

生成AI

最終更新日:2025/10/17
 DeepSeek V3-0324とは?
DeepSeek V3-0324とは?
中国の DeepSeek は2025年3月25日、高い推論性能やフロントエンド開発スキルを持つ最新AIモデル「DeepSeek V3-0324」を発表しました。前モデルの「DeepSeek V3」に比べてツール使用能力が向上するなど、大幅なアップデートを実現しています。
本記事では、DeepSeek V3-0324 の特徴や前モデルからの進化、他社モデルとのベンチマーク比較などの概要を詳しく紹介します。
DeepSeek V3-0324 は、中国のAI企業 DeepSeek が2025年3月25日にリリースした最新AIモデルです。前モデル「DeepSeek-V3」は、OpenAIのGPT-4o に匹敵する高性能モデルとして公開されており、さらなるアップデートモデルとして発表されました。
DeepSeek-V3 がカスタムライセンスであったのに対し、DeepSeek V3-0324 はオープンソースの MIT ライセンスです。DeepSeek の公式Xの投稿によれば、DeepSeek V3-0324 はWeb開発におけるコーディングスキルと、推論性能における大幅な向上を実現したと述べています。
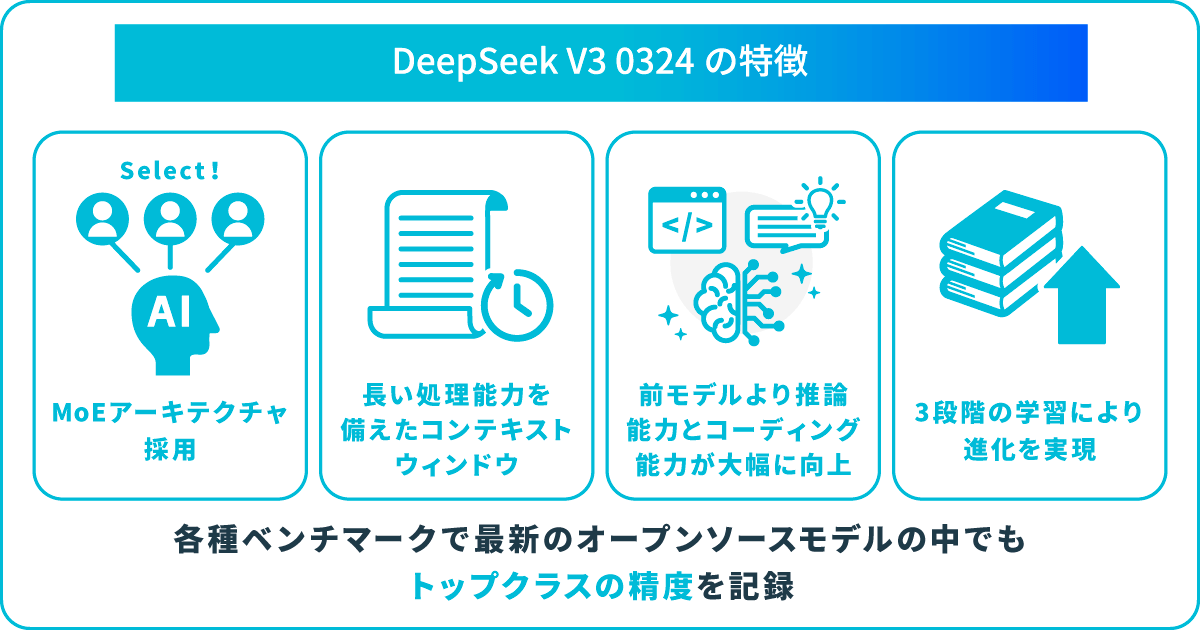
DeepSeek V3-0324 の代表的な特徴を紹介します。
DeepSeek V3-0324 では、前モデルに引き続き「MoE(Mixture-of-Experts)アーキテクチャ」が採用されています。従来のMoEで見られたエキスパートの偏りという課題を解消するために、1トークンあたりのアクティブパラメータ数を約370億まで抑えることで、計算リソースを効率化しています。
結果的に、全パラメータをフル活用した際の性能は約92%に達すると報告されています。
DeepSeek V3-0324 で入力できる文脈の長さ(コンテキストウィンドウ)は、128Kトークンと非常に長い点も大きな特徴です。この長文脈を効率的に扱うために、MLA(多頭潜在アテンション)による低次元圧縮でキー・バリューメモリを削減する工夫も導入されています。
また、マルチトークン予測(MTP)機能により、1つのステップで次の最大2~3トークンを同時予測できる補助モジュールを備えています。MoEアーキテクチャを含む Deepseek の最新独自技術により高性能モデルを実現しています。
