

最強モデル「Claude Mythos」はなぜ一般開放されない?異次元のコーディング・推論性能
最終更新日:2026/07/16

Anthropicが開発した最新モデル「Claude Mythos Preview」が注目を集めています。しかし、このモデルには既存のClaudeシリーズと決定的に異なる点があります。それは「一般ユーザーには決して公開されない」ということです。
なぜ、これほどの高性能AIが「封印」されているのか。その理由は、脆弱性の発見から攻撃コードの作成までを自律的にこなす、極めて高いサイバーセキュリティ能力にあります。
本記事では、一般公開されないMythosの驚異的な性能や、提供範囲を限定する「Project Glasswing」の実態を解説します。次世代AIがもたらす破壊的進化と、企業が知っておくべき安全管理の最前線を、最短ルートで理解しましょう。
Mythosとは?一般公開されない理由
Claude Mythos Previewとは、Anthropicが開発した大規模言語モデルで、公式サイトでは「Claude Mythos Preview」または「Mythos Preview」と表記されています。Mythosは古代ギリシャ語に由来し、「発話」や「物語」といった意味を持つ言葉です。
AnthropicはClaude Mythos Previewを、コーディングやエージェント型タスクに強い汎用フロンティアモデルと説明しています。
また、サイバーセキュリティ領域でも高い能力を示しており、脆弱性の発見・再現・修正や概念実証(PoC)の作成につながる能力が確認されています。
そのためAnthropicは、Claude Mythos Previewを一般提供する予定はないと説明しています。
現在はProject Glasswingの一環として、重要なソフトウェア基盤を守る組織などに対し、防御的なサイバーセキュリティ用途を中心とした研究プレビューとして提供されています。Anthropicのドキュメントでも、アクセスは招待制であり、セルフサービスの申し込みはないとされています。
なお、2026年4月には、Claude Mythos Previewに対して一部の未承認ユーザーがアクセスしたと報じられています。
報道によると、第三者ベンダー環境の情報などを手がかりにアクセスされたとみられ、Anthropicが調査を進めています。限定提供される高性能モデルであっても、提供先や外部環境を含めた管理体制が重要であることがわかります。
参考:Anthropic「System Card: Claude Mythos Preview」
Mythosの性能を6つの観点から解説
Mythosの性能は、他のAIと同じく複数のベンチマークで評価されています。
AnthropicではMythosの性能を計測する際に、公開されているベンチマークの問題とその回答が意図せずモデルの学習データに含まれてしまわないよう、評価においては複数のデータ除染(デコンタミネーション)対策を行っています。
例えばマルチモーダル(画像を含む)評価においては、評価データに含まれる画像と一致する特徴(パーセプチュアルハッシュ)を持つ画像が学習データ内に存在する場合、その学習データは除外される形です。
以下では、Mythosの性能について、次の6つの観点から紹介します。
- ソフトウェア開発能力
- 推論力
- 数学力
- 長文理解
- 自律検索
- マルチモーダル
ソフトウェア開発能力
ソフトウェア開発能力について、SWE-benchとTerminal-Bench 2.0の2つの評価から解説します。
SWE-benchにおける評価
画像出典:Anthropic「System Card: Claude Mythos Preview」
