

生成AI

最終更新日:2026/03/31
 Whisperを実際に使ってみた!
Whisperを実際に使ってみた!
OpenAIが発表した音声認識モデル「Whisper」は、日本語の音声でも精度高く文字起こしできるツールとして知られています。今回はアイスマイリー編集部が「AIニュース原稿の読み上げ音声を素材にどのくらい精度高く文字起こしできるのか」や「生活騒音下における読み上げ音声でも結果は変わらないのか」について調べてみましたので是非やり方を真似して試してみてください。
記事後半ではWhisper APIおよびChatGPT APIを活用した文字起こしサービスである「writeout.ai」の紹介も行っていますので、業務への活用イメージとしてご活用ください。
生成AIについて詳しく知りたい方はこちらの記事もご覧ください。
生成AI(ジェネレーティブAI)とは?種類・使い方・できることをわかりやすく解説
音声認識モデルとは、AIが人間の声を認識し、認識した音声をもとに何らかのデータをアウトプットする技術を指します。身近な音声認識モデルには、アレクサでお馴染みのAmazon Echoがあります。Amazon Echoなどのスマートスピーカーは、人間の声を認識し、その音声の意図を把握した後、情報検索を行ったり、接続されている電化製品の操作を行ったりします。
スマートスピーカーの他にも、入力された音声をリアルタイムに翻訳するサービスや、人間の声から発話者の感情を可視化するサービスなどが存在します。今回紹介するOpenAIの「Whisper」は音声認識モデルを活用した文字起こしサービスの1つで、音声ファイルを入力するとテキストデータを出力します。
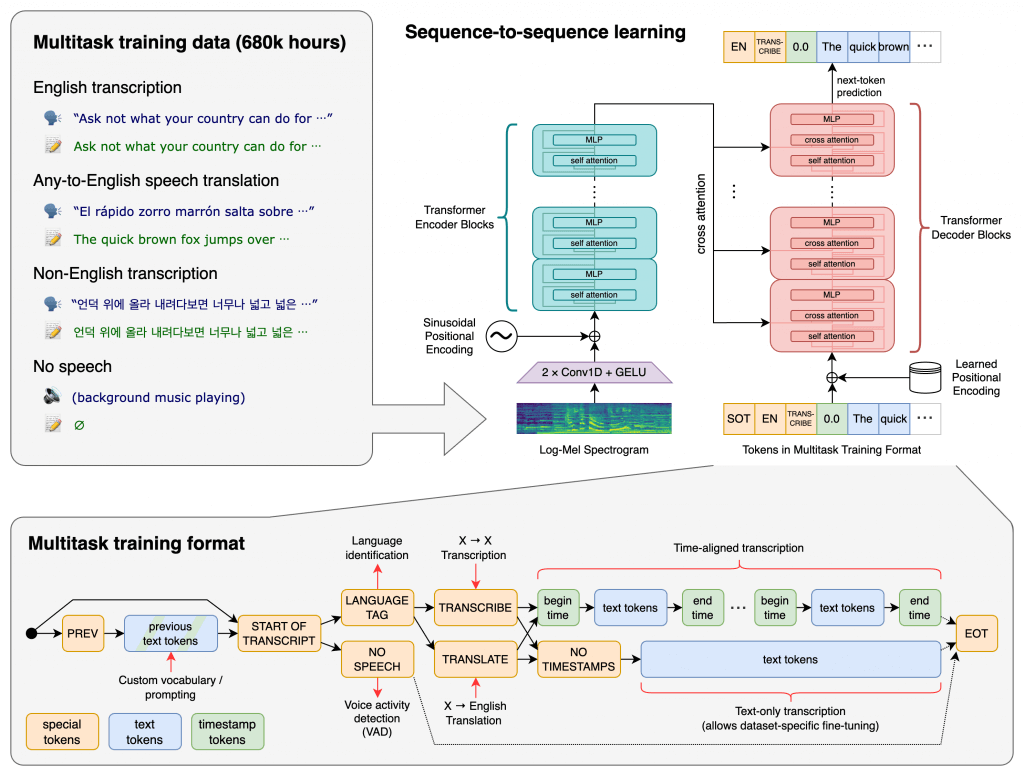
Whisperは、OpenAIが文字起こしサービスとして公開した無料の音声認識モデルです。WhisperはWebから収集した68万時間分の多言語音声データを教師付きデータで学習させており、高い精度で入力した音声を文字起こしすることが可能になっています。
Whisperには書き起こしに用いるモデルサイズが5つ存在し、largeサイズに移行するにつれて書き起こしの精度が上がっていきます。
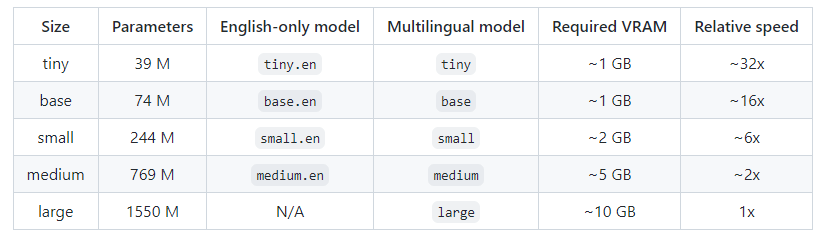
