

【2026年最新】コンテキストウィンドウとは?主要LLM比較と「記憶の罠」を防ぐ使いこなし術
最終更新日:2026/05/29

生成AIを使用している時に、
「長い資料をAIに読み込ませると、途中から指示を無視し始めてしまう」
「会話が長くなると最初の前提をAIが忘れてしまう」
といった経験はないでしょうか。こうした課題は、入力した情報量がAIの「短期記憶」の上限に近づいているサインです。この上限を決める要素こそが、本記事で解説する「コンテキストウィンドウ」です。
数値が大きいほど一度に多くの文書をインプットできますが、実は「単に上限が大きければ良い」というわけではありません。モデルの長文処理性能やプロンプトの構成、さらには2026年最新モデルで主流となった「料金や処理速度の落とし穴」によっても、実際の使い勝手は大きく変わります。
「結局、どのAIならこの分厚いマニュアルを丸ごと読み込めるのか?」
そんな疑問に答えます。
本記事では、GPT-5.5やClaude Opus 4.7といった2026年最新モデルの徹底比較に加え、100万トークンの広大な空間を「無駄にせず、コストを抑えて賢く使い切る」ための実践的テクニックをプロの視点で解説します。
コンテキストウィンドウとは?AIの「短期記憶」を決める要素
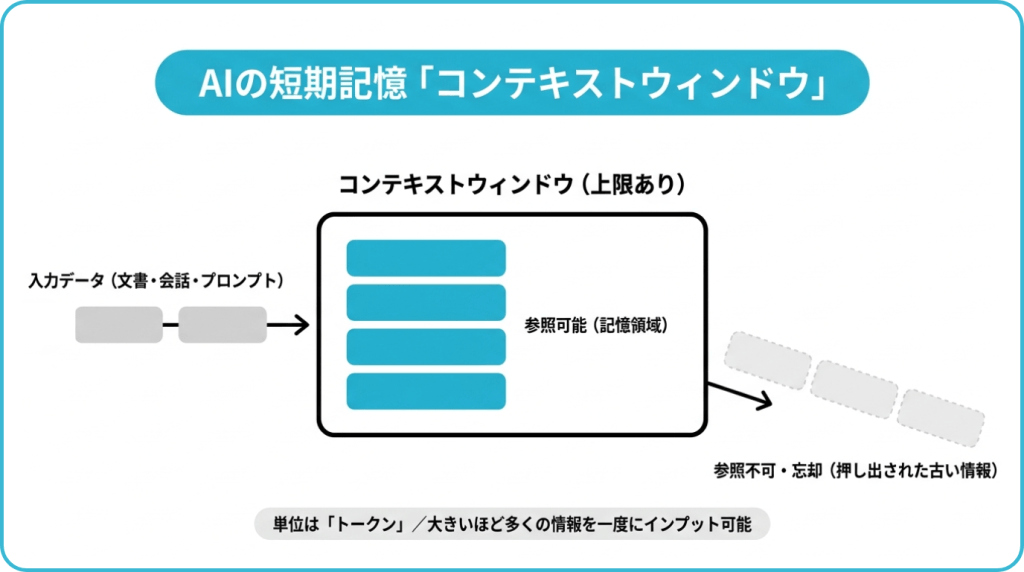
「コンテキストウィンドウ」とはLLM(大規模言語モデル)が一度の応答生成時に参照できる情報量の上限を指します。
単位は「トークン」といい、この数値が大きいほど1回のやり取りで多くの文書や会話履歴、指示をAIへ同時にインプットできます。
コンテキストウィンドウは「AIの短期記憶」によく例えられます。人間が会話中に直前のやり取りを覚えているように、AIもコンテキストウィンドウの範囲内の情報を参照しながら応答を生成するのです。
そして、コンテキストウィンドウの範囲外になった古い情報はモデルが直接参照できなくなったり、サービス側で要約・圧縮された形で扱われる場合があるため、どの情報が文脈内に残るかが応答精度を大きく左右します。
コンテキストウィンドウとトークンの関係
コンテキストウィンドウを理解するため、まずは「トークン」の仕組みや、上限が設定される理由を押さえておきましょう。
コンテキストウィンドウに上限がある理由
LLMが扱える情報量に上限があるのは、主に計算リソースとコストの制約があるからです。
標準的なTransformerアーキテクチャでは、トークン同士の関連性を計算する「Self-Attention(自己注意機構)」が使われます。
この計算量は入力トークン数の二乗(O(n²))に比例して増えるため、長い入力を扱うほど処理負荷が大きくなります。つまり、入力が2倍になると計算量は4倍(2²)に膨らみ、10倍になれば100倍(10²)になります。この特性があるため、単純にウィンドウを無限に広げることは現実的ではなく、各AI企業は性能・処理速度・コストのバランスを取りながら上限を設計しているのです。
