

VLA(Vision-Language-Action)モデルとは?仕組み・VLMとの違い・主要モデルを解説
最終更新日:2026/06/26

工場や物流倉庫で稼働するロボットは、決められた作業を正確に繰り返すことを得意としてきました。一方で、置かれた物の位置が少しずれただけで止まってしまう、新しい作業のたびに専門家による細かな設定が必要になるといった制約が残っています。
こうした制約を越える技術として注目されているのが、VLA(Vision-Language-Action)モデルです。VLAは、カメラで「見て」言語を「理解」し、自ら「動く」という3つの働きを1つのAIに統合したモデルなのです。
この記事では、VLAモデルの定義や仕組み、混同されやすい「VLM(Vision-Language Model)」との違い、2026年時点で主流となっている代表的なモデルまでをわかりやすく解説します。
VLAモデルとは
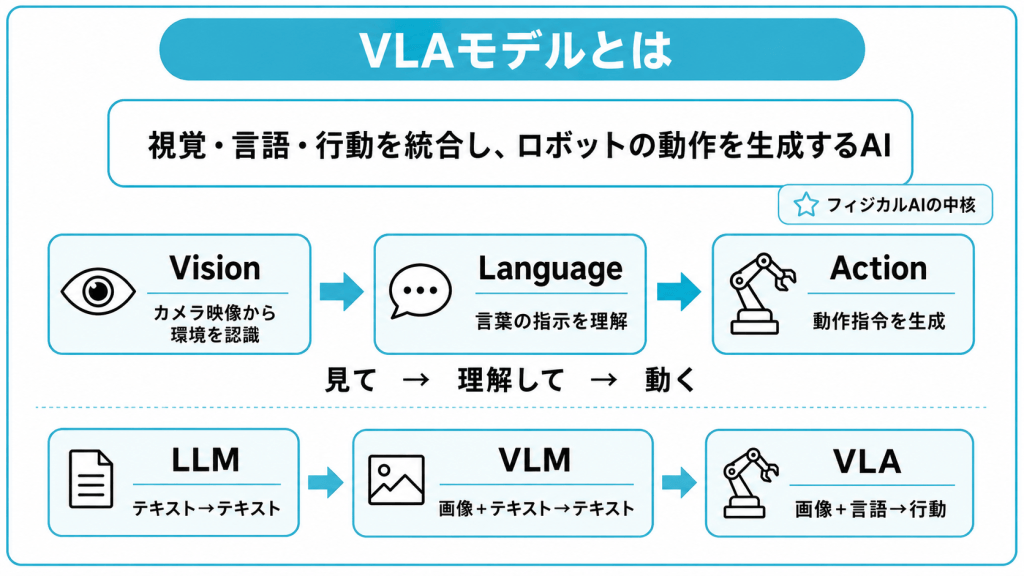
VLAモデルとは、視覚・言語・行動の3つの情報を1つのAIに統合し、ロボットなどの物理的な動作を生成するモデルです。「Vision-Language-Action」の頭文字をとった名称で、AIが現実世界でタスクを実行することを目的としています。
ChatGPTのような会話型AIが文章を出力するのに対し、VLAはロボットの腕や関節をどう動かすかという具体的な動作指令を出力します。この「行動を出力する」という点が、VLAをほかのAIモデルと分ける特徴です。
近年は「フィジカルAI」という言葉とともに語られる機会が増えています。フィジカルAIとは、ロボットのような物理的な身体を持ち、現実世界を理解しながら動作するAIを指します。VLAは、そのフィジカルAIの中心となる技術として注目を集めています。
定義とVision・Language・Actionの3要素
VLAモデルは、Vision(視覚)・Language(言語)・Action(行動)という3つの要素を組み合わせ、見た状況と指示の内容から、次にとるべき動作を導くという働きをします。従来は別々のAIで処理されてきた3つの能力を、1つのモデルに統合した点が本質的な特徴です。
VLAが扱う3つの要素は、それぞれ次の役割を担います。
- Vision:カメラ映像から環境を認識する
- Language:言葉による指示を理解する
- Action:具体的な動作指令を生成する
Vision(視覚)は、カメラやセンサーから取り込んだ映像をもとに、物体の位置や形状・状態を認識する役割です。Language(言語)は、「赤いカップを箱に入れて」といった自然言語の指示を理解し、何をすべきかを把握します。そしてAction(行動)は、理解した内容にもとづいて、関節の角度や移動方向といった動作指令を生成します。
この3つが連続して働くことで、VLAは「見て、理解して、動く」という一連の流れを1つのモデル内で実現します。
LLM・VLMからVLAへ
