

生成AI

最終更新日:2024/06/24
 教師なし学習とは?
教師なし学習とは?
近年はさまざまな分野で積極的にAI(人工知能)が活用され始めており、私たちにとって身近な存在になりつつあります。ただ、AIが搭載された製品やサービスを当たり前のように利用していても、その仕組みまでは理解できていないという人は多いのではないでしょうか。
AIを正しく活用し、さらなる利便性向上や生産性向上を図るためには、AIの仕組みを理解することが大切です。そこで今回は、AIの基礎ともいえる「教師なし学習」について解説するとともに、その種類や応用例なども紹介していきますので、ぜひ参考にしてみてください。
機械学習について詳しく知りたい方は以下の記事もご覧ください。
機械学習とは何か?種類や仕組みをわかりやすく簡単に説明
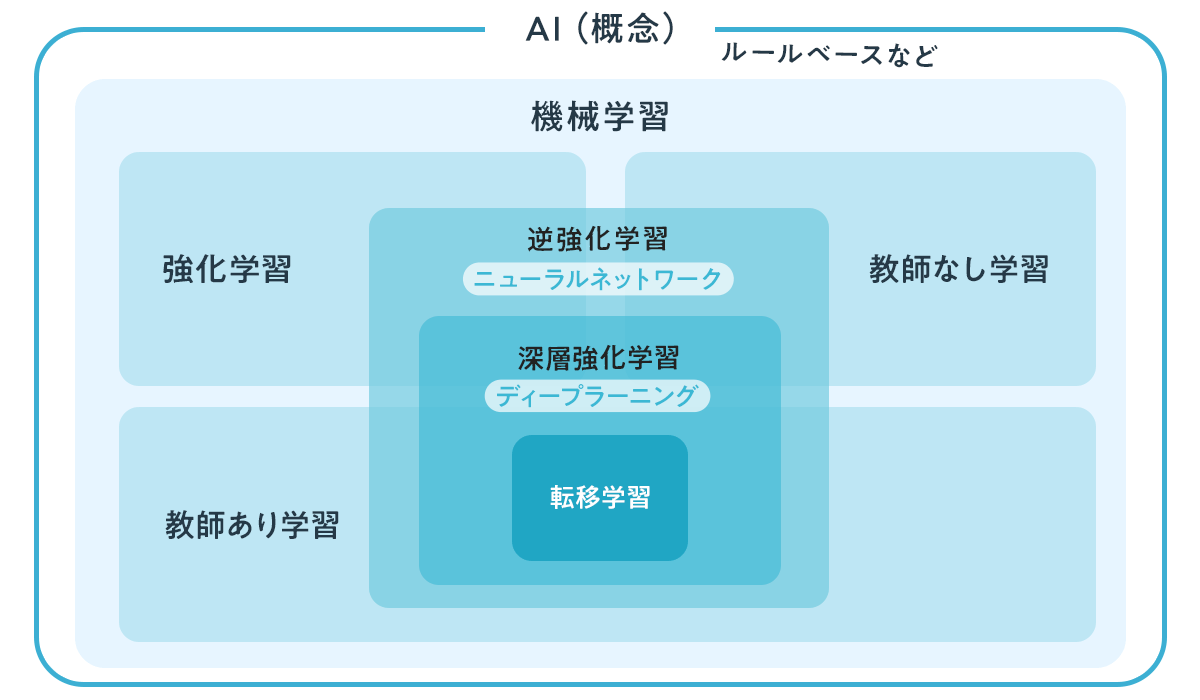
教師なし学習(Unsupervised Learning)は、正解となるデータが存在せず、入力されたデータを利用して正解を導き出していきます。教師あり学習の場合、教師となるデータをもとに学習していく必要がありますが、教師なし学習は教師データが必要ありません。
一見、教師なし学習のほうが難しいように思えるかもしれませんが、適切な方法で学習を行えば、教師なし学習でも精度を高めていくことが可能です。
教師なし学習は、膨大なデータの学習を行うわけではなく、データそのものが持っている構造や特徴の分析を行うため、以下のような作業が得意といえるでしょう。
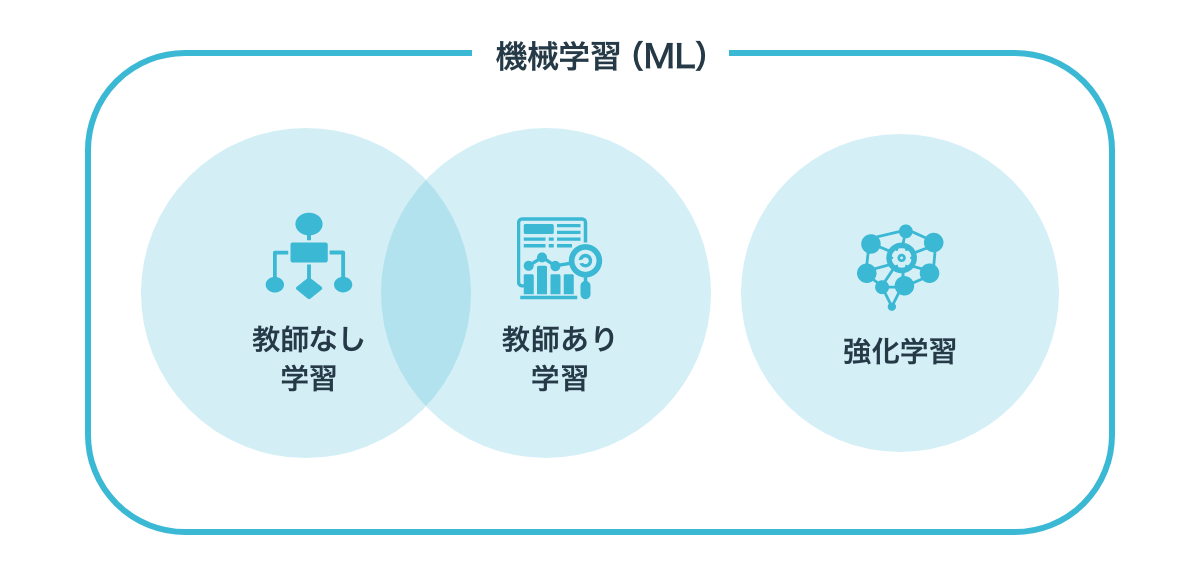
機械学習には、教師なし学習の他に「教師あり学習」や「強化学習」も存在します。
教師あり学習とは、その名の通り、教師となるデータをもとに学習していくものであり、不明なデータを持ち寄った場合には正解を教えてくれるというイメージで問題ありません。そのため、正解となるデータを大量に学習していくことで、新しいデータにも対応することができるようになるのです。
そんな教師あり学習は、「学習」「認識・予測」という2つのプロセスによって成り立っています。1つ目のプロセスである「学習」では、正解のデータを用いてルールやパターンの学習を行っていくわけです。そして2つ目のプロセスである「認識・予測」では、新しくインプットされた「まだ正解がわからないデータ」に対して、これまでに学習したデータを用いて認識・予測を行っていきます。
そして「強化学習」は、AIが報酬の獲得を求めて能動的に学んでいく機械学習モデルのことを指します。その一例としては、囲碁AIや将棋AIなどが挙げられるでしょう。
