

生成AI

最終更新日:2026/01/16
 画像認識AIの仕組みと活用事例
画像認識AIの仕組みと活用事例
近年は、さまざまな分野でAI・人工知能が積極的に導入され始めています。その中には「AIを用いなければ実現できない技術」も多く、今や私たちにとってAIは欠かせない存在と言っても過言ではありません。
そんな中、AIを活用したサービスとして「画像認識」に注目が集まっているのをご存知でしょうか。今回は、この「画像認識」の仕組みについて詳しく解説していくとともに、業界別の注意点や活用事例もご紹介していきますので、ぜひ参考にしてみてください。
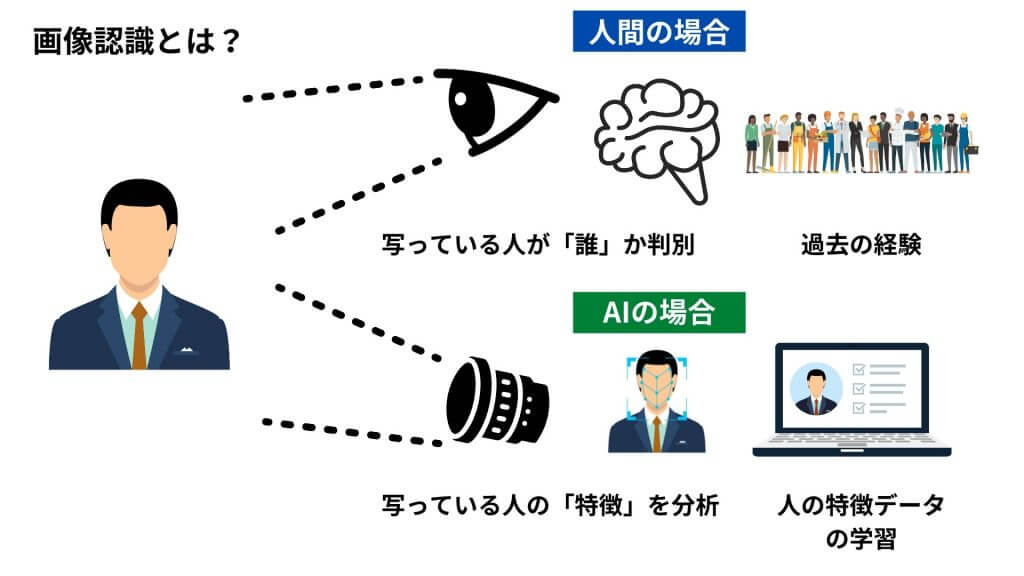
「画像認識(Image Recognition)」とは、画像に映る人やモノを認識する技術です。「画像に何が写っているのか」を解析します。画像認識はパターン認識の一種で、近年は深層学習(ディープラーニング)という手法によって、さらに精度が向上し、多様な分野での導入が進んでいます。
画像認識は、製造業の外観検査、小売業の無人レジ、物流の検品作業、セキュリティの監視カメラなど、幅広い業界で活用されています。「目視作業の自動化」や「人手不足の解消」を検討している方にとって、まず理解しておきたい基本技術です。
人間の場合であれば、過去の経験をもとに「画像に写っている人(物)が誰(何)なのか」を判別することが可能です。しかし、コンピューターには人間のように「蓄積された経験」が存在しないため、経験を活かして画像に写っている人(物)を認識するという作業はできませんでした。
しかしAIを活用すれば、コンピューターも数多くの画像データから人(物)の特徴などを学習できるようになります。学習データをもとにして「画像に写っている人(物)の識別」を行えます。
この画像認識の技術は、すでにさまざまな分野での活用が進んでいます。例えば、防犯の分野では、IoTと組み合わせて「防犯カメラの映像から人物を割り出す」こと」が可能になります。そのため、従来よりも精度高く犯人を特定できたり、不審人物を検知したりすることができます。
画像認識はディープラーニング(深層学習)の登場によって改めて注目を集めましたが、その歴史は意外に古く、基礎となる技術は以前から存在していました。現在では、画像認識には機械学習によるパターン認識が標準的に用いられ、そこにディープラーニングが加わることで、高精度な画像認識が可能になっています。
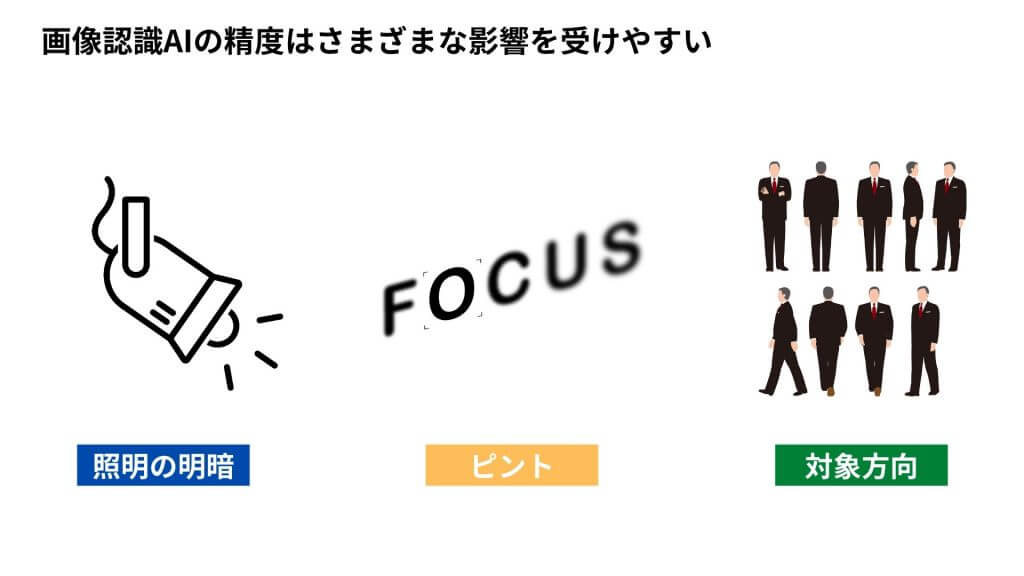
しかし、コンピューターが画像を認識するのは決して簡単なことではありません。照明の明るさ、ピントのずれ、対象物の向きなど、さまざまな影響を受けやすいからです。では、どのような経緯で画像認識の精度は高まってきたのでしょうか。歴史とともに振り返ってみましょう。
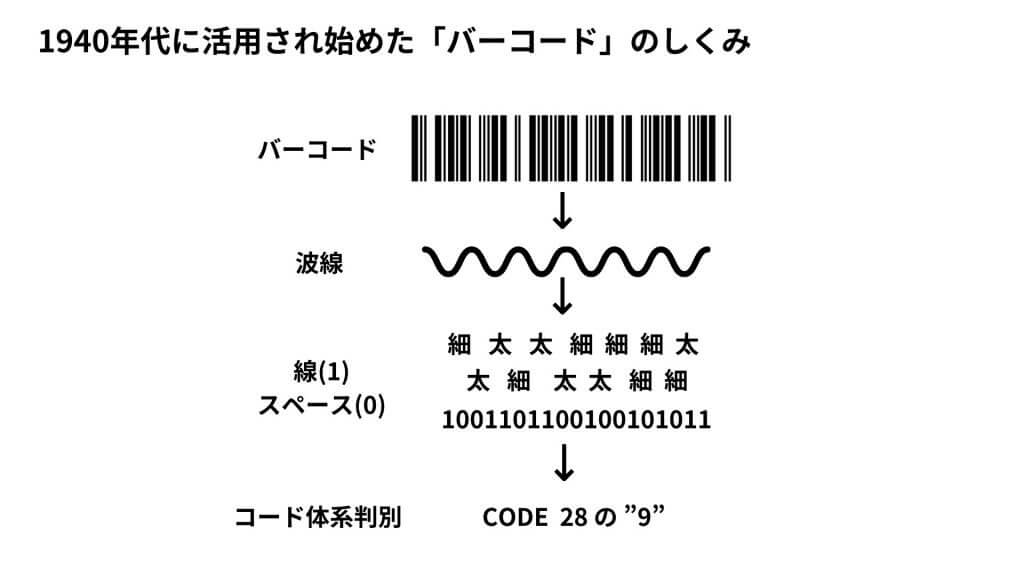
画像認識技術として最も古いのは、1940年代に活用され始めた「バーコード」です。バーコードとは、バーとスペースの組み合わせによって、機会で機械が読み取れるように表現したものを指します。さまざまな商品のパッケージに記載されているので、ご存知の方も多いと思います。そんなバーコードは、バーコードスキャナと呼ばれる光学認識装置を使って、バーコード化された金額等の情報をによって読み取ります。