VLAは、テキストのみのLLM、画像を理解できるVLMへと拡張されてきたAIの歴史の延長線上にあります。扱える情報の範囲が『行動』にまで広がった結果として生まれた技術です。
LLM(Large Language Model:大規模言語モデル)は、テキストを理解してテキストを返すAIです。ChatGPTが代表例で、当初は文章だけを生成していました。
次に登場したVLM(Vision-Language Model:視覚言語モデル)は、画像も理解できるように拡張されたモデルで、画像の内容を言葉で説明できます。GeminiやGPT系のモデルが備えるマルチモーダル機能が該当します。マルチモーダルとは、テキストや画像など複数種類の情報を同時に扱える性質を指します。
VLAは、このVLMの出力側をさらに拡張したものです。VLMが「画像とテキストを入力し、テキストを出力する」のに対し、VLAは「画像と言語指示を入力し、行動を出力する」モデルへと発展しています。
出力が仮想世界のテキストではなく、物理的な動作を伴う点が、VLAを「フィジカルAI」と呼ぶ理由です。
VLAとVLM・従来のロボット制御との違い
VLAを理解する過程で混同しやすいのが、VLM(Vision-Language Model)との違いです。名称が似ている上にいずれも画像と言葉を扱うため、何が違うのかという疑問を持つかもしれません。
さらに押さえておきたいのが、従来のロボット制御との違いです。
VLMとの違い
VLMとVLAの決定的な違いは、出力が言語で止まるか行動まで到達するかという点です。VLMは認識した内容を言葉で表現するところまでを担い、VLAはそこから先のどう動くかまでを担います。
VLMは、画像とテキストを統合的に処理するマルチモーダルAIです。画像の説明文を作る、画像を検索する、画像についての質問に答えるといったタスクに強みを発揮します。しかしVLMの出力はあくまで言語情報にとどまるため、現実世界で行動を起こす機能は基本的に備えていません。
これに対してVLAは、VLMの能力を土台にしながら、認識した情報から行動計画を立て、物理的な動作を出力するところまで踏み込みます。
たとえばカメラ画像を見て「赤いカップを箱に入れて」という指示を理解し、その場でロボットアームの動作指令を出すのがVLAです。VLMが認知レベルのAIであるとすれば、VLAは行動レベルまで到達したAIといえます。
従来のロボット制御との違い
従来のロボット制御とVLAの違いは、決められた動作を実行するのか状況を見て動作を考えるのかという点です。VLAは、あらかじめプログラムされていない作業にも柔軟に対応できる可能性を持つ点で、従来方式と大きく異なります。
従来の産業用ロボットは、決められた位置にある物に対して決められた動作を繰り返すことを得意としてきた一方、状況が少しでも変わると対応できないという弱点があります。
複数のAIを連携させる場合も、指示の理解・画像認識・行動決定が別々のシステムで動くパイプライン方式が一般的で、処理に遅延が生じやすく、ある段階の誤りが後段に伝わりやすいという課題がありました。
