

ディープラーニングを用いた画像の物体検出とは?モデルや応用例を紹介
最終更新日:2024/01/18

近年のAI・人工知能技術の発達は著しく、さまざまな分野、業界でAIを導入する動きが加速しています。その中でも、画像に写る物体を検出するAIやディープラーニングモデルには大きな注目が集まっており、今後さまざまな分野で活用されていくことが期待されているのです。
では、それらの技術は具体的にどのような仕組みで成り立っているのでしょうか。今回は、画像に写る物体を検出するAIについて学ぶ上で欠かせない「物体検出」についてご紹介するとともに、「物体検出によく使われるディープラーニングモデル」などについても詳しく解説していきます。ぜひ参考にしてみてください。
物体検出とは

物体検出とは、取り込んだ画像の中から「物体の位置、種類、個数」を特定する技術のことを指します。物体の種類を分別すること自体は画像分類でも実現可能ですが、物体検出ではさらに「物体の位置の絞り込み」「対象外の物体の排除」を行うことで、対象物の位置・個数まで正しく検出することができます。
そんな物体検出は主に外観検査で活用されており、医療・建設業・製造業といったさまざまな分野で導入され始めています。最近ではスマートフォンのカメラでも利用できるケースが多くなっており、顔の検出などにも活用され始めている状況です。
また、近年注目を集めている自動車の自動運転においても、「歩行者を検出して事故を未然に防ぐ」という目的で活用されています。さまざまな分野で活用され始めているため、これからの時代において非常に重要な役割を担う技術といえるでしょう。
物体認識と物体検出の違い
物体認識は、一般的に「画像内に何があるのか」を特定する技術のことを指します。たとえば、猫が写っている画像であれば「画像の中に猫がいること」を特定することはできますが、その猫が画像内のどこに写っているのかを特定することはできません。あくまでも「画像内に何があるか」を特定することだけが、物体認識の特徴といえるわけです。
それに対し、物体検出は「何がどこに写っているのか」を特定することができます。そのため、「黒い猫」と「茶色い犬」という混同しそうな画像でも「それぞれがどこに写っているか」という部分まで特定することができるわけです。物体検出のほうが、より画像内の情報を詳しく特定できる技術であることがお分かりいただけるでしょう。
物体検出によく使われるディープラーニングモデル

