

生成AI

最終更新日:2024/02/29
 OpenAI開発の「GPT-3」とは?
OpenAI開発の「GPT-3」とは?
AIが各分野で浸透してきている中、2020年に登場した「GPT-3」は業界の垣根を超えて大きな話題を呼んでいます。高度な自然言語処理技術を搭載したAIモデルであるGPT-3により、テキスト作成や自動翻訳、対話形式の応答など、多彩な機能が実現しています。
本記事では、GPT-3の仕組みやできること、残されている課題や問題点について解説します。すでにさまざまな分野で活用され、文章生成や自動要約など多くのアプリケーションに応用されているGPT-3について理解を深めるために、ぜひお役立てください。
ChatGPTについて詳しく知りたい方は以下の記事もご覧ください。
ChatGPTとは?使い方や始め方、日本語対応アプリでできることも紹介!

GPT-3とは「Generative Pre-trained Transformer-3」の略称で、OpenAIが開発した事前学習済みの自然言語処理モデルです。日本語では「事前学習済み文章生成型モデル『Transformer』の3番目のバージョン」と訳すことができます。
自然言語処理とは、ディープラーニング(深層学習)や機械学習を得意とするAIを用いて、人間の言葉(自然言語)を機械的に処理し、内容を抽出することを意味します。
GPT-3は、過去最大の1,750億個ものパラメータ数(プログラムに影響するデータ)を誇り、高い自然言語処理能力を実現しています。直前の単語の次にくる単語を高い精度で予測できるため、人間が入力した文(prompt)を受け取り、適切な出力文を返すことが可能です。
2020年に、Microsoft(マイクロソフト)社はOpen AIからGPT-3の独自ライセンスを取得しました。また、2021年には同社のクラウド基盤「Azure(アジュール)」にて、Open AI APIによってGPT-3を利用できるサービスの提供をスタートしています。
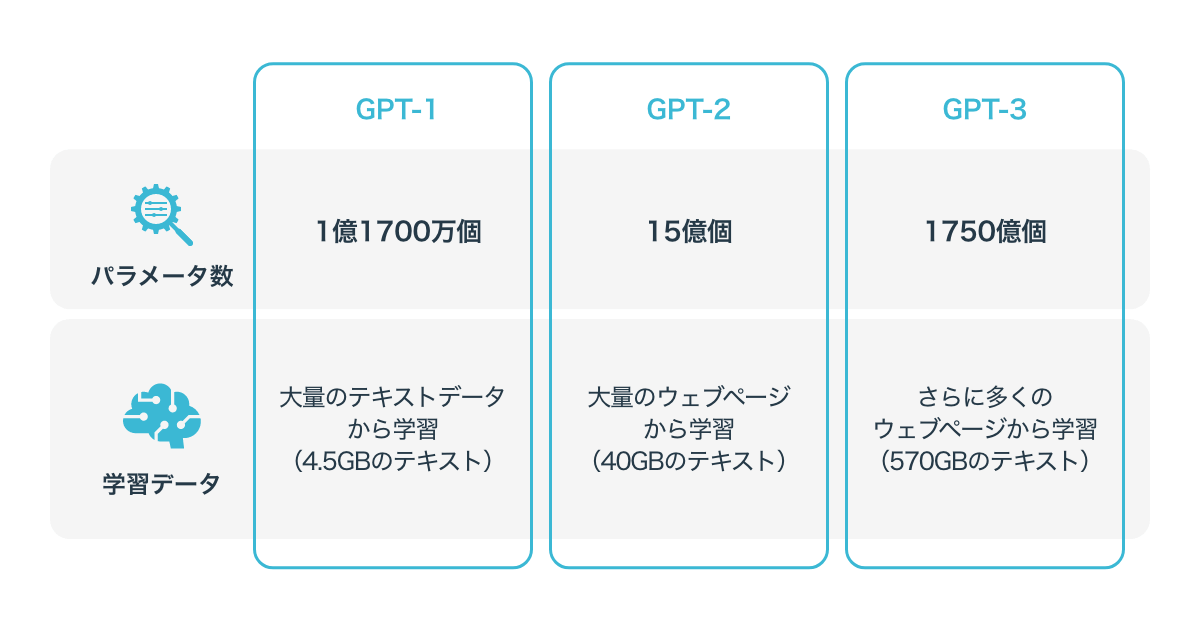
GPT-3は、その名の通りGPTの3番目のバージョンで、「GPT」「GPT-2」「GPT-3」とバージョンアップしてきました。GPT-3に採用されている「Transformer」自体は、2017年にGoogle Brainチームによって開発されたものです。
OpenAIがTransformerを用いて開発したGPTの初代バージョン「GPT」では、大量のテキストデータから事前学習を行い、さまざまなタスクに適応させることで高い精度を達成しました。
続いて2019年に登場したGPT-2では、GPTに改良が加えられ、より多くのテキストデータから事前学習を行えるようになっています。GPTでは1.1億パラメータ(2018年6月時点)を使用していたものの、GPT-2(2019年2月時点)では15億パラメータに増えています。