VLAは、これらの機能を1つのモデルに統合します。視覚と言語を理解したうえで行動を判断するまでを一貫して行うため、段階の分断による遅延や誤りが伝わるのを防げます。
さらに学習ベースで動作を習得するため、事前にすべての動作を書き込まなくても、未知のタスクにある程度対応できる点が従来方式との大きな違いです。
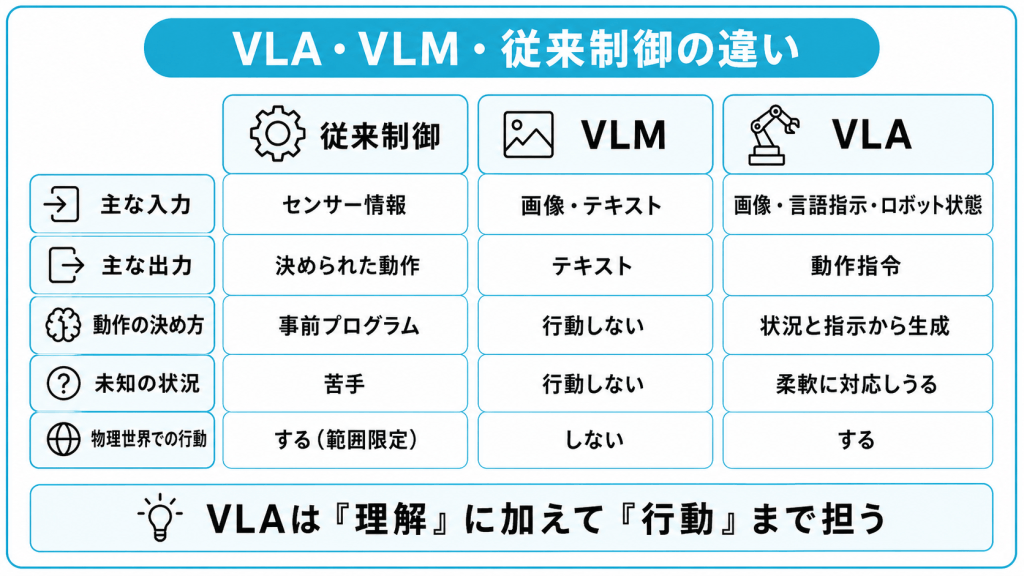
VLM・従来制御・VLAの違いを比較
従来のロボット制御・VLM・VLAの違いを比較表にまとめました。
| 観点 | 従来のロボット制御 | VLM | VLA |
|---|---|---|---|
| 主な入力 | センサー情報 | 画像・テキスト | 画像・言語指示・ロボット状態 |
| 主な出力 | 決められた動作 | テキスト(説明・回答) | 動作指令(関節角度・移動量など) |
| 動作の決め方 | 事前のプログラム・ティーチング | 行動はしない | 状況と指示から自ら生成 |
| 未知の状況への対応 | 苦手 | 行動はしない | 柔軟に対応しうる |
| 物理世界での行動 | する(決められた範囲) | しない | する |
3者は物理世界で行動するかどうか・動作を自ら決められるかどうかという2つの軸で性質が分かれます。従来のロボット制御は物理世界で行動できますが、その動作は事前に決められた範囲に限られます。
VLMは画像と言葉を高度に扱えますが、行動そのものは生成しません。VLAは、この2つの性質を併せ持ち、状況に応じた動作を自ら生成して物理世界で実行する点に独自性があります。
VLAモデルの仕組み
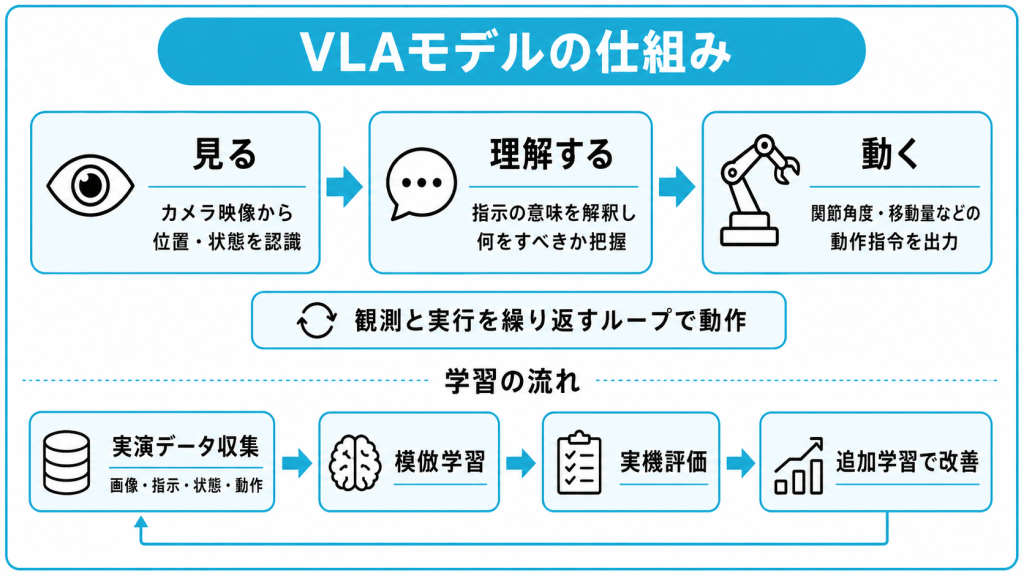
VLAモデルは、大まかに見る・理解する・動くという3つの処理を連続して行うことで動作します。内部では複雑な計算が行われていますが、全体像はこの3段階で捉えると理解しやすくなります。
見て・理解して・動くの3ステップ
VLAの内部処理は、入力された画像と指示が最終的に動作指令へと変換される、次の3ステップで進みます。
- 視覚情報の処理:カメラ映像から環境を認識する
- 言語指示の理解:何をすべきかを把握する
- 行動の生成:具体的な動作指令を出力する
最初のステップでは、ロボットに搭載されたカメラの映像を「Vision Encoder(視覚エンコーダー)」と呼ばれる仕組みに入力し、物体の位置や形状といった特徴を抽出します。
次のステップでは、言語モデルが指示の意味を解釈し、視覚情報と結びつけて「何をすべきか」を把握します。最後のステップでは、その理解にもとづいて具体的な動作指令を生成します。
なお、VLAは1回の推論で処理が完結するわけではありません。カメラ画像は環境の変化に応じて更新され、観測と実行を繰り返すループのなかで動作指令が出され続けます。生成される行動の表し方には、関節の角度で表す方法、手先の移動量で表す方法などがあり、どの形式を採るかはロボットの身体構造によって変わります。
VLAはどのように学習するのか?
