

コンテキストエンジニアリングとは?手法・プロンプトエンジニアリングとの違い・業種別の活用を解説
最終更新日:2026/07/01

生成AIを業務で使い始めた方の多くが直面する、「同じような指示を出しているのに、回答の質が安定しない」という壁。その原因の多くは、指示文そのものではなく、AIに渡している情報全体の設計にあります。
このように、プロンプト(指示文)だけでなく、AIに与える情報環境そのものを整理し、AIのポテンシャルを最大限に引き出す手法が「コンテキストエンジニアリング」です。AIエージェントや社内向け生成AIの活用が広がる今、プロンプトエンジニアリングの次に必須となるスキルとして注目を集めています。
この記事では、コンテキストエンジニアリングの定義から、プロンプトエンジニアリングとの違い、代表的な4つの手法、業種・職種ごとの具体的な活用イメージまでを網羅。さらに、実践時に陥りやすい失敗と対策についても、専門用語を使わずわかりやすく解説します。
コンテキストエンジニアリングとは
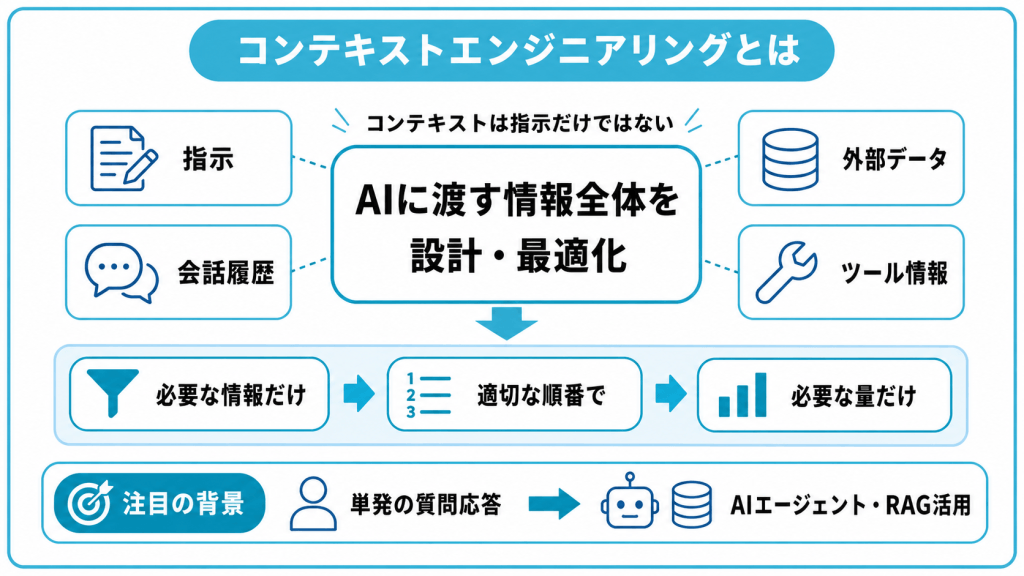
コンテキストエンジニアリングとは、AIに渡す情報全体を緻密に設計し、AIが最も働きやすい状態を作る技術のことです。ここでいうコンテキスト(文脈)とは、LLMが回答を生成する際に参照する『指示・会話履歴・外部データ・ツール情報』などの前提情報全体を指します。
具体的には、ユーザーが入力した指示だけでなく、過去の会話履歴・外部データベースから取得した資料・利用できるツールの情報などが含まれます。これらをどう組み合わせ、どの順番で、どれだけ渡すかを設計するのがコンテキストエンジニアリングです。
近年はこの考え方が体系立てて語られるようになり、生成AIを安定して活用するための前提として位置づけられています。
コンテキストエンジニアリングの定義
コンテキストエンジニアリングの本質は、「AIに与える情報を取捨選択して制御すること」にあります。目的に応じて必要な情報だけを適切な形で渡す発想です。
この技術が成り立つ前提として、LLM(大規模言語モデル)には、一度に扱える情報量の上限が存在します。この上限はコンテキストウィンドウと呼ばれ、AIにとっての作業机や短期記憶にたとえられます。机の上に載せられる資料の量には限りがあり、何を載せるかによって作業の質が変わります。
多くのLLMは、文章をトークンという単位に分割して処理します。入力した指示も会話履歴も外部資料も、すべてトークンとしてこの机の上を占有します。机の広さは決まっているため、関係が薄い情報まで載せてしまうと、本当に必要な情報が埋もれてしまいます。コンテキストエンジニアリングは、この限られた机の上を、目的に合わせて意図的に使い分ける技術なのです。
なぜ今コンテキストエンジニアリングが注目されているのか
コンテキストエンジニアリングが注目される大きな理由の1つは、生成AIの使われ方が「単発の質問応答」から「複数の作業を続けて任せる利用」へと変わってきたためです。利用の形が変わったことで、指示文の工夫だけでは対応しきれない場面が増えました。
ChatGPTのような対話型生成AIが一般に広がり始めた当初は、人間が質問してAIが答える一往復のやり取りが中心でした。この段階では、指示文を工夫するだけで出力の質を十分に高められました。