画像引用元:https://github.com/openai/whisper
また、気になる日本語の文字起こしの精度ですが、公開されている「単語誤り率」の順位で6位の「5.3%」(Fleursデータセットの言語別WERを、large-v2モデルを用いて示した結果)となっており、日本語を他の言語に比べて高い精度で文字起こし可能と報告されています。スペイン語、イタリア語、英語、ポルトガル語、ドイツ語に続く書き起こし精度ということで、今後Whisperを試す日本企業も増えていくと予想されます。
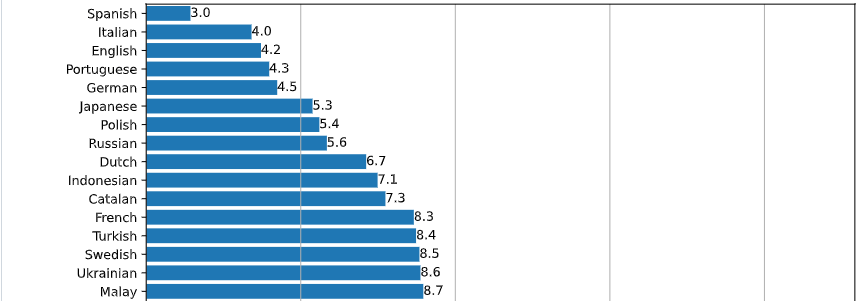
画像引用元:https://github.com/openai/whisper
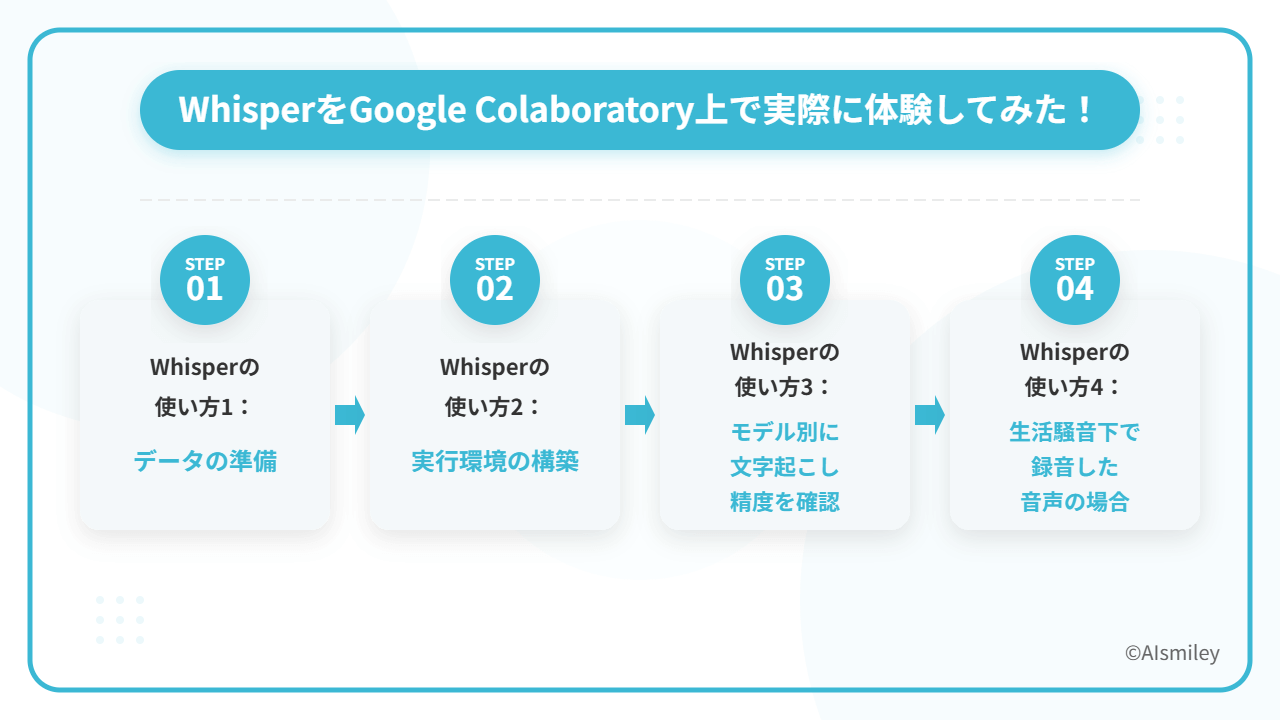
今回はそんな高い文字起こしの精度を誇るWhisperをGoogle Colaboratory上で実際に体験してみようと思います。Google ColaboratoryはGoogleが提供する環境で、ブラウザから直接pythonを記述し、実行できるサービスとなっています。下記のステップ2でWhisper実行環境の構築を図解解説していますが、「試しにサッと使ってみたい」という人はオープンソースコミュニティ「Hugging Face」でWhisperを使ってみるとよいでしょう。
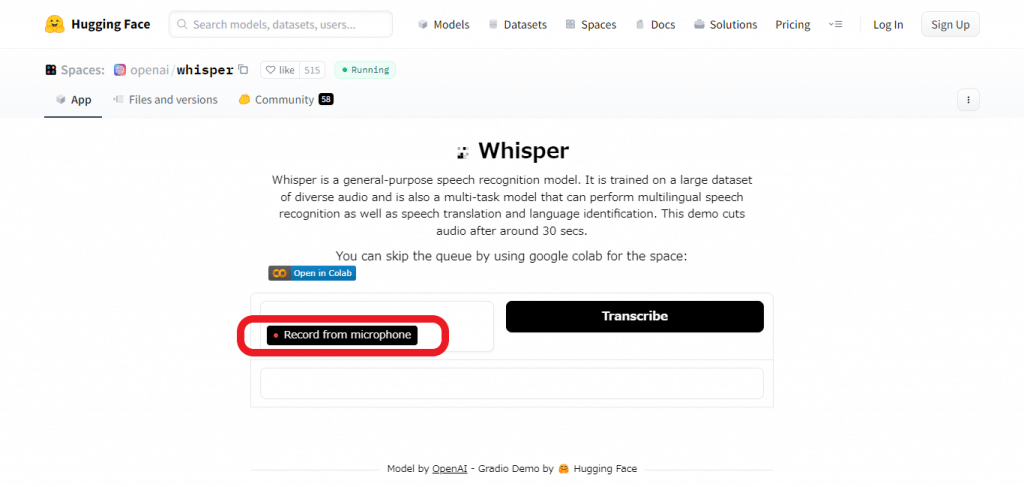
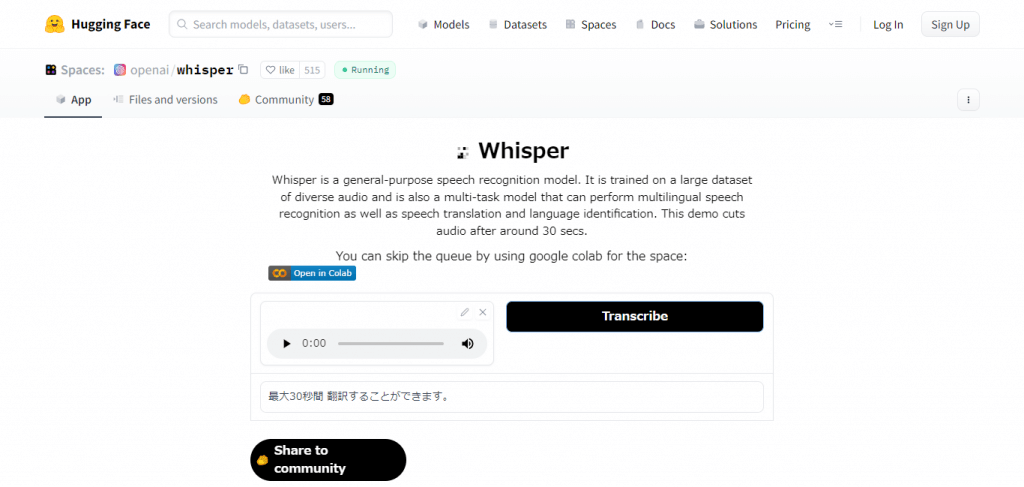
こちらのリンクからアクセスし、赤枠の「Record from microphone」を選択することで、PC等に接続されたマイクから音声を直接入力し、保存することができます。保存した音声はその場で聞くことが可能で、「Transcribe」を選択すると数十秒程度で入力した音声を自動で文字起こししてくれます。試しに「最大30秒間、翻訳することができます」と音声入力したところ、一文字も間違うことなく文字起こしすることができました。