バーとスペースで構成されたシンプルなものですが、画像のパターンから情報を読み取っているという点を踏まえれば、立派な画像認識といえるでしょう。
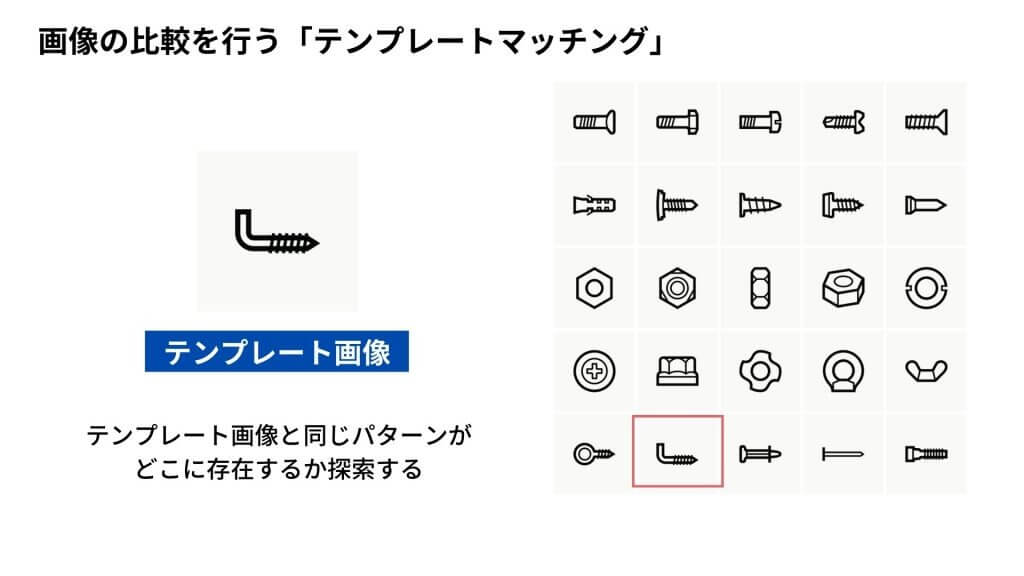
これまでの画像認識では、テンプレートマッチングを使用するのが一般的とされていました。テンプレートマッチングとは、画像に映っている物体の位置を検出する「画像検出」という技術のひとつです。この方法では、検出したい物体の画像そのものをテンプレートとして、対象画像の一部分との類似性を、その領域をスライドしながら比較していきます。これによって、「対象となる物体が画像内のどこに映っているのか」「いくつ映っているのか」といった情報を抽出することが可能になります。
しかし、この方法では、照明による変化が大きい場合など、テンプレート画像からの変化が激しいケースではどうしても認識率が下がってしまう傾向にあります。また、認識したい対象物ごとにテンプレートが必要となるという点も、大きな課題でした。
2000年代に入ると、計算機の技術が発展したことで、データの処理速度も大幅に向上していきました。この変化によって、大量の画像データを用いた機械学習による画像認識が実現可能となり、人が手作業でルールやモデルを構築する手法から、機械学習によるパターン認識中心のアプローチへと移行して行きました。
さらに2012年には、ディープラーニングの登場したことで世界に大きなインパクトを与えました。ILSVRC(ImageNet Large Scale Visual Recognition Challenge)という、2010年から2017年まで開催されていたILSVRCという画像認識コンテストにおいて、カナダ・トロント大学のヒントン教授が率いるチームが開発した「AlexNet」が画像認識に対して初めてディープラーニングを活用し、2位のエラー率26.2%に対して15.3%を記録し、約4割の削減に成功したのです。
また、その一方ではGoogleが2012年に「ディープラーニングによってAIが自動的に猫を認識する技術」(大量のYouTube画像をディープラーニングに見せたら、何も教えていないのにAIが自分で猫の顔を見分けられるようになった」という実験)を発表し、大きな注目を集めました。このように、ディープラーニングは画像認識という領域において大きな成果をあげており、その能力の高さを能力の高さも世界に見せつけています。
その後、ディープラーニングは画像認識以外の領域にも急速に広がり、そして、2016年にはアルファ碁が登場したことで第三次AIブームを決定づけました。近年では、産業界においてもディープラーニングを活用した画像認識が、製造、医療、小売などさまざまな分野で実用段階に入りつつあります。

画像認識にはさまざまな種類があり、解決したい課題によって適した技術が異なります。以下では、代表的な6つの技術を紹介します。自社の課題に近いものがあれば、該当する活用事例のセクションも合わせてご覧ください。