VLAの学習は、人間がロボットを操作したお手本データを真似る「模倣学習」を中心に行われます。模倣学習(imitation learning)とは、人間や既存の制御装置が実際に動かした動作を記録し、それを再現できるようにモデルを訓練する手法です。
モデルの学習には、遠隔操作で集めたロボットの実演記録に加え、人間の動作動画、既存の公開データセット、シミュレータ上で作成した合成情報などを組み合わせて活用します。実演を集める際は、カメラ画像、言語指示、ロボットの状態、実際に流した動作、そしてその試行がうまくいったかどうかを記録していきます。
集めたデータは、画像と動作の時間を合わせる、単位をそろえるといった前処理を経て、学習に使える形に整えられます。
学習後は、実際のロボットで動かして評価する工程が欠かせません。オフラインの評価だけでは、つかみ方が甘い、特定の物体で失敗しやすいといった癖が見つからないためです。実機で動かして失敗の例を集め、それを追加で学習させて改善していく流れが取られます。
主要なVLAモデルの最新動向【2026年版】
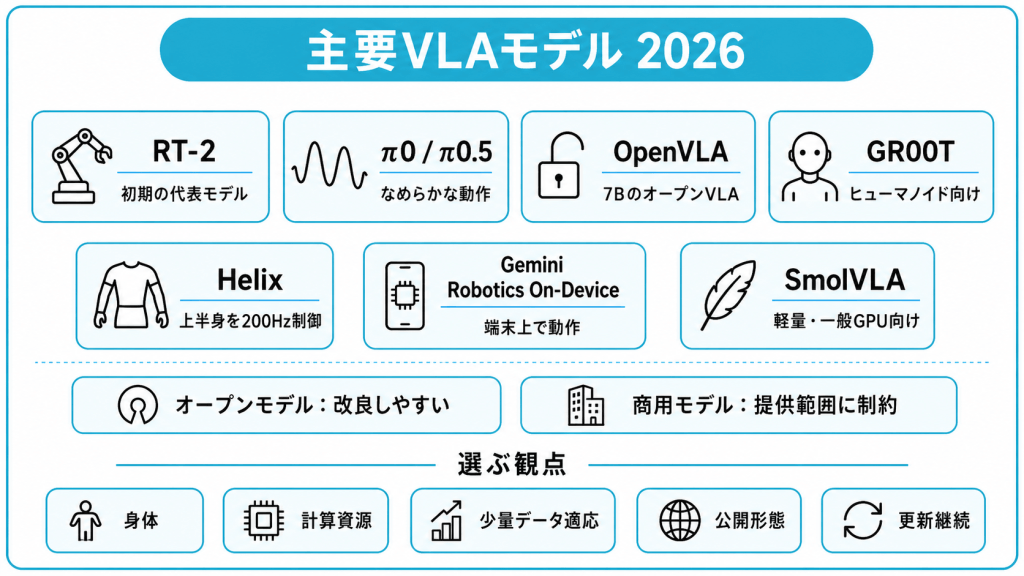
VLAモデルは2023年ごろから急速に数を増やし、2026年時点では多くの有力なモデルが登場しています。機械学習の国際会議であるICLR 2026でもVLA関連の発表が相次いでおり、研究が活発な時期に入っていることがうかがえます。
2026年時点で代表的とされるモデルを比較表にまとめたうえで、オープンモデルと商用モデルの違い、モデル選びで確認したいポイントを解説します。
| モデル | 開発元 | 特徴 |
|---|---|---|
| RT-2 | Google DeepMind | VLA開発の流れを作った初期のモデル。インターネット上の知識を行動に活用 |
| π0 / π0.5 | Physical Intelligence | なめらかな動作の生成が得意。π0.5は未知環境への対応を強化 |
| OpenVLA | Stanford、UC Berkeley、Google DeepMindなどの共同開発 | 7BパラメータのオープンVLAモデル。Open X-Embodimentデータセットで学習 |
| NVIDIA Isaac GR00T(N1シリーズ) | NVIDIA | ヒューマノイド向けのオープンVLAモデル。多様なロボットデータで学習され、ポストトレーニングによる適応に対応 |
| Helix | Figure AI | ヒューマノイドの上半身を200Hzで制御するVLAモデル。物体把持や複数ロボット連携のデモが公開されている |
| Gemini Robotics On-Device | Google DeepMind | Geminiを土台にしたVLA。端末上で動作し、限られたテスター向けに提供されている |