ではGoogle Colaboratory上でWhisperを実行するために、まず文字起こしを行う音声データを準備していきます。今回はAIsmileyのニュース記事から「バーティカルSaaS AIカオスマップを初公開」という記事を選定し、記事冒頭部分の文章を30秒だけ読み上げました。また、Whisperの書き起こし精度を調べるため、「生活騒音下における読み上げ音声」も複数準備し、生活騒音下でも問題なく文字起こしできるかどうかを調査しています。
※読み上げ音声はiPhoneの「ボイスメモ」で録音し、Dropboxへとアップロード、PCブラウザ上のDropboxからPC環境にダウンロードした後、Google Colaboratory上にアップロードしています。
今回読み上げの対象とした記事の読み上げテキストは下記の通りです。
「バーティカルSaaSとは各業種に特化したSaaSです。各業種に特化したサービスを導入することで、業界特有の課題を解決できる可能性が高まります。その反面、日々新たなサービスがローンチしている状況のため、自社にマッチした製品を知ることが難しくなっています。今回のカオスマップは「自社の業種に特化したAIサービスを知りたい」といったご希望にお答えするため、100社以上の製品を独自調査した上で作成いたしました」
こちらの文章をほとんど無音の状態で録音した音声を「ongen 0」とし、他の生活騒音下における読み上げ音声と区別して精度を測っていきます。ちなみに生活騒音を調査するために使用した騒音計測アプリはこちらになりますので、スマートフォンで音声を録音したい人は参考にしてください。
先ほどのテキスト部分を下記の生活騒音下で読み上げを行いました。
今回使用した読み上げ音声の騒音レベル(デシベル)は上記の通りになりましたが、その他デシベルデータの参考はこちらをご確認ください。
では実際にGoogle Colaboratory上でWhisperの実行環境を構築していきます。
まずGoogle Colaboratoryにアクセスします。Googleアカウントがあれば誰でもGoogle Colaboratoryにアクセス可能です。
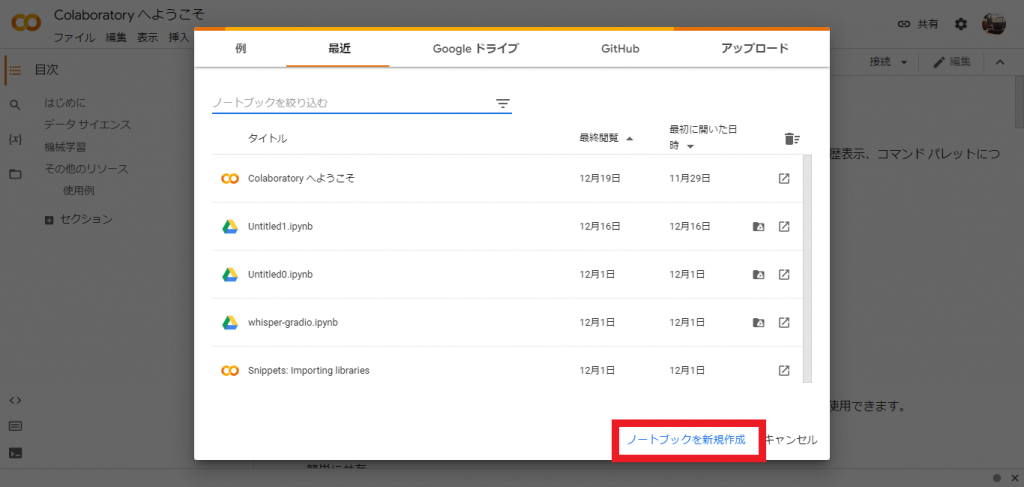
上の画面が表示されたら「ノートブックを新規作成」を選択します。
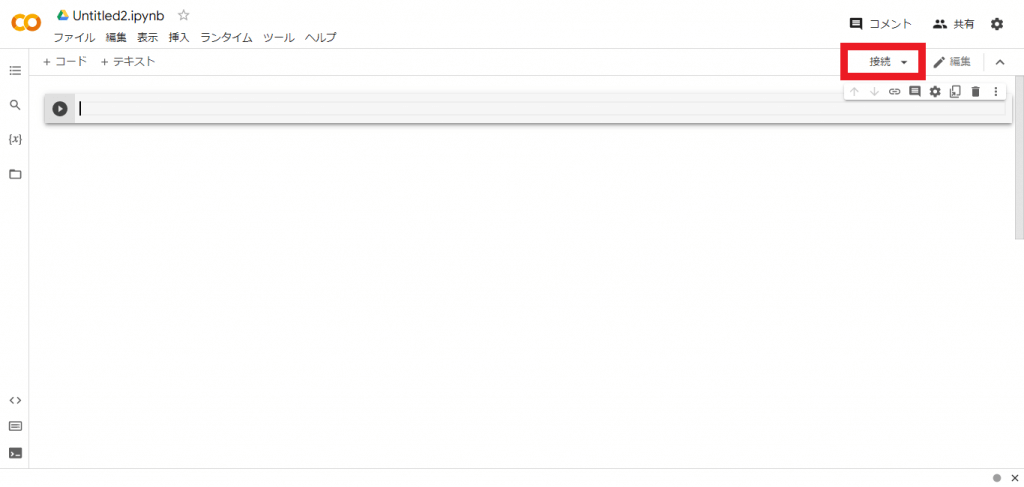
次に画面右上の「接続」を選択してください。
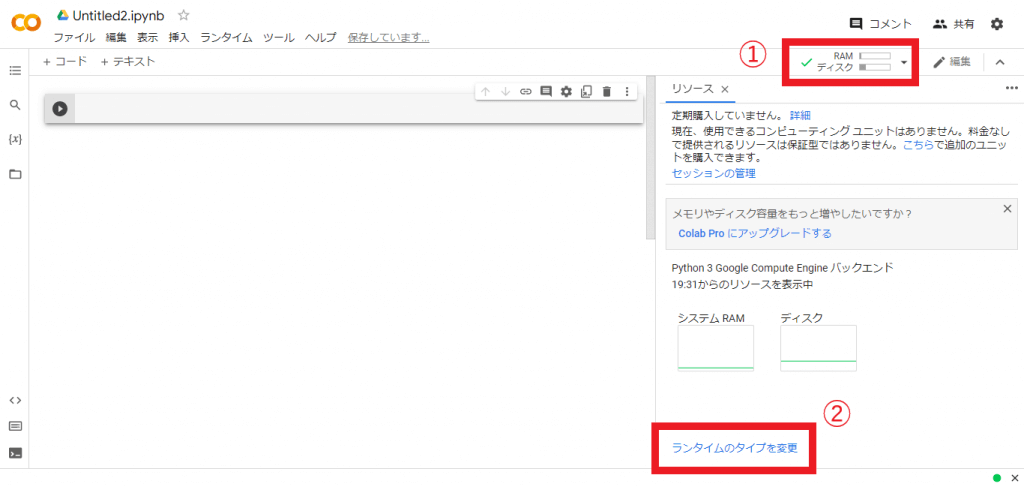