R-CNN
R-CNNとは、従来の物体検出モデルをCNN(画像認識モデル)に置き換えたものです。画像内にdetectorを走らせてしまうと、どうしても計算コストが大きくなってしまいます。そのため、最初に「物体があると予想できる領域を提案させる」というアプローチになっているのが特徴です。これにより、detectorは物体がありそうな領域だけを計算すればよくなるため、Windowベースモデルよりも高速化が期待できます。
そんなR-CNNは、region proposalされた画像部分に対し、CNNdetectorを回していくため、Windowベースモデルと比べてCNNを回す回数を大幅に削減することが可能です。その数字を削減できるようになったことは、大きなメリットといえるでしょう。その一方で、region proposalで用いられるのは非DNN技術の従来技術であるため、あまり精度が高くないというデメリットもあります。
Fast R-CNN
Fast R-CNNは、名前からも分かるようにR-CNNの高速化を実現したものです。Fast R-CNNの場合、画像認識を行う際は毎回CNNを走らせる必要がありません。RegionProposalの抽出した特徴領域だけを切り出し、全結合層に与えるだけで良いのです。
そのため、画像認識のたびにCNN層も走らせていた従来のR-CNNと比べて、大幅な高速化が実現できます。たとえば、RegionProposalが1,000回あったとすれば、演算量は以下のようになります。
従来のR-CNN:CNN × 1,000 + FC × 1,000
Fast R-CNN:CNN × 1 + FC × 1,000
そのため、CNNの演算回数を1/1,000に削減することができるのです。また、Fast R-CNN
は、Multi-task lossと呼ばれる学習技術も提案しており、BBとクラス分類のネットワークを2つ同時に学習することも実現しています。
Faster R-CNN
Faster R-CNN は、2015年にMicrosoftが開発した物体検出アルゴリズムです。ディープラーニングによるEnd-to-Endな実装に成功しています。そんなFaster R-CNNの流れとしては、まず初めに矩形の中身が物体なのか、それとも背景なのか(何も写っていないのか)を学習していきます。そして、検出した場所には具体的に何が写っているのかを学習していくという流れです。
Faster R-CNNの特徴としては、物体なのか背景なのかを学習していく段階において、Resion Proposal Network(RPN)というCNN構造を用いている点が挙げられるでしょう。それまでは、Selective Searchという画像処理の手法を用いていたのですが、そこをディープラーニングによって実装しているのです。この点は、画期的な部分といえるでしょう。
YOLO (You Only Look Once)
YOLOとは、「Humans glance at an image and instantly know what objects are in the image, where they are, and how they interact.(人類は画像を一目見て、瞬時にそれが画像の中にある物体が何であるのか、どこにあるのか、どのように相互作用しているのかを理解する)」 というコンセプトのもとで提案された論文のことです。もともとは「You Only Look Once(人生一度きり)」という言葉の頭文字を取ったスラングであり、YOLOの著者であるJoseph Redmon氏が「You Only Look Once(見るのは一度きり)」と文字って名付けたといわれています。
End-to-end時代の先駆けともいえる存在だったFaster R-CNNは、Region Proposal Networkという「検出」を行うためのネットワークを通り、その後Classifierにおいて識別を行うという仕組みでした。そのため、検出の後に「識別」という処理を行う直列の処理構成になってしまっていたわけです。このRegion Proposal Networkがボトルネックとなって、処理速度を遅らせてしまっていました。
その点、YOLOは検出と識別という2つの処理を同時に行うことによって、この処理時間の遅延を解消することに成功しています。
SSD (Single Shot Detector)
SSD (Single Shot Detector)とは、機械学習を用いた一般物体認識のアルゴリズムの一種です。ディープラーニングの技術を利用して、高スピードでさまざまな種類の物体を検知することができます。また、特定の物体を学習させ、その特定の物体を検知させることも可能です。
そんなSSD (Single Shot Detector)では、「デフォルトボックス」と呼ばれる長方形の枠が重要な役割を担います。たとえば、一枚の画像をSSDに認識させ、「その中のどこに何があるか」を予測させる場合、SSDは画像上に「形・大きさの異なるデフォルトボックス」を8732個乗せ、その枠ごとに予測値を計算していくのです。
デフォルトボックスは、それぞれの枠が「自身が物体からどれくらい離れているのか」「そこには何があるのか」という2点を予測する役割を担っています。
Mask R-CNN
Mask R-CNNとは、Faster R-CNNとほとんど同じネットワークを持ちながらイメージセグメンテーションのタスクを遂行していくモデルのことです。セグメンテーションは、物体の周りにBoundingBoxを囲うのみではなく、ピクセルレベルで判定を行っていきます。
Faster R-CNNとの違いとしては、RPN結果をROIアラインレイヤによってサイズを正規化し、その後にdeconvolutionレイヤを利用して物体用のマスクを作成しているという点が挙げられます。
セグメンテーション

セマンティック・セグメンテーション
セマンティック・セグメンテーションとは、画像のピクセル(画素)一つひとつに対し、「何が写っているのか」などのラベルを付けたり、カテゴリを関連付けたりする作業のことです。「画像に何が写っているのか、識別することによってメリットを得られる作業」において多く使用される傾向があります。そのため、現代では幅広い場面で使用されており、その一例としては以下のようなものが挙げられるでしょう。
・手書きの文字列の認識(単語や行を抽出する)
・Googleポートレートモード(前景と背景を分離する)
・YouTubeストーリー
・仮想メイク(仮想試着)
・視覚的な画像検索
・工場における製品の傷検出
・医療における画像診断(病変部分の検出等)
・自動車の自動運転(環境の把握、走行可能な経路の識別)
・衛星画像による地形の識別
・フォントの違いを比較・検出
なお、セマンティックセグメンテーションを活用したい場合には、データを準備した上で、アノテーションツールを利用していく必要があります。Anacondaなどでpython環境を用意して、「labelme Github」をインストールすれば利用可能です。
インスタンス・セグメンテーション
インスタンス・セグメンテーションとは、画像上、もしくはRGB-D画像に写っている物体インスタンスの前景領域マスクを、それぞれの物体インスタンスを区別しながら推定していく問題のことです。画像のピクセルを「どの物体クラスに属するか、どのインスタンスに属するか」といった基準で分類していく方法と考えれば分かりやすいでしょう。物体ごとの領域を分割し、尚且つ物体の種類を認識していきます。
RoI(region of interest)に対して segmentation を行うため、画像内すべてのピクセルに対してラベルを振るわけではありません。
パノプティック・セグメンテーション
パノプティック・セグメンテーションとは、セマンティック・セグメンテーションとインスタンス・セグメンテーションを組み合わせた方法のことです。画像内のすべてのピクセルにラベルが振られます。また、カウントできる物体に関しては、個別で認識した結果が返されるのも特徴の一つです。
既存のパノプティックセグメンテーションアルゴリズムの大半は、セマンティックセグメンテーションとインスタンスセグメンテーションをそれぞれ別に処理していく「Mask R-CNN」が用いられています。
TensorFlowのオブジェクト検出
物体検出と聞いて、ハードルの高い処理のように感じられた人も多いかもしれませんが、物体検出の実装をサポートしてくれるフレームワークはすでに数多く存在しています。その中でも特に注目すべきフレームワークとして挙げられるのが、「Tensorflow Object Detection API」です。
物体検出を行うためには、検出したい物体すべての画像データが必要となります。そのため、検出したい物体が増えるごとに、必要な画像データも増加してしまうわけです。当然、画像認識を行うとき以上に大量の画像データを用意しなければなりません。
ただし、Tensorflow Object Detection APIには学習済みのモデルが用意されており、80種類の物体を認識できるため、物体検出を気軽に試すことができます。気軽に物体検出を実行できる点は、大きなメリットといえるのではないでしょうか。
物体検出の応用例
自動運転
福岡県の自動車学校に導入された「AI教習システム」

