

生成AI

最終更新日:2024/04/26
 日本企業が開発したLLM8選
日本企業が開発したLLM8選
ChatGPTをはじめとする最新AI技術が世界で普及する中で、世界的大手企業も独自のAI製品の開発に取り組んでいます。Google社のBardやMicrosoft社のBingなどのLLM(大規模言語モデル)がその代表例ですが、日本国内でも独自のLLMを開発する企業が増えています。
海外企業のLLMは英語などの外国語がベースのものが多く、日本語への応対や精度の向上に時間を要します。一方、国産LLMであれば日本語に特化しているため、高品質な日本語の出力が期待できます。
本記事では、日本企業が開発したLLM製品や、国産LLMの開発に取り組む企業の事例を紹介します。国内企業が手掛けるLLMや日本語LLMサービスの導入を検討している企業の方は、ぜひ参考にしてください。
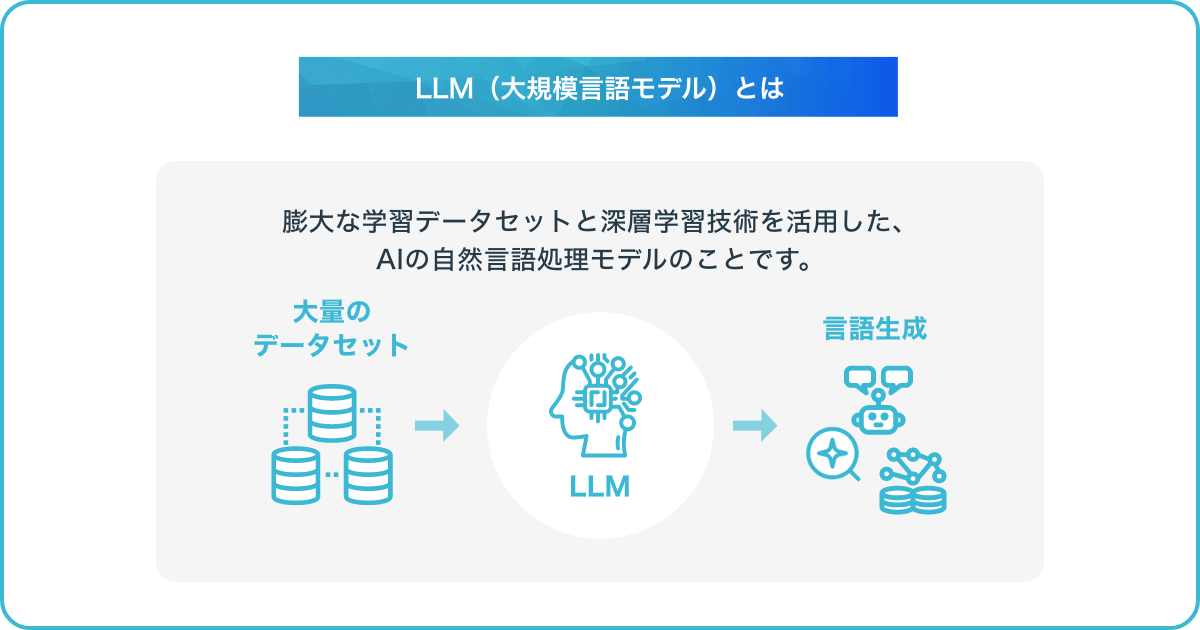
LLM(Large Language Models/大規模言語モデル)とは、膨大な学習データセットと深層学習技術を活用した、AIの自然言語処理モデルのことです。巨大テキストデータセットを用いた事前学習を経て、性能を最適化する微調整(ファインチューニング)というプロセスにより高精度なタスク処理を実現しています。
従来の自然言語モデルと比べて、LLMではコンピュータが処理する仕事量やデータ量、パラメータ数が巨大化しています。人間の自然な会話に近い違和感のないやり取りや、テキスト生成や文章要約、質疑応答といったさまざまな自然言語処理を実行可能です。
LLMのタスク処理の流れや種類など、詳しくはこちらの記事もご覧ください。
LLM(大規模言語モデル)とは?種類・活用サービス・課題を徹底解説

海外の大手テック企業だけでなく、LLM開発に力を入れている日本企業も最近は多く見られます。ここからは、日本企業が開発したLLMを紹介していきます。
NTTが開発した独自の日本語LLM「tsuzumi」は、軽量かつ高い日本語処理性能を誇る世界トップレベルのLLMモデルです。
「tsuzumi」は、パラメータサイズが小さい軽量モデルでありつつも、日本語の出力精度が高い点が特徴です。現在発表されている70億パラメータの「軽量版」と6億パラメータの「超軽量版」は、いずれもGPT-3の1,750億パラメータに比べて圧倒的に小さいことがわかります。
コンパクトでありながらも自然な日本語をスピーディに処理できる上、従来のLLMに比べて学習や推論のコストが大幅に削減できることが期待できます。
当初は特定の業界に特化したサービス提供を目指し、メディカルやコンタクトセンター分野などでの先行トライアルが行われていました。2024年3月に商用サービスを提供開始することが発表されています。
株式会社サイバーエージェントも日本語LLMを独自開発してきた企業の1つです。2023年5月には、当時国内で最大級規模となるモデルのオリジナル日本語LLMをHugging Face Hub上で公開しました。
その後、2023年11月にはより高性能な70億パラメータ・32,000トークン対応の日本語LLMを一般公開しています。