Deepseep V3-0324 は、前モデル DeepSeek V3 から大幅にアップデートされています。まず、推論・論理推理能力が大幅に向上しました。強化学習(RL)と思考チェインデータを活用することで能力を最適化し、数学やコードの複雑な論理問題への対応力が強化されています。
また、数学・プログラミング分野では、OpenAI 社の GPT-4o を上回る性能を示しました。フロントエンド開発に関する能力も強化され、HTML/CSS などのコード生成でデザイン性やタスク実行の安定性が向上しています。
さらに、中国語での文章生成では対話型のリライト能力が向上し、言い換えや翻訳、手紙文など多様な文章生成を高精度に実行できるように調整されています。他にも、複合タスクへの対応力や正確性、関数呼び出しなどにおいても、精度の改善が見られます。
DeepSeek V3-0324 のトレーニングは、大きく分けて「プリトレーニング(事前学習)」「長文脈拡張」「ポストトレーニング(微調整+強化学習)」という3つの段階で実行されています。
プリトレーニング(事前学習)では、14.8兆トークンもの多言語文章を活用。特に数学やプログラミング関連の比率を強化し、重複の排除と多様性の両立を重視しています。
続く長文脈拡張では、32Kと128Kという2段階のシーケンスで訓練されました。YaRN(RoPE拡張手法)を採用し、コンテキスト長は最大128Kまで対応可能となっています。
最終ステップのポストトレーニングでは、教師あり微調整(SFT)と強化学習(RLHF相当)を実行。思考過程のチェックも導入されています。

DeepSeek V3-0324 の性能について、公式データによると各種ベンチマークでスコアが大幅に向上しています。以下は、ベンチマークを比較した表です。
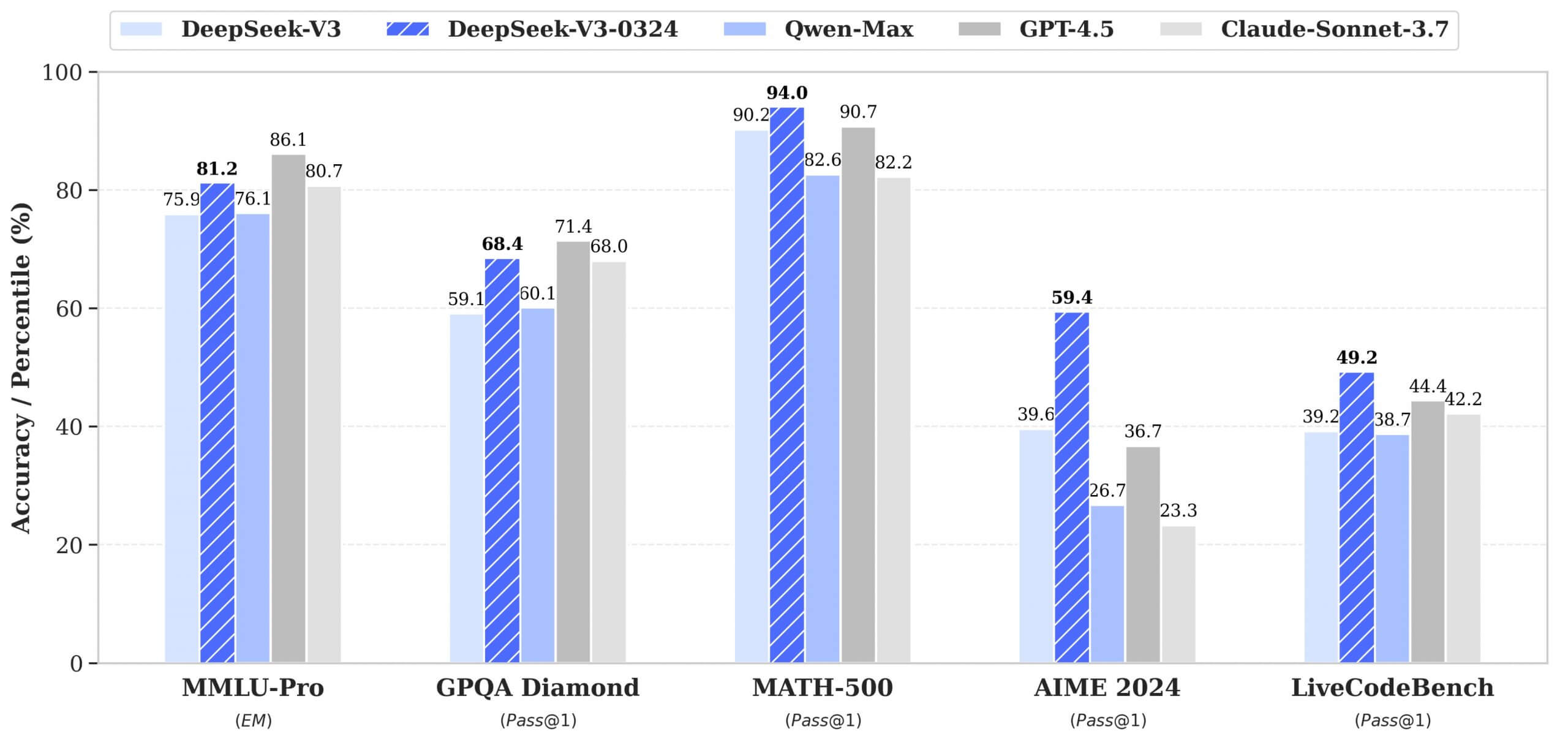
特に、数学分野やコード分野では GPT-4.5 を上回る性能を記録しました。また、一部タスクでは GPT の推定能力に匹敵するパフォーマンスを打ち出したこともわかっています。
 DeepSeek V3-0324 は現在、DeepSeek 公式サイト及びモバイルアプリにて提供されています。公式サイトではデフォルトで最新モデルが組み込まれており、設定で思考モードの切り替えも可能です。
DeepSeek V3-0324 は現在、DeepSeek 公式サイト及びモバイルアプリにて提供されています。公式サイトではデフォルトで最新モデルが組み込まれており、設定で思考モードの切り替えも可能です。
また、公式APIも公開されており、登録済みの DeepSeek API ユーザーは既存のプラットフォーム上で最新モデルを利用できます。現在、ModelScope や Hugging Face にてモデル重みデータとトークナイザ(MITライセンス)が公開されており、誰でもダウンロードや利用できます。