近年では「コンテキスト圧縮(Compaction)」や、必要な情報だけを動的に取得する「RAG(検索拡張生成)」といった方法も使われています。これにより、すべての情報を一度に詰め込むのではなく、限られたコンテキスト内で必要な情報を扱いやすくする工夫が進んでいます。
トークンとは?
トークンとは、LLMがテキストを処理する際の最小単位で、単語や文字よりも細かく切り分けられた「意味のかたまり」です。単語とトークンの間に固定の換算比率はなく、同じ文章でもモデル(トークナイザ)が違えば分割結果も変わります。
日本語のトークン数の目安
日本語のトークン数は、使用するモデルやトークナイザによって変わります。
英語の単語数を基準にした感覚とは単純に比較しにくいため、以下はあくまで概算として見てください。正確なトークン数は、OpenAIのTokenizerや、Gemini APIのトークンカウントに関する公式ドキュメントなどで確認できます。
| 日本語文字数 | トークン数(概算) | 相当する文書量 |
|---|---|---|
| 1,000文字 | 数百〜2,000トークン程度 | 短いブログ記事1本 |
| 10,000文字 | 数千〜2万トークン程度 | 長めの記事・レポート |
| 400,000文字 | 数十万〜100万トークン程度 | 長編小説数冊分 |
この換算を頭に入れておくと、「100万トークン対応」という数値の規模感をつかみやすくなります。
ただし、実際のトークン数はモデルや入力内容によって変わるため、API利用時は事前確認が重要です。コストを試算する際は、OpenAIやGoogleなど各社の公式ツール・公式ドキュメントでトークン数を確認しておくと安心です。
コンテキストウィンドウはどのように消費されるのか
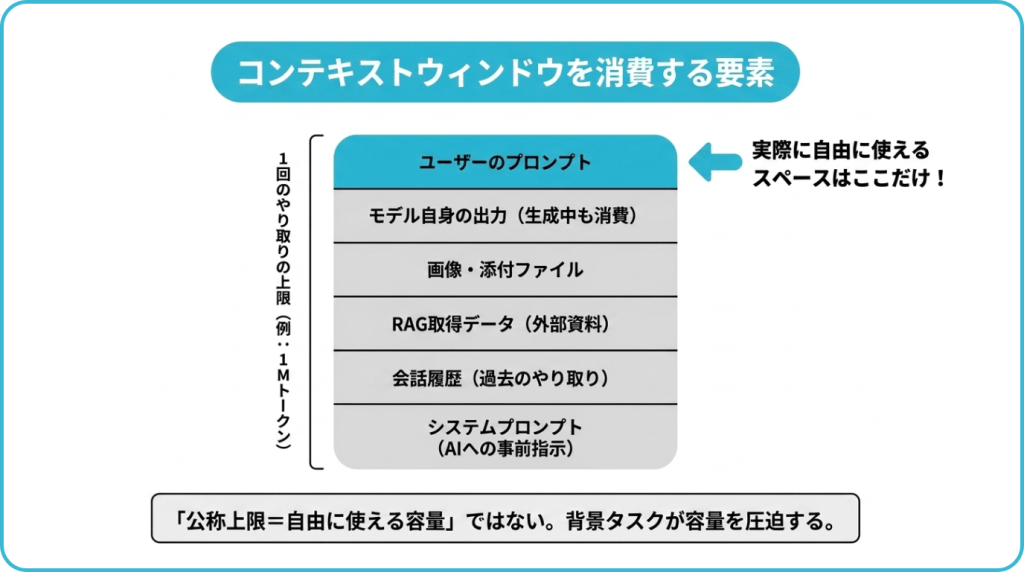
見落とされがちですが、コンテキストウィンドウを消費するのはユーザーがテキストを入力したときだけではありません。以下の要素もすべて容量を消費します。
- ユーザーの入力プロンプト:その時点で書き込まれた指示や質問
- システムプロンプト:ユーザーには見えない、AIの振る舞いを規定する事前指示
- 会話履歴:過去のやり取り全体(マルチターン会話ほど積み上がる)
- RAGで取得した外部情報:RAG(検索拡張生成)で動的に挿入される参照資料
- ツール・MCP定義:エージェント用途で使うツール群の仕様書
- 画像・PDF・添付ファイル:画像やPDFは、モデルや処理方式によってトークン換算される
- モデル自身の出力:生成中の応答自体もカウントされる
- 特殊文字や改行・書式情報:不可視だがトークンは消費する
つまり、公称100万トークン対応のモデルであっても、実際にユーザーが自由に使えるスペースはそれより小さくなると考えてください。
「100万トークンもあるから大丈夫」と油断して豪快に使っていると、入力が上限を超えたり、必要な情報が文脈から外れたりする可能性があります。
