

Gemma 4とは?性能・アーキテクチャ・使い方を徹底解説
最終更新日:2026/05/29
 Gemma 4とは?
Gemma 4とは?
2026年4月、GoogleはオープンモデルシリーズGemmaの最新モデル「Gemma 4」を公開しました。
Apache 2.0ライセンスへの変更により、商用利用における制約が低減されています。また、スマートフォンからサーバーまで対応可能な4つのモデルサイズと、音声・動画・画像を処理するマルチモーダル機能を備えています。
本記事では、Gemma 4 の主な機能や前世代からの進化、4つのモデル比較、環境別の使い方などを網羅的に解説します。
Gemma 4とは

Gemma 4は、Google DeepMindが開発したオープンウェイトモデルです。モデルの重みデータ(AIの学習結果)を公開し、誰でもローカル環境にダウンロードして動かせる形式を指します。
同モデルは、Gemini 3の研究成果をベースに構築され、パラメータあたりの性能においてオープンモデルとして最高水準を達成しています。
Gemma 3からの進化
2025年3月にリリースされたGemma 3と比べると、Gemma 4ではさまざまな項目において従来の水準を超えています。
代表的な変更点は、以下の4つです。
- ライセンスのApache 2.0への移行
- MoEアーキテクチャの導入
- 全モデルへのマルチモーダル対応の拡張
- エージェント機能(Function Calling)対応
両者を項目ごとに比較した表を以下に示します。
| 比較項目 | Gemma 3(27B) | Gemma 4(31B) |
| Arena ELO(LLM性能) | 1,365 | 1,452 |
| AIME 2026(数学) | 20.8% | 89.2% |
| LiveCodeBench v6(コーディング) | 29.1% | 80.0% |
| GPQA Diamond(科学) | 42.4% | 84.3% |
| τ2-bench(AIエージェント) | 6.6% | 86.4% |
| ライセンス | 独自ToS | Apache 2.0 |
| マルチモーダル | テキスト・画像 | テキスト・画像・動画・音声 |
※Arena ELOは計測タイミングにより変動
特に、AIMEとArena ELOのスコアが大幅に向上しており、数学やLLMとしての相対的な性能における顕著な進化が見られます。
Apache 2.0ライセンスへの変更
Apache 2.0ライセンスへ移行した結果、自社製品・サービスへの組み込みや商用配布が可能になりました。
また、ファインチューニングや再配布が可能になり、AUP(Acceptable Use Policy)による制約も撤廃されています。
結果的に、文字起こしなどでの商用利用時の報告義務がなくなり、クローズド環境で組み込みやすくなりました。ライセンスの変更は、モデルを事業に取り込みやすい環境の整備につながっています。
GemmaとGeminiの違い
Googleが提供するGeminiとGemmaは、基本的に提供形態が異なります。
Gemmaがオープンモデルで、自分のPCやスマートフォンなどローカル環境で実行できるのに対し、Gemini はGoogleが管理するクラウドAPI経由でのみ利用できます。
Gemma は機密情報を扱うビジネスユースに適しています。
一方、Geminiはローカルへのダウンロードはできませんが、最新の大規模モデルにアクセスしやすいため、最高性能を求める場合にはGeminiのAPIを検討すると良いでしょう。
主要機能
Gemma 4では、前世代モデルから大きく強化された3つの機能が搭載されています。
ここでは、各機能について詳しく説明します。
全モデル共通のThinking(思考)モード
Thinking(思考)モードとは、モデルが最終回答を出す前に段階的な推論プロセスを実行する機能です。人間が複雑な問題を解く際、頭の中で手順を整理してから答えを出すプロセスに似ています。
この機能はOn/Offの切り替えが可能で、特に以下のようなタスクでの有効活用が期待できます。
- 数学・論理パズルなど多段階の計算が必要な問題
- 複数の条件を整理して判断する要件定義・仕様検討
- コードのバグ原因を追跡するデバッグ作業
ただ、ThinkingモードがOnの間は処理時間が長くなるため、単純な質問応答や定型文の生成などスピード重視のケースはOffにするなど、使い分けも大切です。
マルチモーダル対応
モデルによっては、テキストと音声以外の動画処理も可能です。モデル別の対応状況を以下表にまとめました。
| モダリティ | テキスト | 画像 | 動画(最大60秒) | 音声(最大30秒) |
| E2B | ○ | ○ | ✕ | ○ |
| E4B | ○ | ○ | ✕ | ○ |
| 26B A4B | ○ | ○ | ○ | ✕ |
| 31B | ○ | ○ | ○ | ✕ |
書類やスクリーンショットなど、実務で扱う画像をそのまま入力できるため、OCR(文字認識)やグラフの数値読み取り、UIのスクリーンショットからの指示といった場面で役立ちます。
また、テキストと画像を任意の順序で組み合わせて入力できる「インターリーブドマルチモーダル入力」にも対応しています。
「この図を見て、次にこの文章を読んで回答してください」といった複合的な指示もスムーズに回答できます。
会話中の外部機能呼び出し(Function Calling)