しかし、AIエージェント(人間の指示を受けて、自ら手順を考え複数の作業を進めるAI)や、外部データを参照するRAG(検索拡張生成。外部データベースや文書群から関連情報を検索し、回答に反映する仕組み)が普及すると、状況が変わります。
複数のターンにわたって作業を続けると、会話履歴やツールの実行結果が次々に積み上がり、机の上はすぐにあふれてしまいます。何を残して何を捨て、何を新たに渡すかという判断が、出力の品質を左右するようになったのです。
Anthropicの公式記事では、コンテキストエンジニアリングはプロンプトエンジニアリングの自然な発展形であり、AIを安定して動かすうえで欠かせない考え方であると発表しています。
プロンプトエンジニアリングとの違いと位置づけ
コンテキストエンジニアリングを理解するうえで最もつまずきやすいのが、プロンプトエンジニアリングとの違いです。両者は混同されがちですが、設計の対象とする範囲が根本的に異なります。
プロンプトエンジニアリングが「どう指示するか」に焦点を当てるのに対し、コンテキストエンジニアリングは「どんな情報を渡すか」という、より広い範囲を扱います。さらに近年は、AIエージェントを安定して動かすために、モデルの周辺環境まで含めて考える議論も出てきました。
設計対象と目的の違い
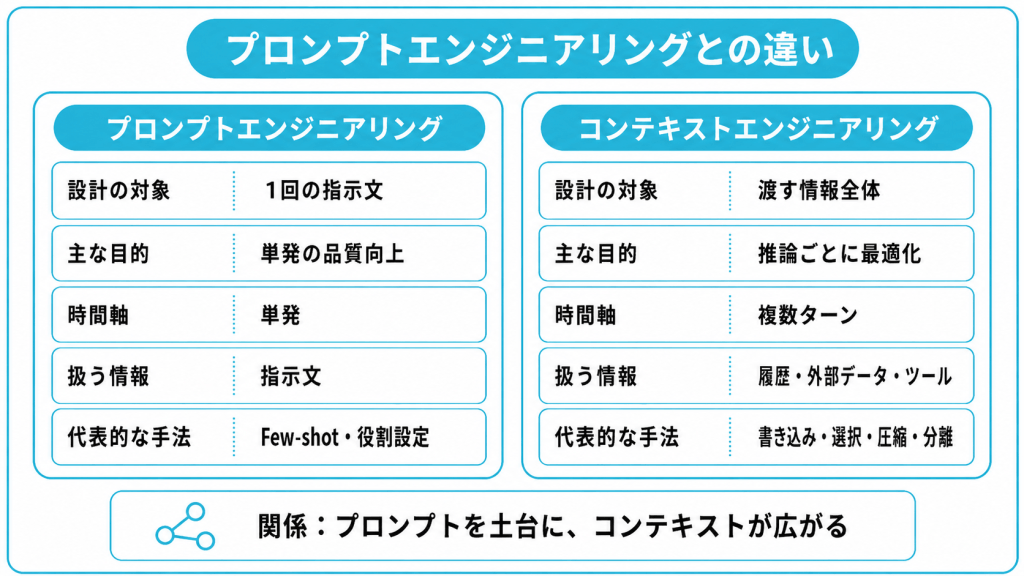
両者の違いは、設計の対象とする範囲の広さに集約されます。プロンプトエンジニアリングは1回の指示文を磨く技術であり、コンテキストエンジニアリングは渡す情報全体を設計する技術です。
| 観点 | プロンプトエンジニアリング | コンテキストエンジニアリング |
|---|---|---|
| 設計の対象 | 1回の指示文 | 渡す情報全体 |
| 主な目的 | 単発の出力品質を高める | 推論ごとに情報を最適化する |
| 時間軸 | 単発のやり取り | 複数ターンの連続作業 |
| 扱う情報 | 指示文のみ | 履歴・外部データ・ツール情報など |
| 代表的な手法 | Few-shot・役割設定 | 書き込み・選択・圧縮・分離 |
プロンプトエンジニアリングは、LLMへの指示文を工夫して出力を改善する手法です。Few-shot(いくつかの例を示して望ましい出力の形式を学ばせる手法)や役割の設定などが代表例で、単発の質問応答では高い効果を発揮します。一方で、設計の対象が「その場の指示文」に限られるため、AIが複数の作業を続けたり、外部データを動的に参照したりする場面には対応しきれません。
コンテキストエンジニアリングは、指示文だけでなく、会話履歴・外部データ・ツール情報・メモリまでを含めた情報全体を設計の対象とします。毎回結果が変わるという再現性の低さは、指示文ではなく渡す情報の設計で解決できる場合が多いです。両者は対立するものではなく、プロンプトエンジニアリングを土台としてコンテキストエンジニアリングが積み上がる関係にあるといえます。
指示文から情報設計へ
生成AIの設計に関する考え方は、「指示文を書くこと」から「情報全体を管理すること」へと広がっています。この流れを押さえておくと、コンテキストエンジニアリングが全体のどこに位置するのかが見えてきます。