コンテキストを使い切ると何が起きるのか
コンテキストウィンドウを使い切った場合の挙動は、利用しているAIサービスやAPIの仕様によって異なります。入力と出力の合計が上限を超えるケースでは、そもそもリクエストが送信できず、「入力が長すぎる」といったエラーメッセージが表示されることが一般的です。
一方、チャット形式のサービスでは、すぐにエラーにならず、古い会話履歴が自動的に要約・省略される場合も見られます。この場合、ユーザーから見ると会話は継続しているように思えても、モデルが最初の条件や過去の指示を直接参照できなくなっている可能性に注意しなければなりません。
その結果、以前に伝えた前提を忘れたような回答をしたり、根拠として渡した資料の一部を無視した出力になったりするリスクが生じます。
業務で利用する場合は、長い会話を漫然と続けず、重要な条件や前提を定期的にまとめ直す、不要な資料を削る、必要な情報だけをRAGで参照する、といった対策が有効です。
コンテキストウィンドウが大きいことのメリット3つ
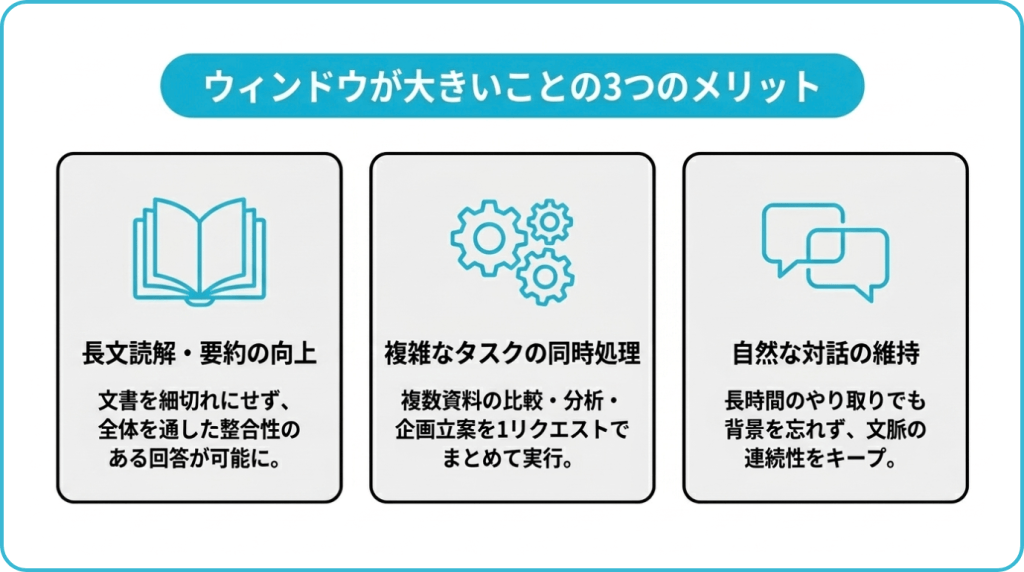
コンテキストウィンドウが大きくなると、AIが扱える情報の幅と深さが広がります。ここでは代表的な3つのメリットを見ていきましょう。
長文読解や要約精度が向上する
100万トークン級のモデルであれば、長編小説や大規模な資料、コードベースを一度に読み込ませやすくなります。ただし、ファイル形式、画像解像度、システムプロンプト、出力トークンなどもコンテキストを消費するため、常に大規模文書をそのまま安定処理できるとは限りません。
従来のように文書を細切れにして別々に処理する必要が少なくなり、文書全体を通した整合性のある回答を得やすくなります。たとえば、長大な調査レポートから特定テーマに関する記述だけを抽出したり、複数の議事録をまたいだ意思決定の経緯を追跡したり、といった業務を1リクエストで処理しやすくなります。
複雑な指示やタスクを同時に処理できる
「添付の3つの製品資料を比較し、ターゲットが20代女性である製品Aのマーケティング施策を、競合Bの弱点を踏まえて5つ提案してほしい」といった多段階の指示を、情報の取りこぼしを抑えながら一度に実行しやすくなるのも長コンテキストの強みです。
これまで人間が複数の資料を往復しながら行っていた分析・比較・企画立案を、AIにまとめて任せやすくなります。
文脈を維持した自然な対話ができる
長時間にわたる対話の流れを失わずに応答できるため、チャットボットや業務アシスタントに実装すればユーザーが何度も同じ背景を説明し直す必要が少なくなります。
カスタマーサポートでの過去問い合わせ参照、面談日程調整、採用面接の記録など、文脈の連続性が成果を左右する業務領域では特に役立ちます。
主要生成AIのLLMによるコンテキストウィンドウ比較
2026年4月時点で、主要モデルの多くは100万トークン級のコンテキストに対応し始めています。