「接続」の箇所が「RAM ディスク」の表示に変わったらクリックし、右下の「ランタイムのタイプを変更」を選択しましょう。
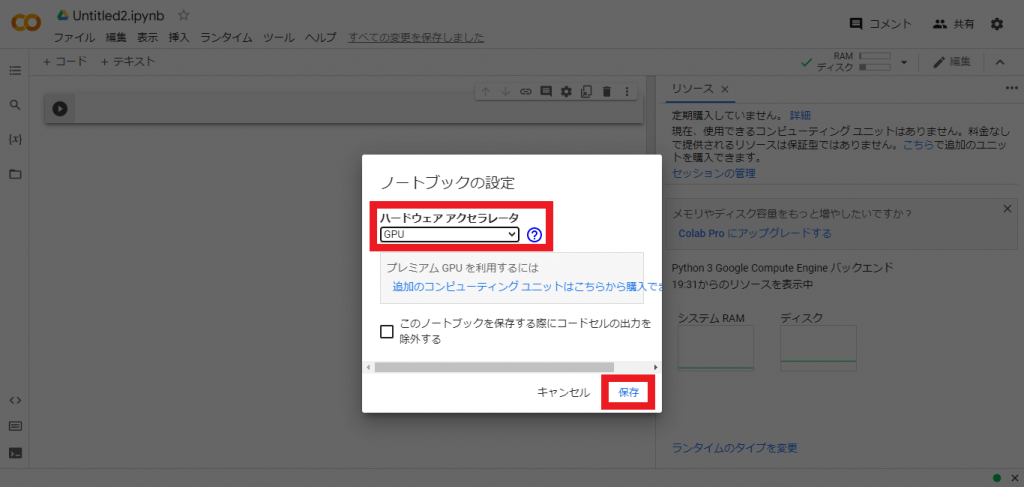
「ハードウェアアクセラレータ」を「GPU」に変更し、保存します。
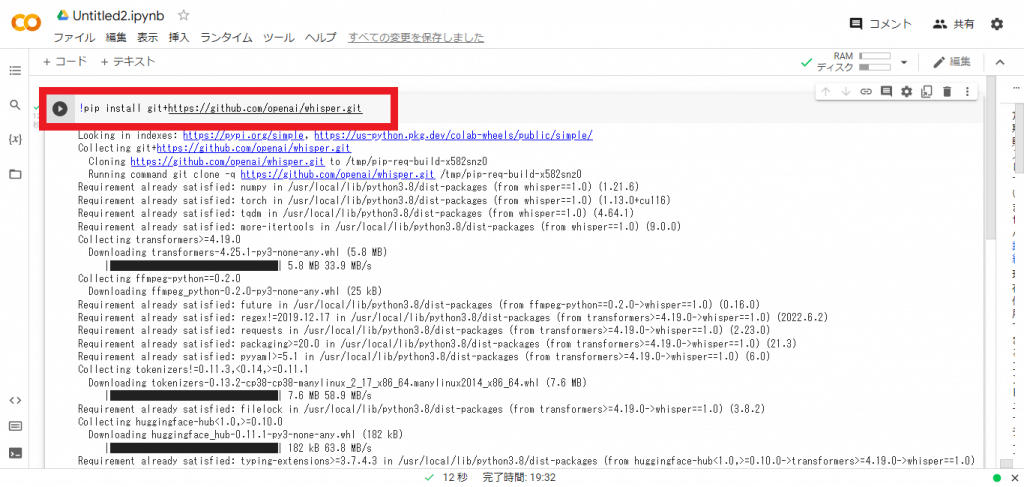
次はWhisperをGoogle Colaboratoryにインストールするため、下記のコマンドを入力していきます。
!pip install git+https://github.com/openai/whisper.git
コマンドを入力し終えたら左側の実行ボタンを選択しましょう。
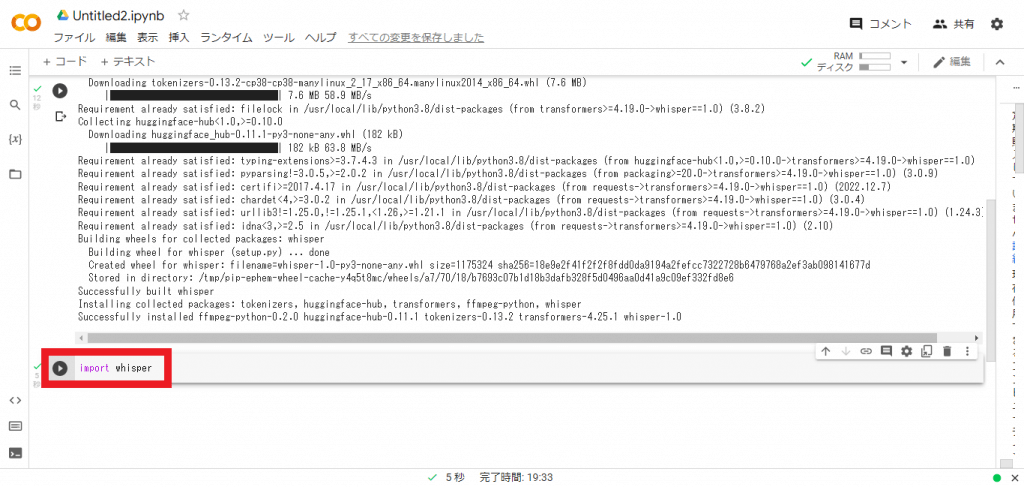
次に別のコードを作成し、「import whisper」と入力します。すると5秒程で実行が完了するため、画面左側のファイルを選択します。
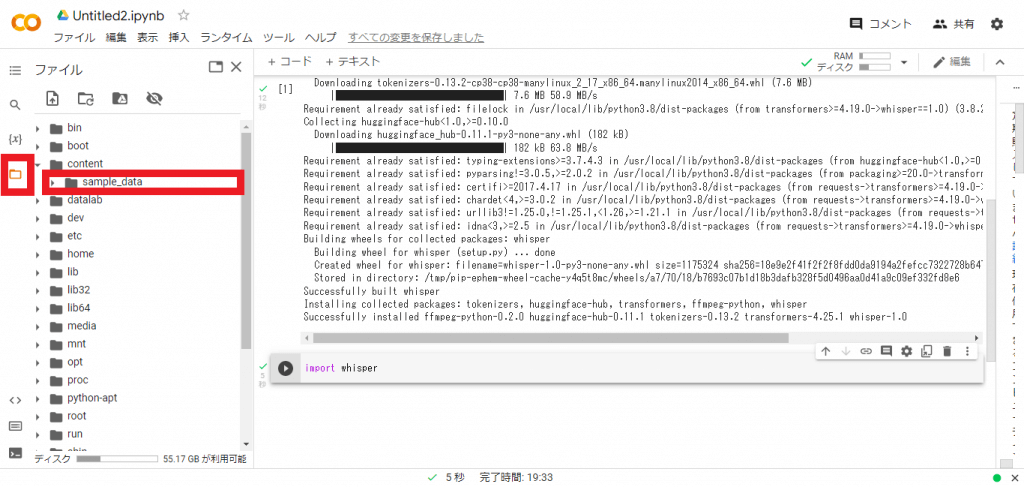
ファイルを選択した後、「content」と書かれたファイルを開きましょう。上の画面になったら、content右側のケバブアイコンを選択し、PCから音源をアップロードします。今回は「ongen 0〜3」の4つのファイルをアップロードしました。
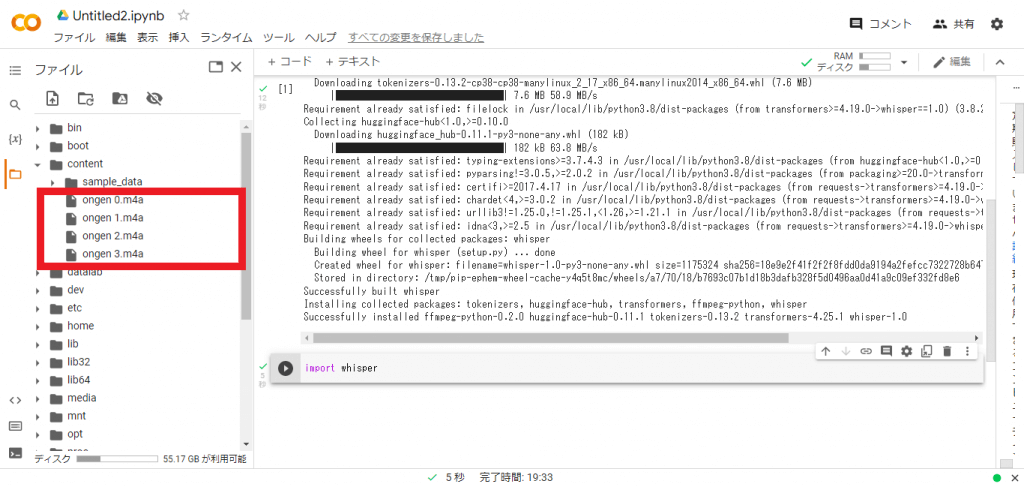
上の画像のようにアップロードした音源がcontentの下層に表示されたら成功です。
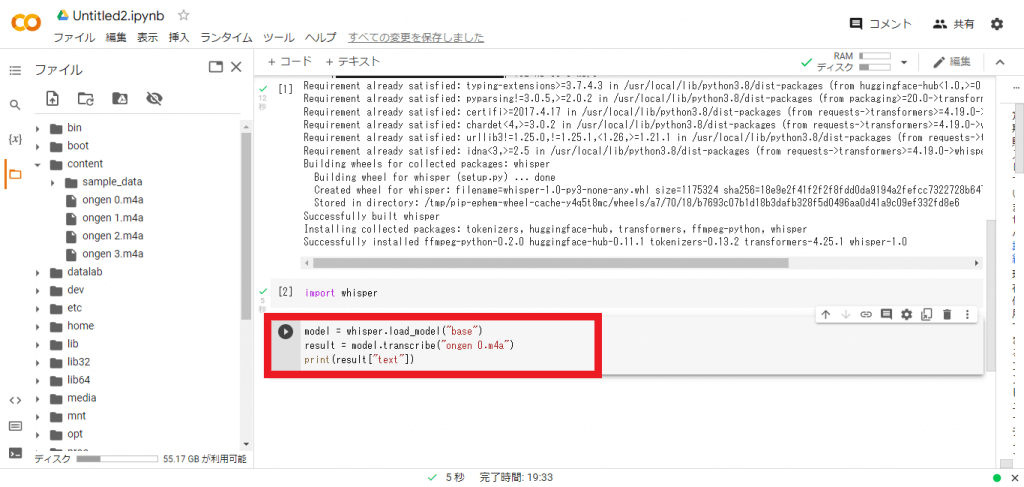
そして最後に下記のコマンドを入力します。
model = whisper.load_model(“base”)
result = model.transcribe(“ファイル名”)
print(result[“text”])
「ファイル名」の部分は、文字起こしを実行したいファイル名を入れる必要があるため、まずは「ongen 0.m4a」を入力しました。「base」の部分は、先述した5つのモデルサイズを指定できる項目です。
入力が完了したら、いよいよ実際の文字起こしに入っていきます。