ソフトウェアエンジニアリング分野における代表的な評価指標のひとつが、SWE-benchです。
これは、GitHub上の実際のソフトウェア課題をもとに、大規模言語モデル(LLM)がどの程度問題を解決できるかを評価するベンチマークです。
SWE-bench Verified、SWE-bench Multilingual、SWE-bench Proはオープンソースリポジトリの問題を利用しているため、内容がモデルの学習データに含まれている可能性があります。
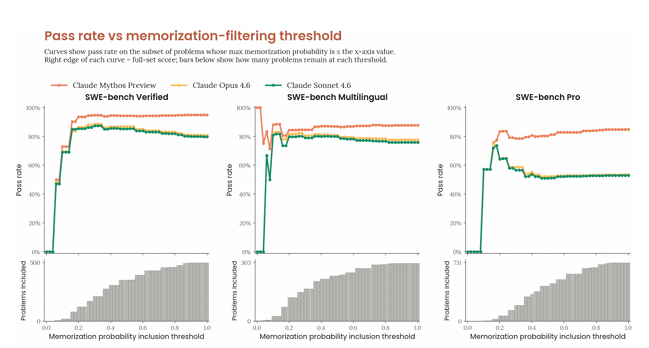
そのためデータ全体での除染を行っていますが、それでも3つのベンチマークすべてにおいて、記憶(モデルが独自に解答を導くのではなく、学習データに含まれていた解答を再現してしまう現象)の兆候が一部確認されています。
性能を検証する際は、すべてのベンチマークの試行に対して複数のフィルターを適用し、記憶の可能性が指摘された問題をさまざまな閾値で除外しました。
その結果、フィルターの厳しさを変えても、Mythosは上記グラフのようにClaude Opus 4.6やSonnet 4.6を大きく上回る性能を維持しました。
この結果は、記憶に頼らずソフトウェア課題を解決する能力の高さを示しています。
Terminal-Bench 2.0における評価
一方のTerminal-Bench 2.0は、AIモデルがコードを生成するだけでなく、実際にターミナル上でコマンドを実行しながら問題を解決できるかを評価するベンチマークです。
評価にあたっては、推論の遅延(レイテンシ)の影響の受けやすさ、制限時間の厳しさによる本来の性能向上の見えにくさといった要因を排除し、純粋なエージェント型コーディング能力を評価しています。
そのため、標準条件での評価とは別に、GitHub上で公開されている2.1改善版を用い、制限時間を約4時間(2.0の約4倍)に延長して再評価を行いました。
その結果、平均報酬は92.1%に向上しました。標準条件での評価結果とは異なる条件での再評価である点には注意が必要です。
この結果は、ターミナル操作を含む複雑なコーディングタスクでも、同モデルが高い性能を示すことを証明しています。
上記2つの結果から、Mythosは図表を含む複雑な情報の理解や、専門性の高い問題への推論において高い性能を示しています。
推論力
本モデルの推論力を、CharXiv ReasoningとGPQAの2つの評価からご紹介します。
CharXiv Reasoningによる評価
画像出典:Anthropic「System Card: Claude Mythos Preview」
CharXiv Reasoningとは、論文中の図表や情報をもとに、複数の要素を統合して推論する能力を評価するベンチマークです。
既存の公開資料を基に作成されているためモデルの学習データに含まれている可能性が高く、完全に除去(デコンタミネーション)することが難しいという特徴があります。
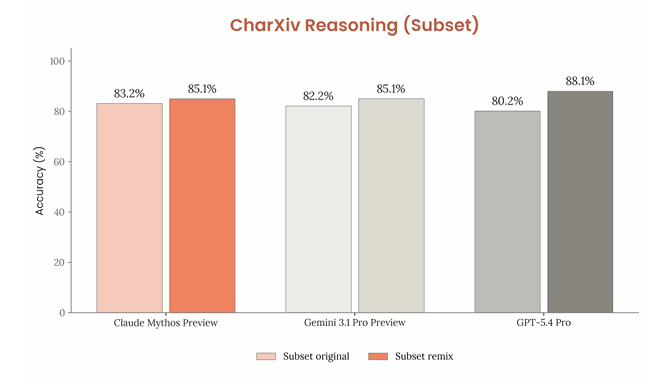
そこで、今回の検証では、一部の問題について「改変版(リミックス)」を作成し、元の問題との正答率を比較しています。
その結果、MythosやGemini 3.1 Pro Preview、GPT-5.4 Proはいずれも、元の問題より改変後の問題で高いスコアを記録しました。
この結果から、少なくともこの評価では、記憶の影響だけで高スコアになったとは考えにくいことが示唆されています。
GPQAにおける評価
GPQA(Graduate-Level Google-Proof Q&A)は、大学院レベルの難易度を持つ科学分野の多肢選択式問題で構成されたベンチマークです。