コンピュータ上で行われる画像認識は、人間の脳とは仕組みが異なります。人間のように「視覚」で認識するのではなく、オブジェクトの抽出やピクセルデータの処理といった複雑な処理が必要になるのです。
そんな画像認識は、画像の種類によって対象物の「形状」「色」「複雑さ」「データ数」などで差が生じることから、画像認識はいくつかの種類に分けられています。つまり、扱う画像データによって技術領域を分類しているということです。では、具体的にどのような種類が存在するのでしょうか。ここからは、画像認識の種類と機能を見ていきましょう。
コンピュータによる画像認識は、人間の視覚とは異なり、ピクセルデータの処理によって行われます。対象物の「形状」「色」「複雑さ」などによって適した技術が異なるため、画像認識はいくつかの種類に分けられています。
 (参照:ImageNet Classification with Deep Convolutional Neural Networks)
(参照:ImageNet Classification with Deep Convolutional Neural Networks)
物体認識(物体識別)とは、対象の物体と同一の物体が画像内に存在するかどうかを検証する技術のことです。画像に映っている物体のカテゴリを特定するなど、画像に含まれている物体の情報を抽出することができます。この物体認識においては、「物体検出」という技術が重要視されており、物体認識と物体検出はそれぞれ区別して使用されます。
→ 製造業の外観検査、小売業の商品識別、物流の検品作業などで活用されています。「製品の種類を自動で判別したい」「正しい商品かどうかを確認したい」という課題をお持ちの方におすすめの技術です。
 (参照:You Only Look Once: Unified, Real-Time Object Detection)
(参照:You Only Look Once: Unified, Real-Time Object Detection)
物体検出とは、画像内に含まれる対象の物体の位置を検出するための技術です。物体認識とは実行方法が異なりますが、対象となる物体の特徴を抽出する際に、その物体の「位置」も重要になるため、物体認識と併用されるケースが多いです。
→ 自動運転の障害物検知、監視カメラでの不審者検出、工場ラインでの位置ずれ検査などで活用されています。「どこに何があるかを把握したい」という課題に適しています。
 (参照:Show and Tell: A Neural Image Caption Generator)
(参照:Show and Tell: A Neural Image Caption Generator)
画像キャプション生成とは、入力した画像内に何が映っていて、映るものがどのような状況かを判別し説明文を出力するものです。CNNと自然言語処理(RNN)を組み合わせたもので、Microsoftが開発する視覚障碍者向けのカメラアプリ「Seeing AI」などで活用されています。
→ アクセシビリティ支援、画像の自動タグ付け、コンテンツ管理などで活用されています。「画像の内容をテキストで説明したい」という場面に適しています。
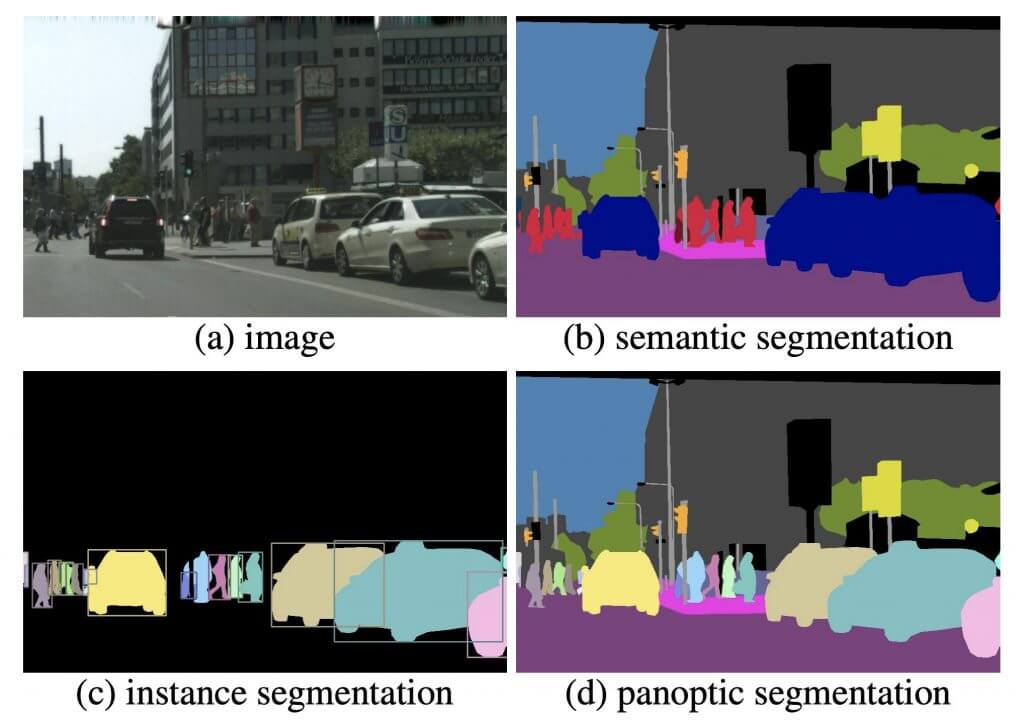