なお、最近では教師あり学習と教師なし学習を組み合わせた「半教師あり学習Semi-Supervised Learning)」という手法も活用され始めています。半教師あり学習は、学習データに「正解ラベルがついているデータ」「正解ラベルがついていないデータ」の両方を使用するのが特徴です。
「半教師あり学習」の流れとして、まず正解ラベルが付与されている一部のデータを利用し、残りの正解ラベルなしのデータに対して事前予測を行っていきます。そして、最後にすべてのデータを統合していくというものです。
通常は、大半の学習データには正解がついていません。そのため、モデル学習のためのデータを取得したり、正解ラベルをつけたりする作業を行うためのコストが発生するのが一般的です。こういった正解ラベル付きのデータを十分に用意できない状況では、「半教師あり学習」が役に立つ可能性が高くなります。
まとめると、どんな作業をAIにさせたいかによって使う手法が変わってくるということです。
教師なし学習には、「クラスタリング」「GAN(敵対的生成ネットワーク)」「アソシエーション分析」「自己組織化マップ(SOM)」「主成分分析」といった種類が存在します。これらは、どのような特徴を持っているのでしょうか。それぞれの特徴について詳しくみていきましょう。
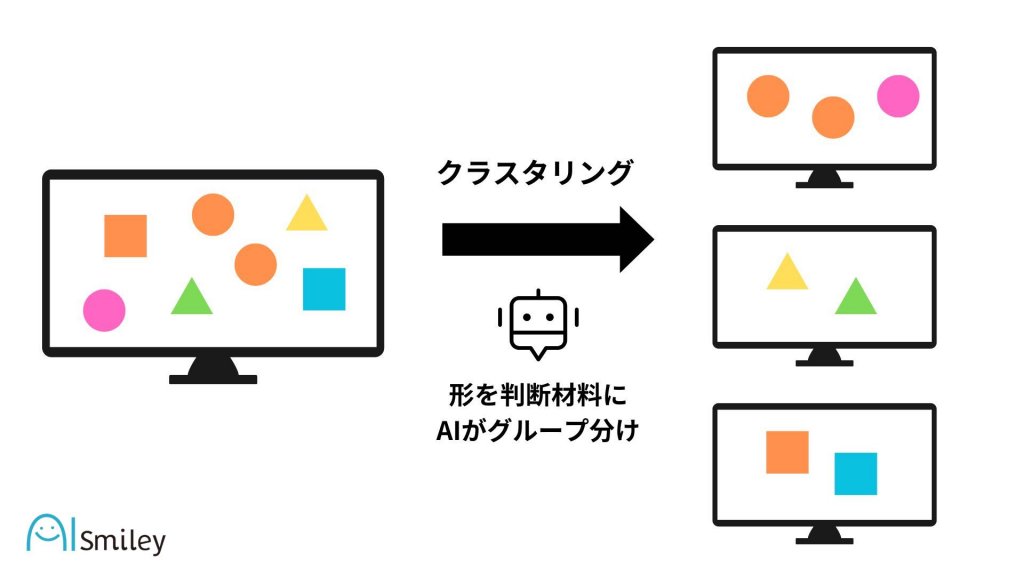
クラスタリングは「データ間の類似度に基づいてデータをグループ分けしていく手法」のことです。ただ、クラスタリングという単語自体は機械学習や統計学の以外でも用いられることがあるため、「クラスタ分析」や「データクラスタリング」といった呼ばれ方をすることも少なくありません。なお、クラスタリングによって分類されたグループは、クラスタと呼ばれます。
そんなクラスタリングの活用例としては、顧客の情報をクラスタリングすることによって「顧客のグループ分け(セグメンテーション)」を実行し、同じグループ内で同じ商品が複数回購入された場合には「同じグループに属する別の顧客にも同じ商品のレコメンドを行う」といった手法が挙げられるでしょう。
ちなみに、各データが1つのグループだけに所属するようなグループ分けの手法(複数のグループへの所属を許容しない手法)をハードクラスタリングと呼びます。そして、各データが複数のグループに所属することを許容してグループ分けしていく手法をソフトクラスタリングと呼びます。