Function Calling とは、モデルが会話の中で外部のツールやAPIを呼び出し、ツールを活用しながら回答を生成する機能です。
Gemma 4では、プロンプトエンジニアリングで後付けするケースと異なり、トレーニングの目標として設計されています。
そのため、ツール呼び出しタイミングの判断精度が高く、段階的な複数ステップの自律的ワークフローも安定的に動作可能です。AIエージェントとしてのツール使用にも通ずる重要な機能と言えます。
4つのモデル比較
用途の異なる4種類のモデルを提供しています。各モデルの主な特徴を以下に示します。
| モデル | 実効パラメータ | アーキテクチャ | コンテキスト | 主な用途 |
| E2B | 2.3B | Dense | 128K | スマートフォン・IoT |
| E4B | 4.5B | Dense | 128K | ノートPC・エッジ |
| 26B A4B | 推論時3.8B | MoE | 256K | 速度重視のAPI・サービス |
| 31B | 31B | Dense | 256K | 品質重視・ファインチューニング |
E2B(スマートフォン・IoTデバイス向け)
E2Bは、実効2.3Bパラメータのモデルで、スマートフォンやIoTデバイスでの動作を想定した設計です。量子化(モデルデータの圧縮)により、1.5GB未満のメモリで動作が可能で、インターネット接続なしのオフライン環境でも利用できます。
また、音声入力(最大30秒)も処理できるため、音声認識や翻訳をクラウドAPI不要で実行したい場合にも向いています。
E4B(ノートPC・エッジデバイス向け)
E4Bは、実効4.5Bパラメータのモデルで、一般的なノートPCや開発者向けエッジデバイスでの利用を想定しています。E2Bと同様に音声入力に対応しており、オフライン動作が可能です。
E2Bより表現力が高く、より複雑な質問応答や文書処理に対応できます。量子化版であれば、GPUなしのCPU環境でも動作するため、ノートPCでの試験導入用としても現実的な選択肢と言えます。
26B A4B(MoE)
26B A4Bは、MoE(Mixture of Experts)アーキテクチャを採用したモデルです。総パラメータ数は26Bですが、推論時に実際に動かすのは3.8Bのみのため、大規模モデルに近い品質を低いメモリ消費で実現します。
高速なトークン生成が特徴で、多数のリクエストを処理するAPIサービスやレイテンシ(応答速度)を重視するアプリケーションにも向いています。動画入力(最大60秒)と画像入力にも対応可能です。
31B Dense
31B Denseは、Gemma 4ファミリーの最上位モデルです。全パラメータを常時使用するDense(密結合)アーキテクチャを採用しています。
ファインチューニング(特定用途向けの追加学習)のベースモデルとしても適しており、自社データで特化モデルを構築したい場合にも使えます。動画・画像の入力に対応していますが、音声入力は非対応です。
アーキテクチャと仕組み
ここでは、開発者・エンジニア向けのGemma 4 のアーキテクチャと仕組みについて、わかりやすく解説します。
DenseとMoEの使い分け
Dense(密結合) は、毎回全パラメータを使って推論を行う構造です。出力の品質が安定しており、ファインチューニングにも適した仕組みで、Gemma 4 の31B・E2B・E4Bが採用しています。
一方、MoE(Mixture of Experts) とは、モデル内部に多数の専門ユニット(エキスパート)を持ち、入力に応じて使い分ける構造です。
Gemma 4では、26B A4Bが採用しており、推論時には一部である3.8B相当のみが稼働します。
速度やコストを重視するならMoEモデルが、品質やカスタマイズ性を重視するならDenseモデルが適しており、両者を使い分けることで最適化が可能です。
PLEによる計算効率の向上
E2B・E4Bに採用されているPLE(Per-Layer Embeddings / 層別埋め込み)とは、モデルを小さく保ちながら表現力を高める技術です。通常のモデルは入力データを最初の層でまとめて変換(埋め込み)し、その情報を全層に引き継ぎます。
一方、PLEでは、各層に独立した埋め込み信号を追加するため、各層が最初の変換結果と自分の層の情報を両方参照しながら処理を進めます。よって、パラメータ数が少なくても深い理解が可能になり、スマートフォンのような限られたメモリ環境でも推論精度や応答品質を維持できます。
ハイブリッドアテンション機構
アテンション機構とは、文章内のどの単語・情報に注目して処理するかを、モデルが判断する仕組みです。Gemma 4では、SWAとグローバルアテンションの2種類のアテンションを組み合わせた「ハイブリッドアテンション機構」を採用しています。
SWA(ローカル・スライディング・ウィンドウ・アテンション)は、直近のテキストのみを参照する軽量な処理で、処理が速くメモリ消費が少ない反面、文脈の遠い部分への対応が弱くなりがちです。また、グローバルアテンションは、入力全体を参照することで文書全体の文脈を把握しますが、その分メモリと計算コストは増加します。
Gemma 4では両者を交互に組み合わせ、最終層は必ずグローバルアテンションになるよう設計されています。メモリ効率を保ちつつ、最終的な回答生成時には全体の文脈を参照して整合性を取っています。
【環境別】Gemma 4の使い方

