っている社員など、管理しきれない穴が必ず生まれます。
企業単位での対策には、法人プランの契約・社内ガイドラインの策定・社員教育・API活用の4つを組み合わせることが必要です。
企業向けTeam・EnterpriseプランとAPI活用の選び方
TeamプランはデフォルトでAI学習にデータを使用しないことが契約レベルで保証されており、個人アカウントのように社員が各自で設定を変更する必要がありません。
管理者画面からメンバー全員のアクセス権限を一括で管理でき、退職者のアカウント停止も一元的に行えるため、人事異動が多い組織でも設定の抜け漏れが起きにくい構造です。
さらに高いセキュリティレベルが必要な場合は、Amazon BedrockやGoogle Cloud Vertex AI経由でClaudeのAPIを利用する方法があります。
Anthropicへのデータ学習利用は商用条件のもとで行われないため、データの流通経路をクラウド契約の範囲内に収めたい組織に適しています。
社内利用ルールと継続的なセキュリティ管理の進め方
プランを整えた後に必要なのが、社内ルールの明文化です。「何を入力してよいか・何を入力してはいけないか」を具体例つきで示したガイドラインを作成します。
たとえば、「顧客の氏名・連絡先・契約金額は入力禁止」「社内資料を貼り付ける場合は固有名詞をA社・B氏に置き換える」といった粒度で記載することで、判断に迷う場面を減らせます。
運用面では、入社時の研修でガイドラインを説明すること、月に一度は管理者が設定状況を確認する監査を行うこと、万が一機密情報を誤入力した際の報告・対応手順をあらかじめ決めておくことの3点が基本的な柱になります。
また、ガイドラインは一度作って終わりではありません。AnthropicはAIのアップデートに合わせてデータポリシーを変更することがあるため、半年に一度は公式ドキュメントを確認し、ガイドラインを見直す習慣が必要です。
あわせて注意したいのが「シャドーIT」のリスクです。会社が承認していない無料のAIツールを社員が個人的に使い始めるケースは、Claude以上にデータ管理が難しい状況を生み出しかねません。
社員が「なぜ社内ルールが必要か」を納得できるよう、リスクの中身を丁寧に伝えることが、ルールを機能させるうえで欠かせません。
まとめ
Claudeに学習させない設定は、プライバシー設定画面のトグルをオフにするだけで完了します。ただし、設定変更前のデータには効果が及ばないため、使い始めるタイミングで確認することが大切です。
プランごとの初期状態を整理すると、Free・Pro・Maxは手動でオフにする必要があり、Team・Enterprise・APIはデフォルトで学習対象外です。Claude Codeを使う場合は、設定画面でのオフに加えて環境変数の設定も行うことで、より確実にデータ送信を制限できます。
設定の対応と並行して、入力する情報そのものを見直すことも重要です。個人情報や認証情報はマスキングしてから送る、不要な履歴は定期的に削除するといった運用習慣が、設定だけでは防ぎきれないリスクを補います。
企業での導入では、プランの選択だけでなく社内ガイドラインの整備・社員教育・定期監査がセットです。まず自分のアカウントの設定を今すぐ確認し、業務での利用範囲に合わせた対策を一つずつ進めていきましょう。
アイスマイリーでは、生成AI のサービス比較と企業一覧を無料配布しています。課題や目的に応じたサービスを比較検討できますので、ぜひこの機会にお問い合わせください。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- 生成AI
- ChatGPT
- Gemini
- Claude
- LLM
- AI研究開発
- 画像生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
- GPU
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI












FOLLOW US
SNSをフォローして、最新情報をチェックできます!

富士通、大規模言語モデルの大幅なコスト削減を実現するアーキテクチ…

Anthropic、Slack上で動作する新機能「Claude …

Noetra、国産マルチモーダル基盤モデルの研究開発を本格始動。…
ノーベル賞受賞者16名含む経済学者ら200名超、AIによる経済変…

Codex MCP完全ガイド:基礎知識から実践的な使い方・ツール連携まで徹底解説

アイスマイリー、8/5(水)から2日間、「AI・人工知能EXPO NEO」にブース出展

つながりAI、横浜市でAI相談サービス「友達AI」実証実験を開始。夏休みの子どもの孤立・SOSに対応

フォーティエンス、財務課題をAIで可視化する「次世代トレジャリー対面型クイック診断」提供開始

みずほFG、金融機関向けAI活用基盤高度化の検討を開始。AIエージェント活用拡大に向けNVIDIA技術を活用

ビジネス職のAI活用調査を実施。AIエージェント化で生産性が上がったのは54%でチャット層の約3.8倍
AI製品・ソリューションの掲載を
希望される企業様はこちら