最新の日本語LLMは、70億パラメータのベースモデル「CyberAgentLM2-7B」と、チャット形式でチューニングを行った「CyberAgentLM2-7B-Chat」の2タイプです。50,000文字相当の大容量テキストを処理可能で、商用利用を視野に入れたオープンライセンスで提供を開始しています。
サイバーエージェント、独自日本語LLMのバージョン2を一般公開
ストックマーク株式会社は、2023年10月に独自の日本語特化LLM「Stockmark-13b」をオープンソースで公開しました。日本語単独としては最大規模になる130億パラメータのモデルで、Amazonが提供するAWS LLM 開発支援プログラムにて計算リソースの確保や技術的支援を受けています。
日本での商用利用に適した精度やMIT Licenseによる利用しやすさに強みがあり、ChatGPTに比べて約4倍の回答速度を実現しています。また、ビジネス関連情報や特許情報も網羅しており、従来の生成AIで課題とされてきたハルシネーションも抑制されている点が特徴です。
ストックマーク、日本語特化のLLM「Stockmark-13b」をオープンソースで公開
東京大学松尾研究室は2023年8月に、100億パラメータサイズの大規模言語モデル「Weblab-10B」を非商用ライセンスで公開しました。「Weblab-10B」では、日本語と英語それぞれの学習データセットを用いて、事前学習と事後学習を実施しています。
主要言語のみのデータセットを用いる多くのLLMとは異なるアプローチを取り、言語間の知識移転を行うことで日本語の精度を向上しています。事後学習後のモデルでは、日本語のベンチマーク(JGLUE評価値)にて公開済みの日本語大規模言語モデルで最高水準を打ち出しています。
東大松尾研究室、日英対応の100億パラメータサイズの大規模言語モデル「Weblab-10B」を公開
生成AIを手がけるStability AI Japan社は2023年8月に、オープンソースのLLM「StableLM」の日本語版「Japanese StableLM Alpha」をリリースしました。
公開されたのは、70億パラメータの日本語向け汎用言語モデル「Japanese StableLM Base Alpha 7B」と、指示応答言語モデル「Japanese StableLM Instruct Alpha 7B」の2種類です。日本語向け汎用言語モデルは、日本語と英語のテキスト生成に特化しています。
また、指示応答言語モデルは、Supervised Fine-tuningという手法を用いて、汎用言語モデルにて追加学習を行い、ユーザーの指示に対する受け答えが可能です。モデルは、Hugging Face Hubにおいて公開され、推論や追加学習にも対応しています。
Stability AI Japan「Japanese StableLM Alpha」をリリース、日本語向け汎用言語モデルと指示応答言語モデルを一般公開。
株式会社Preferred Networksは2023年9月、130億パラメータのLLM「PLaMo-13B」をオープンソースソフトウェアライセンスで公開しました。日本語と英語に対応した当モデルは、両言語を合わせた性能が世界トップレベルと言われ、研究・商用で利用可能です。
学習には、同社が作成した.4兆トークンもの大規模なデータセットと、国立研究開発法人産業技術総合研究所のAI橋渡しクラウド(ABCI)を使用。結果として、30億パラメータというコンパクトなモデルで、高性能を打ち出すことに成功しています。