まずほとんど無音の状態で録音した「ongen.m4a」のファイルを文字起こししていきます。5つのモデルサイズで同じ文章を比較していますので、モデルサイズごとの精度の違いを端的に感じ取れるかと思います。文字起こしに要する時間は使用するPCのスペックにも影響を受けるため、実際の使用感や、使いやすさはご自身で確かめてください。
※読み上げを行ったテキスト
バーティカルSaaSとは各業種に特化したSaaSです。各業種に特化したサービスを導入することで、業界特有の課題を解決できる可能性が高まります。その反面、日々新たなサービスがローンチしている状況のため、自社にマッチした製品を知ることが難しくなっています。今回のカオスマップは「自社の業種に特化したAIサービスを知りたい」といったご希望にお答えするため、100社以上の製品を独自調査した上で作成いたしました。
引用:バーティカルSaaS AIカオスマップを初公開 – アイスマイリー
感想▼
まず1番小さいモデルの「tiny」を試してみましたが、最初の「バーティカル SaaS」の部分が間違っており、文章全体を通じて漢字とカタカナ、平仮名の書き起こしが不十分な印象を受けます。「自社にマッチした製品」の箇所は「実際に待ちした製品」に書き起こされており、そのまま通読しては意味が通じない状態になっています。
感想▼
tinyの次に大きなbaseモデルでは、冒頭の「バーティカル」を文字起こしすることに成功しています。しかし「SaaS」を「サースト」と誤訳しているほか、「ローンチ」も「論知」と誤訳しています。baseモデルの方が漢字・カタカナ・平仮名の書き分けが上手くいっている印象を受けますが、誤字に関してはtinyモデルと変わらずまだまだ改善が必要なレベルです。
感想▼
smallモデルではなぜか句読点が消えました。全体を通じてbaseモデルよりも文字起こし精度が高い印象を受けますが、「バーティカルサースト」や「ロンジ」、「カウスマップ」などのカタカナ語が上手く文字起こしできておりません。とはいえ誤字に気づきながらも通読は可能な範囲の文字起こし精度だと感じました。
感想▼
mediumモデルでは「Vertical Service」と「ローン値」の誤字以外、ほとんどの音を正確に文字起こしできています。mediumモデルで書き起こした文章は、句読点なども適切なタイミングで打たれ、通読ストレスが軽減された印象を受けます。
感想▼
