

Diffusion model(拡散モデル)とは?仕組みやGAN・VAEとの違いを解説
最終更新日:2026/06/23
 Diffusion modelとは?
Diffusion modelとは?
昨今の生成AIブームの流れを受けてさまざまなモデルが登場するなか、画像生成AIサービスを支えるDiffusionモデルへの注目が特に高まっています。Stable DiffusionやDALL・E2といったAIサービスも登場しており、静止画だけでなく動画生成にも応用されています。
本記事では、Diffusion model(拡散モデル)の概要や仕組み、VAEやGAN、フローベースとの違い、採用されている主なモデルなどについて解説します。Diffusion model(拡散モデル)について理解を深め、自社事業に役立つ形でサービスを導入するためにぜひご覧ください。
Diffusion model(拡散モデル)とは?

「Diffusion model(拡散モデル)」とは、画像データを生成するAIサービスを中心に利用されている生成AIモデルの1つです。拡散モデルは、スコアベースや拡散確率モデルなどのタイプに分けられますが、画像生成のタスクにおいて優れた精度を実現できると注目を集めています。
2015年に発表された論文「Deep Unsupervised Learning using Nonequilibrium Thermodynamics」にて初めて提案され、2020年には「Denoising Diffusion Probabilistic Models」の中で改良版が指摘されました。
Diffusion modelは、テキスト情報から画像を生成するStable DiffusionやOpenAIが手掛けるDALL・E2、GLIDE、Google社のImagenといったサービスにも搭載されています。
Diffusion model(拡散モデル)の仕組み

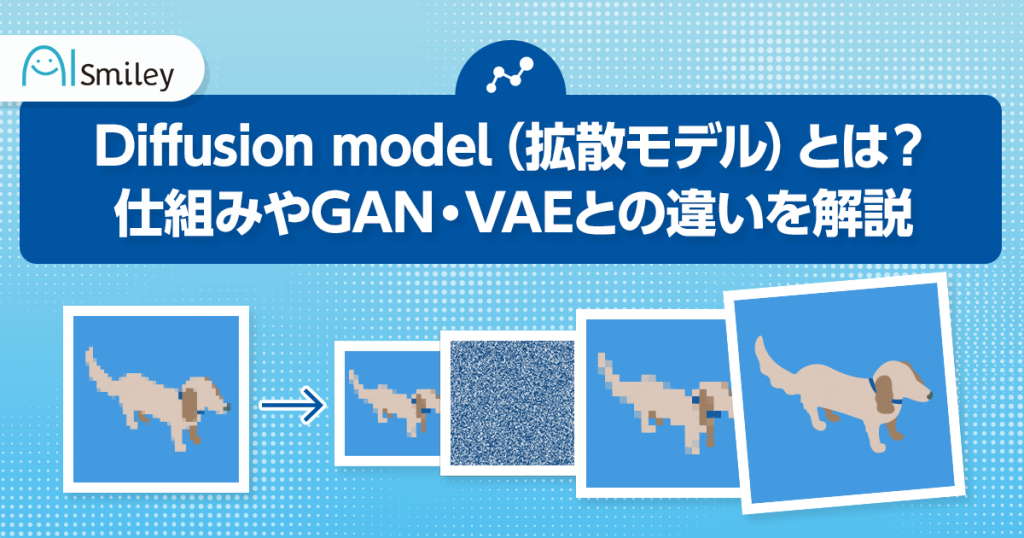
Diffusion model(拡散モデル)の仕組みは、元の画像データにノイズ(Gaussian Noise)を加えていくForward processと、ノイズ分布の状態からノイズを除去することで画像データを作成するReverse Processの2つに分かれています。それぞれの生成過程がどのように機能しているのか説明します。
Forward Process
Forward Processは、元の画像データにランダムノイズを加えていき、最終的にはノイズだけに変換するプロセス(拡散過程)です。AIモデルでは、ノイズを用いて対象の特性を得る実験や解析がよく行われます。Diffusion modelでも、元のきれいな画像にガウスノイズを少しずつ加えることで、結果的にガウス分布を得ます。
このプロセスでは、加えるノイズの平均値や最終的にガウス分布に変換されるまでの回数を使った正規分布の計算式が使われます。
計算したノイズを元の画像に追加することで実行でき、ステップごとのパラメータ学習が不要なため、全体のアーキテクチャは比較的シンプルである点も特徴です。
Reverse Process
Reverse Processは、先述のForward Processの逆で、ガウス分布からノイズを取り除いていき、画像を作成するプロセス(逆拡散過程)です。基本的には、画像にノイズを加えて最終的にノイズだけにする確率過程を考え、その逆を辿ることでノイズから画像を生成します。
ただ、逆再生的にプロセスを実行すれば画像を取得できるわけではなく、データセット全体を用いて条件付き確率を推定するモデルを学習する必要があります。
Reverse Processについて、実際には文献よりも比較的シンプルなコードで実装が可能です。ノイズを加えたデータに対して、作成したネットワーク構造で逆予測し、徐々に元データに近づくような処理を行います。
Diffusion model(拡散モデル)とVAEの違い