一方で、最大出力、料金、長文中の検索精度、ツール利用、提供プランなどには差があるため、単純に最大トークン数だけでは比較できません。まずは数値で全体像を把握しましょう。
なお、各モデルのコンテキストウィンドウや最大出力は、API、チャット画面、Codexなどの利用環境によって異なる場合があります。また、プレビュー提供中のモデルでは仕様が変わる可能性もあります。
導入前には、AnthropicのClaudeモデル一覧、OpenAI APIのモデル仕様、Gemini 3 Developer Guideなどの公式情報を確認してください。
| モデル | 提供元 | 最大コンテキストウィンドウ | 最大出力 | リリース時期 |
|---|---|---|---|---|
| Claude Opus 4.7 | Anthropic | 100万トークン | 128Kトークン | 2026年4月16日 |
| Claude Sonnet 4.6 | Anthropic | 100万トークン(APIではベータ提供) | 64Kトークン | 2026年2月17日 |
| GPT-5.5 | OpenAI | 105万トークン(API)/Codexでは400Kトークン | 128Kトークン | 2026年4月23日 |
| Gemini 3.1 Pro Preview | 100万トークン | 64Kトークン | 2026年2月19日 | |
| Gemini 3 Flash Preview | 100万トークン | 64Kトークン | 提供中 |
Claude Opus 4.7(Anthropic)
2026年4月16日にリリースされたAnthropicのフラッグシップです。100万トークンのコンテキストウィンドウと128Kトークンの最大出力に対応しており、長時間のエージェントタスクや大規模なコードベースの確認に使いやすいモデルです。
高解像度画像にも対応しているため、スクリーンショットや技術資料などを含むマルチモーダルな入力にも活用できます。
参照:Anthropic公式ドキュメント「Claude Opus 4.7の新機能」
GPT-5.5(OpenAI)
2026年4月23日に発表されたOpenAIのモデルです。APIでは1,050,000トークンのコンテキストウィンドウと128,000トークンの最大出力に対応しています。一方、Codexで利用する場合は400Kコンテキストウィンドウとして提供されるため、API利用とCodex利用では上限の見方が異なります。
OpenAIの発表では、GPT-5.5はCodexでのトークン効率や長い作業への対応が改善されたモデルとして紹介されています。コンピュータ操作能力を測るOSWorld-Verifiedでは78.7%を記録し、GPT-5.4の75.0%を上回りました。
参照:OpenAI公式発表「Introducing GPT-5.5」/OpenAI API「GPT-5.5 Model」
Gemini 3.1 Pro(Google)