最初の段階がプロンプトエンジニアリングで、1回の推論における指示の書き方を扱います。次の段階がコンテキストエンジニアリングで、その推論にどの情報を入れるかを制御します。 さらにAIエージェントの分野では、モデルの周囲にあるツール・実行環境・メモリ・検証手順などを含めて設計する議論も見られます。
こうした周辺環境は、AIエージェントが安定して作業を進めるための仕組みにあたります。たとえば、どのツールを使えるようにするか、ツールの説明をどう書くか、途中結果をどこに保存するか、失敗したときにどう検証するかといった設計が含まれます。コンテキストエンジニアリングは、このうち「推論時にAIへ渡す情報」を扱う重要な領域です。
つまり、プロンプトエンジニアリングだけでは、複数回の推論やツール利用を含む作業全体を安定させるには限界があります。そのため、指示文だけでなく、参照情報・履歴・ツール・メモリまでを含めて設計する考え方が必要になっています。
コンテキストを構成する要素
コンテキストエンジニアリングを身につけるには、まず「コンテキストとして何を渡しているのか」を把握することが出発点です。構成要素に分けると、どこを設計すべきかが見えてきます。
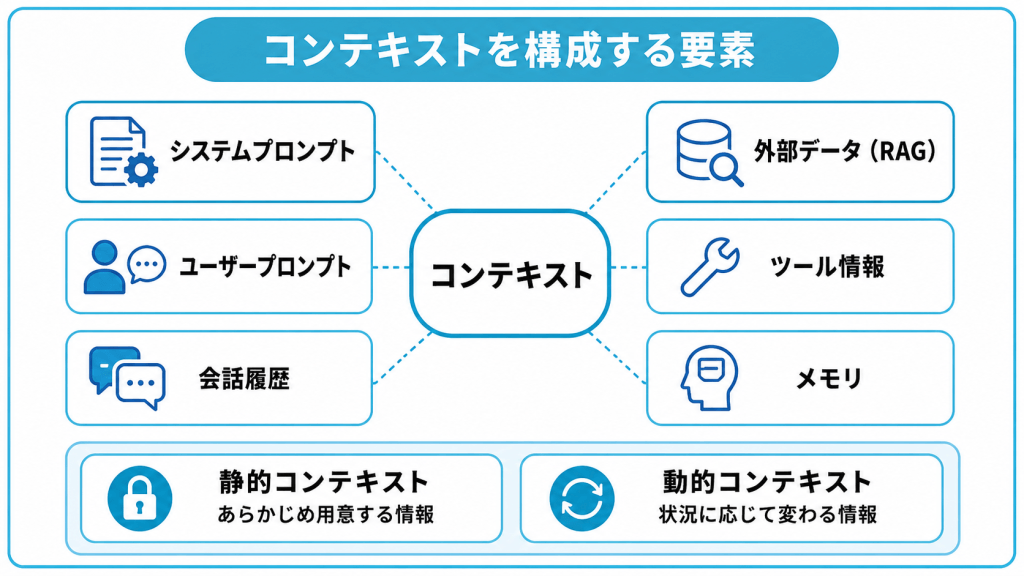
AIに渡されるコンテキストは、次の要素で構成されます。
- システムプロンプト
- ユーザープロンプト
- 会話履歴
- 外部データ(RAGによる取得情報)
- ツールの情報
- メモリ(記憶)
システムプロンプトは、AIの役割・前提条件・守るべきルールを設定する指示です。ユーザープロンプトは、その場で入力する具体的な質問や依頼を指します。会話履歴には、それまでのやり取りが含まれ、外部データはRAGなどで社内資料やデータベースから取得する情報を表します。
また、ツールの情報はAIが使える機能やAPIの説明であり、メモリは過去のやり取りから得た重要な情報を保存する仕組みです。
これらの要素は、変化のしかたで2つに分けられます。1つは静的コンテキストで、設計文書やスタイルガイドのように、あらかじめ用意する不変の情報です。もう1つは動的コンテキストで、ログや実行結果のように状況に応じて変化する情報です。どの要素を固定し、どれを差し替えるかを設計することが、具体的な作業になります。
コンテキストエンジニアリングの主要な手法
コンテキストエンジニアリングには、代表的な4つの手法があり、いずれもAIエージェント開発の現場でも使われている考え方です。
これらは、限られたコンテキストウィンドウを有効活用するためのアプローチです。全体像は以下の通りです。
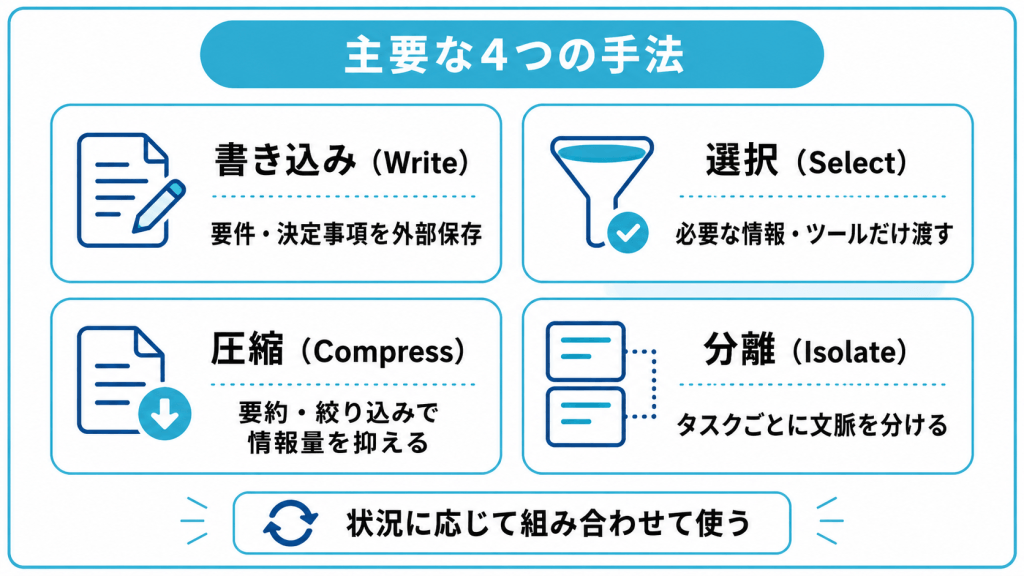
| 手法 | 英語表記 | 内容 |
|---|---|---|
| 書き込み | Write | 情報を外部メモリに保存する |
| 選択 | Select | 必要な情報やツールだけを渡す |
| 圧縮 | Compress | 要約や絞り込みで情報量を減らす |
| 分離 | Isolate | タスクごとに文脈を分けて扱う |
これらは単独で使うものではなく、状況に応じて組み合わせて使います。それぞれがどのような課題を解決するのかを理解すると、自社の場面でどれを採用すべきかが判断しやすくなります。
書き込み(Write)