2020年9月28日、福岡県大野城市の南福岡自動車学校にて自動運転技術を活用した「AI教習システム」の試乗会が行われました。このAI教習システムは、南福岡自動車学校を運営しているミナミホールディングスとティアフォー、レインフォーの3社が共同で開発したシステムで、自動運転技術を用いた運転技能検定システム、そして教習システムで構成されているそうです。
そんなAI教習システムの特徴としては、自動運転の技術を活用することによって、車両位置や周辺環境をより正確に検知することができるという点が挙げられます。これにより、これまでの指導員と変わらない精度で、ドライバーの運転技術を評価することが可能になるのです。
たとえば、運転技能検定では、教習所構内の決められたコースを走行し、AI教習システムがドライバーの運転技能を定量的に評価していきます。また、運転技能の教習においては、教習生の多くが苦手とするS字走行を、AIが音声や画像で指導しました。昨今は人手不足に伴う指導員の負担増も問題視されていますので、このような形でAIによる自動車教習が可能になれば、人手不足問題の解消にもつながっていくでしょう。
さらに、AIを活用することのメリットとして、「評価のバラつきを抑えられる」という点も挙げられます。これまでは、すべて指導員によってドライバーの運転技術が評価されていたため、評価にバラつきが生じることも少なくありませんでした。その点、AI教習システムを導入すれば、AIによる客観的評価が可能になるため、これまでのような評価のバラつきも抑えられることが期待されています。
インドでも「AI教習」の試験運用が開始

