

Claude Opus 4.8とは?4.7からの進化点・新機能・料金を徹底解説
最終更新日:2026/06/23

Anthropicは2026年5月28日、Opusシリーズの最新モデル「Claude Opus 4.8」を公開しました。ベンチマーク全般での性能向上に加えて、自らの作業の不確実性を申告する「正直さ」や長時間タスクの自走など、実務における信頼性に直結する改善が盛り込まれています 。
本記事では、Claude Opus 4.8の主要なアップデートをはじめ、4.6からのバージョン系譜、料金体系や導入手順、他社モデルとの比較までを整理します。生成AIの業務導入に向けて最適なモデルを検討するための判断材料としてぜひご活用ください 。
Claude Opus 4.8とは
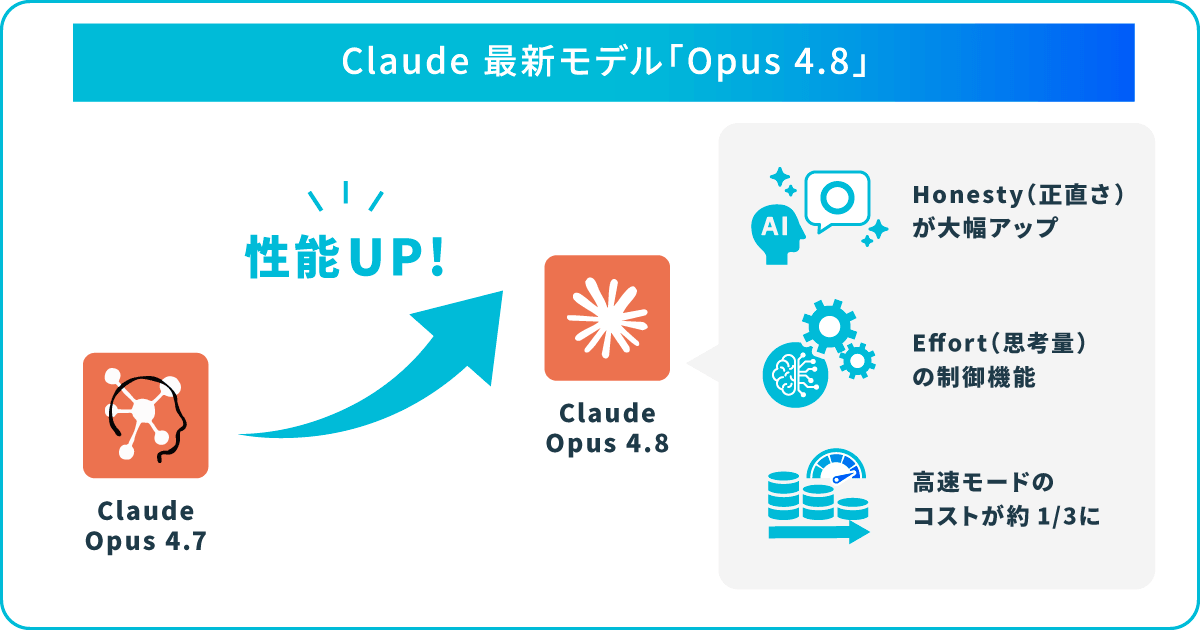
Claude Opus 4.8は、Anthropicの最上位ティア「Opus」の最新モデルです。前世代モデル(Opus 4.7)のリリースからわずか約6週間という異例の速さで登場し、ソフトウェア開発やエージェント型業務を担う常用モデルとして位置付けられています 。
提供チャネルは幅広く、Claude.aiおよびアプリ(Pro / Max / Team / Enterprise)、開発者向けのClaude Platform(API)に加え、Amazon BedrockやGoogle CloudのVertex AIでも利用できます 。
4.6→4.7→4.8のバージョン系譜
Opusシリーズの4.6から4.7へと更新された際に、タスクに必要なツール呼び出しを飛ばすケースや、生成コードのコメントが冗長になる傾向などがユーザーより指摘されました 。
そこで、4.8はこの2点を含めて改善し、4.6の長所を引き継ぎつつ、より少ない手順でタスクを最後まで完遂できるよう仕上げられています。同社の評価によれば、生成コードの不具合を見逃す割合が4.7の約4分の1まで低下したとされています 。
関連記事: Claude Opus(4.7)とは?最新モデルの特徴・性能・導入メリットを徹底解説
Opus 4.7からの主なアップデート
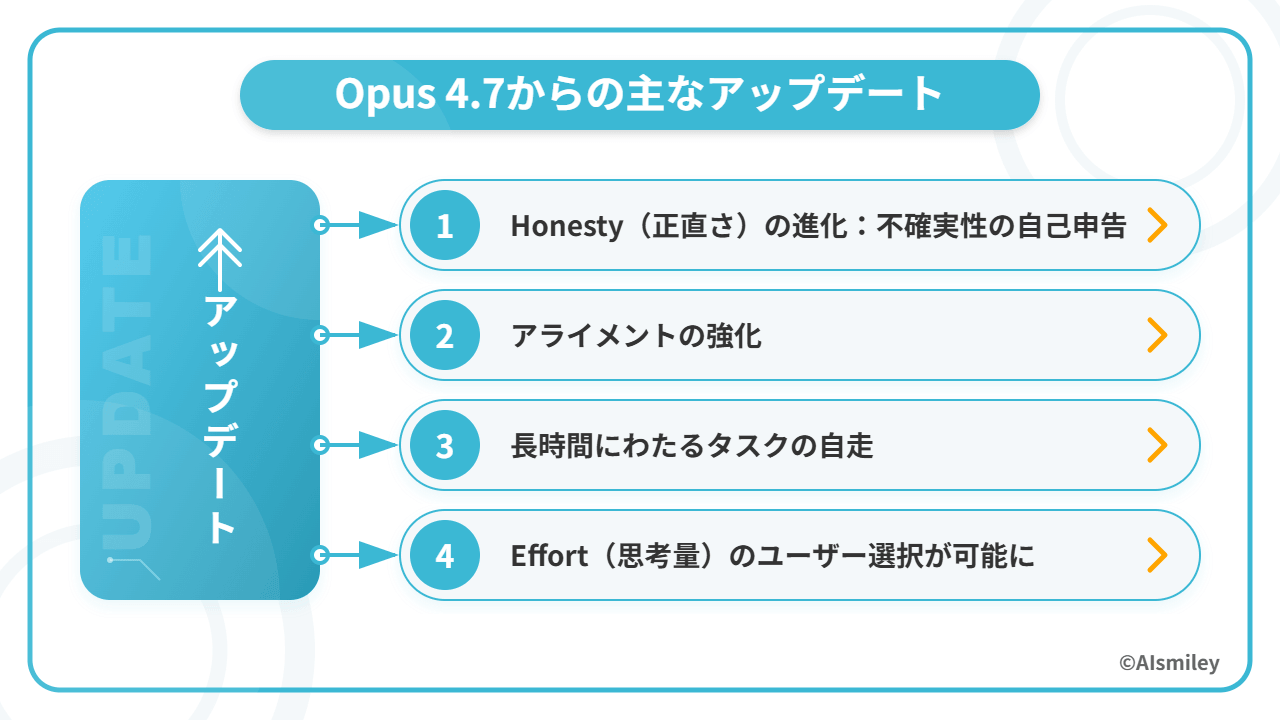
同モデルは、4.7との差別化というよりも実務での改善を実現したアップデートモデルと言えます。ここでは、主要なアップデートについて「正直さ」「アライメント」「長時間タスクの自走」「Effortの選択」の4点から解説します 。