今回の検証で使用された「Diamond」サブセットは、専門家であれば正答できる一方で、一般的な知識レベルでは解答が難しい問題群で構成されています。
Mythosは、GPQA Diamondにおいて5回の試行平均で94.6%という正答率を記録しました。
上記2つの結果から、図表を含む複雑な情報の理解や、専門性の高い問題への推論において高い性能を示しています。
数学力
画像出典:Anthropic「System Card: Claude Mythos Preview」
USAMO(USA Mathematical Olympiad)は、米国の高校生を対象とした全米規模の数学オリンピックで国際数学オリンピック(IMO)米国代表選考の1段階に位置づけられています。2日間にわたり計6問の証明問題に取り組む高度な競技です。
AIの評価指標として広く用いられてきたAIMEは、すでに多くのモデルが高得点を記録しているため、より難易度の高い評価としてUSAMOが用いられています。
なお、2026年のUSAMOは2026年3月21日〜22日に実施されており、Mythosの学習データには含まれていません。
証明問題は短答式と異なり採点に主観が入りやすいため、MathArenaの採点手法に基づき、以下のプロセスで評価が行われています。
- 解答は中立的なモデル(Gemini 3.1 Pro)によって書き直し
- その後、3つの先端モデル(Gemini 3.1 Pro、Claude Opus 4.6、Mythos)が採点
- 最終スコアは、最も低い評価を採用
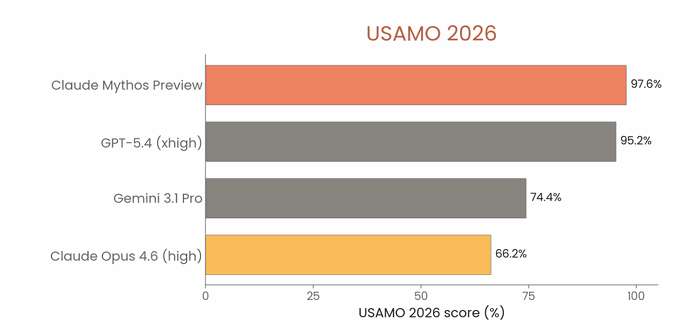
この評価において、各問題につき10回の試行を行い、最大推論設定(ツールなし)で97.6%という非常に高いスコアを記録しました。
同モデルは、数学証明のように長い推論を必要とする問題でも高い解答能力を示しています。
長文理解
GraphWalksは、長文コンテキストにおける推論能力を評価するマルチホップ型(複数の情報を順番にたどりながら結論を導く処理)ベンチマークです。
評価では、コンテキストウィンドウ内に16進数のハッシュ値で構成されたノードの有向グラフが配置されます。モデルには、ランダムに選ばれた開始ノードからBFSを実行する処理と、親ノードを特定する処理の2種類が求められます。
Mythosは、5回の試行平均で以下のスコアを記録しました。
- BFS(256K〜1Mトークン):80.0%
- 親ノード特定(256K〜1Mトークン):97.7%
この結果から、大量の情報を扱う環境でも、複数の情報のつながりを追いながら処理する能力が高いと考えられます。
自律検索
ここからは自律検索能力を、Humanity’s Last Examによる評価とBrowseCompによる評価の2つに分けて紹介します。
画像出典:Anthropic「System Card: Claude Mythos Preview」
Humanity’s Last Examによる評価
Humanity’s Last Exam(HLE)は、「人類の知識の最前線」を対象としたマルチモーダルベンチマークで、2,500問の問題で構成されています。
評価では、以下2つの条件で検証し、採点にはClaude Opus 4.6を使用しました。
- ツールを使用しない推論のみの構成
- Web検索、ページ取得、プログラム的ツール呼び出し、コード実行などを組み合わせた構成
その結果、ツールなしで56.8%、ツールありで64.7%というスコアを記録しました。
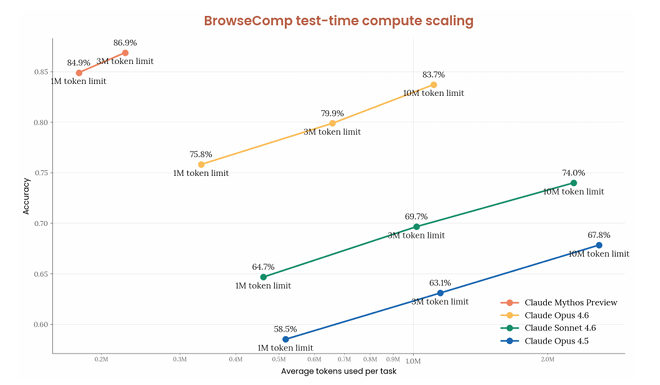
BrowseCompによる評価
