

生成AI

最終更新日:2024/12/06
 画像生成AIとは?
画像生成AIとは?
AI技術の進歩により、画像生成の分野は目覚ましい変化を遂げています。白黒写真をカラーに変換したり、実在しない人物の顔を創造したりと、AIは私たちの想像を超える作品を生み出しています。
特に「GAN(Generative Adversarial Networks)」のような技術は、その精巧さで大きな注目を集めています。
この記事では、以下の内容に沿って、画像生成の基本原理や最先端のモデルまで、幅広く解説します。
画像認識について詳しく知りたい方は以下の記事もご覧ください。
画像認識とは?AIを使った仕組みや最新の活用事例を紹介
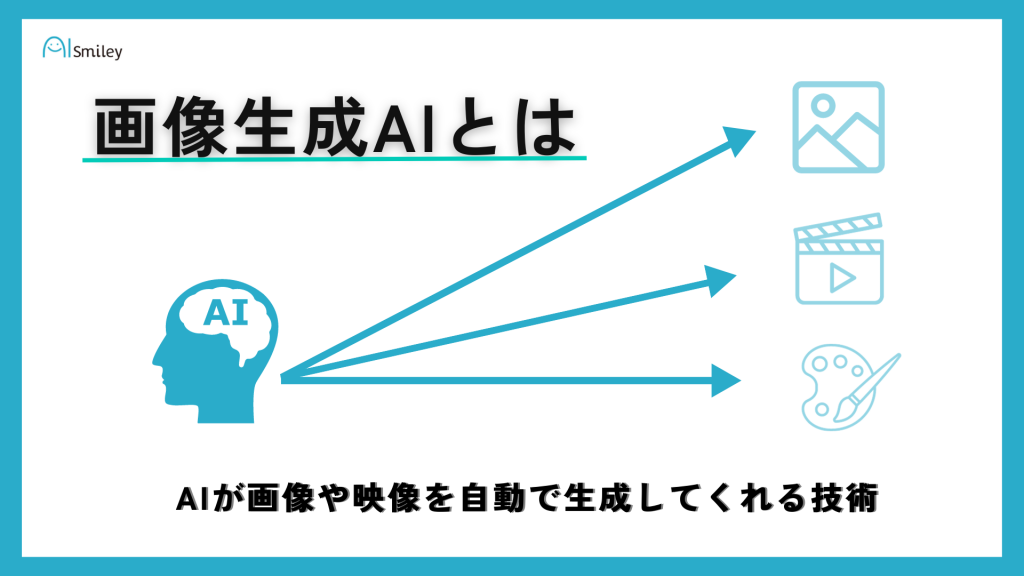
画像生成とは、絵画の生成や画像・映像などの自動加工を行う技術を指します。そのため、画像生成AIとは、AIが画像や映像を自動で生成してくれる技術になります。機械学習の手法の一つであるディープラーニング(深層学習)を利用して行われる技術としても知られています。
近年は、さまざまな場面において高品質な画像が要求されるようになりました。しかし、常にその要求に応えられる完全なオリジナル画像を取得できるわけではありません。たとえば、ピントの合っていないぼやけた画像データしか用意できないケースも考えられます。また、歴史的資料であれば、カラー写真が存在せず、白黒写真しか用意できないケースも多く、ラフスケッチしか存在していないケースなども考えられます。
このような場合、専門的で工数のかかる画像加工を行ったり、イラストを描きながら撮影コンセプトを固めて写真を撮影したりしながら、高品質な画像データを準備するのは難しいのが実情です。ただ、近年はAIの技術が発展したことにより、不十分なデータからでも高品質な画像を作り出すことができるようになってきたのです。
画像生成AIは、業務や個人利用で幅広く活用されています。以下は主な使用シーンです。
画像生成AIは画像データを大量に学習しているため、様々な画像を生成したり修正することができ、幅広く応用できます。
画像生成AIの利用において、著作権に関するポイントは非常に重要です。日本では、2018年の著作権法改正(著作権法30条の4第3号)により、機械学習における著作物利用は原則として著作権侵害に該当しないとされています。この改正により、AIが学習データとして著作物を使用すること自体は、著作権法違反とみなされるリスクが低くなっています。
ただし、生成物が既存の著作物と酷似している場合は、著作権侵害が疑われるリスクがあります。特に、商用利用や公開を予定している場合には、既存作品との類似性をチェックし、リスクを回避することが求められます。
ChatGPTの著作権のリスクについて詳しく知りたい方はこちらをご覧ください。
ChatGPTの著作権リスクは?商用利用はOK?利用時の注意点を解説
画像生成の具体的な手法の次は、実際に画像生成などが可能なツールやサイトをご紹介します。
(参照:midjourney)
Midjourneyは、テキストからイラストを自動生成する画像生成AIです。最も魅力的なのは、その使いやすさと多様なスタイルで高品質な画像を生成できる点です。ユーザーは簡単な指示を入力するだけで、ピカソ風やジブリ風、油絵風、彫刻風など、多種多様なスタイルのイラストを生成できます。
Midjourneyは、特定のアートスタイルやトーンを反映したイラストを簡単に作成できるため、クリエイティブなプロジェクトに幅広く利用されています。また、Discordを通じて手軽にアクセスでき、無料プランで試用することも可能です。有料プランに加入すると、商用利用やプライベート設定も可能になるため、プロジェクトの幅がさらに広がります。