Gemma 4は、ブラウザ版からローカルPC、スマートフォンまで複数の方法で利用できます。ここでは、環境別に具体的な操作手順を紹介します。
Google AI Studioで試す
最も手軽に試せる方法として、Google AI Studioを使用する方法があります。
ブラウザからGoogle AI Studio(aistudio.google.com)にアクセスするだけで、26B A4Bおよび31Bモデルを使用できます。インストールは不要ですが、Google アカウントが必要です。
また、Thinkingモードの切り替えも試せるため、ローカル環境を構築する前に用途に合っているか確認したい場合にも便利でしょう。
なお、無料枠ではレートリミット(時間あたりのリクエスト上限)が付いています。本番利用や高頻度での使用には、有料プランまたはAPI経由での利用を検討しましょう。
Ollamaでローカル実行する手順
Ollamaは、LLMをローカル環境で手軽に動かすツールで、MacとWindows、Linuxの3環境に対応しています。コマンド1行でモデルをダウンロード、実行可能です。
- Ollamaをインストールする
- ターミナル(コマンドプロンプト)を開き、モデル別コマンドを実行する
- 完了後、ターミナル上でチャットを始める
モデル別のコマンドは以下の通りです。
| # E4Bモデルを実行する場合 ollama run gemma4:e4b # 26B A4Bモデルを実行する場合 ollama run gemma4:26b-a4b # 31Bモデルを実行する場合 ollama run gemma4:31b |
LM Studioで使う方法
LM Studioとは、LLMの管理・実行用アプリで、GGUF(GPT-Generated Unified Format)形式でGemma 4を実行できます。GUIベースのため、コマンドラインに不慣れな方でも直感的に操作できる点が特徴です。
操作手順は、以下の通りです。
- LM Studioをダウンロードする
- アプリ内で「gemma-4」を検索し、Hugging FaceのGGUF形式モデルを選択する
- 量子化レベルを選び、ダウンロードする
- 完了後、チャット画面でそのまま会話をスタートする
iPhone・Androidで動かす方法
エッジモデル(E2B・E4B)は、スマートフォン上でも利用可能です。iPhoneとAndroid、いずれでもGoogle公式アプリ(Google AI Edge Gallery)をインストールし、E2BまたはE4Bモデルを設定すれば、インターネット接続不要で使えます。
競合比較:Llama 4・Qwen 3.5
Gemma 4と同様のオープンモデルには、Llama 4やQwen 3.5などがあります。
各モデルを比較するために、特徴を以下にまとめます。
| モデル | パラメータ数 | ライセンス |
| Gemma 4(31B) | 31B | Apache 2.0 |
| Gemma 4 (26B A4B) | 26B(推論時3.8B) | Apache 2.0 |
| Llama 4(Scout) | MoE・大規模 | 独自ライセンス |
| Qwen 3.5 27B | 27B | Apache 2.0 |
パラメータあたりの効率は、Gemma 4がトップクラスです。また、ライセンス面ではApache 2.0を採用しており、Llama 4の独自ライセンスに比べて商用利用や再配布の条件がシンプルなため、法務確認のコストが低い点もメリットです。
ただし、Llama 4 Scoutのコンテキストウィンドウは、Gemma 4の256Kを大きく上回る1,000万トークンに対応しています。極端な長文処理ではLlama 4 の利用を検討すると良いでしょう。
ビジネス・開発での主な活用シーン