GAN(敵対的生成ネットワーク)とは、生成モデルの一種であり、データから特徴を学習することによって実在しないデータを生成したり、存在するデータの特徴に沿って変換したりすることが可能です。正解データを与えずに特徴を学習していく「教師なし学習」の一つとして大きな注目を集めています。
そんなGAN(敵対的生成ネットワーク)は、アーキテクチャの柔軟性が高いことから、アイデア次第ではより多様な領域にも活用していくことが可能です。最近では、応用研究や理論的研究も積極的に進められているため、今後さらに発展していく可能性が高いでしょう。
教師なし学習の種類の一つに、アソシエーション分析というものも存在します。アソシエーション分析とは、データ間の関連を発見する手法です。分かりやすい例としては、「ワインを買う人はチーズも一緒に購入する」といった関連性が挙げられるでしょう。
商品の売上を高めるための複数の施策を行った場合において、「どの施策が最も売上に貢献したかのか」を分析する活用方法がアソシエーション分析です。
主成分分析も、教師なし学習の種類の一つです。主成分分析とは、さまざまな種類のデータを集約する手法のことを指します。たとえば、人が感じる味をデータ化する際には「甘み」「苦味「酸味」「コク」といったさまざまな種類のデータを扱うことになります。
主成分分析では、もとの情報を損なってしまうことを避けながら、集約されたデータで表現を行うことが可能です。主成分分析においてデータが出力された際、そのデータが何を示しているかという点に関しては、人が解釈を与えなければなりません。
そのため、アンケートの各項目の評価を集計し、総合的な評価を示していくといった活用方法が、一つの有効な活用方法といえるでしょう。
自己教師あり学習(Self-Supervised Learning, SSL)は、入力データから独自のラベルを機械的に作成して、学習を行うタスクです。
教師あり学習を行う際には大量の教師データが必要でアノテーションのコストがかかります。自己教師あり学習ではラベリングの必要がないため、アノテーションコストの大幅削減が期待されています。
教師なし学習は、実際にどのような場所で活用されているのでしょうか。ここからは、教師なし学習の応用例について詳しくみていきましょう。
画像生成も、教師なし学習を応用した技術の一つです。画像生成とは、絵画の生成や画像・映像などの自動加工を行う技術を指します。
近年は、さまざまな場面において高品質な画像が要求されるようになりました。しかし、常にその要求に応えられる完全なオリジナル画像を取得できるわけではありません。たとえば、ピントの合っていないぼやけた画像データしか用意できないケースも考えられます。また、歴史的資料であれば、カラー写真が存在せず、白黒写真しか用意できないケースも多く、ラフスケッチしか存在していないケースなども考えられます。