Honesty(正直さ)の進化:不確実性の自己申告
Opus 4.8における最大の改善点が「Honesty(正直さ)」です。AIモデルでは、根拠が薄いにもかかわらず、タスク完了の結論を急ぐ傾向が多く見られました。今回のアップデートによって同モデルは自分の作業の不確実性を自己申告するようになり、裏付けのない主張をするケースが削減されています 。
Anthropicは、生成コードの欠陥を見逃す確率が前モデルの約4分の1まで低下したと公表しています。AIの出力を鵜呑みにしない前提は変わりませんが、誤りを見落とすリスクが下がったことで、人間のレビュー・確認における工数削減につながります 。
アライメントの強化
アライメント(人間の意図や利益との整合性)が強化されています。同社のアライメント評価チームは、同モデルが「ユーザーの自律性の尊重」「最善の利益に沿った行動」といった社会的な特性で過去最高水準に達したと報告しています 。
一方で、悪用や不整合な振る舞いの発生率は、前モデルより大幅に低下しました。同社が最もアライメントの取れたモデルと位置付ける「Claude Mythos(Preview)」と同等水準とも言われています 。
長時間にわたるタスクの自走
前モデルに比べて、独力で長時間の作業を継続できるようになり、タスクの安定した自走が可能になりました。コンテキストの圧縮回数が低減され、圧縮後の作業復帰が安定したことで、長い文脈の扱いも改善されています 。
その結果、途中で文脈を見失って手戻りが発生するなど、長時間タスク特有の失敗が起きにくくなっています。後述するDynamic Workflowsと組み合わせれば、大規模な作業を人間の細かな介入なしに最後まで完走できる可能性が高まります 。
Effort(思考量)のユーザー選択が可能に
応答にどれだけのEffort(思考量)を費やすかを、ユーザー自身で選択できます。デフォルトは、品質と速度・コストのバランスが最も取れる設定「high」です。これは、前モデルのデフォルトと同程度のトークン消費で、より高い性能を発揮できるとされています。
より難しいタスクでは、さらに上位のextra(Claude Codeではxhigh)やmaxも向いています。Effortを高くすると品質は上がりますが、消費トークンとコストも増えるため、予算やタスク難易度を考慮して決めることが重要です 。
同時アップデート

