

生成AI

最終更新日:2024/02/22
 Python画像認識とは?
Python画像認識とは?
現代のテクノロジーの進展において、Pythonを用いた画像認識は重要な役割を担っています。この記事では、Pythonを活用した画像認識の基本から、画像認識の種類や仕組みを解説していきます。また、OpenCVの機能や使い方、画像データの読み込みや処理方法などを解説します。最後に、簡単にpythonの環境を構築し、画像分類モデルの構築を分かりやすく解説していきます。

画像認識は、コンピューターが画像に含まれる対象を識別する技術で、ディープラーニングの進歩により近年飛躍的に発展しました。
この技術は、例えば農業分野では、ドローン撮影を通じて作物の成長状態を把握するために使用されています。これにより、農家は作物の健康状態や必要な水分量をより効率的に管理できるようになりました。
製造業の生産管理でも画像認識技術は重要な役割を果たしています。
製品の品質検査では、コンベヤベルト上を流れる製品の画像をリアルタイムで分析し、欠陥がある製品を自動で識別します。
これは、従来の人手による検査よりも速く、かつ高精度で行えるため、製造業の効率と品質の向上に大きく貢献しています。
さらに、画像認識技術は、以下のように、様々な分野での応用が進んでいます。
これらの進展は、画像認識技術の可能性を広げ、今後も多くの分野で革新をもたらすことが期待されます。
このように、画像認識技術は私たちの生活の多くの面で革新をもたらし、その進歩は私たちの未来を大きく変える可能性を秘めています。それは単なる技術的な進歩にとどまらず、日常生活やビジネスのあり方を根本から変える力を持っています。
画像認識技術は、その使用方法や目的に応じて、主に「物体認識」と「物体検出」の二つの大きなカテゴリに分類されます。物体認識は、画像内の特定の対象を識別する技術で、具体的には「この画像には自転車と人が写っている」といった対象の識別がその例です。この技術は、画像内の対象物が何であるかを理解することを目的としています。
一方で、物体検出は、画像内の対象の位置や数を特定する技術です。これは、例えば自動運転車が周囲の環境を認識し、障害物や歩行者を検出するのに用いられます。物体検出技術は、対象物が画像のどの部分に存在するか、またその大きさや形状はどうかなど、より詳細な情報を提供します。
これら二つの技術は互いに補完関係にあり、多くの応用分野で組み合わせて使用されています。例えば、セキュリティシステムでは物体認識を用いて人や車両を識別し、その後、物体検出技術でその位置や動きを追跡します。
このように、画像認識技術のこれらのカテゴリは、それぞれが独自の役割を持ちながらも、多くの場合で連携して機能しています。
画像認識の種類を理解することは、この技術がどのように機能し、様々なアプリケーションでどのように利用されているかを深く理解する上で重要です。それにより、ビジネスや研究での新たな応用可能性を見出すことができるでしょう。
画像認識の仕組みを理解するためには、そのプロセスを深く掘り下げることが重要です。このプロセスは、まず大量の画像データにタグ付け(アノテーション)を行うことから始まります。このアノテーションプロセスでは、各画像に対象物や特徴などのラベルが付けられ、AIシステムが何を学習すべきかを理解する手助けをしているのです。
次に、画像データは前処理を経てAIが学習しやすい形に変換されます。この前処理には、画像のサイズ調整、色の正規化、ノイズの除去などが含まれます。これらのステップは、AIが画像から重要な特徴をより効率的に抽出し、学習するのを容易にするために必要なステップです。
特に、CNN(畳み込みニューラルネットワーク)という手法が画像認識において頻繁に用いられます。CNNは、画像の局所的な特徴を捉える畳み込み層と、それを組み合わせてより高度な特徴を学習する全結合層から構成されています。畳み込み層では、フィルターを用いて画像の特徴量を抽出し、これにより画像内の重要なパターンや構造を識別しています。
この学習プロセスを経た後、AIは新たな画像に対しても物体を認識・検出する能力を持ちます。学習したモデルは、新しい画像に遭遇した際、それが持つ特徴量を以前の学習データと照らし合わせ、どのカテゴリに属するかを識別します。このようにして、画像認識技術は日々進化し、より正確で効率的な認識能力を獲得しています。