書き込みは、コンテキストウィンドウの外側に情報を保存しておく手法です。会話が長くなって過去の情報が机から溢れても、外部に記録しておけば後から読み返せる、という発想に基づいています。
この手法が必要になる背景には、コンテキストウィンドウの容量が有限であるという制約があります。長い作業を続けると、最初に伝えた要件や決定事項が会話の後半で失われ、AIがルールを忘れたかのような挙動を示すことがあります。これを防ぐために、要件定義・守るべきルール・これまでの決定事項を外部のファイルやナレッジベースに書き出しておきます。
たとえばAIにプロジェクトの前提を渡す際、毎回会話のなかで説明し直すのではなく、専用の文書にまとめて保存しておく方法があります。AIはその文書を参照することで、会話履歴から消えてしまった情報でも常に把握できます。ありがちなのは、すべてを会話のなかだけで伝えようとして、後半で前提が崩れてしまうことです。
選択(Select)
選択は、その時々のタスクに本当に必要な情報やツールだけを選んで渡す手法です。手元にあるすべての情報を渡すのではなく、関連するものだけを取り出して机に載せる、という発想です。
選択が重要になるのは、情報やツールの選択肢が増えるほど、AIが「今どれを使うべきか」を判断しにくくなるためです。利用できるツールの説明文も、それ自体がコンテキストウィンドウを占有します。ツールが多すぎると、AIが必要な情報を取り違えたり、不要なツールを選んだりする原因になります。
ここで役立つのが、RAGのような仕組みです。RAGは、質問に関連する情報だけを外部データベースや文書群から検索して渡すため、選択の手法の1つとして位置づけられます。また、データソースやツールには、わかりやすく一貫した名前を付けることが大切です。AIは名前や説明文も手がかりにするため、命名が曖昧だと適切な選択をしにくくなります。
圧縮(Compress)
圧縮は、要約や絞り込みによって、渡す情報の量そのものを減らす手法です。情報の中身を保ちながら、占有するトークンを小さくすることを目的とします。
圧縮が必要になるのは、長時間の作業によって会話履歴や実行結果が積み上がり、コンテキストウィンドウが埋まってしまう場面です。一部の生成AIツールやエージェント環境では、長い会話や実行履歴を要約・圧縮する仕組みが用意されています。こうした機能により、重要な情報を残しながら、机の上を継続的に片付けられます。
圧縮には大きく2つの方向があります。1つは、長い会話や作業履歴を要約して短くまとめる方法です。もう1つは、古くなった情報や不要な情報を取り除く方法で、古いメッセージから順に外していく仕組みなどが該当します。
どちらも、限られた容量のなかで必要な情報を保ち続けるための工夫です。なお、こうした自動圧縮機能の仕様は変化が速いため、利用するツールの最新の挙動は公式情報で確認することをおすすめします。
分離(Isolate)
分離は、タスクごとにコンテキストを分けて管理し、それぞれが必要な情報だけを扱えるようにする手法です。1つの机にすべてを載せるのではなく、作業ごとに専用の机を用意する、というイメージです。
分離が有効なのは、1つのAIにすべての作業を任せると負担が大きくなり、無関係な情報に影響されて精度が下がる場合があるためです。そこで、複雑なタスクを細かく分け、それぞれを専門のサブエージェントに割り当てます。各サブエージェントは自分の担当に必要な情報だけを扱い、まとめ役のエージェントが各担当から要約された結果だけを受け取ります。