詳しくはこちらの記事をご覧ください。
Midjourneyとは?イラストを自動生成するお絵描きAIの使い方
(参照:stable diffusion)
Stable Diffusionは、オープンソースAIとして広く普及している画像生成AIです。Stable Diffusionを使えば、ユーザーが入力したテキストをもとに、簡単にイメージ通りの画像を生成できます。
利用方法も非常に手軽で、Hugging FaceやDream Studio、MageといったWebアプリケーションを通じて、誰でもすぐに体験可能です。操作もシンプルで、ブラウザ上でテキストを入力するだけで簡単に画像を生成できるため、幅広いユーザーにとって非常に使いやすいツールです。
詳しくはこちらの記事をご覧ください。
Stable Diffusionとは?話題の画像生成AIの使い方・初心者向けのコツも徹底解説!
(参照:Canva AI)
Canvaには、テキストを入力するだけでAIがイメージを生成する「Text to Image」という機能があります。この機能は2022年から公開されており、無料プランでも利用することができます。
機能の使い方はとても簡単で、例えば「昼寝をする犬」「空を飛ぶ猫」などと文字を入力するだけで、1度に4枚の画像を生み出してくれます。
さらに、多彩なスタイル選択が可能です。写真、レトロアニメ、ネオン、ミニマルなど、多様なスタイルから選べるため、SNS投稿、プレゼンテーション資料、ブログ用バナーなど、さまざまな用途に合わせて画像を生成できます。
詳しくはこちらの記事をご覧ください。
Canva AIとは?「Text to Image」でAI画像生成

Recraftは、イギリスのRecraft社が開発した画像生成AIで、プロ向けの機能と高い操作性が特徴です。生成した画像を編集できる点が大きな強みで、デザイン作業を効率化します。写真風やアニメ風など多彩なスタイルを選べ、生成された画像はSVGやPNG、JPEGなどの形式で出力可能です。また、日本語プロンプトにも対応しており、言語の壁を感じることなく利用できます。
Recraftは、ロゴや広告画像、コンセプトアートの制作からプレゼン資料のビジュアル作成、建築や製品デザインのプロトタイプ生成まで幅広い用途に対応。さらに、有料プランでは生成物の完全所有権がユーザーに付与され、商用利用も可能です。
プロフェッショナル向けに特化した機能と高精度な生成能力を備えたRecraftは、デザイナーやクリエイターにとって、業務の効率化と創造性を広げる強力なツールです。
(参照:画像・動画の編集加工AIツール:cre8tiveAI(クリエイティブAI))
cre8tiveAI(クリエイティブAI)は、写真・イラストといった画像の編集作業をサポートしてくれるAIツールです。ディープラーニングを利用したAIツールのプラットフォームとなっており、写真やイラスト、映像に関連するクリエイティブなAIが現在進行形で追加され続けています。
代表的なサービスとしては、以下の通りです。
| サービス名 | 詳細 |
| 彩ちゃん+ | 全身イラストを制作することができる |
| Enpainter | 自分が持っている写真を、以下の世界的アーティスト風の絵画画像に変換することができる ・ゴッホ ・ピカソ ・雪舟 ・モリゾ ・キルヒナー など |
| Photo Refiner | 写真やイラスト等の画像をより美しく高画質化することができる |
| Portrait Drawer (ポートレイト ドロワー) |
写真から6種類の似顔絵を生成できる |
(参考)SNSアイコン作成におすすめ!似顔絵生成AIサービスが開始!