Diffusion modelは、深層ニューラルネットワークの技術と確率グラフィカルモデル(Probabilistic Graphical Model)を組み合わせた統合モデルの1種です。同タイプの中でも、VAEは特に似た特徴を持つとされています。
VAE(Variational Autoencoder/変分オートエンコーダ)は、オートエンコーダのデコーダに変数を混ぜ、入力とは異なる出力を行うモデルです。潜在変数モデルにおけるモデルエビデンスの推論する方法としても使われます。
入力を潜在空間上の特徴量で表すエンコーダと、潜在空間から元の次元に戻すデコーダで構成されており、潜在空間には何かしらの分布を仮定しています。
Diffusion modelは、学習した分布から潜在変数をサンプリングし、ニューラルネットワーク上に変化させる、という生成プロセスはVAEと似ています。ただ、VAEとは違ってエンコード側の学習パラメータは存在しません。
VAEやオートエンコーダについては以下で詳しく解説しますので、あわせてご覧ください。
Diffusion model(拡散モデル)とGANの違い

GAN(Generative Adversarial Networks/敵対的生成ネットワーク)も、Diffusion modelと同じ生成モデルの1つです。GANは、本物のデータと間違われる可能性のあるデータを対峙させることにより、AIデータ学習を進めていく手法です。
新しい人工的なインスタンスを作成するために、ニューラルネットワークを採用し、2種類のモデルを互いに戦わせるというコンセプトがあります。
テキストから画像を生成する能力は、Diffusion modelもGANも同等に備えています。ただ、GANでは敵対的学習の構造そのものに、学習の不安定さと多様性の欠如があります。
また、論文「DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation」において、GANベースの生成モデルに画像とテキストに関する高い性能を持つCLIP(Contrastive Language and Image Pre-training)の記載もあるものの、実用性が低く応用はまだ難しいとされています。
GANを使った画像生成の仕組みや活用シーンなどについては、下記記事もあわせてご覧ください。
敵対的生成ネットワーク(GAN)とは?画像生成の仕組みと今後の課題を解説
Diffusion model(拡散モデル)とFlow-based modelsの違い
Flow-based models(フローベースモデル)とは、ディープラーニングを利用して未知のデータを生成する深層生成モデルの1つです。深層生成モデルでは「潜在変数からデータを生成する」というニューラルネットワークを学習しますが、潜在変数とデータの次元が等しい場合、データ生成プロセスを同じ空間内での軌跡として扱うことができます。
この軌跡が決定論的に1つに定まるものがフローベースモデルです。ただ、潜在変数に逐次変換を加えてデータを生成するため、可逆的な関数でなければならず、モデルの表現力が制限されてしまう点は問題といえます。
一方、Diffusion Model(拡散モデル)における空間内の軌跡は、確率微分方程式によってモデル化されます。生成過程では、少しずつノイズを画像などの実データに足していき、ノイズ分布を作成した後、今度はモデルがノイズから少しずつ実データに近づけていきます。
Diffusion model(拡散モデル)が使用されているAIサービス
ここでは、Diffusion modelが採用されている代表的なAIサービスとして、Stable DiffusionとDALL・E2を紹介します。
Stable Diffusion
Stable Diffusionとは、イギリスのスタートアップ企業Stability AIが開発した画像生成AIサービスです。ユーザーは画像のイメージをテキストで入力するだけで、高品質な画像データを生成できます。
Stable Diffusionはオープンソースであるため、誰でも無料かつ簡単に活用できます。また、Web上に構築された環境はもちろん、ローカル環境で独自に動かすことが可能です。現在Hugging FaceやDream StudioといったWebアプリケーション上にて、Stable Diffusionを使用できます。
英語だけでなく日本語版もあるため、日本語を入力して画像を生成することも可能です。また、「Stable Diffusion web UI」などの関連ツールを使うと、ローカル環境やクラウド上で日本語テキストによる画像生成がスムーズに行えます。
最近話題になっているアート写真のような高品質画像を生成できる「Photorealistic-fuen-v1」も、Stable Diffusionがファインチューニングされたものです。2023年5月には、Stable Diffusion搭載のAI動画生成サービス「text2video Extension」も登場しました。