この方法により、一つ一つのAIが扱う情報が絞られ、それぞれが集中して作業を進められます。複数のAIが連携して動く場合は、担当間で情報の食い違いが起きないよう、共通のデータベースに情報を保存したり、要約した情報を共有したりする工夫もあわせて行われます。
業種・職種別の活用イメージ
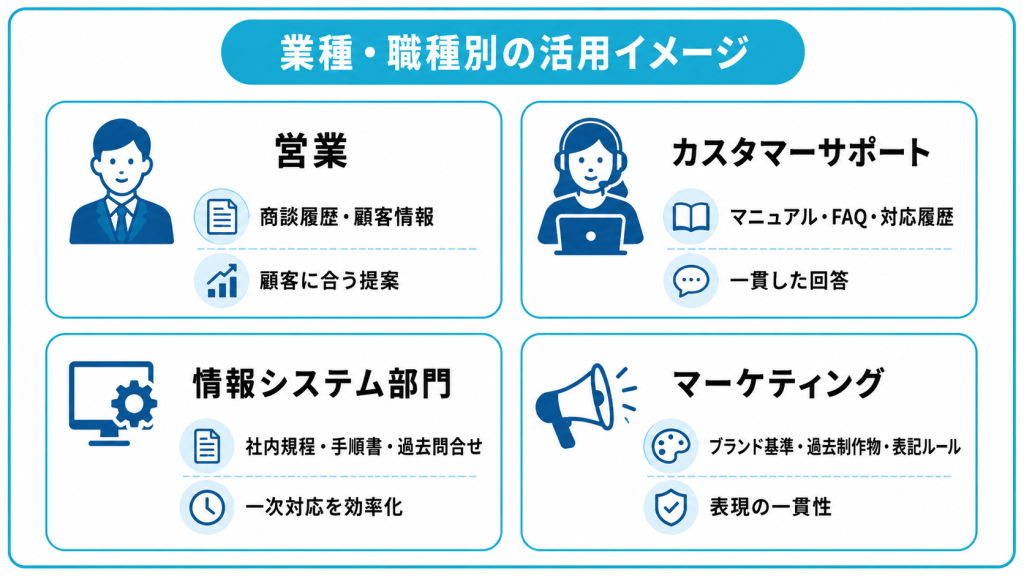
コンテキストエンジニアリングは抽象的に語られがちですが、自分の仕事に当てはめて考えると具体的に捉えやすくなります。「自社のこの業務なら、AIにどんな情報を渡すべきか」という視点で読み進めると、理解が深まります。
ここでは、代表的な4つの職種を取り上げ、それぞれどんなコンテキストを設計すると活用しやすいかを解説します。
営業での活用
営業では、顧客ごとの状況をコンテキストとして渡すことで、AIの提案精度を高められます。汎用的な営業トークではなく、目の前の顧客に合わせた内容を生成できるようになります。
営業活動では同じ商品でも顧客によって訴求すべきポイントが異なります。AIに一般的な指示だけを出すと、無難な提案文しか返ってきません。そこで、過去の商談履歴・提案資料・顧客情報といった情報をコンテキストとして渡します。これらは静的な情報と動的な情報が混在するため、何を固定し、何を最新の状態に差し替えるかを設計することが重要です。
たとえば、特定の顧客への次回提案を作成する際、顧客とのこれまでのやり取りや関心領域を渡せば、AIは文脈に沿った提案を生成できます。「毎回ゼロから状況を説明し直すのが手間だ」という負担も、必要な情報を渡す仕組みを整えることで軽くなります。
カスタマーサポートでの活用
カスタマーサポートでは、製品知識と対応履歴をコンテキストとして渡すことで、一貫した回答を実現できます。担当者によって回答がばらつくという課題に対して効果を発揮します。
問い合わせ対応では、回答の正確性と一貫性が求められます。AIに製品の前提知識がないまま回答させると、誤った案内や場当たり的な返答が生じかねません。これを防ぐために、製品マニュアル・よくある質問・過去の問い合わせ履歴をコンテキストとして渡します。これらは変わりにくい静的な情報が中心となるため、外部メモリに書き込んで保存しておく手法と相性が良いといえます。
たとえば、ある製品に関する問い合わせが来たとき、その製品のマニュアルと過去の類似対応を渡せば、AIは過去の対応と矛盾しない回答を生成できます。問い合わせの優先度を判定させたり、適切な担当部署を振り分けさせたりする場面でも、判断基準をコンテキストとして渡しておくことで精度が上がります。
情報システム部門・社内ヘルプデスクでの活用
情報システム部門では社内規程やナレッジベースをコンテキストとして渡すことで、社内向けの問い合わせ対応を効率化できます。社員からの定型的な質問に対して、AIによる一次対応が可能になります。
社内ヘルプデスクには、申請手続きやシステムの使い方など、同じような質問が繰り返し寄せられます。担当者がその都度対応していると負担が大きくなります。そこで、社内規程・各種マニュアル・過去の問い合わせ記録をコンテキストとして渡し、AIに一次対応を任せます。社内情報は更新されることもあるため、最新の文書を参照させる仕組みをあわせて設計することが大切です。