largeモデルは、5つのモデルの中で初めて「Vertical SaaS」を書き起こし、「ローンチ」や「カオスマップ」も一字違わず文字起こしすることに成功しています。句読点だけ打たれていませんが、ほぼ全ての音が正確な日本語として書き起こされました。

ここからは生活騒音下で録音した音声がどれくらいの精度で文字起こしされるのか調査した結果をまとめています。

感想▼
温風ヒーター(55dB-A)の生活騒音下において読み上げた音声では、largeモデルでも「バーティカルSaaS」を文字起こしすることができませんでした。ongen 0の無音の状況下よりも若干精度が落ちますが、その他の文章は精度高く文字起こしされており、生活騒音下でも十分文字を起こせることが分かります。

感想▼
掃除機の騒音が隣の部屋で聞こえるような状況下で録音した音声も、温風ヒーターの稼働音と同じく精度高く文字を起こすことができました。次の「ニュース番組の音声」と比べて、温風ヒーターと掃除機の音の性質が似ているためか、文字起こし文章にも大きく差が出ない結果となりました。

感想▼
ニュース番組の音声が聞こえる部屋で音声を収録した場合、baseモデルでは無音の状態下での音声(ongen 0)の時と同じように「ローンチ」を「論知」と文字を起こすなどのミスが見られました。一方のlargeモデルでは「Vertical Source」以外は正確に文字を起こすことができており、人の声が聞こえるかどうかよりも、騒音レベル(dB-A)の大きさが文字起こしの精度に影響を与えると考えられます。
ここからは応用編です。Whisperの処理経過を可視化していきます。先ほどから使用している下記のコマンドに「verbose=True」を追加します。
追加前▼
model = whisper.load_model(“base”)
result = model.transcribe(“ファイル名”)
print(result[“text”])
「vorbose=True」追加後▼
model = whisper.load_model(“large”)
result = model.transcribe(“ongen 0.m4a”, verbose=True)
print(result[“text”])
そして約1分後に表示されたテキストが下記になります。