GPT-3は、2020年に発表されたGPT-2のさらなる拡張版です。45TBのテキストデータを用いた結果、事前学習したモデルだけで多くの自然言語処理のタスクにおいて人間レベル以上の性能を達成したことがわかっています。
GPT-3よりも新しい「GPT-3.5」「GPT-4」という進化版は、2022年11月より文章生成AI「ChatGPT」として一般に提供されています。

GPT-3では、言語モデル「Transformer」をベースに用いて、自然言語処理を実現しています。ここではGPT-3が自然言語を作る仕組みについて、もう少し詳しく見てみましょう。
GPT-3の仕組みを理解する上で重要な「Transformer」のコア技術は「Attention」と呼ばれるニューラルネットワークのアルゴリズムです。「Attention」は日本語で「注意」を意味する単語で、「どこに注目するか」に焦点を当てている点が大きな特徴です。
Attentionでは「文章のどこが重要で、どの関係性に重きを置くべきなのか」だけに着目する、というシンプルなアプローチを取ります。従来の回帰型ネットワークのような順番に言葉を読む必要がないため、複雑なネットワークが不要で、処理負担が軽減されています。つまり、要点を押さえることで、膨大なデータセットでも高い精度で学習ができます。
GPT-3を構成する重要な要素である「Transformer」や「Attention」は、自然言語処理分野における画期的なアイデアとして認識されてきました。ただ、これらの技術は、AIが持つ自然言語処理の本質的な仕組みとそれほど変わらず、基本原理は「Word to Vector(Word2vec)」に基づいています。
「Word to Vector」とは、ニューラルネットワークによる自然言語処理の初期に登場した考え方で、日本語で「言葉をベクトル化する」という意味があります。つまり、すべての言語を数値のパラメータに置き換え、そのパラメータ同士の統計的な関係性の問題に置き換えて、ニューラルネットワークで処理すれば、どんなに複雑な文章も処理が可能です。
GPT-3では、「Word to Vector」を「Transformer」と組み合わせて効率的に実行する方法を採用しています。従来の学習モデルをはるかに超える膨大なパラメータを使用し、実用的な水準を達成し、応用も比較的簡単です。
ただし、この言語処理方式では、すべての文章は単なる関係性の一部として理解されるだけで、単語や文章の意味、知識の理解までは至っていません。そのため、言葉の意味を理解でき、知識のある人間にとっては不自然に感じられるような文章を作ってしまうことがあります。
一方で、文化的な背景や高度な文脈理解が必要な「一見すると不自然に見える複雑な文章」も、十分な学習データをもってすれば作り出すことが可能です。