セグメンテーションとは、画像のピクセル(画素)ごとに「どの物体クラスに属するか」という基準で分類していくタスクを指します。画像全体を対象にするセマンティックセグメンテーション、物体検出した領域を対象にするインスタンスセグメンテーション、画像全体を対象に個々の物体はそれぞれ分離して背景などはひとまとめにするパノプティックセグメンテーションなど様々な手法があります。
→ 医療画像診断(腫瘍の範囲特定など)、自動運転の道路認識、農業の作物生育分析などで活用されています。「画像内の特定領域を正確に切り分けたい」という高精度な分析が必要な場面に適しています。

顔認識(顔認証)とは、人間の顔画像から目立つ特徴を抽出していく技術です。この技術を利用することによって、顔の識別を行ったり、似た顔の検索を行ったり、顔のグループ化を行ったりすることができるようになります。
→ 出入国管理や入退室管理、本人確認、マーケティングでの属性分析などで活用されています。「人物の特定や認証を自動化したい」「来店客の属性を把握したい」という課題に適しています。
また、最近では人間の表情から感情を読み取る「感情認識」の研究も進められている状況です。

文字認識(OCR)は、紙に書かれている手書きの文字や、印刷された文字などを判別する技術です。この技術を用いれば、画像内のテキストを抽出することができるようになります。文字認識は古くから研究が行われている分野ですが、最近では翻訳技術と組み合わせたシステムが登場するなど、さまざまな利用用途が存在する技術でもあります。
→ 請求書・帳票の自動読み取り、名刺管理、翻訳アプリなどで活用されています。「紙の書類をデータ化したい」「手書き文字を読み取りたい」という業務効率化に適しています。
このセクションでは、画像認識モデルがどのように動作するかの技術的な仕組みを解説します。導入検討の段階では詳細まで理解する必要はありませんが、ベンダーとの打ち合わせや社内説明の際に役立つ基礎知識です。
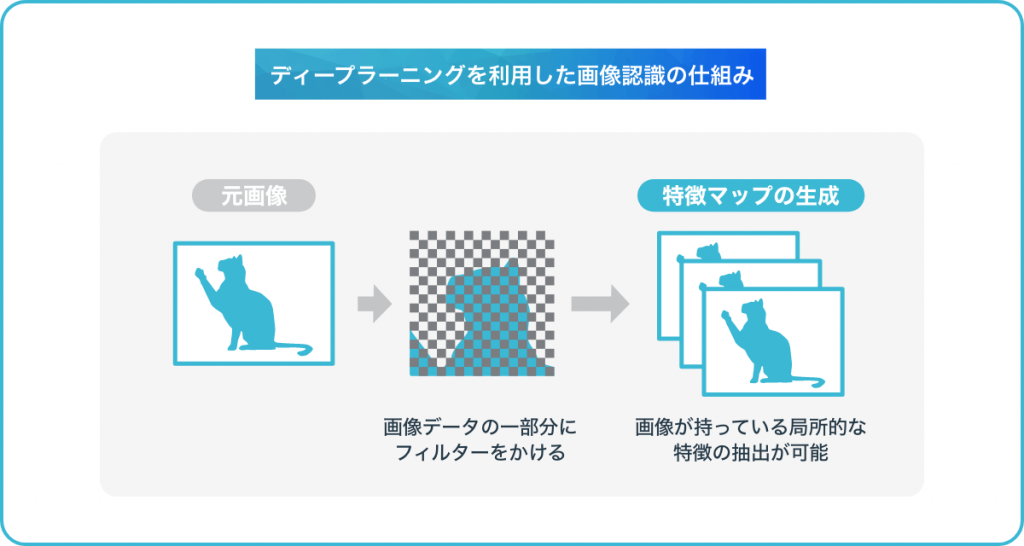
画像認識では、CNN(畳み込みニューラルネットワーク)というネットワークモデルが頻繁に使用されます。このニューラルネットワークは、人間の脳内の神経回路網を表したニューラルネットワークの発展版であり、画像のピクセルデータを人間が抽象ベクトルに変換することなく、画像データのままの状態で特徴を抽出させるという特徴があります。
CNNではそんな畳み込みニューラルネットワークでは、初めに画像データの一部分にフィルターをかけて演算し、その領域のスライドを繰り返していく「畳み込み」を行って特徴マップの生成を行います。この処理を行うことで、画像が持っている局所的な特徴の抽出が可能になるのです。
そして、コンピューターは画像の特徴を繰り返し抽出して対象物の推測を行い、同時に正解データで答え合わせをしながら学習を重ねることで、画像認識の精度が向上していくわけです。このような多層化されたニューラルネットワークの学習の仕組みを「ディープラーニング」と呼んでいます。
超解像と呼ばれるノイズの多い画像を高解像度にする手法にはGAN(敵対的生成ネットワーク)と呼ばれる深層生成モデルが利用されています。