OpenCV(Open Source Computer Vision Library)は、オープンソースのコンピュータビジョンライブラリです。1999年にインテルによって開発され、その後多くの貢献者によって拡張されてきました。コンピュータビジョンは、コンピュータが画像や動画を解析して、それらから情報を抽出する技術のことを指します。
・色空間の変換
RGBからグレースケール、HSVなど、異なる色空間への変換を行うことで、画像解析の柔軟性が高まります。
・リサイズと回転
画像のサイズを変更し、任意の角度で回転させることができます。
・トリミング
画像から特定の領域を切り取り、焦点を絞り込むことができます。
・平滑化
平滑化でノイズを減少させ、エッジ強調で重要な特徴を際立たせることができます。
・エッジ検出
ソーベルフィルタやキャニー法などを使用して、画像内のエッジ(境界線)を識別します。
・形状検出と解析
画像内の特定の形状(円、四角形など)を特定し、その特徴を抽出します。これにより、対象物の識別や分類が可能になります。
・顔検出
OpenCVのアルゴリズムを使用して、画像内の人間の顔を識別します。
・物体追跡
動画内で特定の物体を時間を追って追跡し、その動きを分析します。
・特定の物体の検出
訓練されたモデルを用いて、例えば車や人物など、特定の物体を画像内で識別します。
OpenCVは、機械学習やディープラーニングのモデルを画像処理に統合する機能を提供します。これにより、複雑な画像分類や物体検出タスクを実現できるようになります。例えば、ニューラルネットワークを使った顔認識や、畳み込みニューラルネットワーク(CNN)を用いた物体検出が可能になります。
 ここでは、OpenCVのインストールから画像分類モデルの作り方まで解説していきます。手順は以下の通りです。
ここでは、OpenCVのインストールから画像分類モデルの作り方まで解説していきます。手順は以下の通りです。
1.GoogleアカウントでGoogle colaboratryに
2.アクセスファイル→「新しいノートブック」をクリックして新規ノートブックを開始する
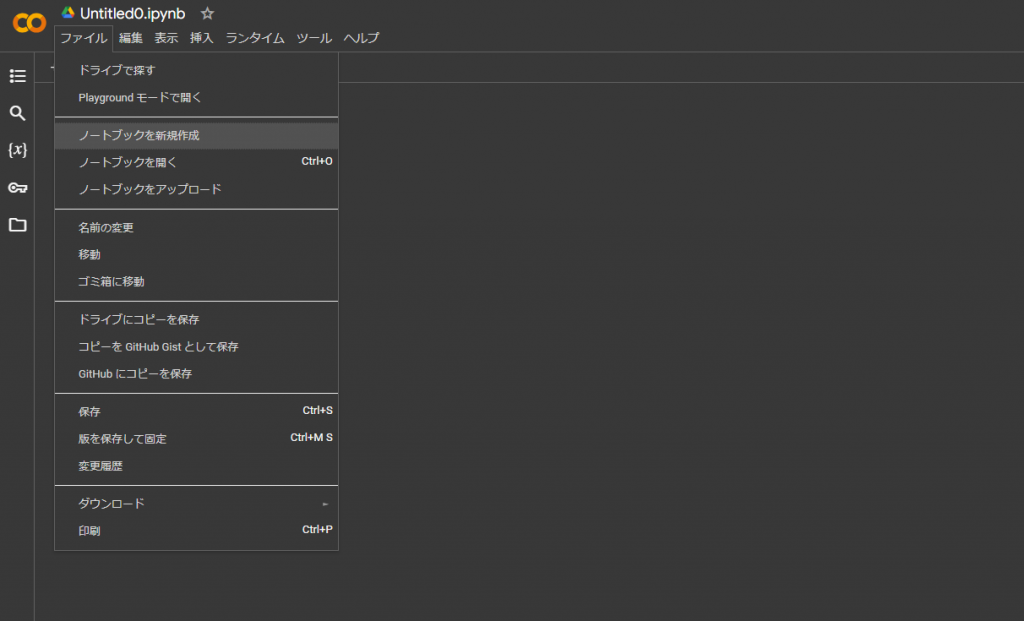 3.コードセルを選択
3.コードセルを選択
4.下記コードを入力し、OpenCVをインストール
!pip install opencv-python
5.ファイルから認識させたい画像をアップロード
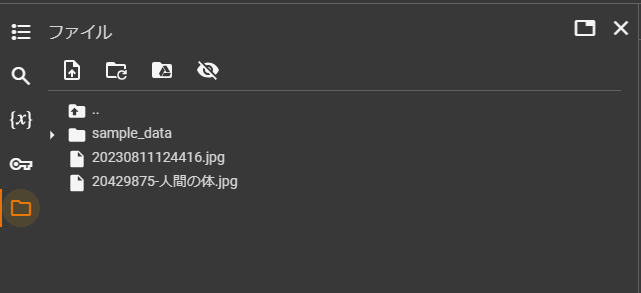
6.下記のコードをコピー&ペースト
import cv2
import numpy as np
from tensorflow.keras.applications.mobilenet_v2 import MobileNetV2, preprocess_input,
decode_predictions
from tensorflow.keras.preprocessing import image
# MobileNetV2をロード(他のモデルでも構いません)
model = MobileNetV2(weights='imagenet')
def recognize_image(image_path):
# OpenCVを使用して画像を読み込む
img = cv2.imread(image_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 画像をモデルの入力サイズにリサイズ
img = cv2.resize(img, (224, 224))
# 画像の前処理
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
# 画像をモデルに渡して予測
preds = model.predict(x)
# 予測結果をデコード
print('Predicted:', decode_predictions(preds, top=3)[0])
# 画像のパス
image_path = '/path/to/your/image.jpg'
# 画像認識関数を実行
recognize_image(image_path)
7.’/path/to/your/image.jpg’は、認識させたい画像のパスに置き換える
8.実行する
本記事ではPythonを用いた画像認識技術について深く掘り下げましたが、この分野の未来と応用可能性は計り知れません。医療分野では、画像認識技術を用いた疾患の早期発見や診断精度の向上が進むでしょう。自動運転車の開発においても、周囲の環境を正確に認識し判断するための核心技術として、画像認識は不可欠です。さらに、セキュリティ分野では顔認証システムの精度向上や新たな認証方法の開発が進んでいます。これらの進展により、Pythonと画像認識技術の組み合わせが、私たちの生活や産業に革新をもたらし続けることでしょう。
画像認識の導入事例に関して知りたい方はこちらの記事をご覧ください。
【最新】画像認識AIの導入活用事例10選!各業界企業の課題と導入効果まとめ
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。















FOLLOW US
SNSをフォローして、最新情報をチェックできます!






AI製品・ソリューションの掲載を
希望される企業様はこちら