2026年2月19日に発表されたGoogleのGemini 3シリーズのモデルです。テキスト・画像・動画・音声・コードを横断して扱えるマルチモーダルモデルで、100万トークンの入力と最大64Kトークンの出力に対応します。
Gemini 3シリーズでは、thinking_levelによって思考の深さを調整できます。Gemini 3.1 Pro Previewではlow / medium / highが利用でき、media_resolutionによるメディア入力の制御にも対応しています。
参照:Gemini 3 Developer Guide/Gemini 3.1 Pro Model Card
コンテキストウィンドウ拡大に伴う課題と注意点3つ

コンテキストウィンドウの拡大は万能ではありません。
むしろ、拡大に伴って新たに生まれた課題を理解していないと、コストと精度の両方を損なう結果になります。ここでは特に注意すべき3つの点を見ていきましょう。
処理速度の低下とAPIコストの増大
前述のとおり、AIモデルは入力する情報量が増えるほど計算量が急激に膨らむため、長いコンテキストを使うほど応答速度は遅くなり、APIコストも大きく膨らみます。
たとえばOpenAIのGPT-5.5では、272Kトークンを超える入力に対して、標準・Batch・Flexの各セッションで入力単価が2倍、出力単価が1.5倍になる仕様があります。
長いプロンプトを使う場合は、事前にOpenAI APIのGPT-5.5モデル仕様で料金条件を確認しておきましょう。一方で、Claude Opus 4.7のように100万トークンまで一律の料金で利用できるモデルもあるなど、料金体系はモデルごとに大きく異なります。
このため、安易に長いプロンプトを投げると、想定外に1リクエストあたりのコストが跳ね上がることがあります。リアルタイム性が求められるチャットボットや、大量のリクエストを捌く必要があるシステムでは、「本当に長大なコンテキストが必要か」を見極める判断が欠かせません。
「Lost in the Middle(長文中盤の情報喪失)」問題
コンテキストを長くしても、AIはその中身を均等に活用しているわけではありません。2023年に発表された論文「Lost in the Middle: How Language Models Use Long Contexts」では、LLMが入力の先頭と末尾にある情報を参照しやすく、中盤に置かれた情報の参照性能が下がりやすい傾向が報告されました。
このような長文中の検索性能を調べる代表的な方法の一つが、Needle-in-a-Haystack(干し草の中の針)型の評価です。長大な文章の任意の位置に特定の情報(針)を埋め込み、AIがそれを正しく取り出せるかを測定します。
つまり、100万対応モデルでも、実際に情報を確実に引き出せる範囲はそれより狭まることがあります。重要な指示はプロンプトの冒頭または末尾に置くなど、配置を工夫することで精度が変わります。