GPT-3がどのようにして精度の高い自然言語処理を実現しているのかを理解する上で重要なポイントとして「Few-shot learning」という学習方策を採用している点が挙げられます。従来までの「ファインチューニング」では、事前学習済みモデルに特定タスク用のデータを取り込み、タスクごとに最適化されたモデルを作成しました。
一方、Few-shot learningでは、入力文(prompt)を使って取り組むタスクを制御することで、プロンプトによる精度の高い文章生成を実現しています。これらの学習手法について、具体的に比較するために詳しく解説していきます。
「ファインチューニング(fine-tuning) 」とは、学習済みのモデルや新しいモデルを事前学習(pre-training)に活用して、調整したものをタスクに使うモデルの初期値として用いる手法です。
ファインチューニングでは、タスクを実行するための必要データが比較的少なく済むというメリットがあります。深層学習モデルの学習には膨大なデータが必要になりますが、事前学習されたモデルのパラメータを初期値とすることで、比較的少ないデータからでも良い性能で出力することが可能です。
ただ、ファインチューニングで複数のタスクを行うためには、タスクごとにモデルのコピーを作り、パラメータを更新しなければなりません。性能を確保するためには、良い事前学習モデルと高品質な学習データが必要です。
GPT-3で採用されている「Few-shot learning」とは、取り組むタスクをプロンプトによって制御する手法のことです。タスクを通じて共通のモデルを使用するため、ファインチューニングで必要とされていたようなタスクごとのパラメータ更新は不要になっています。よって、Few-shot learningではタスクに適応するコストが少なくて済むのです。
Few-shot learningで良い性能を達成するには、良い事前学習モデルに加えて、良いプロンプトが必要です。タスクの特性を的確に捉えた簡潔なプロンプトが求められますが、良い性能が得られるプロンプトを生成するために試行錯誤が必要な場合もあります。
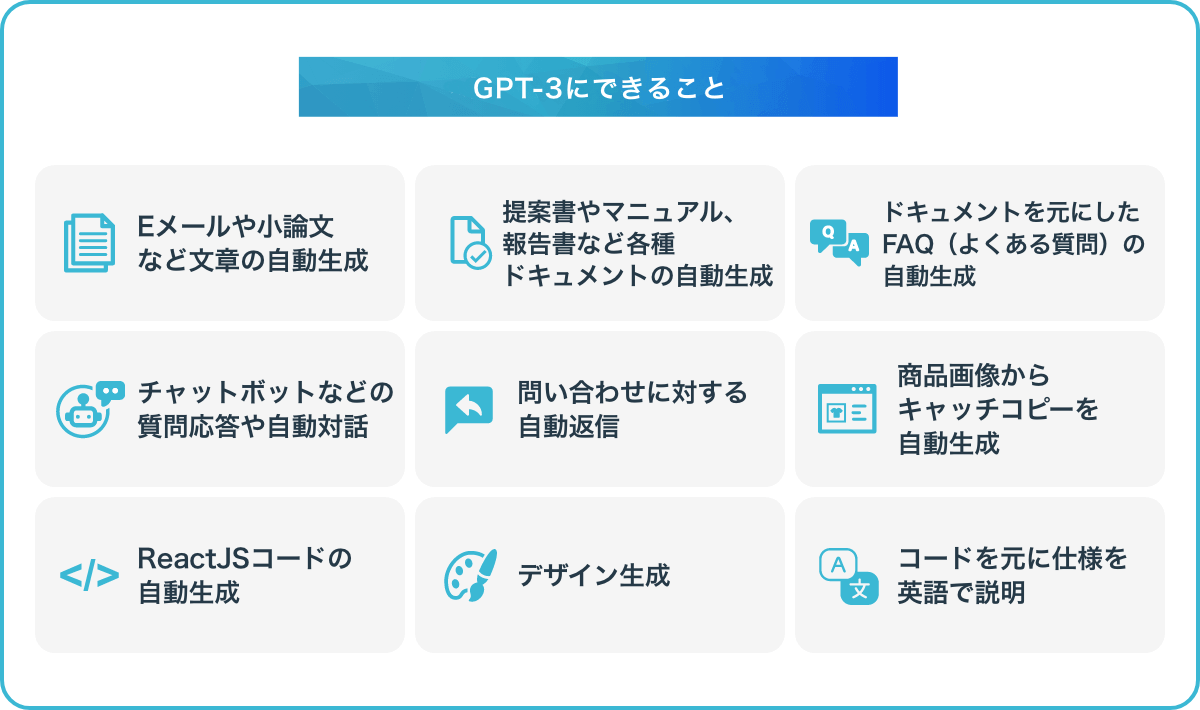
GPT-3では、言葉や文章に関するタスクを中心に、以下のような活用例が考えられます。
GPT-3を利用することで、業務効率化に役立つだけでなく、高品質なサービスの提供ができる可能性もあります。
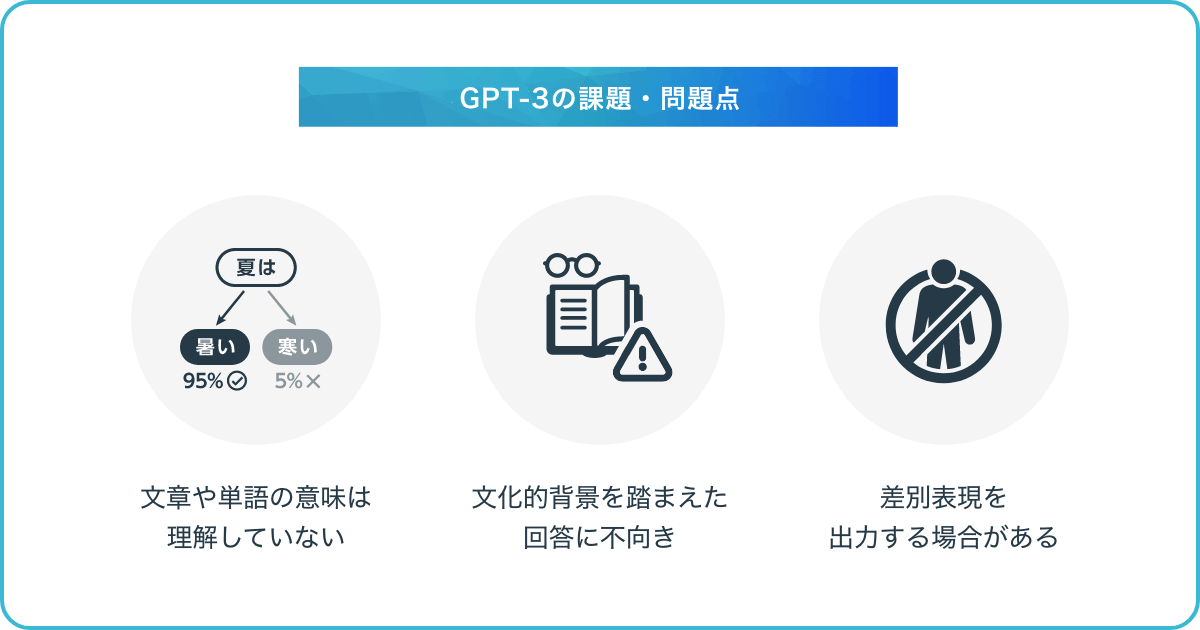
GPT-3では、文章生成の性能が高いため、ビジネスに導入する企業の活用事例も増えてきています。その一方で、複雑な質問にはうまく答えられないなど、課題や問題点も残されています。ここでは、現在のGPT-3の主な3つの課題や問題点を紹介します。
GPT-3は、ユーザーが入力した文章や単語の意味を理解している訳ではありません。GPT-3で文章を生成する際、過去の情報を元に単語を並べ、文法的に正しいとされる文章を作っているにすぎない状態です。