同モデルの公開に合わせて、モデル本体以外にもアップデートが同時提供されました。ここでは開発・エージェント用途に関わる2つの変更点を紹介します 。
Dynamic Workflows
Dynamic Workflowsとは、Claude Codeでより大規模なタスクを実行するための機能です 。
この機能により、Claudeが自ら作業計画を立案し、1つのセッション内で数百のサブエージェントを並列駆動させ、結果の検証までを一気通貫で行えるようになります。
Anthropicは具体例として、数十万行規模のコードベース移行を、着手からマージまで既存テストを基準に完遂可能だとしています。現在は研究プレビューですが、同モデルでは必要なサブエージェントをより長く稼働させられます 。
Messages APIのシステムエントリ
Messages APIの仕様も更新されました。ユーザーの入力の直後に「role: “system”」のメッセージを配置できるようになったため、システムプロンプト全体を書き直さずに指示を追加・更新できます 。
エージェントのループ処理で、先行ターンのプロンプトキャッシュを維持したまま指示を差し込めば、入力コストの削減につながります 。
料金とコストの最適化

同モデルは、Claudeの有料プラン(Pro / Max / Team / Enterprise)にて提供され、無料ユーザーは選択できません。API料金の課金体系は標準モードとFastモードの2種類が用意されています。また、プロンプトキャッシュとバッチ処理でコストを抑える仕組みもあり、費用削減に役立ちます 。
API料金:標準モード・Fastモード
APIでの利用は従量課金制で、料金体系は以下の通りです 。
| 料金区分 | 入力(100万トークンあたり) | 出力(100万トークンあたり) |
| 標準モード | $5 | $25 |
| Fastモード | $10 | $50 |
前モデルから性能が向上しながらも、価格が変わらないため、同じ仕事をするコストは実質下がる計算です。一方、応答速度が約2.5倍のFastモードの料金は標準モードの2倍ですが、前世代のFastモード比では約3分の1に低下しています 。
単価が高い分、常用するとコストがかさみやすいため、用途を絞った使い分けをおすすめします 。
コストを抑える仕組み
継続利用において、ランニングコストを大幅に抑えられる仕組みが用意されています。プロンプトキャッシュでは、同じ文脈を繰り返し送るワークロードで、キャッシュ読み込みの単価が標準入力の約1割まで下がります。100万トークンあたり$0.50で使える計算です 。
また、バッチ処理では即時応答が不要なジョブをBatch APIに回すことで、標準料金の約半額(入力$2.50・出力$12.50)になります。エージェントの反復処理や大量バッチでは、こうした対策を取ることでコストの節約が可能です 。
始め方とAPIキーの取得手順