(参照:Artbreeder)
Artbreederは、写真をアップロードするだけでAIが「存在しない人物」を作り出してくれるサービスです。アップロードした写真を別の人物と掛け合わせたり、複数の写真を合成してまったく別の世界を作ったりと、さまざまな楽しみ方をすることができます。
そんなArtbreederでは、敵対的生成ネットワーク(GAN)が使われており、ポートレートだけでなく風景画やアニメキャラなども作成することが可能です。利用する際はアカウント作成が必要となりますが、Googleアカウントで利用することもできます。
(参照:Generated Photos | Unique, worry-free model photos)
Generated Photosは、この世に存在しない顔をAIが自動生成してくれるサイトです。
2019年に、著作権フリーのオリジナル顔画像を10万枚公開したことで、大きな注目を集めました。また、2019年まではブラウザからダウンロードすることしかできませんでしたが、2020年からは細かな条件を指定し、API経由で画像を取得できるようになっています。
具体的には、以下のような項目が用意されています。それに伴い、表情も笑顔や驚いた顔など、数多くラインナップされています。
取得した顔写真は、透過したり背景色を乗せたりすることも可能ですが、透過の場合はダウンロードに1ドルかかるため事前に把握しておきましょう。
(参照:AI(人工知能)が画像をアートに変換!ACartist)
ACartistは、AI技術を活用して2つの画像からアートを創り出すことができる無料サービスです。操作が非常に簡単なのが特徴で、2クリックで画像をアップロードするだけでアートを創ることができます。
また、AI画像生成サービスの中には、対応している画像サイズが小さかったり、固定されていたりするケースも少なくありません。しかし、ACartistであれば最大2,000pxまで対応できるため、Webサイトでの表示を考えている人でも問題なく活用することができるでしょう。
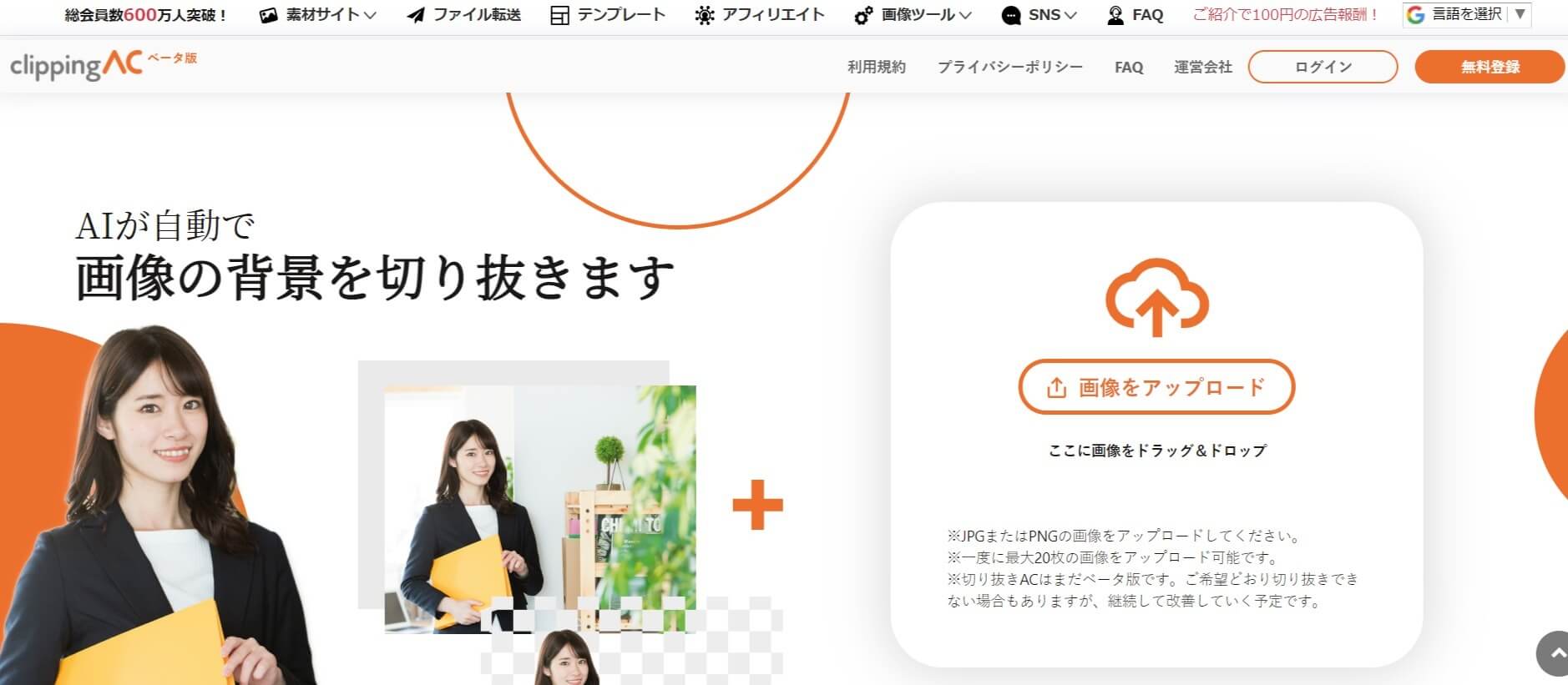
(参照:AIが自動で画像の背景を切り抜きます|切り抜きAC)
写真素材のダウンロードサイトを運営しているACワークスでは、AIが自動で背景を切り抜いてくれる「切り抜きAC」というサービスを提供しています。この「切り抜きAC」は、画像をドラッグ&ドロップ、もしくは画像のアップロードを行うだけで、AIが自動で背景を識別して切り抜いてくれるという仕組みです。
また、写真に点数をつけ良し悪しを評価してくれる「scoringAC」というサービスも提供されているなど、ACワークスでは積極的にAIが活用されています。今後もさまざまな形でAIが活用されていくことが期待されるため、ぜひこの機会に活用してみてはいかがでしょうか。
スマホでは、無料で使用できる画像生成AIアプリがあります。スマホはPCよりも持ち運びやすく、常備しているものです。そのため、いつでもどこでも簡単にAIの力を使って画像を生成することができます。
ここでは、以下の内容に沿って、無料で使えるスマホの画像生成AIアプリについて解説します。
参照:Meituアプリ
