

DataGemmaとは?ハルシネーション対策モデルの特徴や機能を紹介
最終更新日:2024/10/28
 DataGemmaとは?
DataGemmaとは?
Googleは2024年9月13日に、新しいAIモデル「DataGemma」を発表しました。DamaGemmaでは、Googleの生成AI「Gemini」のベースに信頼性の高いナレッジグラフ「Data Commons」を組み合わせ、補足の質問と回答を用いることで、最終的な回答の精度を高めています。このモデルでは、生成AIが抱える大きな課題であるハルシネーションの解消に貢献することが期待されています。
本記事では、DataGemmaの概要から主要な2つのアプローチ、具体的な活用方法などについて詳しく解説します。AIが抱える課題を解消し、正確性の高い情報を提供するために役立つDataGemmaについて、この機会に理解を深めましょう。
DataGemmaとは?
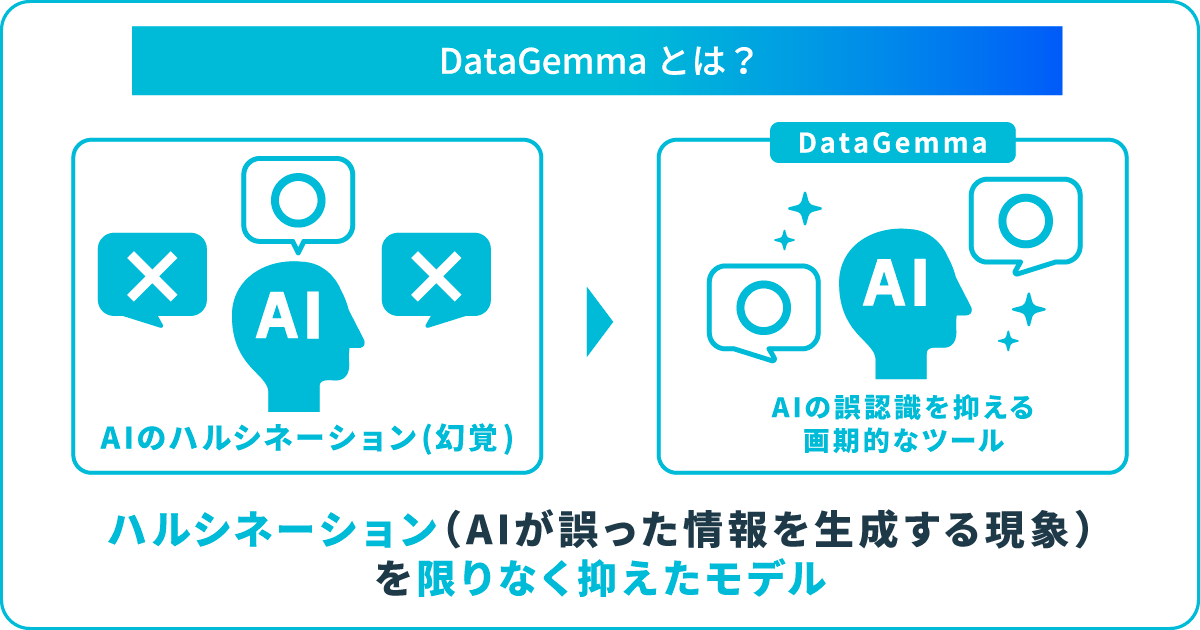
DataGemmaは、Googleが2024年9月13日に発表したオープンモデルです。生成AI「Gemini」の軽量版LLM「Gemma」をベースに、生成AIの課題であるハルシネーション(幻覚)の解消を目的として開発されています。
DataGemmaでは、膨大な統計変数やデータポイントを含むナレッジグラフの「Data Commons」を活用し、回答の正確性を向上させることに成功しました。また、「RIG」と「RAG」という2つのアプローチを採用し、回答の事実性と推論を強化しています。
Googleは、「DataGemmaはAIが人々に正確な情報を提供し、意思決定や世界のより深い理解を促す未来を築く鍵になる」とコメントしています。
関連記事:Google、ハルシネーションに対応する初のオープンモデル「DataGemma」を発表
DateGemmaが解決するハルシネーションとは