Detecting language using up to the first 30 seconds. Use `–language` to specify the language
Detected language: Japanese
[00:00.000 –> 00:04.000] Vertical SaaSとは 各業種に特化した SaaSです
[00:04.000 –> 00:11.000] 各業種に特化したサービスを導入することで 業界特有の課題を解決できる可能性が高まります
[00:11.000 –> 00:15.000] その反面 日々新たなサービスが ローンチしている状況のため
[00:15.000 –> 00:19.000] 自社にマッチした製品を知ることが 難しくなっています
[00:19.000 –> 00:25.000] 今回のカオスマップは 自社の業種に特化した AIサービスを知りたいといったご要望にお答えするため
[00:25.000 –> 00:30.000] 100社以上の製品を独自調査した上で作成いたしました
まず注目したいのが「Detected language: Japanese」の部分です。入力した音源をしっかりと「日本語」として検出していることが分かります。また、30秒間の音声を意味のまとまり、句読点のタイミングで区切っており、かなりの精度で日本語を認識出来ていることが分かりました。読み上げに使用した文章と比較しても全く違和感なく、通読も可能な文章として文字が起こされています。
最後に「language=”ja”, task=”translate”」を加えて、日本語の文字起こし文章を英語に翻訳したいと思います。先ほどのコマンドに追加するだけです。
「language=”ja”, task=”translate”」追加後▼
model = whisper.load_model(“large”)
result = model.transcribe(“ongen 0.m4a”, verbose=True, language=”ja”, task=”translate”)
print(result[“text”])
そして翻訳された文章が下記になります。
[00:00.000 –> 00:04.000] Vertical source is a source specialized for each industry.