ここからは、同モデルを実際に使い始める方法を紹介します。仕様や使い勝手を試したい場合はClaude.aiやアプリ、組み込みならAPI、既存クラウド経由ならBedrockやVertex AIが適しています。
ここでは3つの手順について説明します 。
Claude.ai・アプリで使う手順
ブラウザ版Claude.ai またはデスクトップ / モバイルアプリは、最も手軽な方法です。基本的な操作手順は以下の通りです 。
- アカウントを作成してログインする
- チャット画面のモデルからOpus 4.8を選ぶ
- Effort(思考量)を指定する
すでにClaudeを使用している場合は、いつもの対話画面でモデルを変えることで、すぐに試せます 。
APIキー取得とモデル指定
自社サービスへ組み込むなら、Claude APIが便利です。ただし、使用にはAnthropicのコンソール(Developer Platform)でAPIキーを発行する必要があります。キーを入力し、リクエストのモデル名を指定すれば、モデルの呼び出しが完了します 。
既存クラウド経由(Amazon Bedrock / Vertex AI)
AWS や Google Cloudを利用している場合、各基盤から同モデルの呼び出しが可能です。Bedrockや Vertex AIでは、各基盤でモデルアクセスを有効化し、認証情報を用意します 。
ただし、モデルIDが基盤ごとに違う点に注意が必要です。具体的には、Bedrockはリージョン付きIDで、Claude APIとVertexとは異なるため、流用するとエラーになる可能性があります 。
職種別 Claude Opus 4.8 の使い方