昨今は、AI技術の進展が目覚ましく、大規模言語モデル(LLM)の高度化が急速に進んでいます。LLMが多くのタスクに応用できる現在、モデルが誤った情報をあたかも正しいかのように提案してしまう「ハルシネーション(幻覚)」の問題も見逃せません。
ハルシネーションとは、生成AIがまるで幻覚を見ているかのように、学習していない情報や存在しない事実を作り出してしまうことです。ハルシネーションが発生する原因として、AIに入力されたデータが不十分もしくは間違っていることや、AIの知識が不完全であることなどが挙げられます。
また、AIは文脈の理解が困難であり、人間のように常識や倫理といった基準でミスや誤解に気付けずに、正確ではない内容を自信を持って提供することになるのです。
そこで、DataGemmaでは、GoogleのData Commonsから取得した信頼性の高い統計データを使用し、LLMの回答を補強、応答精度の向上とハルシネーションの削減を目指しています。
Data Commonsは、国連(UN)や国勢調査局、世界保健機関(WHO)、疫病予防管理センター(CDC)といった信頼性の高い組織からデータを習得しています。現実的に高い信頼性を持つ情報を連携させ、補足する形でハルシネーションの発生を回避するのがDataGemmaの主な仕組みです。
関連記事:生成AIのハルシネーションとは?発生の原因やリスク、その対策について
DataGemmaの特徴と仕組み

DataGemmaでは、「RIG」と「RAG」という2種類の手法を用いています。ここでは、RIGとRAGそれぞれの特徴や仕組みを解説します。
RIG(Retrieval-Interleaved Generation)
RIG(Retrieval-Interleaved Generation)は、LLMが生成した情報をData Commonsに保存されているデータと比較することで、事実の正確性を高める手法です。LLMに入力された質問に対して回答を生成すると、RIGがその質問をData Commonsのデータベースと照合します。
例えば、「2023年の再生可能エネルギーの利用はアメリカで増加しているか」という質問を入力すると、モデルが草案としての回答を生成します。次に、RIGが回答案の中から、Data Commonsと照合チェックできる部分を特定し、回答の不正確な部分を正しく置き換えます。
同時に、回答生成に使用した情報源も提示するため、ユーザーが後で参照することが可能です。
RAG(Retrieval-Augmented Generation)
RAG(Retrieval-Augmented Generation)は、モデルの回答生成と外部情報の検索を組み合わせることで、正確性を高める手法です。LLMに入力された質問に関連するデータをData Commonsから取得し、それをプロンプトと統合することで回答を出力します。
RAGのアプローチでは、質問に応じてDataGemmaで「Data Commons向けの質問」を生成します。続いて、Data Commonsから得られたデータを補助LLMに入力し、最終的な回答を出力する仕組みです。
DataGemmaの評価

Googleのテストでは、RIGによって回答の事実性が約58%まで向上し、ベースモデルの結果に比べて約30〜50%も上昇したことがわかっています。また、RAGを用いると質問の約24〜29%に対して統計的な回答を出力でき、約99%と極めて高い割合で正確性を打ち出しています。
一方で、推論に基づく数学的能力については約76%ほどに留まりました。総合的には、他のLLMより高い正確性や事実性のある回答を生成できる可能性は高いと言えます。
DataGemmaの活用シーンと将来性

DataGemmaは柔軟なスケーラビリティを備えており、幅広い規模の市場に対応可能です。DataGemmaの活用例として、以下の分野や用途が挙げられます。
- ビジネス全般
- 政府や公的機関
- 医療・福祉・ヘルスケア
- 教育
- 金融
- 環境保護や社会貢献
技術の継続的な進化や市場拡大、ユーザーエクスペリエンスの向上などさまざまな面での活用が予測されます。将来的には、統計データやクエリの枠にとらわれることなく、社会における課題解決や持続可能な発展といった貢献も期待できます。
DataGemmaが抱える現状の課題