そのため、特に長文になると、同じ意味の単語を繰り返す、あるいは結論が矛盾した文章になる、といった場合があります。
また、GPT-3では、前の文章にある単語との関係性をパターン学習する特性があり、後ろの単語と前の単語の関係性について問う問題を解くことは難しいとされています。なお、この2文間の関係性を理解する能力は、自然言語処理全般で難しいとされており、今後課題を解消したAIモデルが登場すれば、人工知能分野における大きな進化となるでしょう。
GPT-3は、文化的背景を踏まえた回答ができないという問題点も抱えています。GPT-3が応答文を返す際には、文学的な表現を理解して回答している訳ではなく、文章の要点の重みから判断し、それらしいテキストを生成しているだけにすぎません。
そのため、物理的な法則や推論、常識に関する問題を解くことは難しいでしょう。人間が読んで「意味が分からない」と答えるような、ナンセンスな質問に対してGPT-3はうまく答えることができない可能性があります。
先述した通り、GPT-3には常識への理解がないため、差別表現など社会通念上ふさわしくない文章を作り出すことも考えられます。GPT-3は、生成した文章に論理的な整合性があるか、差別表現がないか、といったチェックはしません。
そのため、出力された文章をそのまま公開すると、差別表現による倫理的な問題が発生する可能性があります。現時点では、GPT-3には限界があり、生成された文章が必ずしも正しいとは限らないことを念頭に置いた上で、文章活用の前に内容をチェックする必要があるでしょう。
GPT-3は、OpenAIが開発した自然言語処理AIモデルの1つで、膨大な学習データを元に、自然言語の理解や文章生成を行います。入力されたプロンプトにより、取り組むタスクを制御するFew-shot learningの手法を使用することで、タスク適用のコストを抑えつつ、高精度な文章生成が可能になっています。
GPT-3には、文化的背景への理解や倫理的な表現への対処などの課題が残されていますが、より新しいモデルの「GPT-3.5」や「GPT-4」の登場によって、学習できるデータセットが増え、テキスト生成の精度がさらに向上しています。
これらのGPTモデルを使ったテキスト生成は「ChatGPT」で行うことが可能です。ChatGPTの使い方やできることについては、下記記事で詳しく解説していますので、あわせてご覧ください。
ChatGPTとは?使い方や始め方、日本語でできることを紹介!
生成AIについて詳しく知りたい方は以下の記事もご覧ください。
生成AI(ジェネレーティブAI)とは?種類・使い方・できることをわかりやすく解説
AIについて詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!







AI製品・ソリューションの掲載を
希望される企業様はこちら