

教師データとは?学習データとの違いや作り方をわかりやすく紹介
最終更新日:2026/01/19
 教師データとは?
教師データとは?
近年は多くの企業で人手不足が深刻な課題となっており、解決策としてAIが導入されることも多くなってきています。ただし、AIはさまざまなシーンで活用できる一方、あらかじめ用途を明確化しておかなければ、有効活用できないおそれもあるため注意が必要です。
また、機械学習では「教師データ」と呼ばれるデータの質や量が、AIの精度にも影響を与えます。今回は、AIの精度向上に欠かせない教師データの概要をご紹介したうえで、具体的な作り方や作成時のポイントも解説しますので、ぜひ参考にしてみてください。
教師データとはなにかをわかりやすく紹介

教師データは、英語で表記すると「teaching data」となり、その意味としてはAIが機械学習に利用するデータを指します。教師データの特徴は、「例題」と「「正解」がペアとなっていることで、機械学習においては「教師あり学習」と呼ばれるモデル構築に利用されます。
教師あり学習では、AIに「例題」と「正解」を繰り返し学習させることでパターンとルールを把握させ、学習終了段階では例題と同じカテゴリーの「新しいデータの正誤」も判定が可能です。
例えばリンゴの画像をAIに見せた際、ほかの果物と混同することなくAIが正しく判定を下して、「リンゴ」と回答できれば、教師あり学習は成功したといえます。
教師データと機械学習(教師あり学習)の関係性

機械学習は、データの種類や状況などに応じて「教師あり学習」「教師なし学習」「強化学習」という3つに分けることができます。教師データは「教師あり学習」において必要となるデータです。
教師あり学習は、「学習」「認識・予測」という2つのプロセスによって成り立っています。
まず、正解のデータを用いてルールやパターンを「学習」します。そのデータを用いて、新しくインプットされた「まだ正解がわからないデータ」に対する「認識・予測」を行うのです。
例えば、動物の画像から正しく種類を判別させたい場合、学習の段階ではあらかじめ「犬」「猫」「馬」などにラベリングした画像データをAIへ読み込ませます。認識・予測の段階では、ラベリングしたそれぞれの動物に対してAIが特徴量を割り出す解析作業を行います。そして、機械学習が最終段階になると、画像データを読み込ませた際に、被写体の動物が「犬」か「猫」であるかの判定を下せるようになるのです。
また、教師あり学習は以下のような身近なシーンでも利用されています。
- 受信メールがスパムメールか否かの自動判定
- 過去の実績に基づいた、新築の住宅販売価格の予測
- 選挙候補者の投票率の予測
- 住宅ローンにおける融資リスクの高低の判断
教師あり学習について興味がある方は、ぜひ以下の記事もご覧ください。
関連:AIの基礎「教師あり学習」とは?種類や具体例を紹介
AIの基礎「教師なし学習」とは?種類や応用例を紹介
強化学習とは?手法やAIロボットなどの活用事例を紹介
教師データと学習データの違い