Claude Opus 4.8の職種別の使い方を見ていきましょう。ここからは、エンジニア・Web制作・ライター・データ分析の4職種について、タスク例と新機能・特性の効果的な活用について解説します 。
エンジニア
エンジニアの業務では、大規模なリファクタリングやコード移行で同モデルが活躍します。Dynamic Workflowsを使って作業計画を立て、数百のサブエージェントを並列実行する場合に、Effortをhighやextraに上げることで、数十万行規模のコードベース移行も効率的に進められます 。
また、長い文脈を保ったまま複数ファイルを横断できるため、ツール呼び出しの漏れが減り、手戻りの削減が期待できます 。
Web制作
Web制作では、長時間タスクにおける文脈とスタイルを維持しやすく、業務効率化が可能です。サイト全体のトーンや要素の命名規則、デザイン方針はそのままに、複数のWebページや構成要素の実装・修正を継続的に行えます 。
また、途中で文脈の圧縮が起きても作業復帰が安定するため、長いセッションでも当初の設計意図やコーディング規約から外れることなく完成できる点も利点です。一貫したスタイルを保って、制作業務を円滑に進められます。
ライター
ライティングでは、長文の一貫性と文体・トーンを維持した作業が可能です。文章量の多い記事でも、主張や用語、語り口がぶれにくく、書き手のトーンを保ったまま文書や記事を生成できます 。
また、Effortの使い分けによって工程を分業できます。下書きはEffortを下げて素早く量を出し、推敲や構成の練り直しは Effort を上げて精度を取る、といった切り替えにより品質とスピードを最適化できます 。
データ分析
データ分析では、多様な基準での分析結果の整理にかかる時間と手間を削減できます。同じデータでも、観点や評価軸を変えた複数の切り口で結果をまとめ直す作業を任せられます 。
また、正直さの改善により、根拠が薄い結論を断定するケースが減ったため、不確実な点を申告し、分析の確度を確かめやすくなっています。レポート化や複数条件での再集計を繰り返す業務フローにおいて、作業負担の軽減につながります 。
GPT-5.5・Gemini 3.1 Proとの比較
競合モデルであるGPT-5.5、Gemini 3.1 Proと同モデルの比較を見ていきます。Anthropicが公開しているベンチマークデータを以下表にまとめました 。
| ベンチマーク | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
| SWE-bench Pro(実リポジトリのコード修正) | 69.2% | 64.3% | 58.6% | 54.2% |
| SWE-bench Verified(GitHub課題500問) | 88.6% | 87.6% | 約82%※ | 80.6% |
| Terminal-Bench 2.1(CLI・シェル作業) | 74.6% | 66.1% | 78.2% | 70.3% |
| USAMO 2026(証明数学) | 96.7% | 69.3% | ー | ー |
実リポジトリのコード修正を測る SWE-bench Proでは、Opus 4.8が69.2%で、GPT-5.5 やGemini 3.1 Pro を10ポイント以上上回っています。一方、CLI・シェル作業のスコア(Terminal-Bench 2.1)では、GPT-5.5がトップスコアです 。
用途・シーンでの使い分け目安
1つのモデルで統一するより、得意分野で各社の最新モデルを使い分けた方が費用対効果は高まります。Claude Opus 4.8は、エージェント作業や複数ファイルを横断するコーディング作業、長文の一貫性が求められるタスク、「正直さ」重視の場面などにおいて高い精度が期待できます 。
一方、GPT-5.5 はターミナル・CLI作業や構造化された推論・学術タスクに、Geminiシリーズはマルチモーダルや速度・コスト重視の大量処理に強みがあります。タスクの性質に応じて適切なモデルへ振り分けるやり方が、現実的かつコスト効率の良い運用につながります 。
【開発者向け】ベンチマークと性能
開発者向けに、主要ベンチマークをもう少し細かく見ます。Opus 4.8は、SWE-bench Proで69.2%(4.7は64.3%)、SWE-bench Verifiedで88.6%と、コーディング系で前モデルと他社を引き離しています 。
また、難関推論のHumanity’s Last Exam(ツールあり)でも他社を上回り、証明数学のUSAMO 2026では96.7%(4.7は69.3%)と大幅に向上しました。一方、GPQA Diamondは93.6%で、統計的に他社とほぼ同等です 。
移行・導入時の注意点
4.7 から 4.8への移行・導入は比較的スムーズで、既存実装は大きな修正なく継続可能だと予測されます。一方で、コストや安定性に響くポイントもあるため、本番環境での運用前に、プレビュー段階の機能と想定外のコスト増を確認しておきましょう 。
Dynamic WorkflowsとFastモードはプレビュー
Dynamic WorkflowsとFastモードは、いずれも現時点で研究プレビュー段階です。プレビュー機能は今後、仕様や挙動が変わる可能性があり、出力精度やコストの安定性に影響を及ぼす可能性があります 。
本番環境でのワークフローに全面採用するのではなく、一部の業務で試しながら挙動とコストを確認し、段階的に広げる進め方が無難です。正式提供までの間は、代替手段となる業務フローやシステムも検討、用意しておくと安心です 。