長コンテキストに伴うセキュリティリスクの拡大
長いコンテキストは、攻撃者にとっての「攻撃面」も広げます。Anthropicの研究で報告された「Many-shot Jailbreaking」は、大量の会話例をプロンプトに含めることで、モデルの挙動を望ましくない方向へ誘導する長コンテキスト攻撃です。
コンテキストウィンドウが大きくなるほど、こうした攻撃に使われる入力も増やしやすくなるため、業務で個人情報や機密情報を扱う場合は、入力データの確認、ガードレール設計、ログ監視などの対策も併せて考える必要があります。
コンテキストウィンドウを活かす3つのプロンプト設計

落とし穴を避けつつコンテキストウィンドウの能力を引き出すには、情報の渡し方を工夫することが不可欠です。ここで取り入れやすい3つの方法を紹介します。
重要な情報は「両端」に寄せる
「Lost in the Middle」の特性を踏まえ、守ってほしい制約条件・メインのタスク・重要な参照情報はプロンプトの冒頭または末尾に配置します。
特に末尾は、AIが直前に読んだ内容として強く参照しやすい位置です。長大な資料をインプットする場合は、「この文書を元に、末尾の指示に従ってください」と明示的に誘導すると精度が安定しやすくなります。
XMLタグで情報を構造化し役割を明示する
長いプロンプトでは、資料と指示が混ざってAIが混乱するケースが多発します。XMLタグで構造化すると、この問題を軽減できます。
<document id=”競合分析レポート”>
(長文レポート本体)
</document>
<instruction>
上記レポートから、競合A社の強み・弱みを3点ずつ抽出し、
表形式でまとめてください。
</instruction>
「ここから先は参照資料」「ここから先は指示」という境界を明示することで、AIが資料部分と指示部分を区別しやすくなります。たとえばAnthropicのClaude向けプロンプト設計ドキュメントでは、複数の要素を含むプロンプトでXMLタグを使う方法が紹介されています。
RAGとコンテキスト圧縮を使い分ける
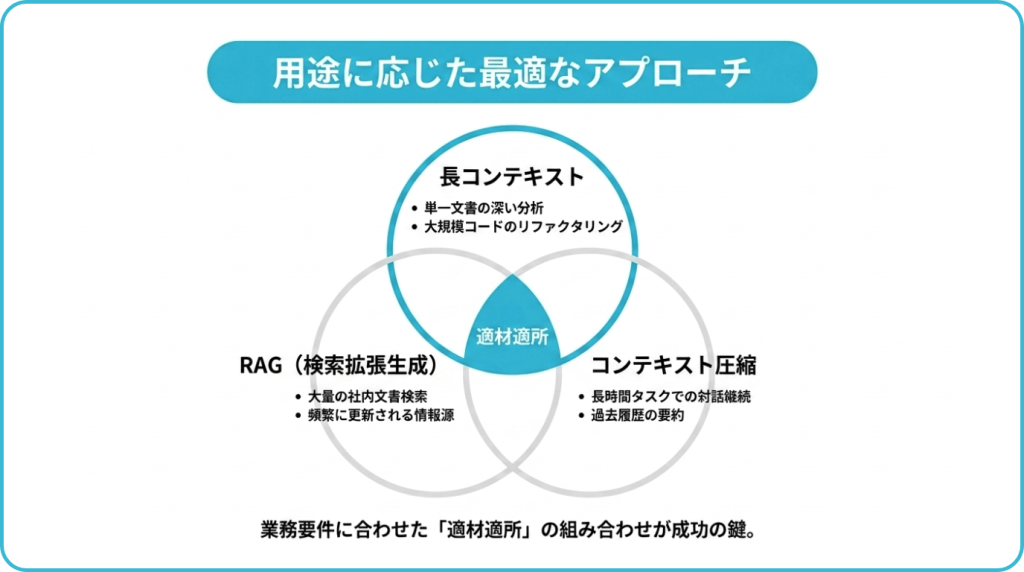
すべてをコンテキストに詰め込むのは、多くの場合、最適な選択肢ではありません。
用途に応じて、長コンテキスト・RAG・コンテキスト圧縮を使い分けることが重要です。AnthropicもAIエージェントに渡す情報を適切に選択・維持する考え方として「context engineering」を紹介しています。以下に使い分けの例を挙げました。
- 長コンテキストを使うべきケース:単一文書の深い分析、連続的な対話、大規模コードベースの一貫したリファクタリング
- RAG(検索拡張生成)を使うべきケース:大量の社内文書からの検索、ナレッジベース、頻繁に更新される情報源
- コンテキスト圧縮を使うべきケース:長時間のエージェントタスクで過去の会話を要約しながら継続したい場合
【診断】あなたの業務に最適なコンテキストサイズは?
