

Transformer(トランスフォーマー)とは?深層学習の仕組みや特徴・応用モデルをわかりやすく解説
最終更新日:2025/05/07
 Transformerとは?
Transformerとは?
近年、ChatGPTをはじめとする自然言語処理AIが大きな注目を集めています。これらのAIの根幹となっている技術が、深層学習モデルの「Transformer」です。本記事では、Transformerとはどのようなものか、その仕組みや特徴、そしてTransformerを応用した代表的なモデルについてわかりやすく解説します。
Transformerの理解を深めることで、ChatGPTをはじめとする最新のAI技術をより身近に感じられるはずです。
Transformer(トランスフォーマー)とは
![]()
Transformerは、2017年にGoogleの研究者らによって発表された、ニューラルネットワークの一種です。元々は機会翻訳などの系列変換タスクを想定して開発されましたが、その後ChatGPTのベースとなる技術として大きな注目を集めました。
Transformerの大きな特徴は、「Attention Mechanism」を主体に処理を行う点にあります。従来のニューラルネットワークとは異なるアプローチにより、高い精度と効率性を重視しています。
Attention Mechanismとは
Attention Mechanismは、Transformerの中核をなす機構です。系列データ(テキストや音声など)の各要素と他の要素との関連性を計算し、重要な情報に「注意(Attention)」を向けることで、文脈理解を行います。
例えば文章の場合、各単語が文章全体の中でどのような役割を持っているかを把握します。これにより、単語の表層的な意味だけでなく、文脈に応じた適切な解釈が可能となります。
系列変換のニューラルネットワークとは
系列変換とは、ある系列データを別の系列データに変換するタスクのことを指します。代表的な例が機械翻訳で、ある言語の文章を別の言語の文章に変換します。他にも、文章の要約や文章生成(短い入力から長い文章を生成)なども系列変換リスクと言えます。
これらのタスクを処理するために設計されたニューラルネットワークが、系列変換のニューラルネットワークです。Transformerは、この系列変換タスクにおいて非常に高い性能を発揮することが知られています。
Transformerの仕組み
![]()
Transformerは大きく分けてエンコーダとデコーダの2つの部分から構成されています。エンコーダが入力系列を処理し、デコーダが出力系列を生成します。この2つが連携することで、系列変換タスクを遂行します。
エンコーダの仕組み
エンコーダは、入力された系列データ(例えば文章)を処理する役割を担います。具体的には、以下のようなステップで処理が進みます。
- 入力文章を単語に分割
- 各単語を単語埋め込み(Word Embedding)によりベクトル化
- Self-Attentionにより、各単語との他の単語との関連性を計算
- 全結合層(Feedforward Neural Network)により特徴量を変換
Self-Attentionが単語間の関係性を捉えることで、文章全体の文脈を考慮した単語の表現を得ることができます。
デコーダの仕組み
デコーダは、エンコーダの出力を受け取り、出力系列を生成する役割を担います。具体的には、以下のようなステップで処理が進みます。
- Self-Attetionにより、これまでに生成した単語間の関係性を計算
- Encoder-Decorder Attentionにより、エンコーダの出力と現在の状態を照らし合わせる
- 全結合層により特徴量を変換
- Softmax層により、次の単語の確率分布を出力
デコーダは、エンコーダからの情報と、自身が今まで生成した単語の情報を組み合わせながら、次の単語を予測していきます。この自己回帰的な生成プロセスにより、文脈を考慮した自然な文章生成が可能となります。
Transformerの特徴
![]()
Transformerの特徴として下記のようなポイントがあります。
- 並列処理による計算効率の向上
- 高レベルな翻訳品質の実現
- 長期的な記憶が可能
- Self-Attentionによる柔軟な活用性
並列処理による計算効率の向上
従来の系列変換モデルであるRNNは、系列データを逐次的に処理する必要がありました。これに対し、Transformerは系列データを並列に処理できます。
例えば文章の場合、RNNは単語を一つずつ順に処理しますが、Transformerは文章中の全ての単語を同時に処理できます。これにより、大幅な計算効率の向上が実現されています。
高レベルな翻訳品質の実現
Transformerは、Self-Attentionにより単語間の関係性を捉えることで、文脈を考慮した翻訳が可能となります。例えば、英語の「bank」という単語は、文脈によって「銀行」や「土手」など異なる意味を持ちます。
Transformerは、文章全体の文脈から適切な意味を選択し、自然な翻訳結果を生成できます。この高い翻訳品質が、ChatGPTのような高性能な言語モデルを支えています。
長期的な記憶が可能
RNNは長い系列データを処理する際、初期の入力情報を徐々に忘れてしまう問題(勾配消失問題)がありました。これに対し、Transformerは系列データ全体を常に参照できるため、長期的な依存関係を捉えることが可能です。