BrowseCompはインターネット上に存在する見つけにくい情報を発見する能力を評価するベンチマークで、公開情報の中から必要な情報を効率的に見つけ出す能力が求められます。
評価では、Web検索、ページ取得、プログラム的ツール呼び出し、コード実行を組み合わせた環境で検証が行われました。
この評価において、Mythosは最大推論設定かつ300万トークンの条件下で、86.9%というスコアを記録しました。
これらの結果から、外部ツールを使いながら必要な情報を探し、回答につなげる能力が高いと考えられます。
マルチモーダル
画像出典:Anthropic「System Card: Claude Mythos Preview」
マルチモーダル性能は、画像理解や画面操作など複数の観点から評価されています。主な評価には、以下の4種類のベンチマークが用いられました。
- LAB-Bench FigQA(図表理解)
- ScreenSpot-Pro(画面操作)
- CharXiv Reasoning(論文図表)
- OSWorld(実環境操作)
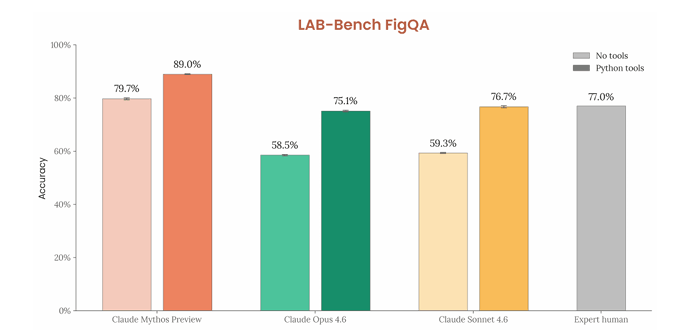
LAB-Bench FigQAは、生物学の研究論文に掲載される複雑な科学図表を正しく解釈・分析できるかを評価するビジュアル推論ベンチマークです。
本テストにおいて、適応的思考(adaptive thinking)かつ最大推論設定(max effort)の条件において、以下のスコアを記録しました。
- ツールなし:79.7%
- Pythonツールあり:89.0%
いずれの条件においても、Claude Opus 4.6とClaude Sonnet 4.6を大きく上回る結果となっています。
このことから、Mythosが複雑な図表情報を読み取り、内容をもとに判断する高いビジュアル推論能力を備えていることがわかります。
参考:Anthropic「System Card: Claude Mythos Preview」
Mythosのサイバーセキュリティ性能
Mythosのサイバーセキュリティ性能について、サイバー能力の特徴・想定されるリスクと対策・各種ベンチマークによる検証結果の3つの観点から解説します。
サイバー能力の特徴
Mythosは、Anthropicがこれまでに公開してきたモデルの中でも、特に高いサイバー能力を持つモデルとされています。
モデルの能力向上に伴い、評価の考え方も変化しています。Anthropicは、従来の静的なベンチマークだけでなく、サイバーセキュリティの現場に近いタスクでの評価を重視しています。
本モデルは、脆弱性の発見および活用の分野において大きく進化し、オープンソースおよびクローズドソースのソフトウェアの両方において、ゼロデイ脆弱性を自律的に発見することが示されています。
また多くの場合において、発見された脆弱性を実際に動作する概念実証(PoC)エクスプロイトへと発展させる能力も確認されているのです。
これらのことから、サイバーセキュリティ領域で、脆弱性の発見や検証を支援できる可能性が高いモデルと考えられます。
リスクと対策
Mythosにおけるサイバー領域での不正利用対策は、主に「プローブ分類器(probe classifiers)」による監視と、厳格に審査されたパートナーへの限定的な提供によって行われています。
プローブ分類器はモデルの利用内容を分析し、潜在的な不正利用を以下の3つのカテゴリに分類して監視します。
| 項目 | 概要 |
|---|---|
| 禁止用途(Prohibited use) | コンピュータワームの開発など、正当な利用がほとんど想定されない用途 |
| 高リスクなデュアルユース(High risk dual use) | 正当な用途も一定程度存在するものの、攻撃目的で利用された場合に重大な被害を引き起こす可能性がある用途 |