DataGemmaは多くの可能性を秘めていますが、まだ課題は残されています。Data Commonsのデータカバレッジには限界があるため、トピックによっては回答の正確性が劣る場合があります。
Data Commonsのインターフェースの精度の向上や関連データセットの拡充により、応用できる範囲が広がるでしょう。
まとめ
DataGemmaは、LLMの大きな課題であるハルシネーションに対応したオープンモデルとして、Googleから発表されました。Data Commonsの信頼性の高いデータと連携し、RIGとRAGの2つのアプローチを用いて、従来よりも正確性や事実性の高い回答を生成することに成功しています。
現状における課題として、Data Commonsのカバレッジの限度や複雑なクエリへの対応などがありますが、幅広いジャンルにおける活用に期待が集まっています。
生成AIサービスの提供企業一覧を、以下より無料でご欄いただけます。自社における生成AIシステムの活用を検討するために、ぜひご利用ください。
よくある質問
DataGemmaの使い方は?
DataGemmaは、Hugging FaceやKaggleといったプラットフォームで、RIGとRAGそれぞれのモデルが公開されています。いずれも巨大なデータセットを処理できる仕様のため、動作環境のGPUやRAMなども高いスペックが求められます。
DataGemmaは日本語に対応してる?
DataGemmaは日本語にも対応しており、日本語クエリを正しく理解して回答を出力することが可能です。ただし、現状では中途半端な日本語や英語まじりの回答が報告されているため、動作が不安定な場合は英語のプロンプトを使うと良いでしょう。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- 生成AI
- ChatGPT
- Gemini
- Claude
- LLM
- AI研究開発
- 画像生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
- GPU
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI
















FOLLOW US
SNSをフォローして、最新情報をチェックできます!
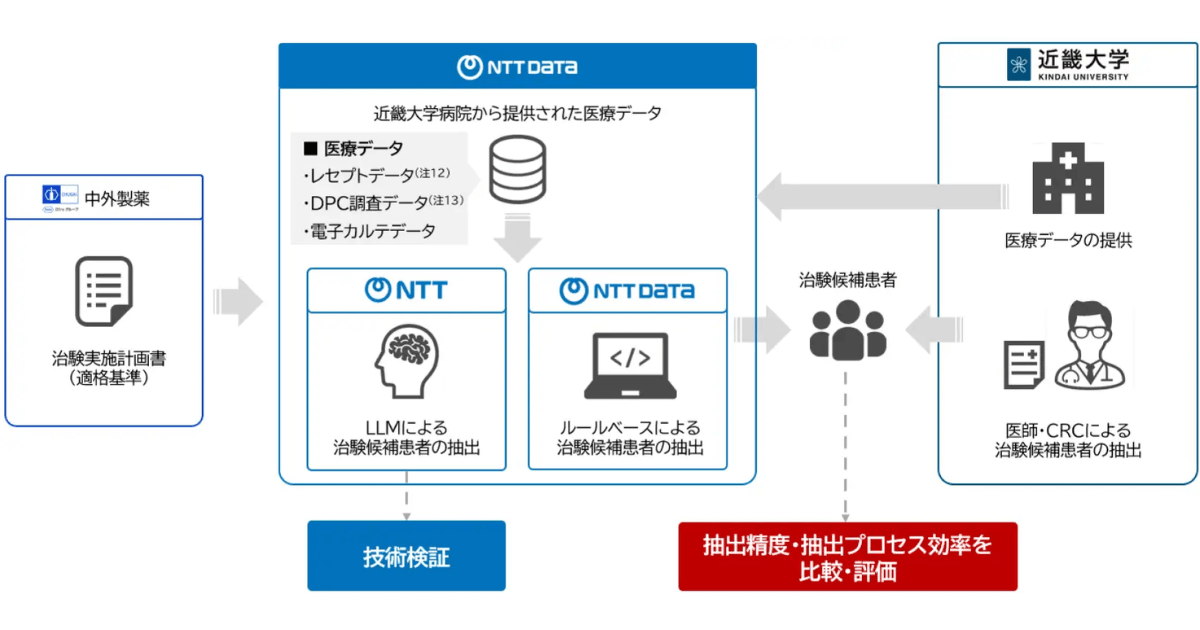
近畿大学病院など4者、リアルワールドデータとLLMを用いた共同研…