学習データの中でも、正解を付与した状態のデータを「教師データ」と呼びます。両者は全く異なるデータというわけではなく、学習データの一種として教師データが属しているイメージです。
例を挙げると、教師あり学習では「例題」と「正解」を付与したデータが必要なため、正解として教師データが用いられます。一方、教師なし学習では、正解を与えていない学習データを使って機械学習を行います。
教師データの作り方
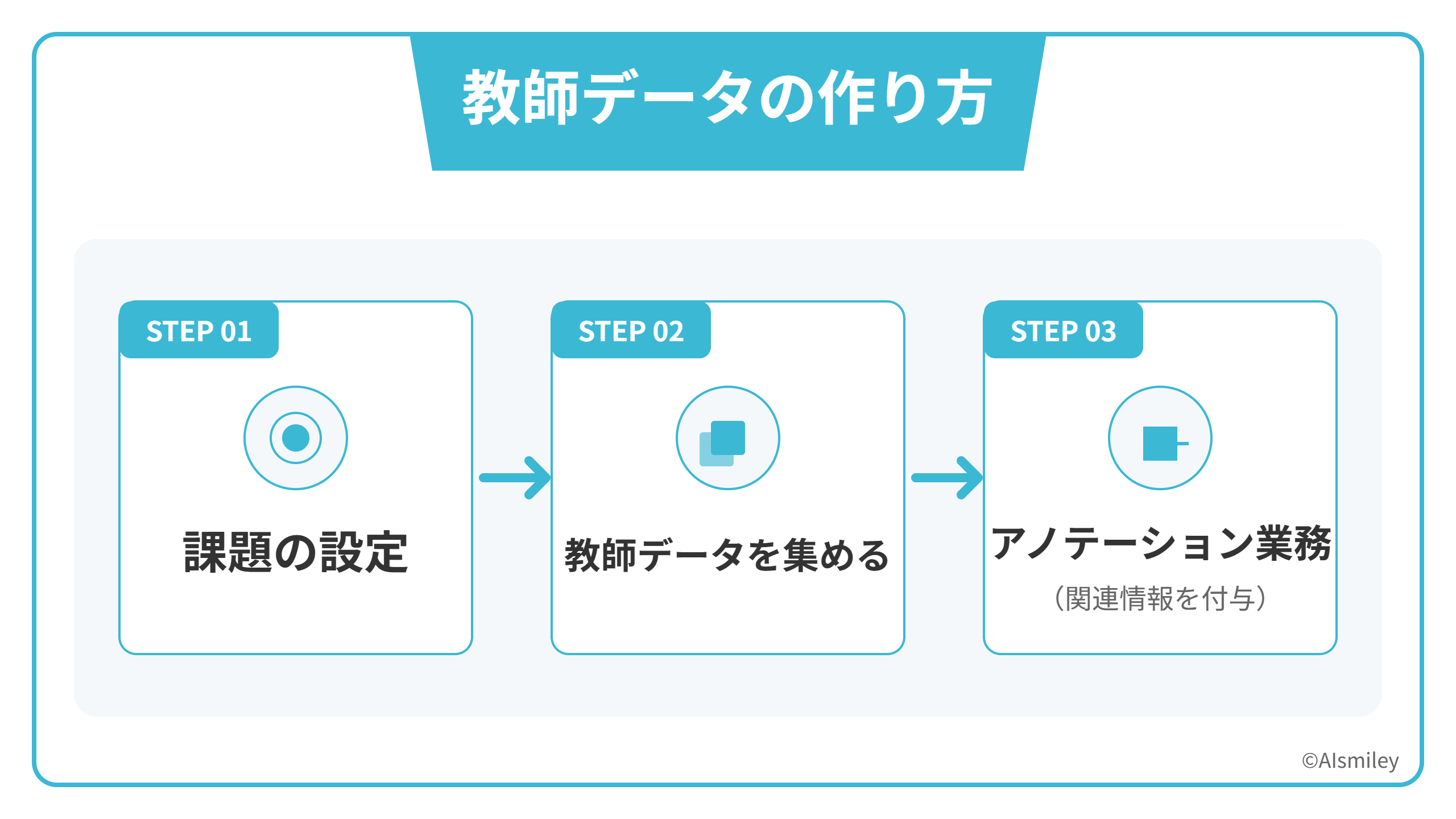
教師データを作るときの流れは、以下の通りです。
- 課題の設定
- 教師データを集める
- アノテーション(関連情報を付与)
教師データの作成は、大きく3つのステップに分かれています。さっそく以下の項目で、各ステップの内容を確認してみましょう。
課題の設定
教師データの課題を設定する際は、機械学習の導入でどのような課題を解決したいか、明確化させておくことが重要です。課題設定できる例としては、自社における事業の売上向上や、需要を予測した商品在庫の仕入れなどが挙げられます。
なお、教師データとして利用するには、「例題」と「正解」がペアでなければならないため、正解が存在しない分野の課題設定は避ける必要があります。
教師データを集める
次に、教師データを集める3つの方法について紹介します。
機械学習を導入するにあたって、どのようにデータを集めるべきか、ぜひ参考にしてください。
- 社内に蓄積されたデータを活用する
社内には顧客データや売り上げデータ、文書データ、機械のセンサデータなど、さまざまなデータが蓄積されています。それらを活用してAIに学習させることで、業務をより効率化できるでしょう。
例えばクレジットカードの審査の場合、過去の数千人分のデータと審査結果の正解ラベルを用意することによって、「クレジットカードを発行できるかどうか」の判別を自動化できます。
- 動画から画像データを収集する
画像データを必要とするAIを構築する場合には、動画から画像データを集める方法が有効です。
そもそも動画は、画像データをパラパラ漫画のように連続で表示させてアニメーションにしたものです。例えば、1秒間あたりの画像の数を表す「フレームレート」が30fps(1秒間あたりの画像数が30枚)の場合、30分の動画からは5万4,000枚の画像データが収集できます。
ちなみに、動画から画像データを収集することで機械学習に活かした事例のひとつに、「Googleの猫」と呼ばれる実験があります。これはGoogleが行った実験で、コンピューターにYouTube動画を1週間見せ続け、そのコンピューターに猫の写真を判別できるよう学習させたというものです。