[00:04.000 –> 00:07.000] By introducing services specialized for each industry,
[00:07.000 –> 00:11.000] the possibility of solving industry-specific problems increases.
[00:11.000 –> 00:15.000] On the other hand, because new services are being launched every day,
[00:15.000 –> 00:19.000] it is difficult to know the product that matches the company.
[00:19.000 –> 00:23.000] This ChaosMap was created after investigating over 100 products
[00:23.000 –> 00:30.000] to answer the demand of customers who want to know the product that matches the company.
一度英文に翻訳したため、所々文末の表現が変わっています。例えば「自社にマッチした製品を知ることが 難しくなっています」の部分は「自社にマッチした製品を知ることは難しい」に変化しており、やや英文を翻訳した時の堅い印象が出てしまっています。その一方で語尾の「作成いたしました」が「作成したものです」と少し柔らかい表現に変化しているのも興味深い発見でした。1点だけ「バーティカルソース」と誤訳していますが、そもそもの英文が「Vertical source」で間違っていたため、英文→日本語も誤訳になったと分かります。単語1語、2語程度のミスであれば英文翻訳も十分利用可能だと感じました。
2023年3月1日にOpenAIから「Whisper API」が公開されました。このリリースにより、開発者はWhisper APIとChatGPT APIを用いて、WhisperおよびChatGPTモデルをアプリや製品に統合できるようになりました。
ChatGPTおよびWhisper APIの初期ユーザーには、グローバルな学習プラットフォームである「Quizlet」や、スピーキングに特化した言語学習アプリ「Speak」などがあります。特に会話練習に対する学習者への正確なフィードバックは、Whisper APIの統合によって得られた価値といえます。
Whisper APIを活用した文字起こしサービスに「writeout.ai」があります。writeout.aiはWhisper APIおよびChatGPT APIを活用しており、読み込まれた音声ファイルの高精度な文字起こし、翻訳を可能にしています。
writeout.aiは以下の流れで利用可能です。
文字起こしが可能な音声ファイルには、「mp3」「mp4」「mpeg」「mpga」「m4a」「wav」「webm」があり、最大ファイルサイズは25MBとなっています。
WhisperをHugging Face上で利用する場合は文字起こし時間に30秒の制約がありますが、writeout.aiで文字起こしを行う場合はファイルサイズ25MBの制約となるため、より長時間の音声を文字起こしできるようになっています。
WhisperをHugging FaceやGoogle Colaboratoryで実行した後、実際に議事録や取材音声などの文字起こしで使いたい方はwriteout.aiの活用を検討してみるとよいでしょう。
今回はWhisperの文字起こしの精度について調査してみましたが、無音の状況下ではほぼ100%文字起こしに成功し、55dB-A程度の生活騒音下ではやや翻訳精度が落ちる印象でした。それでも固有名詞の間違いやそれに付随する文章の表現に誤りが認められる程度で、ノイズによって文章全体が崩れるようなことはありませんでした。
話題の「ChatGPT」を開発したOpenAIによる音声認識モデル「Whisper」。Whisperの文字起こし精度は全く問題ありませんが、使用するPCのスペックや通信状況に応じて処理上限に達することもあるため、ビジネスシーンで安心して活用できるのはもう少し先のことかもしれません。
AIsmileyでは日本語特化や多言語対応の音声認識や音声解析、議事録作成を目的としたAIサービスを提供する企業の情報を取り揃えております。自社の業務効率化に適したAIサービスを探されている方は是非こちらから様々なサービスをご覧ください。
AIについて詳しく知りたい方はこちらの記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
WhisperとはOpenAIが文字起こしサービスとして公開した無料の音声認識モデルです。WhisperはWebから収集した68万時間分の多言語音声データを教師付きデータで学習させており、高い精度で入力した音声を文字起こしすることが可能になっています。
Whisper APIとChatGPT APIを用いて、WhisperおよびChatGPTモデルをアプリや製品に統合できます。
Aismiley編集部が調査した結果、無音の状況下ではほぼ100%文字起こしに成功し、55dB-A程度の生活騒音下ではやや翻訳精度が落ちる印象でした。それでも固有名詞の間違いやそれに付随する文章の表現に誤りが認められる程度で、ノイズによって文章全体が崩れるようなことはありませんでした。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。















FOLLOW US
SNSをフォローして、最新情報をチェックできます!







AI製品・ソリューションの掲載を
希望される企業様はこちら