Meitu(メイツ)は、写真をAIでイラスト化する無料アプリです。美顔効果や多彩なフィルター機能を搭載し、手軽にSNS映えする画像を作成することができます。
似顔絵メーカーで個性的なアバターを生成することも可能で、写真編集からイラスト生成まで、多才な機能を持ち合わせている便利なツールです。
参照:Picsart
Picsartは、高度な画像・動画編集が可能な無料アプリです。
トリミングやフィルター適用はもちろん、背景削除や切り抜き、透過などのプロレベルの編集も手軽に行うことができます。
簡単な操作でプロレベルの編集ができるので、初心者から経験者まで、幅広いユーザーに適しています。
では、具体的に画像生成を行う場合、どのような手法が用いられているのでしょうか。ここからは、画像生成の手法について詳しくご紹介していきます。
(参照:Variational Autoencoder徹底解説 – Qiita)
VAE(変分オートエンコーダ)は、ディープラーニングによる生成モデルの一つです。訓練データを利用し、その訓練データの特徴を捉えた「訓練データに似たデータ」を生成することができます。
通常のオートエンコーダーの場合、「学習時の入力データは訓練データのみを利用し、教師データは利用しない」といった特徴や、「データを表現する特徴を獲得するためのニューラルネットワークである」といった特徴が挙げられます。入力データのXから潜在変数zに変換するニューラルネットワークをEncoderと呼びます。なお、このとき、zの次元が入力Xより小さい場合には、次元削減とみなすことも可能です。逆に、潜在変数zをインプットとして、元画像を復元するニューラルネットワークのことをDecoderと呼びます。
VAE(変分オートエンコーダ)の大きな特徴として挙げられるのは、この潜在変数zに確率分布、通常z∼N(0,1)を仮定している点です。通常のオートエンコーダーの場合、何らかの潜在変数zにデータが挿入されていますが、その構造までは明らかにできません。しかし、VAEであれば、潜在変数zを確率分布という構造に入れ込むことが可能なのです。
ニューラルネットワークについて詳しく知りたい方は、以下の記事もご覧ください。
ニューラルネットワークとは?仕組みや歴史からAIとの関連性も解説

(参照:GANで本物のように精巧な画像生成モデルを作ってみた【Pytorch】 – 株式会社ライトコード)
GAN(Generative Adversarial Networks)は、GeneratorとDiscriminatorという2つのネットワーク構造に分けられます。Generatorは、偽物ともいえるデータをランダムなノイズから作り出していくという役割を担っています。Discriminatorは、Generatorで生成された偽物データを、本物データと比較していくことによって、そのデータが本物なのか偽物なのか判定していくという役割を担っています。
このような判定を何度も繰り返しながら、GeneratorとDiscriminatorの精度の高さを改善させていくことによって、「対象の特徴をより自然な形で反映させたデータ」を自動的に生成するGeneratorが生み出されるというわけです。
また、この過程では、対象の特徴を定量化することもできます。そのため、特定のデータに別の特徴を与えたデータを自動的に生成していくこともできるのです。