また、2024年中に商用サービス提供を目指し、新会社Preferred Elementsを設立し、大規模なマルチモーダル基盤モデル開発を加速させることを公表しています。
Preferred Networksが日英対応言語モデルを公開。2言語あわせたベンチマーク評価で世界トップレベル
チャットボット「りんな」を手掛けるrinna社は2022年9月、日本語に特化した画像生成モデル「Japanese Stable Diffusion」をオープンソースで公開しました。
学習データとして、LAION-5Bの日本語サブセットをはじめ、約1億枚の日本語キャプション付き画像を利用。画像生成AIのStable Diffusionでは扱いが難しいとされていた、和製英語やオノマトペなどの日本語固有の表現も、スムーズに画像生成に反映されることが期待できます。
日本語入力からの画像生成を最適化している上、モデルを使用したAPIも提供されており、画像生成機能をアプリケーションに実装可能です。
rinna、日本語特化画像生成モデル「Japanese Stable Diffusion」を公開
パーソナルAI技術の開発や実用化を行うオルツ社は、大規模言語処理モデル「LHTM-2」を開発しました。LHTM-2はOpenAI社のGPT-3と同水準のパラメータで構成されており、機械翻訳やテキスト生成、対話などのさまざまなタスク処理が可能です。
LHTM-2に個人のライフログを入力し、思考を再現する形で対話を行う実験では、入力された個人と似た言語活動を行うモデルの開発に成功しています。より自然でパーソナライズされた対話や、精度の高い議事録の作成など幅広い用途での活用が期待されています。

ここからは、国産LLMの開発に取り組む日本企業を紹介していきます。現在は開発中のモデルも、今後国内外で大きく活躍する可能性があるので、ぜひチェックしておきましょう。
NECは、2023年12月に世界トップクラスの日本語性能を持つ独自LLMを開発したと公表しました。独自に収集、加工した多言語データを利用して学習を行い、高性能を有しながらも130億パラメータとコンパクトなサイズに抑えることに成功しています。
また、カスタマイズにより幅広い業界や業務で活用することが可能です。NEC社内において、すでにLLMを文書作成や社内システム開発のソースコード作成業務といった社内業務に導入されており、作業の効率化に役立っています。
NEC、世界トップクラスの日本語性能を持つ軽量な大規模言語モデルを開発
ソフトバンク株式会社は2023年10月に、生成AI開発向けの計算基盤開発に本格的に着手したことを公表しました。子会社のSB Intuitions(ソフトバンク・イントゥイションズ)株式会社にて、2024年内の国産LLM構築を目指しています。
国内最大級の計算基盤は、まずはソフトバンクグループ内で段階的に利用しながら、各大学や研究機関、企業などへ提供される予定です。同時に、3,500億パラメーターの日本語特化の国産LLMに搭載されることも決まっています。
ソフトバンク、国内最大級の生成AI開発向け計算基盤の稼働を開始
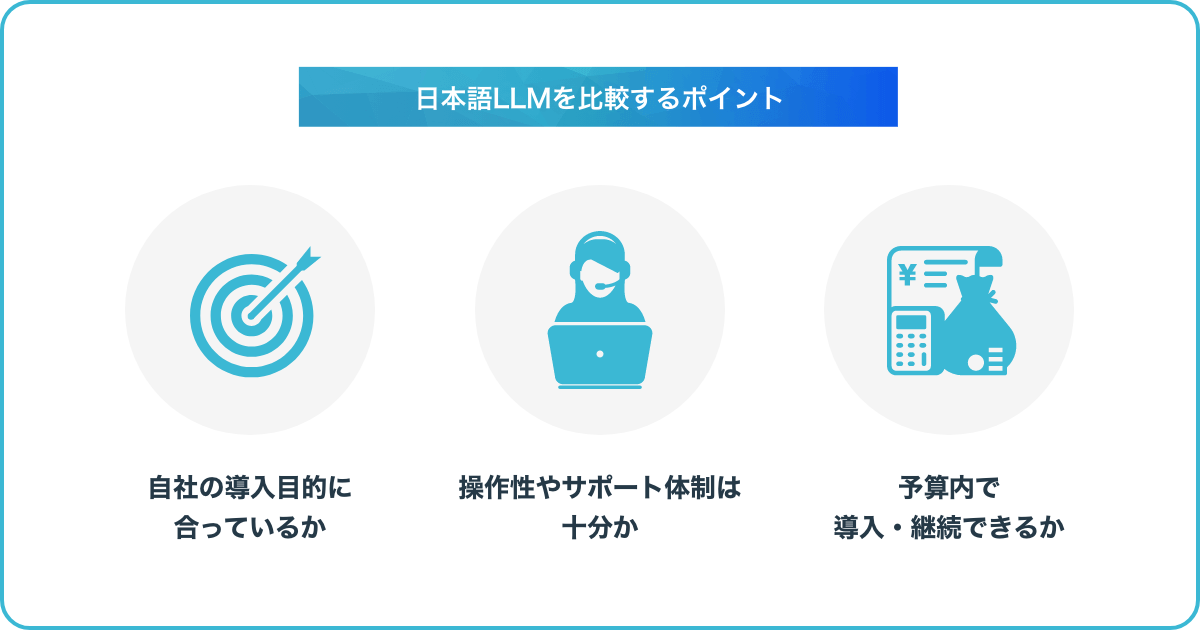
ここで、日本語LLMを比較検討する際のチェックポイントについて解説します。自社組織や事業に適した日本語LLMや国産LLMを選ぶために、ぜひお役立てください。