一般的な機械学習の場合、事前に「猫」というラベル付けを行った画像で学習させますが、この実験では、コンピューター自身がYouTubeの映像から「猫がどのようなものなのか」を学んでいきました。
- データセットやコーパスを購入する
専門知識を持つ担当者がいない場合、基本的に教師データ作成の内製化は難しいでしょう。教師データの作成はAI開発における最大の関門ともいえ、多くの時間を費やさなくてはならないためです。教師データを自社で無理に作成しようとすると、大幅な時間ロスを生じる可能性もあります。
効率的に教師データを作成するために、データセットやコーパスを購入するのも一つの手です。
データセットとは、一定の形式に整えたデータの集合体のことで、機械学習においては大量の「標本データ」を指します。
コーパスとは、大量の文章を構造化したデータベースのことで、AIが自然言語処理のパターンを学ぶうえで辞書のような役割を果たします。
教師データを販売している企業からこれらのデータを購入する、もしくは教師データの作成を代行している企業へ制作を依頼することで、大幅に効率化できます。もちろん購入・依頼の費用は発生しますが、慣れない作業に膨大な時間を費やすデメリットと比較すれば、決して無駄なコストとはいえません。
AIsmileyでは、教師データ作成サービスの利用料金・初期費用・無料プラン・トライアルの有無などを比較検討できる資料を、無料でお配りしています。自社にとって最適なサービスの選定にご活用いただけますので、教師データ作成を検討される際はぜひお気軽にご利用ください。
アノテーション業務(関連情報を付与)
アノテーションとは、学習させるデータの一つひとつに対して、関連情報を付与する作業のことです。
画像や音声、テキストなどデータの形式は問わず、付帯情報が記載された「メタデータ」やタグを付けていきます。
なお、画像データをアノテーションする場合は、以下3つの手法を使えます。
- 物体検出:画像から検出した物体に対して、意味に応じたタグを付ける作業
- 領域抽出:画像から抽出した領域部分にタグを付ける作業
- 画像分類:画像の属性にタグを付ける作業
例えば、山の画像データをアノテーションする場合、作業者(アノテーター)が画像から「山の領域」を選択する作業を行わなければなりません。機械学習を導入する目的によってアノテーションすべきデータの量は異なりますが、多くの場合、手作業でのアノテーションは負担が大きいでしょう。
そのようなときには、アノテーション作業をサポートしてくれるツールの導入、もしくは専門業者への代行作業の依頼を検討したほうが良いでしょう。
アノテーションツールの選び方を知りたい方は、ぜひ以下の記事も参考にしてください。
関連:AIアノテーションツール20選を比較!タグ付け自動化ツールの選び方を紹介
機械学習にはどれくらいの教師データが必要なのか?