これにより、長文の要約や文章生成など、より長い文脈の理解が必要なタスクにも適用できます。
Self-Attentionによる柔軟な活用性
Transformerは、Self-Attentionというシンプルかつ強力な機構をベースにしているため、様々な分野への応用が可能です。
例えば画像処理の分野では、画像を小さなパッチに分割し、それらをSelf-Attentionに処理することで高い性能を発揮するVision Transformerが開発されています。また、音声処理や時系列データ処理など、他の分野へのTransformerの適用も活発に研究されています。
Transformerの応用モデル
Transformerは、その登場以降、様々な応用モデルを生み出してきました。ここでは、代表的なモデルをいくつか紹介します。
- GPT
- BERT
- PaLM
- Conformer
- DeFormer
- VIT
- T5
GPT
GPT(Generative Pre-trained Transformer)は、OpenAI社が開発した言語モデルです。大規模な言語データで事前学習されたTransformerのデコーダを用いて、自然な文章生成を可能にしました。
GPTは、ChatGPTをはじめとする対話システムや、文章生成タスクなどに幅広く活用されています。
参考:ChatGPTとは?使い方や始め方、日本語対応アプリでできることも紹介!
BERT
BERT(Bidirectional Encoder Representations from Transformers)は、Google社が開発した言語モデルです。Transformerのエンコーダを用いて、文章中の各単語の表現を獲得します。
BERTは、質問応答や感情分析、文章分類など、様々な自然言語処理タスクで高い性能を示しています。また、多くのタスクで事前学習済みモデルを利用できるため、少ない学習データでも高い精度が得られることが特徴です。
参考:Googleが誇る「BERT」とは?次世代の自然言語処理の特徴を解説
PaLM
PaLM(Pathway Language Model)は、Google社が開発した大規模言語モデルです。5400億のパラメータを持ち、自然言語処理のみならず、推論、プログラミング、数学など幅広いタスクをこなすことができます。
PaLMは、Google Boardをはじめとする同社の言語AIサービスの基盤となっています。
参考:Google PaLMとは?仕組みやできること、PaLM2とGeminiの展望も解説
Conformer
Conformerは、Transformerと畳み込みニューラルネットワーク(CNN)を組み合わせたモデルです。CNNによる局所的な特徴抽出とTransformerによる大域的な特徴抽出を併用することで、特に音声認識の分野で高い性能を発揮しています。
音声アシスタントやリアルタイム文字起こしなど、音声認識技術が必要とされる場面での活用が期待されます。
DeFormer
DeFormerは、Transformerを改良し、よりメモリ効率の良いモデルとしたものです。質問応答タスクなどにおいて、大規模なデータセットを用いた学習を可能にします。
Deformerは、Transformerの応用範囲をさらに広げる技術として注目されています。
VIT
ViT(Vision Transformer)は、Transformerを画像処理に適用したモデルです。画像を小さなパッチに分割し、それらをTransformerで処理することで高い精度の画像認識を実現します。
ViTは、従来の畳み込みニューラルネットワークを用いた手法と比べ、少ない学習データで高い性能を発揮することが知られています。医療画像の診断支援など、様々な分野での活用が期待されています。
T5
T5(Text-to-Text Transfer Transformer)は、Google社が開発したテキスト生成モデルです。様々なNLPタスクを、入力と出力を共にテキストとして扱う統一的なフレームワークで処理します。
例えば、翻訳タスクでは「英語の文章」を入力とし、「日本語の文章」を出力として学習します。質問応答タスクでは、「質問文」を入力とし、「回答文」を出力として学習します。
この統一的なアプローチにより、T5は様々なタスクに対して汎用的に適用可能であり、少ない学習データでも高い性能を発揮することができます。
まとめ
Transformerは、Attention Mechanisimを用いた系列変換のニューラルネットワークであり、自然言語処理や画像処理など幅広い分野で活用されています。エンコーダとデコーダから構成されており、エンコーダは入力系列を高次元のベクトル表現に変換し、デコーダはそのベクトル表現から出力系列を生成します。
Transformerの特徴として、並列処理による計算効率の向上、高レベルな翻訳品質の実現、長期的な記憶が可能であること、Self-Attentionによる柔軟な活用性などが挙げられます。さらに、GPT・BERT・PaLM・Conformer・DeFormer・ViT・T5など、Transformerをベースにした様々な応用モデルが開発されており、自然言語処理や画像処理の分野で優れた性能を示しています。
深層学習の発展に大きく貢献しており、今後もさらなる進化が期待される技術です。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI










FOLLOW US
SNSをフォローして、最新情報をチェックできます!

ソフトバンク、株主総会で新AI戦略を発表。次世代社会インフラ構築…

MASC、ヒューマノイドロボット「Unitree G1」導入。「…

静岡県藤枝市、全国初となる国産生成AIの公共活用実証実施。ソフト…
AVITAのAIロープレ「アバトレ」、日本調剤の薬局全国768店…

ChatGPT Workとは?機能・料金・使い方、Codexとの違いを徹底解説
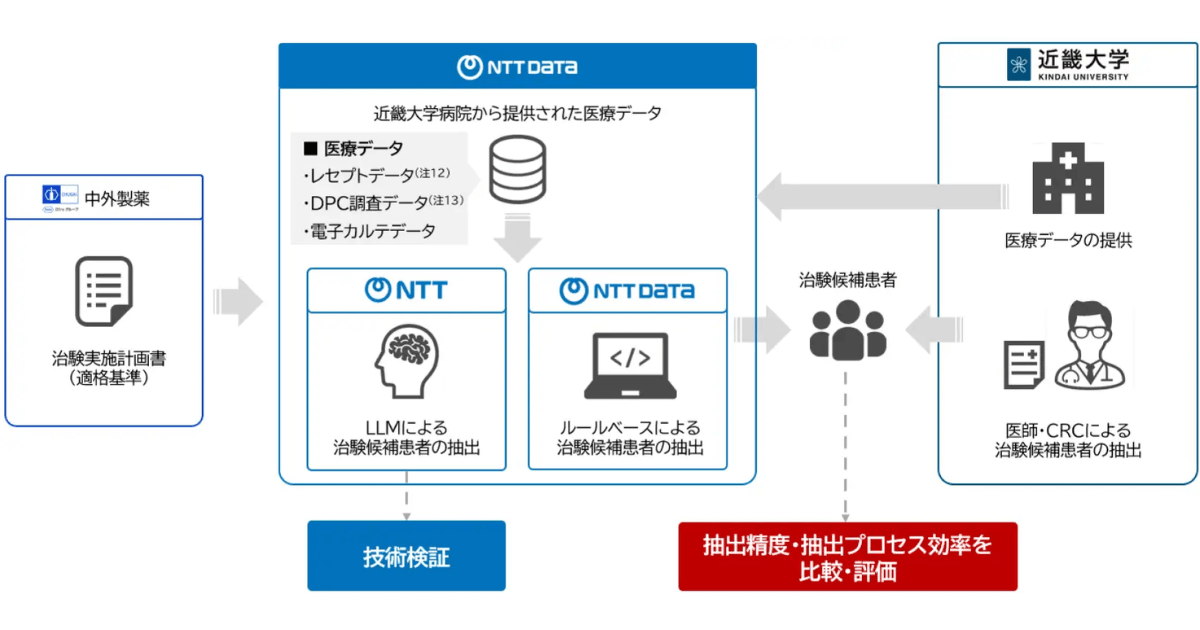
近畿大学病院など4者、リアルワールドデータとLLMを用いた共同研究を開始。治験候補患者抽出の精度向上と効率化を図る

KUMON、AI活用学習サービスのatama plusをグループ化。教室のグローバル展開や指導者支援を推進

Grok 4.5とは?性能・料金・使い方・他社モデルとの違いを解説

Claudeは画像生成ができない?最新機能と代替手段を徹底解説

アイスマイリー、 7/29(水)から3日間「イプロスAI 2026 夏」にブース出展。来場登録・実来場でAmazonギフト500円分プレゼント!
AI製品・ソリューションの掲載を
希望される企業様はこちら