LLMをはじめとする生成AIを導入する際には、AIを使う目的や用途に合ったものを選ぶ必要があります。例えば、営業チームの業績が伸び悩んでいる場合は、顧客管理や販促活動に役立つツール、マーケティング業務ならビッグデータの解析と顧客ニーズの抽出を自動化できるものなどが有用です。
目的や用途を明確化する上で、まずは自社の課題を洗い出し、具体的な目標を設定してから対応したサービスを選びましょう。課題の洗い出しは、業務フローや担当部署の確認、担当者へのヒアリングなどを行うとスムーズです。
LLMを導入する上で、操作性やサポート体制などの要件を確認しておくことが大切です。具体的には、以下のようなポイントをチェックしましょう。
トライアルなどでお試しできるものもあるので、どの形態が適しているのか見極めるために利用してみましょう。
AIサービスの多くは有料のため、予算内で導入・運用できるかを事前に確認する必要があります。サービスを提供するベンダーは多数あるので、契約プランについて比較検討することが大切です。
初期費用だけでなくランニングコストも算出する必要があり、見積もりを依頼してみても良いでしょう。無料トライアルを使って、実際の製品を確認してから導入することも可能です。また、契約年数やカスタマイズ性など長期的な運用に関わる条件も考慮しておくと無難です。

日本語LLMでは、ファインチューニングを通してより最適化されたLLMを構築することが可能です。ファインチューニングとは、事前学習済みのAIモデルを取得し、新しいデータセットを用いて新しいタスクトレーニングを行うことです。
ファインチューニングの方法には、パラメータを含めてフルで調整するFFT(Full Parameter Fine-Tuning)や、ユースケース固定のデータを使って学習を行うPEFT(Parameter-Efficient Fine-Tuning)などがあります。
基本的なファインチューニングの手順は、以下の通りです。
文章要約や翻訳、チャットボットなど自然言語タスクに特化したLLMは、ビジネスや日常生活に広く活用され始めています。ChatGPTの知名度が高いですが、国内でも日本語LLMや国産LLMを開発・運用する企業が登場しており、提供サービスは今後さらに増えていくでしょう。
LLMを含む生成AIを企業や事業に有効活用するために、自社の目的や課題解決に合ったサービスを選ぶことが大切です。サービス提供企業の一覧を下記よりダウンロードいただけますので、比較検討の際にぜひご活用ください。
日本語対応のLLMには、NTTの「tsuzumi」や株式会社サイバーエージェント「CyberAgentLM」、Stability AI Japan「Japanese StableLM Alpha」などがあります。また、ChatGPTなど海外発のLLMでも日本語が使えるものが増えています。
オープンソースの日本語LLMには、Stability AI Japanにの「Japanese Stable LM Beta」やストックマーク株式会社が独自開発した「Stockmark-13b」などがあります。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!








AI製品・ソリューションの掲載を
希望される企業様はこちら