ここからは、ビジネスや開発におけるGemma 4の主な活用例を紹介します。自社での導入検討にお役立てください。
オフライン・閉域環境でのAI活用
エッジモデルは、インターネット接続不要でデバイス単体で動作するため、データが外部に出ない環境でのAI活用が可能です。特に、医療・法務・金融・製造業といった機密情報を扱う業種で、従来のクラウドAPIを使うAIは導入の障壁になるケースがありました。
その点、Gemma 4 では、ローカル環境での利用が可能です。音声と画像の両方をネイティブで処理できるE2BとE4Bでは、以下のような効果的な活用が期待できます。
- 工場・建設業:設備や構造物の写真を撮影し、異常の有無をオフラインで判定する
- 医療・介護:患者との会話を音声入力で記録・要約し、カルテ入力を支援する
- 小売・サービス業:ネットワーク環境が不安定な店舗でも多言語での音声対応による接客案内を稼働させる
長文ドキュメント処理の自動化
最大256Kトークンのコンテキストウィンドウを持つモデルを使えば、数十ページの書類を1つのプロンプトに収められます。この特性を活かし、以下のような活用方法があります。
- 法務文書のレビュー:長文ドキュメントを丸ごと入力し、リスク条項の抽出や要約を自動生成する
- 社内ドキュメントの横断検索:複数のマニュアルや議事録を一括入力し、質問を投げる
- コードベースの解析:中規模のリポジトリをそのまま入力し、バグの原因特定や仕様の説明を依頼する
なお、大量の文書群を事前にインデックス化し、必要な部分だけを都度参照するRAGを、Gemma 4と組み合わせる手法も有用です。
Apache 2.0を活かした自社AIプロダクトの構築
ファインチューニングした独自モデルを、自社製品に組み込んで配布できます。具体的には、以下のような展開が可能です。
- SaaSへの組み込み:自社サービスのAI機能としてモデルを内蔵し、APIコストを固定費化できる
- 業種特化モデルの社内展開:自社の業務マニュアルや過去データを学習させ、社内専用のAIアシスタントを構築する
- OEM・ホワイトラベル展開:特定分野の特化モデルをクライアント向けに提供する
Apache 2.0 ライセンスにより、派生プロダクトの開発から市場投入までのリードタイムを短縮できます。
まとめ
Gemma 4は、「Apache 2.0ライセンスへの移行」「MoEアーキテクチャの導入」「マルチモーダル対応の拡張」という3つの変化により、前モデルから性能が大きく向上しています。また、エージェント機能(Function Calling)対応によって、幅広い用途での活用が実現します。
用途とハードウェアによって適したモデルが異なります。スマートフォンやエッジデバイスで手軽に試したい場合はE2B・E4B、速度とコストのバランスを重視するサービス開発には26B A4B、最高品質や特化モデルの構築を目指すなら31B Denseが望ましいでしょう。
インストール不要のGoogle AI Studioで動作を試した後で、ローカル環境への移行を検討するとスムーズです。
アイスマイリーでは、生成AI のサービス比較と企業一覧を無料配布しています。課題や目的に応じたサービスを比較検討できますので、ぜひこの機会にお問い合わせください。
よくある質問
Gemma 4の読み方は?
「ジェマ フォー」と読みます。GemmaはGeminiと同様に、宝石・天文学に由来する命名規則を踏襲しています。
Gemma 4は商用利用はどこまで可能?
Apache 2.0ライセンスのため、製品への組み込みやファインチューニング済みモデルの再配布・販売が可能です。追加の申請・費用は不要で、月間アクティブユーザー数などの利用制限もありません。 ただし、実務上の対応として、ライセンス文書(著作権表示と免責文)を製品やドキュメント内に明記することが求められます。商用展開を検討する場合は確認しておきましょう。
Gemma 4の日本語レベルはどのくらい?
Gemma 4 は、140言語で事前学習済みで、日本語テキストの生成・理解にも対応しています。ただし、日本語特化ベンチマークの数値は、公式としては未公開のため、完全に対応しているとは言い切れない状況です。 しかし、実用上の自然な日本語生成は可能であり、より高い精度が求められる用途ではファインチューニングを推奨します。
- AIサービス
- 生成AI
- 音声認識・翻訳・通訳
- 画像認識・画像解析
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI














FOLLOW US
SNSをフォローして、最新情報をチェックできます!