このセクションは、自社でAIモデルを開発したい方、エンジニアを採用・育成したい方に役立つ内容です。
近年、画像認識などをはじめとするAIのプログラミング言語は、Pythonが主流になってきています。Pythonとは、少ないコードで簡潔にプログラムを書くことができるという特徴があり、専門的なライブラリが豊富にあることも魅力のひとつです。そんなPythonは、コードを書きやすく、かつ読みやすくするために生まれたプログラミング言語でもあるため、誰が書いても同じようなコードになります。
また、PythonはWeb上にも数多くのPythonライブラリが存在しています。既存のライブラリを活用することによって、自分が作りたいプログラムを作成できるのは大きなメリットといえるでしょう。また、Pythonによって開発されたアプリケーションの代表例としては、YouTube、Instagram、DropBox、Evernoteなどが挙げられます。
なお、Pythonは機械学習を用いたソフトウェアの開発分野で多く活用されており、初めて機械学習を学ぶ人でも習得しやすい傾向にあるため、「機械学習の基本を学ぶ際の「基本のプログラミング言語」とも言われています。
Pythonで画像認識を学ぶ際によく利用されるのが「Pythonの画像処理100本ノック」です。これは、画像処理の基礎から応用まで100問の演習形式で学べるオープンソースの学習教材で、GitHub上で無料公開されています。実際に手を動かしながら学べるため、独学で画像認識の基礎を身につけたいエンジニアに人気があります。
その中でも「Pythonの画像処理100本ノック」は多くの人に利用されており、集中的に機械学習を学ぶことができるものとして重宝されています。Pythonの100本ノックには、ライブラリにフォーカスしたものやデータ分析などの目的からまとめたものなど、さまざまな種類があるため、自身の目的に合ったものを選択すると良いでしょう。
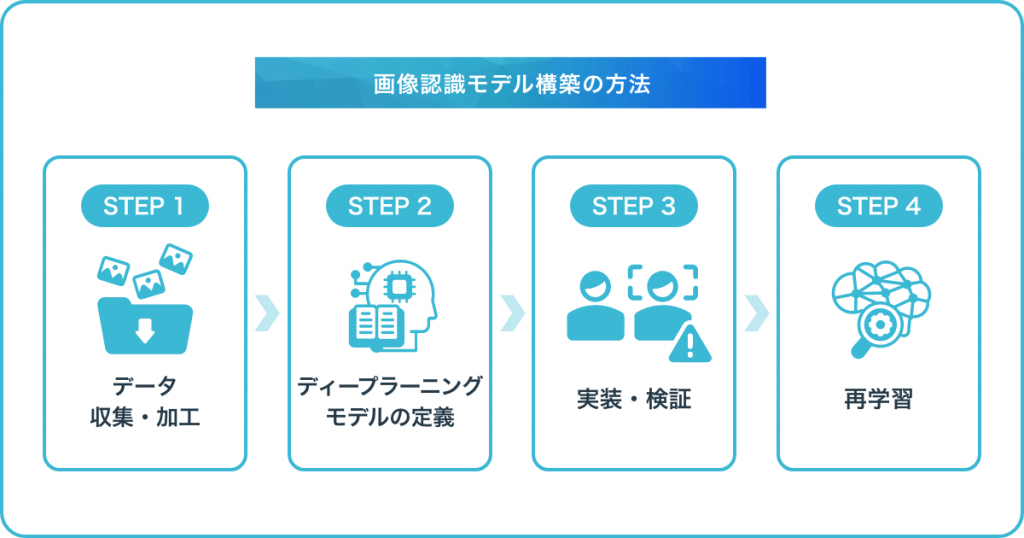
「画像認識モデルを導入したいが、何から始めればいいかわからない」という方に向けて、導入の流れを解説します。自社開発・外部委託のいずれの場合でも、基本的なステップは共通です。実際に画像認識モデルを構築していくためには、まず適切な方法と手順を把握しておくことが重要になります。ここからは、画像認識モデル構築の方法を、手順ごとに詳しくみていきましょう。
機械学習を行わせる上では、データの収集・加工が必要不可欠です。大量の画像データをコンピュータに読み込ませることで、初めて機械が学習を行えるため、最も重要な工程といっても過言ではありません。
また、単純に大量の画像データを収集すれば良いわけではなく、データの「質」にもこだわる必要があります。「量」と「質」のいずれかが欠けてしまうと、理想的な画像認識の精度を実現できなくなってしまうため、注意しましょう。