機械学習を行うためには教師データが必要であることがお分かりいただけたかと思いますが、具体的にどれくらいの教師データを用意する必要があるのでしょうか。
機械学習において必要となる教師データの数は、AIの用途によっても大きく変化するため、一概には言えないというのが実際のところです。そのため現状では、必要だと予測される教師データの数を人間が推測しなければなりません。
例えば、銀行の融資審査に活用するAIを構築する際は、データ量に応じて以下のような推測を立てられます。
◆銀行の融資の審査を行うためのAIを構築していく場合
- 過去の融資審査データを1万人分用意したケース:AIの精度を高めやすい
- 過去の融資審査データを100人分用意したケース:AIの精度を高められない
ただし、AI構築をスタートさせる段階で、必ずしも多くの教師データを用意する必要はありません。運用開始後にデータを収集して、機械学習へ活用する方法もあるためです。
教師データを作成するときのポイント
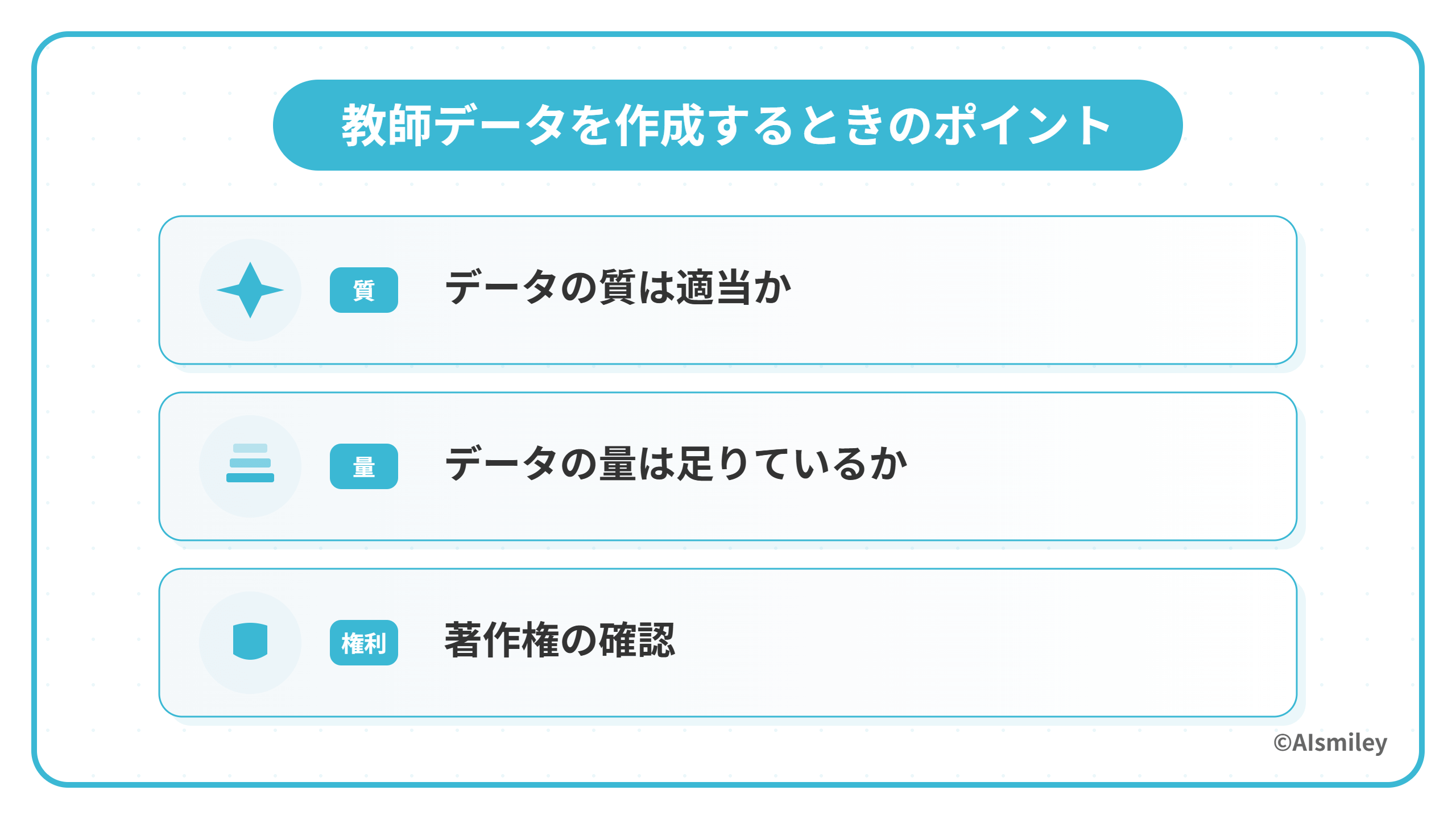
ここからは、教師データを作成するときに気をつけたい4つのポイントについて解説します。
データの質は適当か
AIの精度を向上させるには、まずデータの「質」に注意しなければなりません。というのも、教師データをもとに機械学習が進行するため、データの質が悪ければ学習精度の低下へつながってしまうためです。
基本的にAIの学習には多くの時間を要するため、質の悪いデータを使って機械学習を実行した場合、その学習時間がすべて無駄になるおそれもあります。
例えば、部品や製品の外観検査システムを構築する場合、教師データとして用いる画像が鮮明でないと、システムの精度に差が生まれやすくなります。また、顔認証システムを構築する場合、教師データとして欧米人の顔画像ばかりを用意すると、日本人に対する認証精度が高まりにくいでしょう。
機械学習における後戻り工程の時間を減らすためにも、正解となる教師データの質にはこだわる必要があるのです。
データの量は足りているか
AIの精度を高めるためには、データの量を増やすことも大切です。ただし、手持ちのデータをすべてモデル構築に用いると、学習プロセスで使ったデータへ過度に適合した「過学習」が発生するおそれがあります。
機械学習において過学習が起きると、既知のデータのみにフィットし過ぎるため、データ全体の傾向を掴めず、未知のデータに対する分析力が弱まります。過学習を避けるためには、手持ちのデータを「訓練データ」と「テストデータ」に分けることが重要です。なお、訓練データと学習データの分割方法にはいくつかの手法があります。
その中でも代表的な手法として挙げられるのが、ホールドアウト法です。
ホールドアウト法とは、データを「学習用データ」と「テストデータ」に分割して、モデルの精度を確かめていく手法のことをいいます。例えば、データ全体が100個とした場合、6対4の割合で分割し、学習用データ60個、テストデータ40個に分割します。
また、K-分割交差検証と呼ばれる手法も多く用いられます。Cross Validation(クロスバリデーション法)とも呼ばれるこの手法は、データ全体をK個に分割したうえで、そのうちのひとつをテストデータとし、残った K-1 個を訓練用データに分解していくというものです。
そして、テストデータと学習用データの入れ替えを行いながら繰り返し、すべてのケースがテスト事例となるまで検証を行っていきます。つまり、K 個に分割されたデータは、K 回の検証が行われることになるということです。
著作権の確認
教師データの作成を行うためには、大量の生データや生データをもとに生成した「学習用データセット」が必要です。その際、文章や画像、動画といった著作物(生データ)を利用するケースもあるでしょう。