リコーとライズ・コンサルティング・グループ、AI実装・活用を一貫…
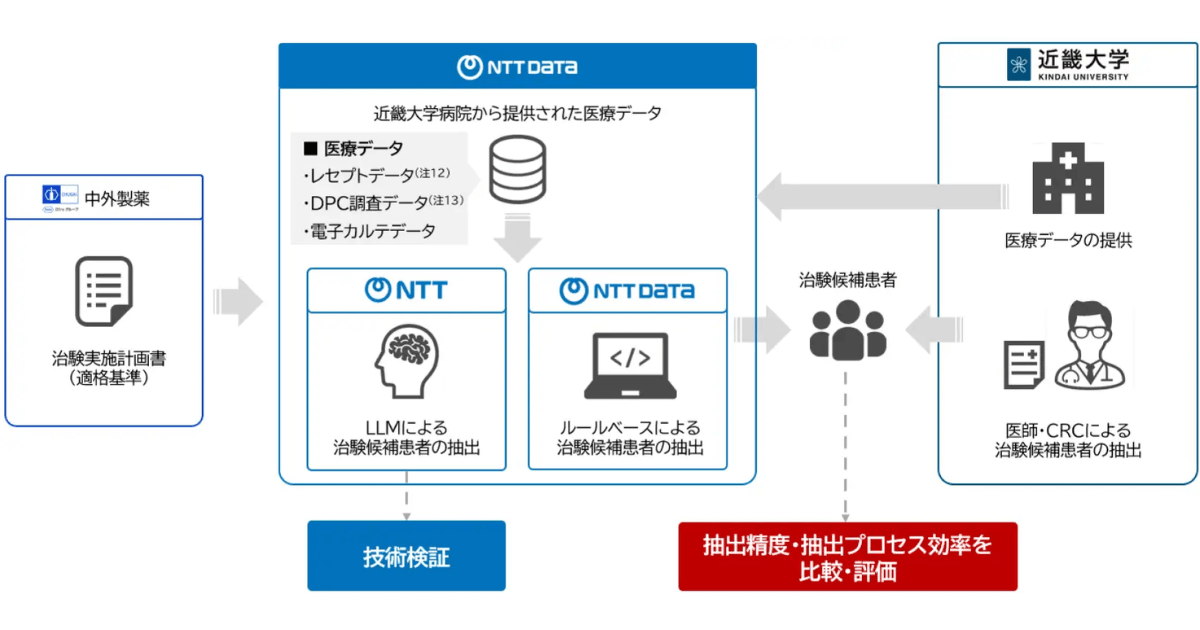
近畿大学病院など4者、リアルワールドデータとLLMを用いた共同研…
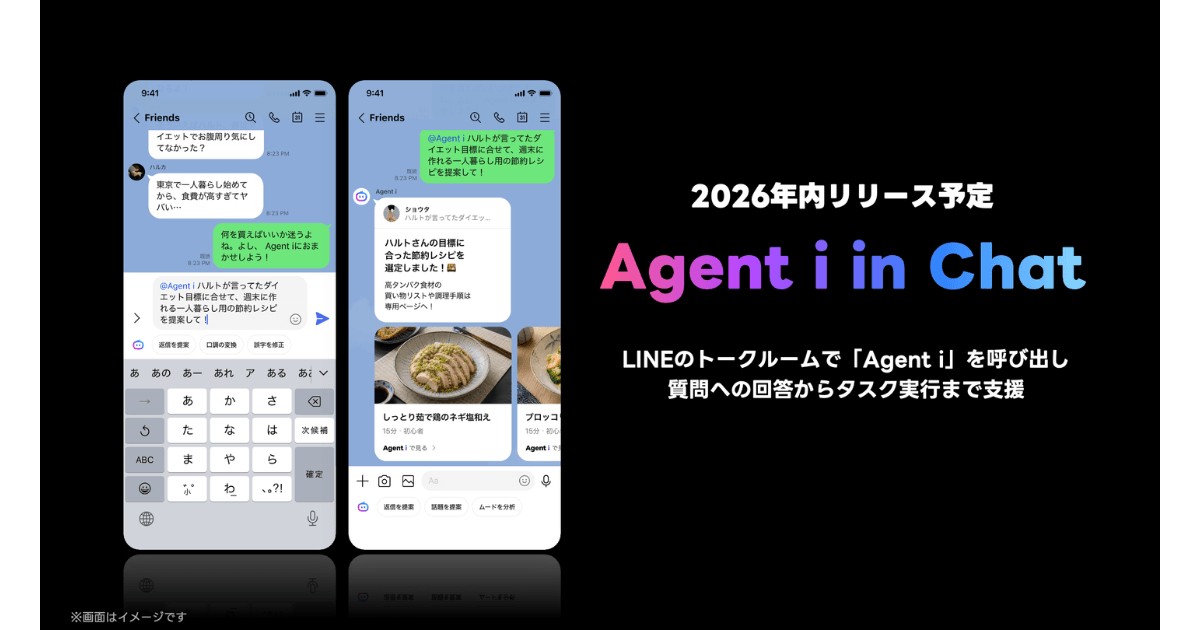
LINEヤフー、「LINE」新機能「Agent i in cha…
Sakana AI、「Sakana Chat」に翻訳機能を追加。…
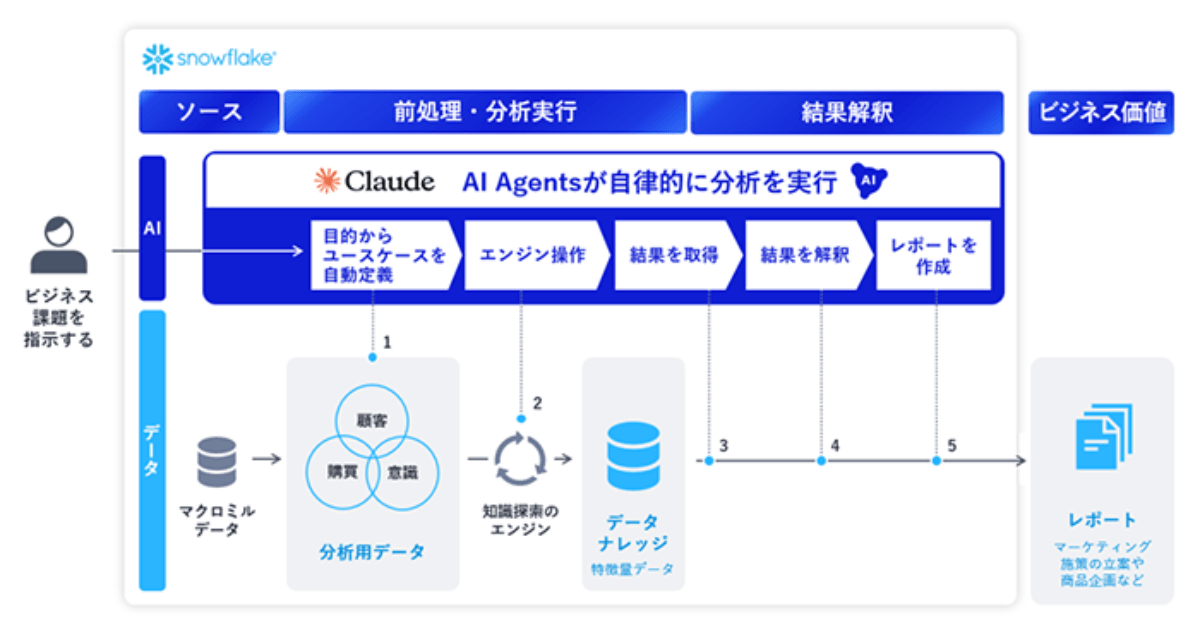
NEC、Anthropic協業による「NEC AIインサイトレポーティングサービス」提供開始。商品企画や販促プラン作成を自動化

オムロン、ケアプラン作成支援AI機能「With.Ai」開発。最短10分で作成、業務時間80%以上削減

GitHub Copilot CLIとは?インストール・使い方・料金を解説

Copilot Keyboardとは?インストール・設定・使い方を徹底解説

SpaceXAI、最新モデル「Grok 4.5」を提供開始。コーディング能力とエージェントタスクの性能を強化

ChatGPTの育て方とは?自分好みに育てる方法とコツを解説
AI製品・ソリューションの掲載を
希望される企業様はこちら