【ポイント】データ収集の目安 :ディープラーニングで学習する場合、1クラスにつき5,000件程度のデータがあればまずまずのパフォーマンスが発揮されますが、人間レベルの精度を求めるとすると約1,000万件という大規模なデータが必要です。ただし、後述する転移学習を活用すれば、より少ないデータでも高い精度を実現できる可能性があります。また、画像に「これは何か」を示すラベルを付ける「アノテーション」作業が必要ですが、AIプロジェクトに費やされる時間の約80%がこのデータ準備作業に充てられるとも言われており、時間とコストがかかるため、外部サービスの活用も検討しましょう。
データの収集や加工を終えたら、次にディープラーニングモデルの定義を行います。Tensorflow(Keras)を用いて画像認識モデルを構築する場合であれば、dataset.npyという数値配列からなるトレーニング・テストデータの作成後、そのdataset.npyを読み込み、畳み込みニューラルネットワーク(CNN)のモデルを学習・評価していきます。
【ポイント】モデル選定のコツ: ResNet、VGGなど、すでに高い性能が実証されている学習済みモデルを活用し、自社のデータで追加学習させる「転移学習」という手法があります。事前学習済みのモデルから知識を転移することで、ラベル付けされたデータが少なくても学習を行うことができます。
データの前処理を終えたら、画像認識モデルの実装・検証を行っていきます。画像認識モデルには、得意な分野・不得意な分野が存在するため、目的に合わせて適切なモデルを選択することが大切です。画像認識を得意とするモデルを選択したら、適用するパラメータを設定していきます。
そして、モデル構築を終えたら検証を行いましょう。たとえば、画像データを「学習用」「テスト用」に分類し、テスト用の画像を想定通りに読み取ってくれるかどうかを評価していくことで、改善点を明確化しやすくなります。
検証結果を踏まえて、必要に応じた再学習を行うことも重要な作業の一つです。浮き彫りになった改善点を解消していくことで、より理想的な画像認識モデルを構築できるようになるため、検証と再学習は必要不可欠な工程といえるでしょう。
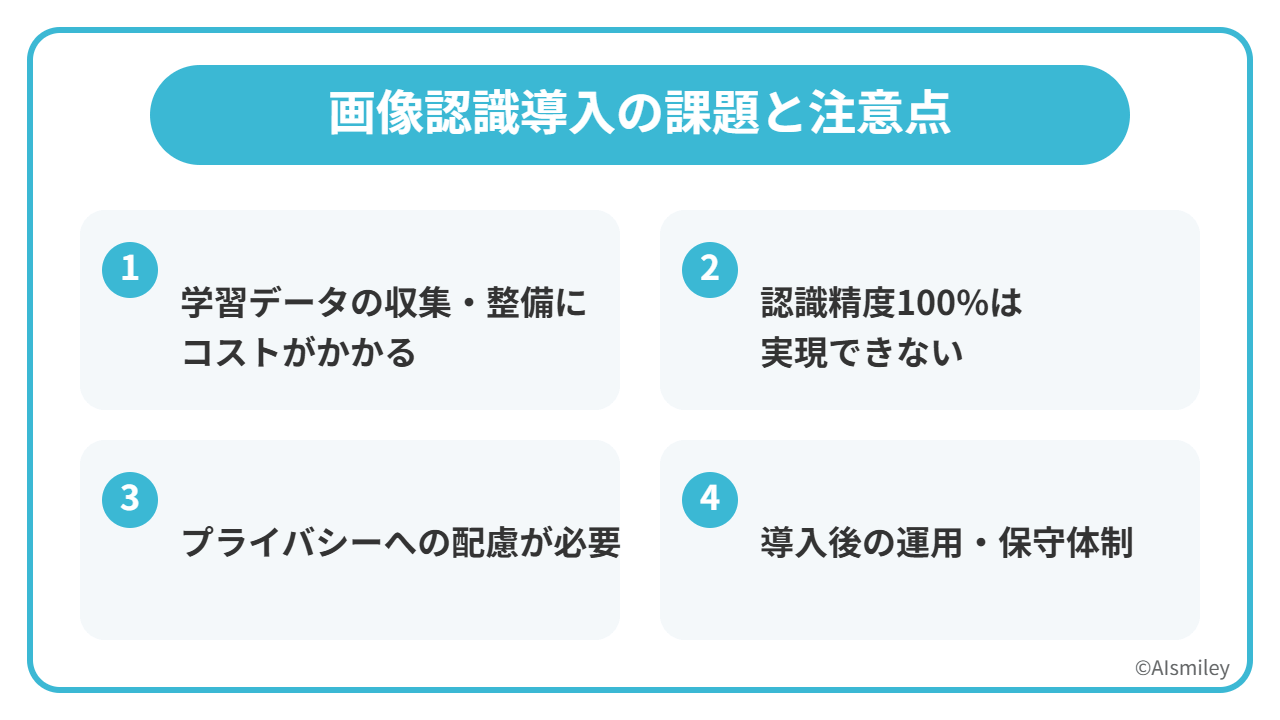
画像認識モデルの導入を検討する際には、期待できる効果だけでなく、事前に把握しておくべき課題もあります。ここでは、導入前に知っておきたい主な課題と、その対策について解説します。
画像認識モデルの精度は、学習に使用するデータの質と量に大きく依存します。十分な量の画像データを集め、それぞれにラベル(正解情報)を付ける作業は、想像以上に時間とコストがかかります。
既存の画像資産を活用:過去に撮影した検査画像や製品写真などがあれば、それを学習データとして活用できないか検討しましょう。
アノテーション外部サービスの利用:ラベル付け作業を専門に行うサービスを活用することで、社内リソースを節約できます。
転移学習の活用:少ないデータでも精度を確保できる転移学習という手法を検討しましょう。
どれだけ高性能な画像認識モデルでも、認識精度100%を達成することは現実的ではありません。照明条件の変化、対象物の汚れや破損、想定外の角度など、さまざまな要因で誤認識が発生する可能性があります。
許容できる精度の明確化:導入前に「どの程度の精度があれば業務に支障がないか」を明確にしておきましょう。
人間によるダブルチェック体制:重要な判断については、AIの結果を人間が確認するフローを設けることも有効です。