| デュアルユース(Dual use) | 正当な利用が一般的である一方、悪用される可能性もある用途 |
また、本モデルは提供範囲が限定されているため、分類器による検知を理由に処理を一律に遮断する仕組みは採用されていません。
これは、信頼されたセキュリティ専門家が防御目的で活用できるようにするための設計です。
このように、同モデルは高いサイバー能力を持つため、提供先の制限や利用内容の監視といった対策が取られています。
一方で、限定提供されるモデルであっても、外部ベンダー環境や共有アカウント、APIキーの管理が不十分であれば、不正アクセスのリスクは残ります。
2026年4月には、Claude Mythos Previewに一部の未承認ユーザーがアクセスしたと報じられており、Anthropicは調査を進めているとされています。高性能AIモデルの安全対策では、モデル自体の制御だけでなく、提供先を含めた運用管理も重要です。
実際の検証結果
ここからは、実際の検証結果について、Cybenchによる評価とCyberGymによる評価の2つに分けてご紹介します。
Cybenchによる評価
Anthropicはこれまで、AIモデルのサイバーセキュリティ能力の評価においてCTF(Capture The Flag)形式の課題を活用し、あわせて網羅的な能力評価にはCybenchを使用してきました。
CTF(Capture The Flag)は、サイバーセキュリティ分野における競技形式の課題であり、実践的な攻撃・防御スキルを測るために広く活用されています。
一方、CybenchはAIモデルのサイバーセキュリティ能力を評価するためのベンチマーク環境であり、主に研究用途で用いられています。
Mythosはこれらの評価において高い性能を示しており、特にCybenchでは、テスト対象の課題すべてで達成率100%(pass@1)を記録しました。
CyberGymによる評価
画像出典:Anthropic「System Card: Claude Mythos Preview」
既存ベンチマークが飽和状態に達したことから、Anthropicは新たな評価指標の検討を進めています。
その中でも、実環境に近い評価として重視されているのがCyberGymです。
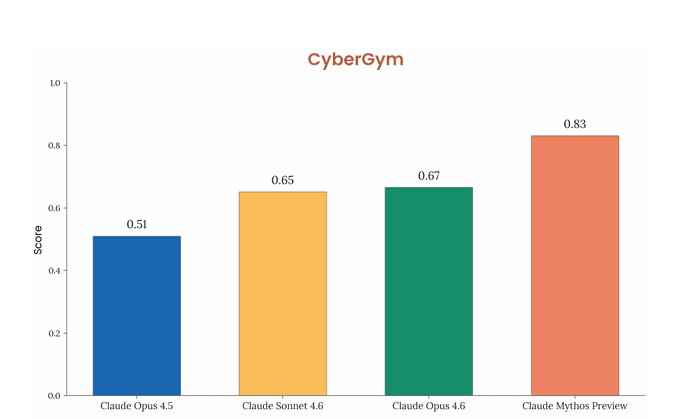
CyberGymは、実在するオープンソースソフトウェアにおいて、既知の脆弱性を抽象的な説明から特定できるか(ターゲット型脆弱性再現能力)を評価するベンチマークです。
スコアは、CyberGymに含まれる1,507のタスクに対するpass@1(1回の試行で達成する確率)で評価されます。この評価では、各タスクを1回ずつ実行した結果をもとに、全体のパフォーマンスを集計しています。
本モデルは0.83のスコアを達成し、Claude Opus 4.6の0.67、Claude Sonnet 4.6の0.65を上回る結果となりました。
これらの結果から、既存のベンチマークだけでなく、実環境に近いサイバーセキュリティ評価でも高い性能を示していると考えられます。
参考:Anthropic「System Card: Claude Mythos Preview」
AnthropicがClaude Mythos Previewで目指す方向性
AnthropicがClaude Mythos Previewで目指す方向性を、「AIを活用したサイバーセキュリティの強化」「社会全体におけるサイバーセキュリティ基盤の強化」の2つの観点から紹介します。
AIを活用したサイバーセキュリティの強化