このような場合、専門的で工数のかかる画像加工を行ったり、イラストを描きながら撮影コンセプトを固めて写真を撮影したりしながら、高品質な画像データを準備するのは難しいのが実情です。ただ、近年はAIの技術が発展したことにより、不十分なデータからでも高品質な画像を作り出すことができるようになってきたのです。
異常検知も、教師なし学習を応用した技術の一つです。異常検知とは、大量のデータから通常とは異なるもの(異常)を検出することをいいます。データマイニングを利用してデータセット中の他のデータと照らし合わせを行い、一致していないものを識別していくという仕組みです。そのため、異常検知における「異常」というのは、通常の動作として定義された概念に当てはまらないものことを指しています。
そんな異常検知ですが、用途によっては「故障検知」「不正使用検知」といった呼ばれ方をすることもあります。そのため、これらを別物として捉えてしまう方もいらっしゃいますが、これらはすべて「他の大量のデータとは異なる振る舞いをみせるデータを検出する技術」であることに変わりはないため、すべて同じものと捉えて問題ありません。
なお、最近の異常検知では、メールや文書、動画、画像、Webサイトのログといった「非構造化データ」が用いられるケースが多くなっています。そのため、実際のビジネスにおいて活用していくためには、データ分析に関する知識や経験が必要になるでしょう。
以下のページでは、今回ご紹介した「教師なし学習」をはじめとするさまざまなAI関連ニュースを掲載しております。最新のAI活用事例を紹介しておりますので、ぜひこちらも一緒にご覧ください。
AIについて詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
教師なし学習(Unsupervised Learning)は、正解となるデータが存在せず、入力されたデータを利用して正解を導き出していきます。教師あり学習の場合、教師となるデータをもとに学習していく必要がありますが、教師なし学習は教師データが必要ありません。
教師なし学習には、以下の種類が存在します。
教師なし学習の応用例として、以下が挙げられます。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。















FOLLOW US
SNSをフォローして、最新情報をチェックできます!








AI製品・ソリューションの掲載を
希望される企業様はこちら