自動車教習という分野において、画像(映像)に写る物体を検出するAIが活用され始めているのは、日本だけではありません。インドではすでに自動車教習でAIが活用され始めているのです。これは、Microsoftがインドで行っている「HAMS(Harnessing AutoMobiles for Safety)」というプロジェクトで、試験運用が行われています。
先ほどご紹介した福岡県の事例と同じく、自動車教習所の指導員の業務をAIが代行することを目的としたプロジェクトです。具体的な仕組みとしては、スマートフォンをフロントガラスに取り付け、前面のカメラで運転者を撮影し、背面のカメラで道路や障害物などを撮影するというもの。もちろん、ここで用いられているのは一般的なカメラだけではありません。スマホに搭載されている加速度計などのセンサーも活用することで、より高度な計測を実現しています。
これらを活用して、「車間距離は適切かどうか」「レーンの中に停められているかどうか」といった点を確認したり、「急ブレーキ」や「運転者の疲労」などのチェックを行ったりするわけです。
また、ディープラーニングの活用も想定されているため、運転手により的確なフィードバックを行うことも可能になるといいます。指導員によるチェックでは、運転者の集中力や疲労度などまでチェックするのは難しいと言わざるを得ません。そのような点もしっかりとチェックできるようになるという点は、AIを活用することの大きなメリットといえるのではないでしょうか。
なお、このシステムを利用する際は、はじめに個人IDを入力し、カメラの指示にしたがって左・右・正面を見て顔を登録する必要があります。そして、テストが開始されると受験者は車内で一人になるわけですが、カメラの顔認識機能によって常に「受験者が同一人物であるか」が確認されているため、受験者を入れ替えたりすることはできません。
医療画像診断
のど撮影でインフル診断を行うAI医療機器
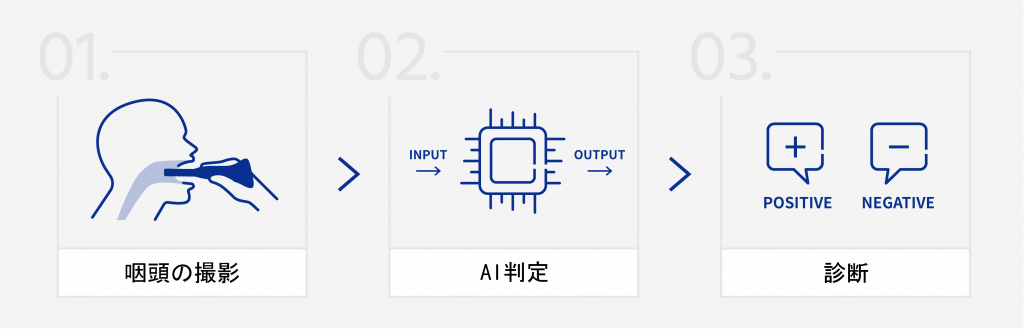
AI医療機器ベンチャーのアイリス株式会社は、咽頭画像の解析をもとにインフルエンザ判定を行うAIアルゴリズムを開発し、咽頭カメラを含むAI搭載システムを「医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律(医薬品医療機器等法)」に基づき、厚生労働大臣宛てに医療機器製造販売承認申請をしました。
現在のインフルエンザ検査法では、現場で実践した場合の精度が6割程度という研究報告があります。また、検査時に綿棒を鼻腔内に挿入する行為は、患者の痛みを伴うと同時に、検査時の医療者に対する飛沫感染リスクが懸念されています。
今回開発されたAIシステムは、専用カメラで撮影した患者の咽頭写真をもとに、体温などのデータと組み合わせてAI・人工知能がインフルエンザの「陽性」「陰性」を短時間で判定するものです。この仕組みには、日本人医師の宮本医師が発見したインフルエンザ濾胞(ろほう)の知見も活かされています。
2018・2019年度に、自社開発の咽頭カメラを用いて、臨床研究法における特定臨床研究として大規模な前向き研究を実施。のべ100医療機関・10,000人以上の患者の協力で、50万枚以上の咽頭画像を収集し、独自の咽頭画像データベースを構築しました。このデータベースの活用によりインフルエンザ判定AIプログラムを開発。AI解析に適した咽頭画像を撮影するための咽頭撮影専用カメラも自社で設計・開発し、既存の内視鏡などを用いずに口腔内・咽頭を鮮明に撮影することを実現しました。
AIドローン
AI搭載のドローンで畑の見守りを行う葉色解析AIサービス
基本的に農業は広大な敷地で作物が育てられるため、隅から隅まで人間が目視で状況を確認するのは決して簡単なことではありません。そのため、最近ではAIを搭載したドローンを活用する事例も多くなってきています。特にレタスやトマトなどを管理された工場内で栽培する植物工場の先進国、オランダや韓国ではITを使ったスマート農業がさかんです。
もちろん、日本の農業においてもAIは積極的に活用されています。その代表例として挙げられるのが、葉色解析AIサービスの「いろは」です。「いろは」は、ドローンを活用して圃場の様子を上空から撮影し、作物の育成状況を把握することができるサービスです。ドローンで撮影した画像をAIで解析することで、収穫量の予測を行ったり、除草剤を散布すべきポイントを可視化したりすることができます。