| SmolVLA | Hugging Face | 4億5,000万パラメータ規模の軽量モデル。一般的なGPUで動かせる |
これらのモデルは、ねらいや設計思想がそれぞれ異なります。
RT-2はインターネット上の言語・画像データも学習に使い、π0シリーズはなめらかで高頻度な動作の生成が得意です。GR00TやHelixはヒューマノイド(人型ロボット)向け、SmolVLAは軽量さで手元での実験を容易にしています。
同じVLAでも、得意とする身体や用途が分かれている点を押さえると、モデルの比較がしやすくなります。
オープンモデルと商用モデルの違い
主要なVLAモデルは、重みやコードが公開された「オープンモデル」と、開発元が内部で保有する「商用モデル」に大きく分かれ、選択によって自社で改良できる範囲や導入の自由度が変わります。
オープンモデルは、モデルの重み(学習結果のパラメータ)やコードが公開されており、各モデルのライセンス条件に従ってファインチューニング(追加学習による調整)や改変を検討できます。
OpenVLA、NVIDIAのGR00Tシリーズ、SmolVLAに加え、Physical Intelligenceのπ0.5も一部公開されています。これにより研究者や開発者が利用・改良しやすく、ロボット研究への参入も進めやすくなっています。
一方の商用モデルは、重みを公開せず限られた相手にのみ提供する方式をとります。Figure AIのHelixがその一例で、Gemini Robotics On-DeviceもSDK経由で特定のテスター向けに提供されています。
商用モデルは高い性能を期待できる反面、自社での持ち運びや改変がしにくい制約があります。
VLAモデル選びのチェック項目
VLAモデルを比較するときは、対応するロボットの種類・必要な計算資源・適応のしやすさといった項目を確認することが欠かせません。
カタログスペックだけでモデルを選ぶと、自社の環境で動かせない、調整に手間がかかりすぎるといった問題が発生する恐れがあるのです。
モデルを比較する際は、次のような項目を確認するとよいです。
- 対応する身体(アーム・人型など)
- 必要な計算資源とハードウェア
- 少ないデータで適応できるか
- オープンモデルか商用モデルか
- 開発元による更新の継続性
たとえば、少ない数のお手本データで新しい作業に適応できるかどうかは導入の手間に直結します。実際に、50〜100回程度のお手本で別のタスクに適応できるとされるモデルも登場しています。
また、軽量なモデルであれば一般的なGPUでも動かせる一方、大規模なモデルはロボット本体での動作が難しい場合があります。これらは自社の現場条件と照らし合わせて判断する必要があり、専門的な知見が求められる部分でもあります。
なお、画像や言葉の理解が得意なAIが、そのまま優れたVLAになるとは限らない点にも留意が必要です。実際にロボット向けに設計され、その用途のデータで学習されたモデルかどうかを見極めることが、現実的な判断につながります。