DeepSeek V3-0324 の活用事例として、以下が挙げられます。
例えば、プログラミングコードによる高品質なデザインのWebサイトを1つのプロンプトで自動生成することが可能です。また、10ヶ国語対応の動画スクリプトを自動生成することで、動画制作コストの大幅な軽減につながります。
DeepSeek の高い能力はすでに世界で評価されており、「中国発のAI新星」としてSNSやメディアで話題を呼んでいます。今回のアップデートにより、創造的なコードの出力や大規模モデルへのスムーズな対応などを評価する声が、技術者を中心に多く挙がっています。
また、「中小企業でも使いやすい低コストな最先端AIモデル」としても注目されているモデルです。さらに、オープンライセンスであるため、Tencent 社がモデル公開からたった1日のうちに、自社サービスに統合したことも見逃せません。クローズドモデル戦略の根幹を揺るがす存在という声も挙がっています。
DeepSeek V3-0324 は、計算リソースの効率性や長いコンテキストの処理能力を強みとするオープンソースのAIモデルです。文脈理解や数学、コードなど多くのベンチマークで前モデルの V3 を上回っており、一部の評価では GPT-4o よりも高いスコアを記録しました。
また、GPT モデルとの共存も進んでおり、並列利用によってさらなるユーザー満足度の向上も期待できるでしょう。AI業界全体が注目する DeepSeek の技術革新とその影響から目が離せません。
アイスマイリーでは、OpenAIのResponses APIのような連携サービスとその提供企業の一覧を無料配布しています。
はい、DeepSeek V3-0324 の商用利用は認められています。また、モデル出力による二次創作や、派生モデルの学習も可能です。
はい、DeepSeek V3-0324 は日本から利用できます。公式Webサイトまたはアプリからアクセスできる他、Hugging Face からモデルをダウンロードして利用することも可能です。また、APIを使えば独自のアプリケーションやシステムにモデルを組み込むこともできます。
ただし、モデルのサイズが大きいため、ローカル環境での実行に十分なハードウェアを備えているか確認しておくと無難です。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!








AI製品・ソリューションの掲載を
希望される企業様はこちら