農業において天候は極めて重要な要素となるわけですが、特に露地栽培の場合は天候が栽培環境に大きな影響を与えます。そのため、作物の育成状況を確かめるのが難しい傾向にあったのです。
しかし、「いろは」を活用すれば、ドローンで効率的に状況確認を行えるため、圃場の巡回時間を大幅に削減することが可能です。むしろ、ドローンであればより正確に育成状況を確認することができます。近年は特に人手不足が深刻化していますので、こういったサービスによって業務効率化を実現できることには大きなメリットがあるといえるのではないでしょうか。
顔認証
顔認証技術の活用によって銀行のローン申し込みを効率化
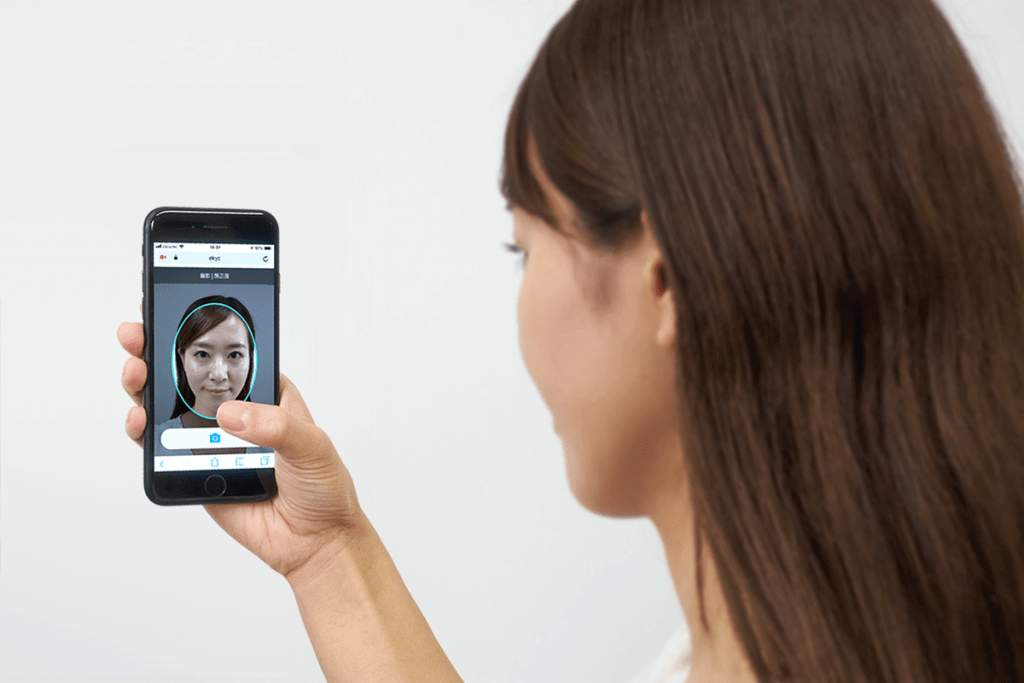
福島県を拠点とする株式会社東邦銀行は、株式会社Liquidが提供する「LIQUID eKYC」を東北地方で初めて導入し、WEBからの個人ローンの申込みにおける本人確認手続きで活用しています。スマートフォンで本人確認書類と顔を撮影するだけで、本人確認が可能になりました。
LIQUID eKYCは、顔認証やOCRなど高精度のAI・人工知能を搭載したサービスです。スマートフォンのカメラで写真付き本人確認書類と本人の容貌(顔)を撮影するだけで手続きできる迅速、低い離脱率かつセキュアな本人確認が可能となっています。本人確認手続きがオンラインで完結するため、本人確認資料のアップロードや郵送物の受け取りが不要となり、ユーザーの負担軽減や本人確認時間の大幅な削減によるスピーディーな融資サービスを提供することが可能になったのです。
まとめ
今回は、画像に写る物体を検出するAIについて学ぶ上で欠かせない「一般物体認識」や「CNN (畳み込みニューラルネットワーク)」、「物体検出のディープラーニングモデル」についてご解説するとともに、画像認識の活用事例についてもご紹介しました。
サービスの向上やセキュリティ強化など、今後もさまざまな領域で活用されていくことが予想されます。また、類似した人物画像でも高精度に分類したり、ピンぼけやノイズがある画像でも高精度に検出したり、捏造された画像を的確に検出したりできるようになる可能性も十分に考えられるでしょう。ぜひこの機会に画像認識AI、物体検出AIに関する知識を深めながら、積極的に活用してみてはいかがでしょうか。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- 生成AI
- ChatGPT
- Gemini
- Claude
- LLM
- AI研究開発
- 画像生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
- GPU
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI












FOLLOW US
SNSをフォローして、最新情報をチェックできます!

富士フイルムBI、複合機の保守プロセスを効率化するAI搭載「統合…

Google、「Gemini」新モデル「3.6 Flash」「3…

つながりAI、横浜市でAI相談サービス「友達AI」実証実験を開始…

MFS、無料の不動産AI査定サービス「CAPS」提供開始。約45…
住宅ローン比較診断サービス「モゲチェック」、AIエージェント連携向けMCPサーバーを公開
AVITAのAIロープレ「アバトレ」、新潟県労働金庫に導入。職員の対人コミュニケーション訓練に活用

Google、画像検索25周年に合わせ新たなホーム画面導入、「AI Overviews」に画像生成機能を追加
京都銀行、AI活用の不正取引検知モデル運用開始。マネー・ローンダリング対策などの実効性を向上

北陸銀行、「ナレッジワークAI商談記録」を導入。商談記録作成の効率化と品質向上を推進

「カスタマーサポート向けAI活用ガイド」を公開!対応工数削減からCX向上までをAIで実現する業務別ユースケース集
AI製品・ソリューションの掲載を
希望される企業様はこちら