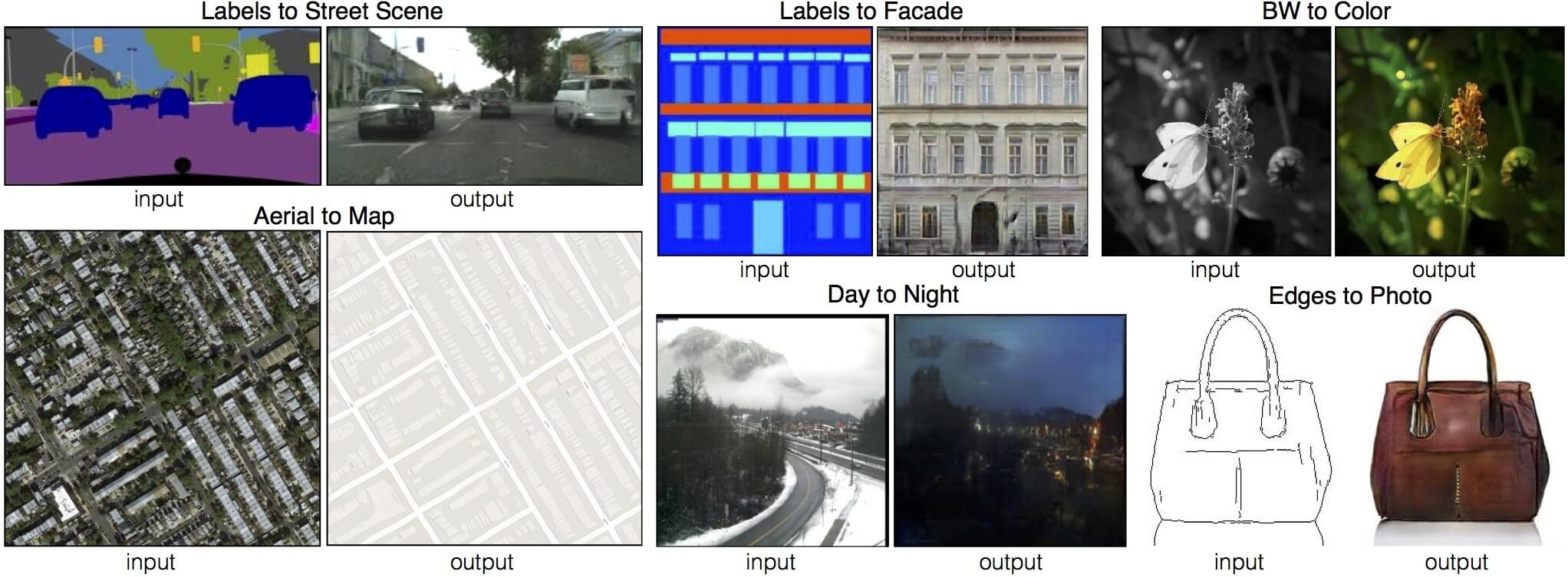
(参照:Image-to-Image Translation with Conditional Adversarial Networks)
pix2pixとは、コンピュータビジョンとパターン認識の国際会議「CVPR 2017」で発表された「Image-to-Image Translation with Conditional Adversarial Networks」という論文において発表された手法のことです。2つのペアの画像をもとに、画像間の関係を学習していき、「画像生成を行う予測モデル」と「生成された画像がダミー画像かどうかを判定していく判定器」の2つを競わせます。これにより、2つの関係を反映したペア画像を生成していくという技術です。
この技術は、CGANの拡張版ともいえるものであり、Pix2Pixは条件ベクトルではなく条件画像を利用することによって、画像〜画像への変換問題を扱っています。

(参照:GitHub – VITA-Group/TransGAN: [Preprint] “TransGAN: Two Pure Transformers Can Make One Strong GAN, and That Can Scale Up”, Yifan Jiang, Shiyu Chang, Zhangyang Wang)
TransGANとは、畳み込みを用いることなくTransformerだけで画像を生成していく技術のことです。2021年2月に誕生し、注目を集めました。大きな特徴としては、STL-10の画像生成において、CNNベースのGANを超えてState-of-the-Art(SoTA) な性能を示しているという点が挙げられるでしょう。
そんなTransGANのアーキテクチャは、ViTに類似しており、非常にシンプルなものになっています。構成部分としては「レイヤーノーマライゼーション(LN)「マルチヘッドSelf-Attention(MSA)」「全結合層」の3つです。

(参照:GitHub – NVlabs/stylegan: StyleGAN – Official TensorFlow Implementation)
StyleGANとは、教師なし学習に分類される機械学習の内の一手法である「Genera tive Adversarial Networks(GAN)」から派生したものです。前述の通りGANは、学習したデータの特徴をもとに、実在していないデータの生成を行ったり、データの変換を行ったりすることができます。
その派生として注目を集めているStyleGANは、「写真を証拠にできる時代は終わった」と言われてしまうほど、極めて高精度な画像の生成を行えるようになったのです。実際にStyleGANによって生み出された画像を見てみても、一目で「実在しない人物」だと判断することは不可能なほど高精度な画像であることが分かります。
そんなStyleGANがGANと大きく異なるポイントとして挙げられるのは、「各転置畳み込み処理のあとにstyleの調整を行っていること」「細部の特徴がノイズによって生成されていること」「潜在変数zを潜在空間wに非線形変換していること」の3点です。これらの特徴により、従来よりもはるかに高精度な画像を生成することができています。
