

生成AI

最終更新日:2025/07/29
 クラスタリングとは?
クラスタリングとは?
クラスタリングとは、機械学習の一種であり、「データ間の類似度に基づいてデータをグループ分けしていく手法」のことです。さまざまな用途で活用されていることから、機械学習を学ぶ上では欠かせない手法といえます。
今回は、そんなクラスタリングのメリットや手法、事例などを詳しくご紹介していきますので、ぜひ参考にしてみてください。
データマイニングについて詳しく知りたい方は以下の記事もご覧ください。
データマイニングの手法とは?膨大なデータをAIを使ってデータ分析

冒頭でもご紹介したように、クラスタリングは「データ間の類似度に基づいてデータをグループ分けしていく手法」のことです。ただ、クラスタリングという単語自体は機械学習や統計学の以外でも用いられることがあるため、「クラスタ分析」や「データクラスタリング」といった呼ばれ方をすることも少なくありません。なお、クラスタリングによって分類されたグループは、クラスタと呼ばれます。
そんなクラスタリングの活用例としては、顧客の情報をクラスタリングすることによって「顧客のグループ分け(セグメンテーション)」を実行し、同じグループ内で同じ商品が複数回購入された場合には「同じグループに属する別の顧客にも同じ商品のレコメンドを行う」といった手法が挙げられるでしょう。
ちなみに、各データが1つのグループだけに所属するようなグループ分けの手法(複数のグループへの所属を許容しない手法)をハードクラスタリングと呼びます。そして、各データが複数のグループに所属することを許容してグループ分けしていく手法をソフトクラスタリングと呼びます。
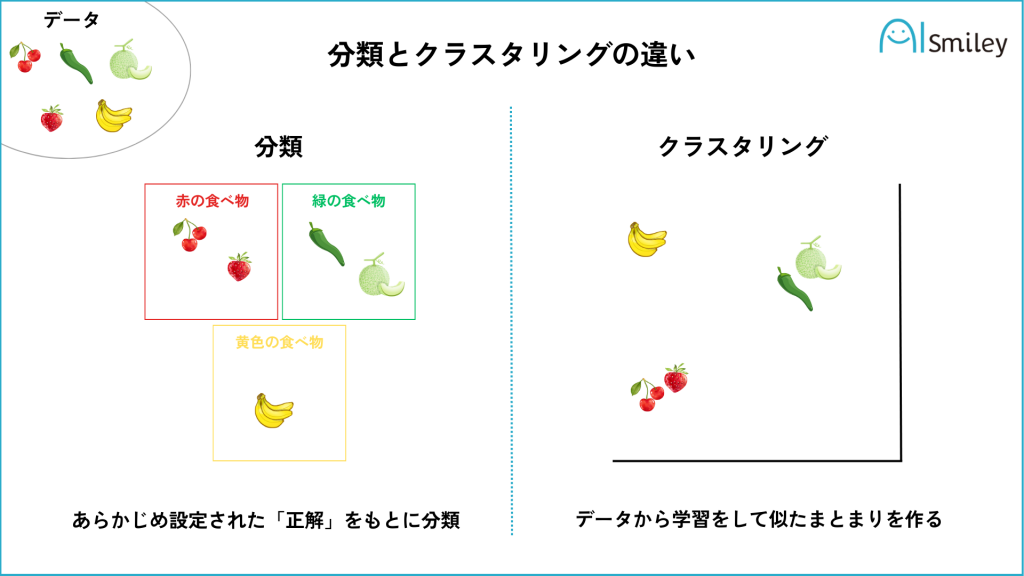
「クラスタリング=データをグループ分けしていく手法」と聞いて、分類とは何が違うのか疑問に感じた方もいらっしゃるのではないでしょうか。しかし、クラスタリングと分類には大きな違いが存在します。それは、「グループ分けに明確な答えが存在するかどうか」という点です。
たとえば、手書き文字認識を行う場合、属性を付与するための「正解」となるデータを用意しておかなければなりません。つまり、手書き文字認識においては「明確な答え」が存在しているということです。この事例はまさに「分類」に該当します。
一方のクラスタリングは、顧客のグループ分けを行う場合などが該当します。さまざまな顧客の情報をグループ分けしていくことになるため、「絶対的な正解」を用意することはできません。あくまでもデータをもとに特徴を学習して、グループ分けを行うことになるわけです。
答えをもとに学習したデータを用いるのが「分類」、データをもとに特徴を学習していくのが「クラスタリング」と考えれば分かりやすいでしょう。
クラスタリングには、「階層的クラスタリング」「非階層的クラスタリング」という2つの種類が存在します。階層的クラスタリングとは、データ間の類似度が近いものからまとめていく手法のことです。データの類似度が遠いものから離していく手法ともいえます。
一方の非階層的クラスタリングは、「グループ分けの良さを表現する関数」を定義した上で、反復的に計算していくことによって、関数が最適となるグループに分けていく手法のことです。
クラスタリングの概要についてはお分かりいただけたかと思いますが、実際にクラスタリングを導入するメリットとしては、どのような点が挙げられるのでしょうか。ここからは、クラスタリングのメリットについて詳しくご紹介していきます。
マーケティングにおいて、顧客の性別や年齢、趣味嗜好などをもとに顧客市場を再分解していく「セグメンテーション」は非常に重要な作業といわれています。セグメンテーションを適切に行うことで、最適な顧客層に対して自社の提供する製品(サービス)を訴求することができるようになるからです。また、最適な訴求を行うためのマーケティング戦略を立てる上でも役立てることができます。
こういったセグメンテーションの実施には、まさにクラスタリングが最適といえるでしょう。分析の目的に沿って「セグメンテーション変数とする属性」を定めることで、効果的にターゲット市場の選択を行えるようになります。
新たに製品(サービス)の販売を行う際は、いかに競合との差別化を図れるかという点にも注意しなければなりません。そのため、多くの企業はキャンペーンや無料体験といった施策を講じるわけですが、施策の効果を最大化させるためには市場調査が重要になります。他の企業と似通った施策を講じているだけでは、「自社の製品(サービス)を利用することのメリット」が顧客に伝わりにくくなってしまうからです。
だからこそ、自社の製品(サービス)でしか得られないメリットを伝えるための差別化戦略が重要となります。クラスタリングは、企業との差別化を図るための分析作業にも応用していくことが可能です。
多くの企業は、マーケティング施策を導入する前の段階で、少ない顧客で構成されたテストマーケットでの「事前評価」を行います。このテストマーケットでの事前評価が高ければ、本格的にマーケティング施策を実行へと移していくわけです。