誤認識時のリカバリー手順:万が一の誤認識に備えて、リカバリー手順を事前に決めておきましょう。
顔認識や人物検知など、人を対象とした画像認識では、プライバシーへの配慮が不可欠です。個人情報保護法や業界ガイドラインに沿った運用が求められます。
利用目的の明示:カメラで撮影することや、その目的を利用者に明示しましょう。
データの適切な管理:収集した画像データの保存期間、アクセス権限、廃棄方法などを明確に定めましょう。
必要最小限のデータ収集:目的を達成するために必要な最小限の情報のみを収集するようにしましょう。
画像認識モデルは「導入して終わり」ではありません。運用開始後も、精度のモニタリング、モデルの再学習、システムのメンテナンスなど、継続的な対応が必要です。
運用体制の事前構築:誰がどのように運用・保守を担当するか、導入前に決めておきましょう。
ベンダーサポートの確認:外部サービスを利用する場合は、導入後のサポート体制(問い合わせ対応、アップデート頻度など)を確認しましょう。
定期的な精度評価:月次や四半期ごとに精度を評価し、必要に応じてモデルを更新する仕組みを設けましょう。
これらの課題を踏まえた上で、自社の状況に合った導入計画を立てることが重要です。不安な点があれば、まずは専門家に相談することをおすすめします。

「画像認識ってどんなものか、まずは体験してみたい」という方に向けて、無料で試せるアプリを紹介します。
画像認識は私たちにとって身近な存在になりつつあり、最近では画像認識を使ったフリーソフトや顔認証を用いた無料アプリなどもリリースされています。その一つとして挙げられるのが、「AI Stylist」というアプリです。
AI Stylistは、ヘアサロン「Hair&Make EARTH」を展開している株式会社アースホールディングスが提供しているAI搭載型のアプリです。この「AI Stylist」は、画像認識技術を用いることで、ユーザーに最適な髪型をアプリが提案してくれるというものです。その使い方は、ユーザーはヘアスタイルなどを選択して自分の顔写真をスマートフォンで撮るだけなので、とても簡単です。
2020年3月にiOS版がリリースされ、2020年8月にはAndroid版もリリースされました。2021年にはヘアスタイルを試せるシミュレーション機能も追加され、2023年1月時点で累計100万ダウンロードを突破しています。髪型シミュレーションアプリのおすすめランキングでも常に上位に入るなど、多くのユーザーに利用されています。2020年3月にiOS版が先立ってリリースされ、すでにダウンロード数が5万を突破するなど、多くの注目を集めています。2020年8月にはAndroid版もリリースされたため、今後さらに多くのユーザーが活用するようになるのではないでしょうか。
この「AI Stylist」は髪型の提案だけではなく、似ている芸能人を判定する機能なども備わっています。比較対象はモデルや歌手、タレントなどで、男性557人、女性949人のデータが用意されているそうです。
今後は、これらの機能に加え、髪型を試すことができる「ヘアスタイルシミュレーション」という機能も実装される予定だといいます。
まずは無料で画像認識技術を体験してみてはいかがでしょうか。