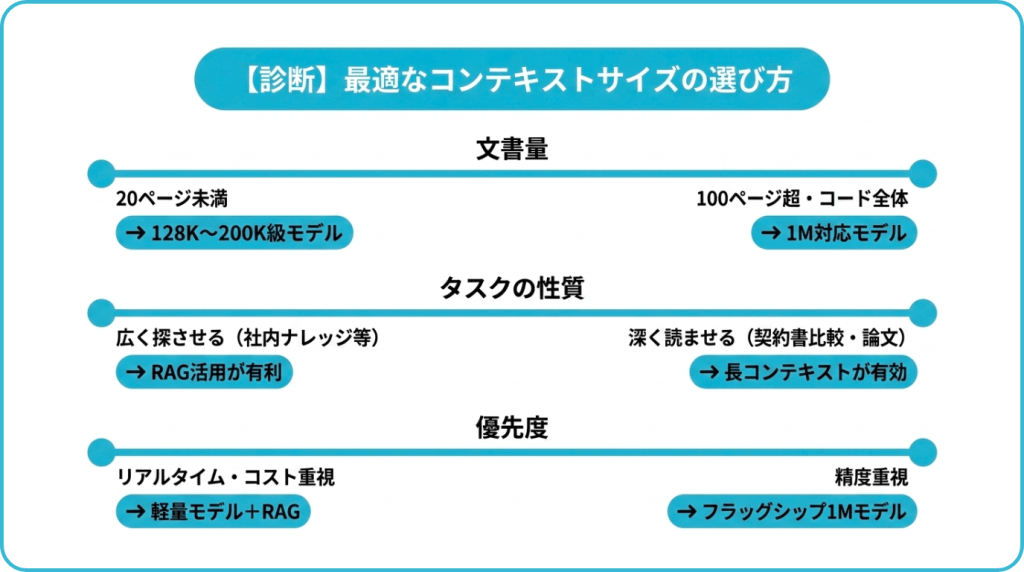
全業務で最大サイズのコンテキストが必要なわけではありません。以下の3つの問いで、自分のタスクに合うサイズ感を見極めてみてください。
Q1. 一度に扱いたい文書量はどのくらいか?
- A4で20ページ未満:文書の文字量やファイル形式によって異なりますが、128K〜200K級のモデルで対応しやすい
- A4で20〜100ページ程度:200K〜500K級のモデルや、必要に応じて100万対応モデルを検討しやすい
- 100ページ超/コードベース全体/長編小説級:Claude Opus 4.7、GPT-5.5 API、Gemini 3.1 Pro Previewなどの100万対応モデルが選択肢になる
Q2. タスクは「深く読ませる」か「広く探させる」か?
- 深く読ませる系(契約書の条項比較、論文精読、コードレビュー):長コンテキストが効く
- 広く探させる系(社内ナレッジから該当情報を抽出、FAQ応答):RAGの方がコスト効率・精度ともに有利
Q3. 応答速度とコストの優先度は?