VLAの導入が進む現場と検討の現実
VLAモデルは研究段階から実用段階へ移りつつありますが、すべての現場で同じように使えるわけではありません。どの分野で導入が先行しているのか、そして導入には何が必要なのかを具体的に押さえておくことが、検討を進めるうえで役立ちます。
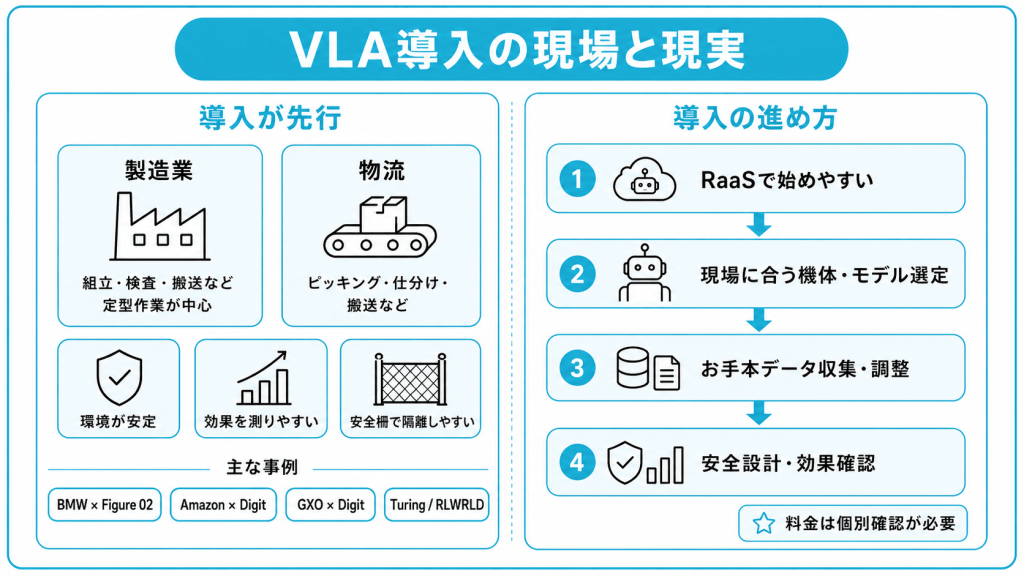
導入が進んでいる分野と事例
VLAの導入は、製造業と物流の現場から先行して進んでいます。これらの分野では、技術的な条件と経済的な条件の両方がそろっているためです。
製造・物流でVLAの導入が先行している理由は、主に次の3点です。
- 環境が比較的制御されている
- 経済効果を測りやすい
- 安全柵で隔離しやすい
工場や倉庫は環境の変化が少なく、対応すべき状況を絞り込みやすい場所です。人件費削減の効果を数値で測りやすく、安全面でも柵などで作業領域を隔離しやすい点が後押しになっています。
具体的な事例としては、Figure AIのヒューマノイドロボットFigure 02がBMW Group Plant Spartanburgで試験され、板金部品を治具へ挿入する作業を行った例があります(BMW Group公式発表)。
物流分野でも、Agility RoboticsのDigitがAmazonの倉庫で空トートのリサイクルに使われ(Agility Robotics公式発表)、GXOの物流拠点ではトートの移動に導入されています(Agility Robotics公式発表)。
今後は家庭用、医療・介護、自動運転、サービス業などへの広がりが期待されます。日本でも自動運転分野でTuring(チューリング)がVLAを使った公道走行に取り組み(Turing公式発表)、産業ロボット領域でもRLWRLDなど国内拠点を持つフィジカルAI企業が事業化に向けた研究開発を進めています(RLWRLD公式発表)。
提供形態とコストの考え方
VLA搭載ロボットは購入して終わりではなく、月額制で利用するRaaS(Robot as a Service)型の提供が広がっています。RaaSとは、ロボットをサービスとして利用する形態を指します。
2026年時点では、VLAを搭載したロボットをRaaS型で提供する事例が見られます。月額制であれば初期投資の負担を抑えやすく、一定期間使ってみて効果を見極めてから本格導入を判断する進め方も取りやすくなります。
ただし、料金は提供会社や契約条件によって異なり、公開されていない場合も多いため、導入検討時には個別に確認することが必要です。
VLAの導入で検討すべきは、料金だけではありません。
自社の作業に合うモデルやロボットの選定、お手本データの収集、現場に合わせたファインチューニング、安全面の設計など、専門的な検討を要する工程が多く含まれます。
VLAは今どこまでできて何ができないのか?