Anthropicは「Project Glasswing」という取り組みを通じて、AIを活用したサイバーセキュリティの強化を目指しています。
具体的には、Project GlasswingのパートナーにClaude Mythos Previewへのアクセスを提供し、基盤システムの脆弱性や弱点の発見・修正に活用します。
Project Glasswingには、AWS、Apple、Broadcom、Cisco、CrowdStrike、Google、Linux Foundation、Microsoft、NVIDIA、Palo Alto Networksなどの組織が参加しています。また、AnthropicはProject Glasswingや追加参加者向けに、1億ドル分のモデル利用クレジットを用意すると説明しています。
これらの基盤システムは、世界全体のサイバー攻撃対象領域(アタックサーフェス)の大きな割合を占めており、その安全性の確保が重要な課題となっています。
この取り組みでは、ローカル環境での脆弱性検出、バイナリのブラックボックステスト、エンドポイントの保護、システムのペネトレーションテストなどが実施される見込みです。
Project Glasswingは今後数か月にわたって拡大・継続される予定であり、Anthropicは90日以内に、得られた知見や公開可能な修正内容を報告するとしています。
社会全体におけるサイバーセキュリティ基盤の強化
Anthropicは、Mythosの攻撃・防御両面のサイバー能力について、米国政府関係者とも継続的に協議を行っています。
Anthropicは、米国や同盟国がAI技術で優位性を保つことや、AIモデルに伴う国家安全保障上のリスクを評価・軽減するうえで、政府の役割が重要だと説明しています。
将来的には、民間と公共の双方を横断する独立した第三者機関が、こうした大規模なサイバーセキュリティの取り組みを担う基盤となる可能性も示されています。
これらの取り組みは、AIが単なるツールにとどまらず、社会全体のサイバーセキュリティ基盤に大きな影響を与えつつあることを示しています。
その中で本モデルは、サイバー攻撃に備えるための新しい取り組みを進めるうえで、重要な役割を担うモデルとして位置づけられています。
まとめ
Claude Mythos Previewとは、Anthropicが開発した大規模言語モデルで、コーディングやエージェント型タスク、サイバーセキュリティ領域で高い能力を示しているモデルです。
一方で、一般向けに自由に提供されているモデルではなく、Project Glasswingの一部として、主に防御的なサイバーセキュリティ用途に限定して提供されています。高い性能を持つモデルであるほど、提供先の管理や不正利用対策も重要になります。
Claude Mythos Previewは、AIモデルの性能向上がサイバーセキュリティ対策にどのような影響を与えるのかを考えるうえで、重要な事例といえます。
アイスマイリーでは、生成AIのサービス比較と企業一覧を無料配布しています。課題や目的に応じたサービスを比較検討できますので、ぜひこの機会にお問い合わせください。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- 生成AI
- ChatGPT
- Gemini
- Claude
- LLM
- AI研究開発
- 画像生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
- GPU
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI














FOLLOW US
SNSをフォローして、最新情報をチェックできます!