たとえば、経費精算の方法を尋ねる質問に対して、最新の規程文書を参照させれば、AIは現行ルールに沿った回答を返せます。ここで注意したいのは、社内情報には機密性の高いものが含まれる点です。誰がどの情報にアクセスできるかという範囲を踏まえてコンテキストを設計しないと、本来見せるべきでない情報が回答に含まれるおそれがあります。
マーケティングでの活用
マーケティングでは、ブランドの基準や過去の制作物をコンテキストとして渡すことで表現の一貫性を保てます。複数の担当者が制作にかかわっても、トーンが揃った成果物を生み出せます。
コンテンツ制作では、企業ごとに守るべき表現のルールがあります。AIに何も渡さずに文章を生成させると、ブランドの雰囲気から外れた表現が混ざりがちです。そこで、ブランドガイドライン・過去に制作した記事や広告・用語の表記ルールをコンテキストとして渡します。これらは変わりにくい静的な情報のため、文書にまとめて常に参照させる手法が向いています。
たとえば、新しい記事を作成する際、自社のトーンや許容される表現をまとめた文書を渡せば、AIはその基準に沿った文章を生成します。「担当者ごとに文章のテイストが揃わない」という課題も、共通の基準をコンテキストとして固定することで解消に近づきます。
コンテキストエンジニアリングで陥りやすい失敗と対策
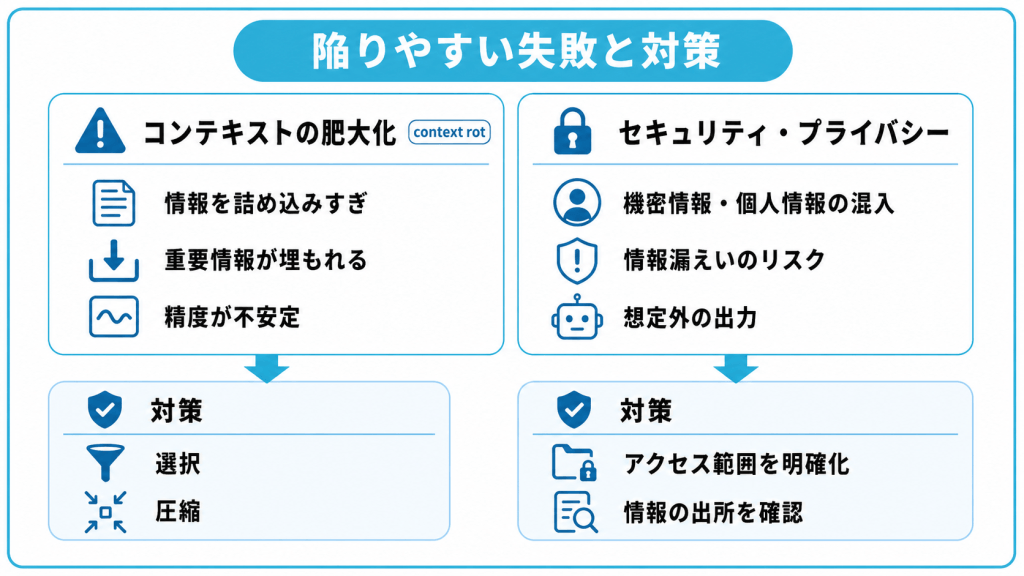
コンテキストエンジニアリングを実践する際、多くの人が「情報は多く渡すほど良い」と考えがちです。しかし、これは典型的な誤解であり、かえって精度を下げる原因になります。
ここでは、特につまずきやすい2つの失敗を取り上げ、それぞれの背景と対策を解説します。あらかじめ知っておくことで、回避しやすくなります。
コンテキストの肥大化と劣化(context rot)
コンテキストは、多く渡せば良いというものではありません。情報を詰め込みすぎると、かえってAIの出力精度が下がる現象が起きます。これはcontext rot(コンテキストの劣化)として論じられており、Chromaが2025年7月に公開した調査でも、入力長が増えるほどモデル性能が不安定になる傾向が示されています。
context rotが起きる理由は、AIにも人間と同じく注意力の限界があるためです。渡される情報が多いほど、AIは何が重要かを見分けにくくなり、肝心な指示を見落としたり、矛盾した回答を返したりします。
また、長い入力では、関連情報が冒頭や末尾にある場合に比べ、中央付近にある場合に性能が下がる「Lost in the Middle」の問題も報告されています。Chromaが18種類の主要なモデルを検証した調査では、入力長が増えるほど性能が一様ではなくなり、上限に達する前から不安定化する場合があることが示されました。
対策の中心になるのが、すでに解説した圧縮と選択の手法です。要約で情報量を抑え、関連する情報だけを選んで渡せば、劣化を防ぎやすくなります。ありがちなのは、念のためにと多くの資料をまとめて渡してしまうことです。「とりあえず全部渡す」のではなく、「この作業に本当に必要なものは何か」を見極める姿勢が、安定した出力につながります。
セキュリティとプライバシー上の注意点