VLAモデルの可能性は大きい一方で、過度な期待は禁物です。VLAを万能のように扱うメディアもありますが、2026年時点での到達点と限界を誇張なく押さえておくことが、現実的な検討につながります。
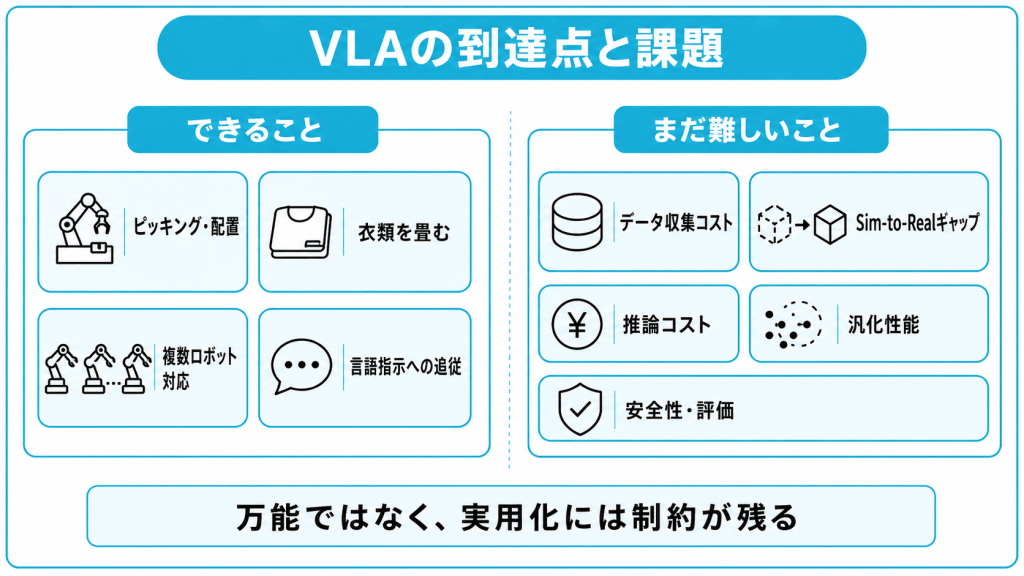
2026年5月時点で実現できていること
VLAは、物のピッキングや配置、衣類を畳むといった一定の器用さを要する作業を、ある程度こなせる段階に来ています。数年前と比べて、扱えるタスクの幅と動作の質が着実に向上しています。
たとえば、なめらかな動作の生成に向いた手法を採用したモデルでは、従来はカクカクしていた動きが改善され、洗濯物を取り出して畳むといった連続した作業も実演されています。
また、1つのモデルで複数の種類のロボットを動かす「クロスエンボディメント」と呼ばれる能力も進んでおり、アームの構成が異なるロボットにも同じモデルで対応できる例が出てきています。
言語指示への追従も進み、学習時とは異なる言い回しの指示や、ある程度未知のタスクにも対応できる場面が増えています。研究の現場ではこうした能力に関する発表が相次いでおり、進展が速い状況です。
VLAの課題
一方で、VLAには学習データの収集コスト・シミュレーションと現実の差・推論コストといった課題が残っています。これらは実用化を広げるうえで越えるべき壁とされています。
| 課題 | 内容 |
|---|---|
| データ収集のコスト | 人がロボットを操作してお手本を集める方式は高コストで時間がかかる |
| Sim-to-Realギャップ | シミュレーションで学んだ動作が現実でうまく働かないことがある |
| 推論コスト | 高性能なモデルほど計算負荷が大きく、ロボット本体で動かしにくい |
| 汎化性能 | 学習時と大きく異なる環境や物体には対応しきれないことがある |
| 安全性・評価 | 共通の評価指標や安全基準がまだ確立されていない |
データ収集の課題は特に深刻です。お手本データを遠隔操作で集める方式では、ロボット1台とオペレーター1人で集められる量に限りがあり、大規模なデータをそろえるには膨大な人手と時間がかかるとされています。
この対策としてシミュレーターによる擬似データの生成が進んでいますが、シミュレーションと現実の見た目や物理の差、いわゆるSim-to-Realギャップは依然として大きな研究テーマです。
さらに、高性能なモデルほど計算負荷が大きく、ロボット本体に積んで動かすことが難しいという推論コストの問題もあります。学習や評価の標準化、実環境での安全性の確保についても共通の指標づくりが進んでいる途上であり、これらの課題が残っている点は導入検討の前提として理解しておく必要があります。
まとめ
VLAモデルは、視覚・言語・行動の3つを1つのAIに統合し、ロボットが「見て、理解して、動く」ことを実現する技術です。言葉で説明するところまでを担うVLMや、決められた動作を繰り返す従来のロボット制御とは異なり、状況に応じた動作を自ら生成して物理世界で実行できる点に独自性があります。
2026年時点では、π0シリーズやGR00T、Helix、Gemini Robotics On-Deviceといった有力なモデルが登場し、学習方法も模倣学習から強化学習へと広がるなど、研究は活発な時期に入っています。
製造業や物流の現場から実用化が進む一方で、データ収集のコストやSim-to-Realギャップ、推論コストといった課題も残されており、過度な期待をせず到達点と限界の両方を踏まえることが欠かせません。
VLAの導入を具体的に検討する段階では、自社の現場に合うモデルやロボットを見極め、データの収集や調整、安全面の設計まで含めて計画する必要があります。専門的な知見を持つ事業者に相談することで、こうした検討をスムーズに進めやすくなります。
VLAは発展の途上にある技術であり、最新の動向を追いながら、自社に合った活用の形を考えていくことが大切です。
アイスマイリーでは、生成AIのサービス比較と企業一覧を無料配布しています。課題や目的に応じたサービスを比較検討できますので、ぜひこの機会にお問い合わせください。
よくある質問
VLAとVLMは何が違いますか?