教師なし学習について詳しく知りたい方は、以下の記事もご覧ください。
教師なし学習とは?種類・活用事例・クラスタリング手法を簡単解説
(参照:GitHub – NVlabs/stylegan2: StyleGAN2 – Official TensorFlow Implementation)
StyleGAN2とは、StyleGANを改良した敵対的生成ネットワークのことです。AdaINの代わりに、CNNのWeightを正規化することによって、dropletを除去しています。また、Progressive Growingの除去によって不自然なモードを改善したり、潜在空間において連続性を持たせて画像品質向上を図ったりと、StyleGANよりもFID等が大幅に向上している点が特徴です。
最近では、AIアーティストが作成したGANモデルを使用した「This Anime Does Not Exis t」というホームページが公開されたことでも大きな注目を集めました。このホームページでは、実在しないアニメキャラクターを生成することが可能です。

(参照:DALL·E: Creating Images from Text)
DALL・Eは、OpenAI(オープンエーアイ)が2021年に発表した画像生成モデルです。任意のテキストを入力することによって、その内容に合わせた画像を生成することができます。DALL・Eは、主に2つのステージを経て画像が生成される仕組みです。
1つ目のステージは、画像の圧縮・復元モジュールの作成。このステージではDiscrete VAE(離散変分オートエンコーダ)というモデルが使用されており、エンコーダがRGB 256×256画像を32×32の中間出力に圧縮を行い、デコーダはその中間出力を再度入力と同じ品質のRGB256×256画像に復元していきます。
一般的に画像は情報量が大きいので、そのまま扱うのは現実的とはいえません。ただ、Discrete VAEの中間出力を使用することによって、画像の情報量を192分の1にまで削減することができるわけです。そしてDiscrete VAEは、画像だけを学習データとして、入力した画像を正確に出力していくことを学習します。
2つ目のステージは、画像とテキストの対応関係を学習するというもの。この学習には、Transformerというモデルが使用されており、画像情報(画像トークン)とその内容を説明するテキスト情報(テキストトークン)の対応関係を学習していくわけです。
Transformerに入力するためのデータ形式は、「画像トークンとして中間出力したもの(32×32=1024個)」「テキストを構成する単語をベクトルに変換したテキストトークン(最大256個)」、これら2つを連結させたものになります。学習データは、インターネットを介して収集した2億5000万の画像・テキストのペアを先ほどの形式にして、120億のパラメーターを持つTransformerに学習させていくという仕組みです。
DALL・Eは、「DALL・E 2」や「DALL・E 3」の発表もしており、日々進化し続けています。
DALL・E 2、DALL・E 3について詳しく知りたい方は、以下の記事もご覧ください。
DALL·E 2の使い方 文字を入れるだけで使える話題の画像生成AIを試してみた!