コンテキストエンジニアリングには、セキュリティ・プライバシーの観点からの注意も欠かせません。渡す情報の中身によっては、情報漏えいや想定外の出力を招くおそれがあります。
注意が必要な理由は、コンテキストとして渡す情報に、個人情報や機密情報が含まれる場合があるためです。個人の好みや行動履歴はAIの精度を高める一方で、扱いを誤るとプライバシーの侵害につながります。
また、コンテキストに悪意のある情報が紛れ込むと、AIが利用者の意図しない回答を生成するおそれもあります。コンテキストの候補となる情報は量が多いため、不正な情報を検証する範囲が広がり、対策が難しくなる側面があります。
対策としては、どの情報を誰に渡してよいかというアクセス範囲を明確にし、機密性の高い情報の扱いに方針を定めておくことが挙げられます。外部から取得する情報については、信頼できる出所かどうかを確認する仕組みも求められます。利便性と安全性は両立させるべき要素であり、コンテキストを設計する段階からセキュリティを組み込んでおくことが不可欠です。
RAG・AIエージェント・メモリとの関係と始め方
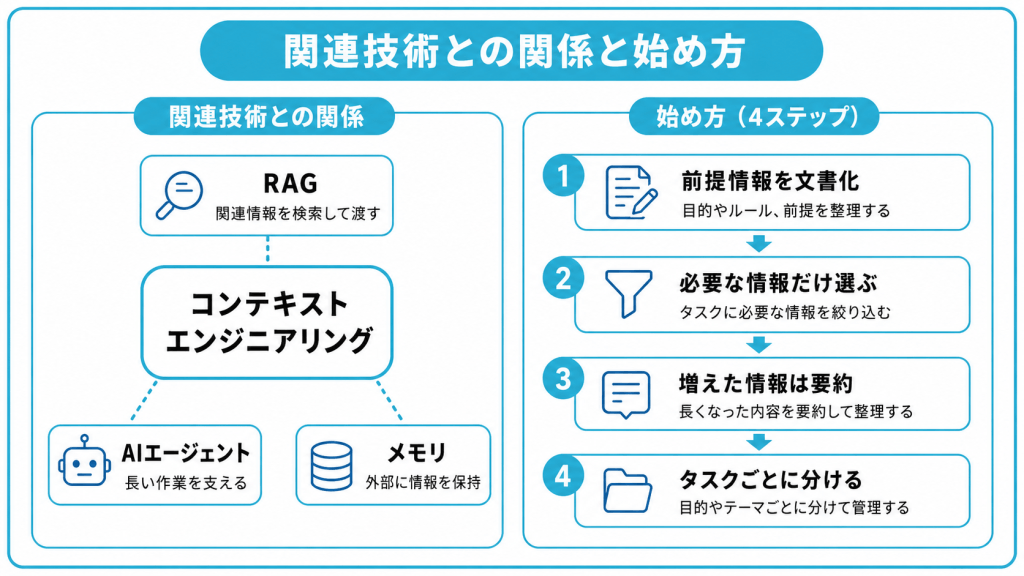
コンテキストエンジニアリングを学ぶと、RAG・AIエージェント・メモリといった言葉との関係が気になってきます。これらは別々の技術ではなく、コンテキストエンジニアリングという大きな枠組みのなかで結びついています。
ここでは、関連する概念との関係を解説したうえで、最初にどこから手を付ければよいかを示します。全体像をつかんでから始めると、迷いが少なくなります。
関連する概念との位置づけ
RAG・AIエージェント・メモリは、いずれもコンテキストエンジニアリングを構成する要素として理解できます。それぞれが、コンテキストを管理するための役割を担っています。
RAGは、外部データベースやドキュメント群から関連情報を検索・取得し、回答生成時のコンテキストとして渡す仕組みです。これは、必要な情報を選んで渡す「選択」の手法に含まれます。AIエージェントは、複数の作業を自律的に進める存在であり、その動作を支えているのがコンテキストの管理です。
エージェントが長い作業を続けられるのは、書き込み・選択・圧縮・分離といった手法でコンテキストが維持されているためです。メモリは、コンテキストウィンドウという短期記憶に対して、外部に情報を保存しておく長期記憶にあたります。
これらを別々の流行技術として捉えるのではなく、「AIに渡す情報をどう管理するか」という共通の課題に対する、それぞれの答えとして理解すると自然に結びつきます。コンテキストエンジニアリングは、これらをつなぐ全体の設計思想だといえます。
コンテキストエンジニアリングの始め方
最初の一歩としておすすめなのは、いきなり高度な仕組みを作ることではなく、渡す情報を見直すことです。手元の生成AIに渡している情報を点検するだけでも、出力は変わります。
進め方の目安は次のとおりです。
- 渡す前提情報を文書にまとめる
- 必要な情報だけを選んで渡す
- 増えすぎた情報は要約して減らす
- タスクごとに文脈を分ける
最初に、毎回口頭で説明し直している前提条件を、文書としてまとめておきます。これが「書き込み」の手法にあたり、AIへ安定して前提を伝える基盤になります。次に、その文書のなかから目の前の作業に関係する部分だけを選んで渡します。情報をすべて渡すのではなく、「選ぶ」という意識を持つことが選択の手法です。
