

生成AI

最終更新日:2024/04/12
 楽天 高性能LLMを3モデル発表
楽天 高性能LLMを3モデル発表
楽天は、日本語に最適化されたオープンかつ高性能の大規模言語モデル(LLM)を3モデル公開しました。
このAIニュースのポイント
楽天グループ株式会社は3月21日、日本語に最適化されたオープンな高性能の大規模言語モデル(LLM)3つを公開しました。高品質データでの事前学習による、高性能なLLMです。
楽天は、実現基盤モデル「Rakuten AI 7B」と、同モデルを基にしたインストラクションチューニング済モデル「Rakuten AI 7B Instruct」、インストラクションチューニング済モデルを基にファインチューニングを行ったチャットモデル「Rakuten AI 7B Chat」を、オープンなモデルとして公開しました。
「Rakuten AI 7B」は、フランスのMistral AIのオープンモデル「Mistral-7B-v0.1」を基に、継続的に大規模なデータを学習させて開発された70億パラメータの日本語基盤モデルです。また「Rakuten AI 7B Chat」は、「Rakuten AI 7B Instruct」を基にしたチャットモデルで、会話形式の文章を生成するチャットデータを用い、ファインチューニングされています。
楽天LLMの事前学習に使われたデータは、与えられた条件に従ってデータを選別および抽出を行う内製のフィルタリング機能と、関連情報をメタデータとして付与するアノテーション作業によって、質を向上させています。これにより、楽天LLMの性能の高さが実現しています。
また楽天LLMは、日本語に特化して設計された独自の形態素解析器を使用しています。この解析器によって、文章の分割単位であるトークンあたりの文字数が増加し、より多くの情報を単一のトークンに含めることが可能です。従来の形態素解析器と比較して、より効率的に事前学習や推論時のテキスト処理をし、テキストの理解と生成の精度が向上しています。
加えて楽天LLMは、言語モデルの評価基準である「LM Evaluation Harness」で高い評価を獲得しています。この評価は、日本語と英語の両方で行われ、楽天LLMがオープンな日本語LLMの中でも特に優れた性能を持つモデルとして認識されています。高品質なデータでの事前学習や、日本語に最適化された形態素解析器の使用など、複数の面で高い効率性と性能を実現していることを示しています。
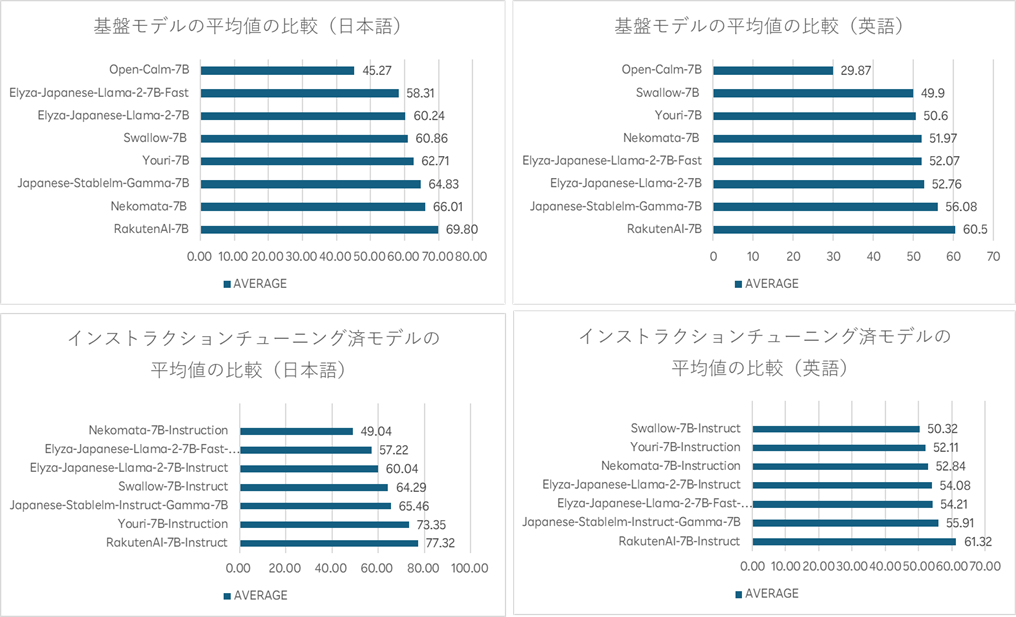
今回発表された3モデルは、文章の要約や質問応答、一般的な文章の理解、対話システムの構築などで商用目的として使用することができるほか、本基盤モデルは他のモデルの基盤としても利用可能です。
なお、今回公開された3モデルは、Apache 2.0ライセンスで提供されており、楽天の公式「Hugging Face」リポジトリからダウンロードできます。
出典:楽天
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!










AI製品・ソリューションの掲載を
希望される企業様はこちら