想定外のコスト増加に注意
すべてのタスクをデフォルトのEffort(high)設定で回した場合、消費トークンが増えてコストが膨らむ可能性があります。簡単なタスクは低めのEffortでも十分処理できるため、タスクの難度に応じて Effortを切り替えることが重要です 。
また、Fastモードの常用も総額が跳ね上がりやすい点に注意が必要です。プロンプトキャッシュやバッチ処理を併用するなど、トークン消費を監視する仕組みの構築を検討しましょう 。
今後の展望
同モデルは単発のリリースではなく、Anthropicのロードマップの一部として提供されています。ここでは公式が示す今後の方向性について、執筆時点の状況とあわせて整理します 。
公式が示すロードマップ
同社は、同モデルと同等の能力をより低コストで提供できるモデルの開発を進めることを発表しています。Opusは最上位ゆえに単価が高く、用途によっては費用が見合わないことも考えられます。同等性能を安く使えるモデルが出れば、低価格帯で処理していたタスクもClaudeで一貫して扱えます 。
Fable 5:Mythos級の一般公開とその後の停止
Opusのさらに上位にあたるのが Mythosクラスです。2026年6月9日、同社はその一般公開版として、安全対策を強化した「Claude Fable 5」を提供開始しました。しかし提供開始のわずか3日後、6月12日に米国政府の輸出管理指令を受けて、アメリカ国外からのFable 5のアクセスが停止されました 。
現時点での再開時期は未定ですが、Opus 4.8を含む他モデルは通常どおり利用できます 。
関連記事: Claude Fable 5とは?性能・料金・使い方やMythos 5との違いを解説
まとめ
Claude Opus 4.8は、前モデルからの「実務における信頼性の底上げ」を実現したモデルです。正直さの向上により自身の誤りの見逃しが減り、長時間タスクの自走やEffortの選択も加わりました 。
API料金(標準モード)は4.7から据え置きで、性能向上を踏まえると実質的なコスト低下と言えます。Claude.aiやアプリ、APIの他、BedrockやVertex AIでも利用でき、既存の4.7実装ともほぼ互換です 。
自社業務への組み込みをより詳しく検討したい場合は、アイスマイリーによる「生成AIサービスの比較と企業一覧」で情報を総合的に比較検討できます。下記より無料でご請求いただけますので、ぜひこの機会にご活用ください 。
アイスマイリーでは、生成AI のサービス比較と企業一覧を無料配布しています。課題や目的に応じたサービスを比較検討できますので、ぜひこの機会にお問い合わせください。
よくある質問
4.7から乗り換えるかどうかの判断基準は?
料金は据え置きで性能が上がり、APIの使い方もほぼ互換のため、基本的には乗り換えを推奨できます。コーディング系の指標は向上し、正直さやアライメントも改善しており、さらなる業務効率化が期待できます 。 ただし、出力の傾向は変わるため、一定期間は2つのモデルを並走させ、実タスクで出力を見比べてから移行するのが最適です 。
Fastモードは常時ONにすべき?
コストが高くなりやすいため、Fastモードの常時ONは推奨しません。Fastモードは応答速度が約2.5倍になる代わりに、単価が標準の2倍です。対話型のコーディング支援やチャット製品のような、速さがユーザー体験に直結する場面では費用対効果は高まりやすいですが、即時性が不要な処理では割高になります。速度が必要な用途に絞って使用するのが合理的でしょう 。
既存の4.7向けプロンプトやAPI実装はそのまま使える?
同モデルの基本的な使い方は前モデルとほぼ互換です。また、APIの構造やパラメータ制約もさほど大きく変わっておらず、多くの実装はモデル名を変えるだけで動きます。ただし、コメントの簡潔さや正直さなど出力の傾向は変化します 。 既存のプロンプトが前モデルに最適化されている場合、同程度の出力にならないケースもあります。主要なプロンプトで確認し、必要な微調整を行いましょう 。
- AIサービス
- 生成AI
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI














FOLLOW US
SNSをフォローして、最新情報をチェックできます!

リコーとライズ・コンサルティング・グループ、AI実装・活用を一貫…
近畿大学病院など4者、リアルワールドデータとLLMを用いた共同研…
LINEヤフー、「LINE」新機能「Agent i in cha…
Sakana AI、「Sakana Chat」に翻訳機能を追加。…
NEC、Anthropic協業による「NEC AIインサイトレポーティングサービス」提供開始。商品企画や販促プラン作成を自動化

オムロン、ケアプラン作成支援AI機能「With.Ai」開発。最短10分で作成、業務時間80%以上削減

GitHub Copilot CLIとは?インストール・使い方・料金を解説

Copilot Keyboardとは?インストール・設定・使い方を徹底解説

SpaceXAI、最新モデル「Grok 4.5」を提供開始。コーディング能力とエージェントタスクの性能を強化

ChatGPTの育て方とは?自分好みに育てる方法とコツを解説
AI製品・ソリューションの掲載を
希望される企業様はこちら