DALL-E 3とは?Bing Image Creatorの使い方や品質を高めるコツを解説
今回は、画像生成AIの方法や無料ツールについて、詳しくご紹介しました。これまで多くの手間がかかっていた作業も、画像生成AIによって効率化を実現できるということがイメージできたのではないでしょうか。また、タイトルにもある通り、画像生成AIはディープラーニングの最前線ともいえる注目の技術であることもお分かりいただけたかと思います。
すでに画像生成ツール・サイトは数多く存在していますが、今後もさらに革新的なツール・サイトが登場する可能性も十分に考えられますので、ぜひこの機会に画像生成AIに関するさまざまな情報をチェックしてみてください。
2024/11/15
東京都日野市にAIプロデュースの美容室がオープン。立地選定からデザイン、メニュー開発などにAIを活用
2024/11/15
Google、Workspaceユーザー向けに「Google Vids」を提供開始。Geminiがビジネス動画作成を支援
2024/11/12
「いえらぶCLOUD」のAIコンテンツ生成機能に画像生成が登場。不動産専門のブログテーマに沿った高クオリティ画像を自動生成
「JAPAN AI SALES & MARKETING」のAI画像生成機能のギャラリーを拡充。6000点を超えるビジネス利用向け画像が利用可能に
2024/10/18
ニュウジア、「AIモデルエージェンシー」を提供開始。企業ニーズに合わせた高度でリーズナブルなAIモデルを提供
2024/10/16
7言語対応可能な生成AIライブコマースプラットフォーム「AnyLive」の提供を開始。リアルタイムで商品の紹介や販売可能
2024/10/15
Meta、高解像度動画生成モデル「Movie Gen」を発表。最大16秒の音声付き動画の生成が可能に
2024/10/10
AIで唯一無二の祭壇デザインを生成。故人らしさを表現した葬儀をプロデュース
アットホームラボ、AIを活用しホームステージング画像を自動生成する「AIホームステージング」の特許を取得
2024/10/4
生成AIで家具写真の背景を合成。商品画像の背景合成からSNS投稿まで、PicWishで対応可能
2024/10/2
東大研究グループ、ネズミの脳波を基にAIが画像を生成する研究を発表。芸術創作の新しい手法へ期待
2024/9/30
たった10秒!生成AIでプロレベルのジュエリーデザインを作成。「AI Jewelry Designer」登場
2024/9/26
Youtube、6秒間の動画クリップの生成が可能に。Google DeepMindの動画生成モデル「Veo」を統合
2024/9/19
画像生成AIツール「JAPAN AI MARKETING」に、AIで画像を部分修正する機能をリリース
2024/9/12
Apple、「Apple Intelligence」を10月より米国で提供開始。日本語対応は2025年を予定
AIの画像生成の手法として以下が挙げられます。
「GAN(Generative Adversarial Networks)」の略で、画像生成モデルの一つです。機械によって生成されたとは思えない精巧さであることから、大きな注目を集めています。
VAE(変分オートエンコーダ)は、ディープラーニングによる生成モデルの一つです。訓練データを利用し、その訓練データの特徴を捉えた「訓練データに似たデータ」を生成することができます。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!







AI製品・ソリューションの掲載を
希望される企業様はこちら