そんなテストマーケットの選定においても、クラスタリングは効果的な手段といえるでしょう。形成されているクラスタからテストマーケットを選出することで、マーケット間の異質性とテストの網羅性を担保できるのです。
クラスタリングには、デメリットがあることも把握しておく必要があります。クラスタリングのデメリットとして挙げられるのは、「計算量が多い」という点です。クラスタリングでは、すべてのデータの組み合わせを計算し、ひとつずつクラスタを作っていかなければなりません。そのため、データの数が多くなるにつれて計算量も膨大なものになってしまうのです。
また、データの数が多くなると、樹形図を作成しても分かりにくさが増してしまうため、活用が難しくなってしまうリスクもあります。こういった点を踏まえると、データ数が多くなるビッグデータは、階層クラスタリングには不向きといえるでしょう。
クラスタリングの手法は以下の2軸で分類することができます。
詳しい手法についてそれぞれ解説いたします。
階層的クラスタリングは、「最も似ているサンプル(もしくは最も似ていないサンプル)同士をひとつずつ順番にグルーピングしていく」という手法です。一つずつデータを比較し、似ているもの同士をクラスタとしていきます。そして、そのクラスタに一番似ているデータ(クラスタ)をグループ分けしていくわけです。これらの作業は、すべてのデータがグルーピングされるまで繰り返されます。
そんな階層的クラスタリングには、主に以下のような4つの計算手法が存在します。それぞれみていきましょう。
群平均法は、2つのクラスタを構成するデータの全組み合わせの距離を求めた上で、その平均をクラスタ間の距離としていく計算手法です。全組み合わせの距離の平均を用いるので、クラスタ内に外れ値があった場合でも影響を受けにくいという特徴があります。また、クラスタが帯状に連なってしまう鎖効果が起こりにくい点も特徴といえるでしょう。
ウォード法とは、データの平方和(それぞれのデータと平均値の差を二乗した値の和)を求めた上で、平方和が小さい順にクラスタを作っていく計算手法です。平方和は、データのバラつきを示すものでもあるため、「平方和が大きい=データのばらつきが大きい」、「平方和が小さい=データのばらつきが小さい」と捉えることができます。
最短距離法とは、2つのクラスタ間で最も近いデータ同士の距離を「クラスタ間の距離」として採用する計算手法です。単連結法と呼ばれるケースもあります。群平均法と同じようにクラスタを構成する要素同士の距離をすべて求めた上で、最も距離の短い組み合わせを選択し、その値をクラスタ間の距離として考えるというものです。
ウォード法よりも計算量が少なくなる点はメリットといえますが、外れ値に弱い点はデメリットといえるでしょう。
最長距離法とは、最短距離法とは逆の方法で行う計算手法です。完全連結法と呼ばれることもあります。クラスタを構成している要素同士のすべての距離の中で、最も距離が長いものをクラスタ間の距離として採用するという手法です。
最短距離法と同じく、計算量が少ないという点はメリットですが、外れ値に弱い点がデメリットといえます。
階層的クラスタリングのように階層を作らず、データをグルーピングしていく手法のことを「非階層的クラスタリング」といいます。そんな非階層的クラスタリングの代表的な手法として挙げられるのが、「k-means法(k平均法)」というものです。
k-means法とは、非階層クラスタリングを行うためのアルゴリズムのことです。「指定されたk個のクラスタに、平均(means)を用いて分類していく」という意味が込められています。
そんなk-means法は、初めに指定したクラスタの数だけ「重心」をランダムに指定して、その重心をもとにクラスタをグルーピングしていくという手法です。k-means法を活用すれば、データ間の距離を計算する必要がなくなるというメリットがあります。
ただし、最初の重心はランダムに指定されるという点には注意が必要です。同じ母集団であっても、計算する度に結果が少しずつ変化する可能性があることを把握しておくことが大切になります。
ハードクラスタリングは、各データを一つのグループに割り当てる方法で、各データは必ず一つのグループに属します。
ハードクラスタリングのメリットは、各データが明確に一つのグループに属するため、解釈が容易であり、計算が高速であることです。一方、デメリットは、データが複数のグループに属する場合には適用できないことです。
ソフトクラスタリングは、各データが複数のグループに属する確率を計算する方法で、各データがどのグループに属するかは確率的に決まります。
ソフトクラスタリングのメリットは、各データが複数のグループに属する確率を計算するため、データが複数のグループに属する場合にも適用できることです。また、グループ間の類似度を評価する指標として、距離以外の指標を使用できることもメリットの一つです。一方、デメリットは、解釈が複雑であることや、計算が複雑であることです。
クラスタリングは、すでにさまざまな分野で活用され始めています。実際にどのような分野で活用されているのか、活用事例を見ていきましょう。