清水建設、AIロボットの研究開発を本格化。現場巡回や塗装作業で実…

SpaceXAI、最新モデル「Grok 4.5」を提供開始。コー…

Cloverse、アパレル特化型AI「Clovia」提供開始。撮…
NEC、Anthropic協業による「NEC AIインサイトレポ…

ビジネス職のAI活用調査を実施。AIエージェント化で生産性が上がったのは54%でチャット層の約3.8倍

AIOpsとは?IT運用の未来を変える仕組みと次世代ツールの選び方
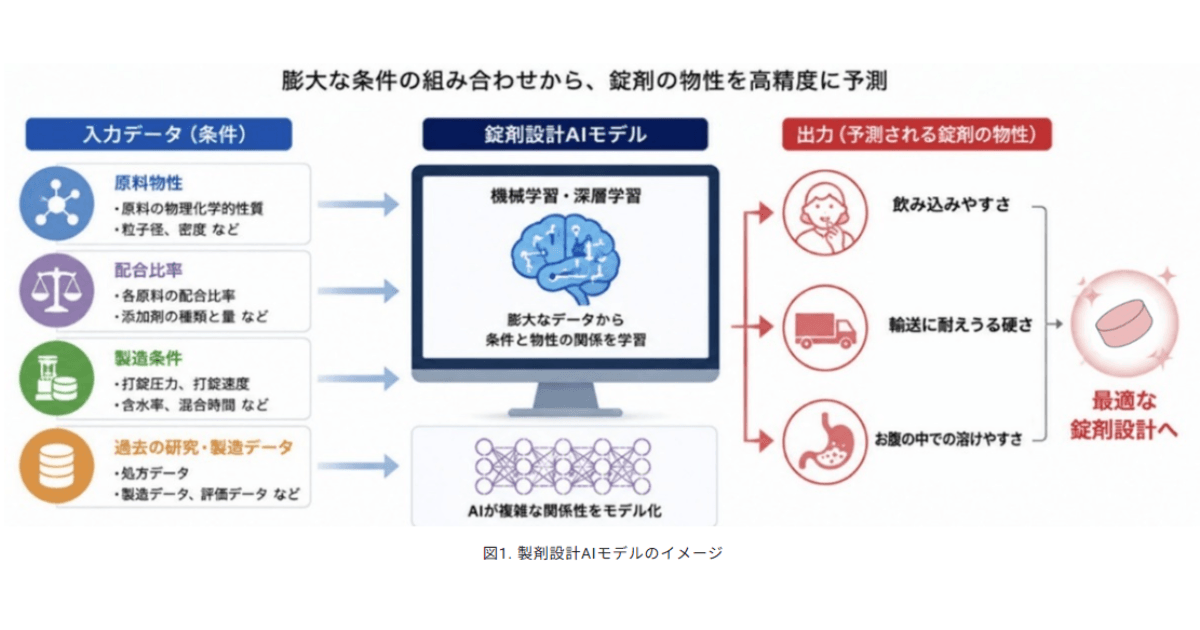
キリンとファンケル、サプリメント開発を支援する「錠剤設計AI」を共同開発

富士通、大規模言語モデルの大幅なコスト削減を実現するアーキテクチャ「PHOTON」開発。Transformerの最大475倍の出力トークン数を持つ

キッセイコムテック、ペーパーレス会議システムに生成AI活用の資料検索・要約機能を搭載。ANAホールディングスの経営会議で導入

ソフトバンクと安川電機、「AIデータセンターGPUクラウド」を活用し、柔軟物体ハンドリングシステムを実証
AI製品・ソリューションの掲載を
希望される企業様はこちら