OpenAI、新世代音声モデル「GPT-Live」公開。全二重ア…

KUMON、AI活用学習サービスのatama plusをグループ…

Cloverse、アパレル特化型AI「Clovia」提供開始。撮…

ELYZA、三井住友カードで「入会審査自動判定AI」運用開始。従来審査の20%を自動化し対応時間を短縮
ノーベル賞受賞者16名含む経済学者ら200名超、AIによる経済変革への警告・対応求める声明発表

ちゅうぎんフィナンシャルグループ、「AI1,000人プロジェクト」を開始。Microsoft 365 Copilot活用で業務変革を推進

ChatGPTの共有リンクとは?作り方から削除・安全な使い方まで解説

ChatGPTでダイエットを成功させる使い方・プロンプト完全ガイド
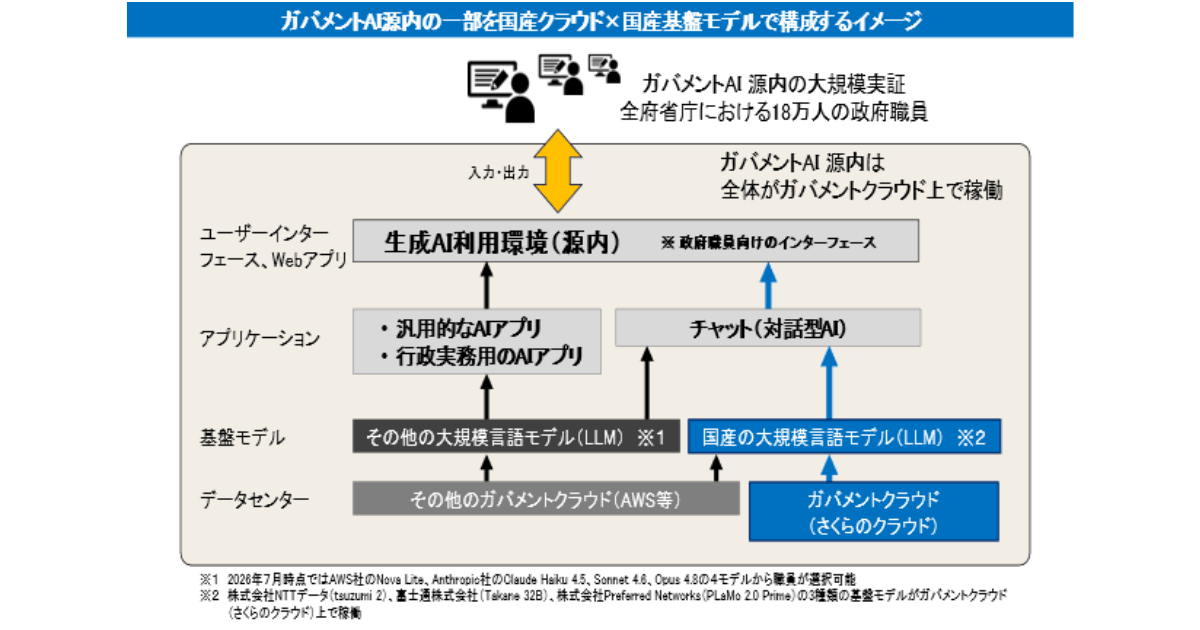
デジタル庁、ガバメントAI「源内」で国産AIの試用開始。「さくらのクラウド」で3種類の基盤モデルを検証
AI製品・ソリューションの掲載を
希望される企業様はこちら