Stable Diffusionの使い方や生成画像の商用利用などについては、下記記事もあわせてご覧ください。
Stable Diffusionとは?話題の画像生成AIの使い方・初心者向けのコツも徹底解説!
DALL・E2
DALL・E2 (ダリ ツー)は、ChatGPTなどの生成系AIモデルで知られるOpenAIが、2022年4月に発表した画像生成AIツールです。Stable Diffusionと同様に、入力テキストを基に画像やイメージを作成できます。
他の画像生成AIに比べて、クリエイティビティに優れているという特徴があり、極端に見える英文を入力しても要素を上手に読み取り、1つのデータとしてまとめてくれます。また、一部の削除や編集、フレーム外への描き足しといった機能も搭載されており、生成画像に手を加えて仕上げていくことも可能です。
無料で利用できますが、毎月の使用上限が設定されており、回数を超えて使いたい場合は料金を支払って追加する必要があります。日本語の入力にも対応は可能ですが、精度が不十分な可能性があるため、英文入力が望ましいでしょう。
DALL・E2の画像生成機能を実際に試した記事もあわせてご覧ください。
DALL·E 2の使い方 文字を入れるだけで使える話題の画像生成AIを試してみた!
Diffusion modelの実装方法とは?
Diffusion modelの実装方法として、PyTorchで実装する方法があります。PyTorchとは、Python向けのオープンソース機械学習ライブラリで、機械学習を使ったAI開発やブロックチェーン開発、IoT開発などさまざまな分野で活用されています。
PyTorchは柔軟性が高く、複雑なネットワークも比較的容易に実装できるため、Python開発の効率化や生産性の向上に役立ちます。
とはいえ、自社で一からプログラミングによりシステムを開発するとなると、膨大な時間とコストがかかります。日常業務にも影響が出る可能性があるので、AI技術に特化した開発サービスやモデル生成サービスを扱っている企業に依頼するとスムーズです。
Diffusion model まとめ
Diffusion model(拡張モデル)は、元の画像データに少しずつノイズを加えた後、ノイズを除去してデータを復元するというコンセプトを持つ生成モデルです。生成モデルでも特に有名なVAEやGAN、フローベースなどと似ている部分もありますが、より高品質の画像を生成することに成功しています。
すでにStable DiffusionやDALL・E2、GLIDEといったさまざまなAIサービスが登場しています。今後は高解像度化など、さらなる技術の進歩・発展や応用に期待が高まっています。
自社に適した導入と運用を効率的に実現するためには、専門知識や運用経験が豊富なプロに相談することをおすすめします。
AIに関する開発・構築を委託できる専門企業やサービスを選ぶためには、比較検討する必要があります。下記よりサービス・企業の一覧を無料ダウンロードいただけますので、ぜひご活用ください。
AIモデル作成ツールを利用することで、プログラミング言語の技術がなくても、直感的な操作でツールの開発が可能です。人件費などのコストが限られている場合でも、ツールを使えば業務効率や生産性の向上が見込めるでしょう。AI開発の情報共有にも役立つツール一覧を配布していますので、あわせてご覧ください。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI










FOLLOW US
SNSをフォローして、最新情報をチェックできます!

ソフトバンク、株主総会で新AI戦略を発表。次世代社会インフラ構築…

MASC、ヒューマノイドロボット「Unitree G1」導入。「…

静岡県藤枝市、全国初となる国産生成AIの公共活用実証実施。ソフト…
AVITAのAIロープレ「アバトレ」、日本調剤の薬局全国768店…

ChatGPT Workとは?機能・料金・使い方、Codexとの違いを徹底解説
近畿大学病院など4者、リアルワールドデータとLLMを用いた共同研究を開始。治験候補患者抽出の精度向上と効率化を図る

KUMON、AI活用学習サービスのatama plusをグループ化。教室のグローバル展開や指導者支援を推進

Grok 4.5とは?性能・料金・使い方・他社モデルとの違いを解説

Claudeは画像生成ができない?最新機能と代替手段を徹底解説

アイスマイリー、 7/29(水)から3日間「イプロスAI 2026 夏」にブース出展。来場登録・実来場でAmazonギフト500円分プレゼント!
AI製品・ソリューションの掲載を
希望される企業様はこちら