作業が長くなって情報が増えてきたら、過去のやり取りを要約して量を減らします。これが圧縮にあたります。さらに複雑な作業では、1つのAIにまとめて任せるのではなく、作業を分けてそれぞれに必要な情報だけを渡します。これが分離です。難しい技術から始める必要はなく、こうした手順を1つずつ取り入れていくことで、コンテキストエンジニアリングは現場に根づいていきます。
まとめ
ここまで解説してきた通り、コンテキストエンジニアリングとは、単なる指示出しを超えて「AIを優秀なアシスタントとして育て上げるための情報管理術」と言えます。指示文を磨くプロンプトエンジニアリングの次の段階として位置づけられ、AIエージェントの分野では、ツール・実行環境・メモリなどを含む周辺環境を設計する考え方も議論されています。
中心となるのは、書き込み・選択・圧縮・分離という4つの手法です。これらを組み合わせ、限られたコンテキストウィンドウに必要な情報だけを渡すことで、出力の品質と一貫性が高まります。一方で、情報を詰め込みすぎるとcontext rotによって精度が下がるおそれがあるため、量よりも中身を見極める姿勢が求められます。
生成AIを活用したAIエージェントや社内向けの仕組みが広がるなかで、コンテキストをどう設計するかは、今後さらに重要になっていくと考えられます。自社の業務に合った生成AIツールやサービスを選び、安定して活用していくうえでも、どんな情報をどう渡すかという設計の視点が出発点になります。まずは身近な業務で、AIに渡している情報を見直すところから始めてみてください。
アイスマイリーでは、生成AIのサービス比較と企業一覧を無料配布しています。課題や目的に応じたサービスを比較検討できますので、ぜひこの機会にお問い合わせください。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
ChatGPT連携サービス

チャットボット

AI-OCR

生成AI
ChatGPT連携サービス
チャットボット
AI-OCR








FOLLOW US
SNSをフォローして、最新情報をチェックできます!

Sakana AI、マルチエージェント基盤「Sakana Fug…
Microsoft、「Copilot Cowork」一般提供を開…

NECとJR東日本、「みどりの窓口AI対応サービス」の実現に向け…

2026年上半期トレンドワードランキングをPR TIMESが公開…

Claude Sonnet 5とは?性能・料金・Sonnet 4.6との違いを徹底解説

GPT-5.6とは?進化点や活用方法・従来のモデルとの違いを徹底解説

Google Workspace Studioで実現する、AI時代の業務ルーティン──AIが裏で勝手に働き出す「イベント駆動型」の自動化

NTT、LVLMの推論根拠を説明できるマルチモーダルXAI技術を確立。追加学習コストなしで運用可能
買物での生成AI利用調査結果を発表。生成AIの回答信頼度はレビューを上回る51.7%

PKSHA InfinityのAI議事録作成ツール「YOMEL」、福井県に全庁導入。高精度な文字起こしと話者分離
AI製品・ソリューションの掲載を
希望される企業様はこちら