最も大きな違いは、出力が言葉で止まるか行動まで到達するかという点です。VLM(Vision-Language Model)は画像と言葉を理解し、その内容を言葉で説明します。VLA(Vision-Language-Action)は、そこから先のどう動くかまでを生成し、ロボットを実際に動作させます。VLMが認知レベルのAIであるのに対し、VLAは行動レベルまで踏み込んだAIといえます。
VLAを使えばロボットのティーチングや学習は完全に不要になりますか?
完全に不要になるわけではありません。VLAは事前にすべての動作を書き込まなくても柔軟に対応できる可能性を持ちますが、自社の作業に合わせるためにはお手本データの収集やファインチューニングが必要になる場合が一般的です。従来のように動作を1つずつ細かく設定する負担は軽くなる一方、データを使った調整という新しい工程が生じる点を理解しておく必要があります。
VLAはすでに実用段階に入っている技術ですか?
製造業や物流の一部では実用段階に入りつつありますが、すべての分野で同じように使えるわけではありません。環境が制御されていて経済効果を測りやすい現場では導入が先行しています。一方で、家庭や屋外のように環境の変化が大きい場所での本格的な実用化は、まだこれからの段階といえます。
VLAとフィジカルAI・世界モデルはどう関係しますか?
フィジカルAIは、物理的な身体を持ち現実世界で動作するAI全般を指す広い概念で、VLAはその中核を担う技術です。世界モデルは、現実世界の物理・空間的な変化をモデル化し、将来状態の予測やシミュレーション、合成データ生成などを通じてロボットの学習を支える技術で、VLAの学習データ不足を補う役割でも使われます。フィジカルAI・VLA・世界モデルは対立する概念ではなく、フィジカルAIという大きな枠組みのなかでVLAと世界モデルが連携することが特徴です。
中小企業でもVLA搭載ロボットを導入できますか?
月額で利用するRaaS型の提供が広がっているため、大規模な初期投資をせずに導入を検討できる環境は整いつつあります。ただし、自社の作業に合うモデルやロボットの選定、現場に合わせた調整には専門的な知見が必要です。導入の規模にかかわらず、知見を持つ事業者に相談しながら進めることが現実的な選択肢になります。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- 生成AI
- ChatGPT
- Gemini
- Claude
- LLM
- AI研究開発
- 画像生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
- GPU
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI














FOLLOW US
SNSをフォローして、最新情報をチェックできます!

リコーとライズ・コンサルティング・グループ、AI実装・活用を一貫…
近畿大学病院など4者、リアルワールドデータとLLMを用いた共同研…
LINEヤフー、「LINE」新機能「Agent i in cha…
Sakana AI、「Sakana Chat」に翻訳機能を追加。…
清水建設、AIロボットの研究開発を本格化。現場巡回や塗装作業で実用化に向け実証開始

ChatGPT自己分析プロンプト|メモリ機能で強みと価値観を言語化

プロンプトとは?生成AIの意味・書き方のコツ・例文まで徹底解説

ChatGPTの育て方とは?自分好みに育てる方法とコツを解説

ChatGPTカスタム指示のおすすめ設定例と効果的な書き方を解説

OpenAI、新世代音声モデル「GPT-Live」公開。全二重アーキテクチャ搭載で自然な音声対話を実現
AI製品・ソリューションの掲載を
希望される企業様はこちら