著作権法では、著作権者の許可なく無断で著作物を利用(ダウンロードや改変等)することは認められていません。
ただし、AIの開発を目的とした場合は、著作権法第三十条の四により、一定限度で著作権者の許諾なく著作物を利用することができます。
第三十条の四 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りではない。
引用:著作権法 第三十条の四
プライバシーへの配慮とGDPR対応
教師データを集めるうえでは、プライバシーへの配慮も必要です。特に、画像データや動画データを扱う際には、本人が気付かぬうちにパーソナルデータを収集してしまうというプライバシー侵害のリスクもあるため、注意する必要があります。
総務省の資料によると、パーソナルデータは「個人情報に加え、個人情報との境界が曖昧なものを含む、個人と関係性が見出される広範囲の情報を指す」と定義されています。
引用:総務省「平成29年版情報通信白書」
例えば2017年には、札幌市がカメラ画像を使ったデータ取得の実証実験を実施していましたが、プライバシーの侵害や個人情報の流出を懸念する市民の声が広がったことで、実験を中止した事例がありました。実験の目的は「年代・性別等の属性データの取得」で、実施内容を掲示板で事前に告知するなど、対策も実施されていました。しかし、結果的には中止へ至ったことを考え合わせると、パーソナルデータ取得の難しさが露呈した事例といえるでしょう。
また、2018年5月にGDPR(一般データ保護規則)が施行されるなど、「データの主体である個人がデータ管理者に対して自身のパーソナルデータの訂正・削除・移動を求める権利」が保障され始めています。だからこそ、細心の注意を払いながら、教師データ作成を進めていくことが大切です。
必要に応じて、専門知識を持つ企業のサポートを受けるのも一つの手段といえるでしょう。
教師データの作成を代行するサービスも増加中
今回は、精度の高いAIを構築するうえで重要な役割を果たしている教師データについてご紹介しました。教師データの収集に難しさを感じられた方もいらっしゃるかもしれませんが、最近では教師データの作成を代行してくれるサービスなども増えています。より効率的にAIを構築していきたい場合には、こういったサービスの利用を検討してみても良いかもしれません。
もちろん、社内に蓄積されたデータを活用するのも有効な手段のひとつですが、蓄積されたデータは自社にとって極めて大切な財産です。データを取り扱う際は、情報漏洩などの事態を招かないように、十分な注意を払いましょう。
よくある質問
教師データとは何ですか?
教師データとはAIが機械学習に利用するデータのことです。
教師データと学習データの違いは何ですか?
学習データの中でも、正解を付与した状態のデータを「教師データ」と呼びます。両者は全く異なるデータというわけではなく、学習データの一種として教師データが属しているイメージです。
機械学習にはどれくらいの教師データが必要ですか?
機械学習において必要となる教師データの数は、AIの用途によっても大きく変化するため、一概には言えないというのが実際のところです。そのため現状では、必要だと予測される教師データの数を人間が推測しなければなりません。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- 生成AI
- ChatGPT
- Gemini
- Claude
- LLM
- AI研究開発
- 画像生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
- GPU
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI














FOLLOW US
SNSをフォローして、最新情報をチェックできます!

リコーとライズ・コンサルティング・グループ、AI実装・活用を一貫…
近畿大学病院など4者、リアルワールドデータとLLMを用いた共同研…
LINEヤフー、「LINE」新機能「Agent i in cha…
Sakana AI、「Sakana Chat」に翻訳機能を追加。…

アイスマイリー、 7/29(水)から3日間「イプロスAI 2026 夏」にブース出展。来場登録・実来場でAmazonギフト500円分プレゼント!

アイスマイリー、7/22(水)から3日間「AI World 2026 夏 東京」に出展 ブース予約でAmazonギフト1,500円分プレゼント!

アイスマイリー、7/8(水)から3日間「バックオフィス World 2026 夏 東京」に出展 ブース予約でAmazonギフト1,500円分プレゼント!

アイスマイリー、7/1(水)から3日間、第38回 ものづくり ワールド [東京]内、「製造業DX展」にブース出展

Anthropic、一般向けMythos級AIモデル「Claude Fable 5」、サイバー防衛向け「Claude Mythos 5」発表

アイスマイリー、6/24(水)から3日間 マーケティングWeek -夏 2026-内、「マーケティング戦略立案 EXPO」にブース出展
AI製品・ソリューションの掲載を
希望される企業様はこちら