- リアルタイム性重視(チャットボット、顧客対応):Gemini FlashやHaiku系の軽量モデル+RAG
- 精度重視で時間はかけてよい(法務レビュー、事業計画の分析、長大な技術資料の確認):フラッグシップ級の100万モデル+長コンテキスト活用
この3つを組み合わせて考えると、単に「一番大きいモデル」を選ぶのではなく、扱う文書量、求める精度、応答速度、コストに合わせてモデルを選びやすくなります。
まとめ
コンテキストウィンドウは単なるスペック値ではなく、AI活用の費用対効果と品質を大きく左右する重要な要素です。
AIを業務で使う際は、モデルの性能だけでなく、どの情報をコンテキストに入れ、どの情報をRAGや要約で扱うかを考えることが重要です。
本記事の診断フローや使い分けの考え方を参考に、自社の業務に最適なAI活用の組み合わせを見極めていきましょう。
アイスマイリーでは、生成AIのサービス比較と企業一覧を無料配布しています。課題や目的に応じたサービスを比較検討できますので、ぜひこの機会にお問い合わせください。
よくある質問
コンテキストウィンドウとトークンの違いは何ですか?
トークンはAIが処理する言語の最小単位で、コンテキストウィンドウは「一度に扱えるトークン数の上限」を指します。トークンが「コマ数」、コンテキストウィンドウが「視野に入るコマの総数」と考えると分かりやすいでしょう。
100万トークンは日本語で何文字くらいですか?
日本語の文字数とトークン数の関係は、モデルやトークナイザによって変わります。100万トークンは非常に大きな入力容量ですが、正確な文字数は一概には言えません。APIで利用する場合は、各社の公式ツールやトークンカウント機能で事前に確認すると安心です。
コンテキストウィンドウは大きければ大きいほど良いですか?
必ずしもそうとは限りません。大きくなるほどAPIコストと処理時間が増え、「Lost in the Middle」問題で中盤の情報を取りこぼすリスクもあります。タスクに合わせた適切なサイズ選定が重要です。
RAGと長コンテキストはどう使い分ければ良いですか?
単一文書の深い分析や連続的な対話には長コンテキスト、大量のナレッジから必要な情報だけを引き出す用途ではRAGが向きます。両者は対立ではなく補完関係にあり、併用することでコストと精度のバランスを取りやすくなります。
どのモデルを最初に試すべきですか?
日常業務であれば、Claude Sonnet 4.6やGemini 3 Flash Previewなど、速度・料金・性能のバランスを取りやすいモデルから試すとよいでしょう。複雑なコーディングや長大な文書分析が必要になった段階で、Claude Opus 4.7、GPT-5.5 API、Gemini 3.1 Pro Previewなどを検討すると、コストを抑えながら必要な性能を選びやすくなります。
- AIサービス
- 生成AI
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- 生成AI
- ChatGPT
- Gemini
- Claude
- LLM
- AI研究開発
- 画像生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
- GPU
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI












FOLLOW US
SNSをフォローして、最新情報をチェックできます!

Google、「Gemini」新モデル「3.6 Flash」「3…

安川電機、「エージェンティック・ロボットシステム」開発。AIロボ…

富士フイルムBI、複合機の保守プロセスを効率化するAI搭載「統合…

Anthropic、最新AIモデル「Claude Opus 5」…
住宅ローン比較診断サービス「モゲチェック」、AIエージェント連携向けMCPサーバーを公開

ChatGPT広告に31.1%が出稿済みと回答、全体の7割超が出稿に意欲。AIツール広告に関する実態調査結果発表

【インタビュー】全従業員の「生成AI活用の義務化」、その先へ ――LINEヤフーが挑む「AIエージェント化」の現在地

ChatGPTで手相占い|写真の送り方・プロンプト例と注意点を解説

Grokで夢小説を書く方法|無料版・プロンプト例・口調を保つコツ

Sakana AI、Fuguオーケストレーションモデルのサイバーセキュリティ特化AI「Fugu-Cyber」を発表
AI製品・ソリューションの掲載を
希望される企業様はこちら