マネックス証券では、株式会社AI Shiftが提供しているAIチャットボット「AI Messenger Chatbot」を導入し、顧客対応の効率化に繋げています。この「AI Messenger Chatbot」には、運用サポート機能の「AI Compass」が搭載されており、クラスタリングによってチューニング作業の効率化を実現しているのです。
チャットボットを適切に運用するためには、「手動での対応が必要となる問い合わせ内容の分析」、「回答の紐付け」といったチューニング作業が欠かせません。この作業に関しては、AIを熟知した人の手によって行われるのが一般的でした。
しかし、「AI Messenger Chatbot」では、これらの作業をAIがサポートするため、更なる業務効率化が期待できるのです。
また、クラスタリング技術を問い合わせ分析業務にも活用することで、自動化可能な領域を可視化したり、AIの事前学習データを集計したりすることも可能になります。
順天堂大学では、日本医学放射線学会所属の施設の研究代表機関として、国立大学法人東海国立大学機構 名古屋大学、国立情報学研究所などと共同で、新型コロナウイルスによる肺炎CT画像をAIで解析する手法を開発しました。この研究開発においてもクラスタリングが活用されています。
今回開発された技術では、以下のような3つの技術が開発されました。
これらの処理において、ニューラルネットワークやクラスタリングといった技術が用いられているのです。今後、新型コロナウイルス対策において、クラスタリングがどのような役割を果たしていくのか、ますます目が離せません。

今回は、クラスタリングと分類の違いについてご紹介するとともに、クラスタリングのメリット・手法・事例などをご紹介しました。新型コロナウイルス対策にクラスタリングが活用されていることからも、非常に重要な役割を担う手法であることがお分かりいただけたのではないでしょうか。
AIsmileyでは、データ分析のサービスごとの利用料金・初期費用・無料プラン・トライアルの有無などを簡単に比較検討できる資料を無料でお配りしております。無料トライアルが設けられているサービスもありますので、ノーコードでのクラスタリングに興味をお持ちの際は、ぜひお気軽にお問い合わせください。
AIについて詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
クラスタリングとは、機械学習の一種であり、「データ間の類似度に基づいてデータをグループ分けしていく手法」のことです。さまざまな用途で活用されていることから、機械学習を学ぶ上では欠かせない手法といえます。
クラスタリングのメリットとして、以下が挙げられます。
データ間の類似度が近いものからまとめていく手法のことです。データの類似度が遠いものから離していく手法ともいえます。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。



















FOLLOW US
SNSをフォローして、最新情報をチェックできます!







AI製品・ソリューションの掲載を
希望される企業様はこちら