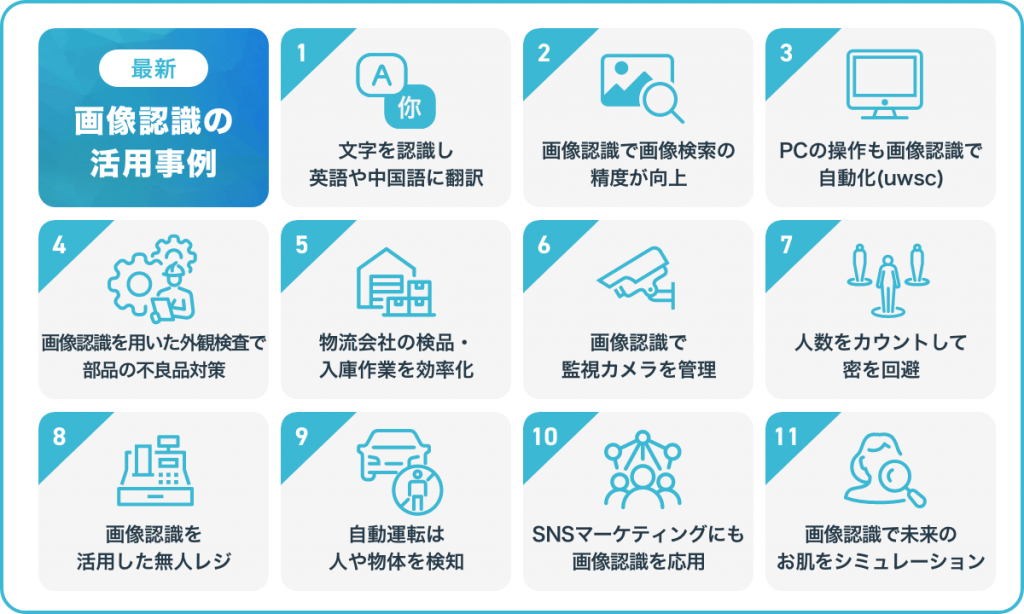
最近ではさまざまな分野で画像認識が活用されていますが、具体的にどのような場所で画像認識が活用されているのでしょうか。ここからは、最新の画像認識の活用事例についてご紹介していきます。
製造業の方 → 「外観検査で部品の不良品対策」
物流業の方 → 「物流会社の検品・入庫作業を効率化」
小売業の方 → 「画像認識を活用した無人レジ」「人数カウントして密を回避」
セキュリティ担当の方 → 「画像認識で監視カメラを管理」
マーケティング担当の方 → 「SNSマーケティングにも画像認識を応用」「属性分析や行動解析」
→ 多言語対応が必要な観光業、翻訳・通訳業、海外取引のある企業向けの活用事例です。
Google翻訳をはじめとする機械翻訳は、多くの方が一度は利用したことがあるのではないでしょうか。この機械翻訳は、自然言語処理によってできることのひとつです。「自然言語」とは、私たちが日常的な会話で使用している言語のことだと捉えていただければ問題ありません。
ちなみに、自然言語と相反する言語としては「コンピューター言語」というものがあり、「1+2+5」といったような一通りの解釈しか存在しないようなものは、コンピューター言語に該当します。
一方の自然言語には、複数の解釈ができるケースも少なくありません。例えば、「A君は自転車で帰宅中のB君を追いかけた」という文章があったとします。この場合、「A君は自転車に乗り、帰宅中のB君を追いかけた(自転車に乗っているのは
A君)」という解釈をすることもできますし、「A君は、自転車に乗って帰宅中のB君を追いかけた(自転車に乗っているのはB君)」という解釈をすることもできるわけです。
このように、自然言語は複数の解釈ができることから、これまでは適切な形で処理を行うことが難しいとされてきました。しかし、近年はAI(人工知能)の技術が発展したことにより、非常に高い精度で自然言語処理を行えるようになってきているのです。そして、最近では音声合成や文字認識と組み合わせたサービスも増えています。 多くなってきています。
例えば、「あなたは将来、進歩した自然言語処理の技術を実感することになるでしょう」をという日本語を英語に訳した場合には、「In the future, you will experience advanced natural language processing techniques.」となります。
しかし、この「In the future, you will experience advanced natural language processing techniques.」という文章をもう一度和訳すると、「将来的には、高度な自然言語処理技術が体験できます。」という文章になるのです。
私たち日本人は主語を省略することが多く、一般的な会話の中で「あなたは~するでしょう」という話し方はあまりしません。といった言葉の使い方をするケースは多くありません。Google翻訳はそれを理解した上で、対象言語においてより一般的な表現に近い言葉に置き換えることができているのです。これは、AIの技術によって的確に文脈解析と意味解析が行われ、 適切な解釈のもとで自然言語処理に基づいた精度の高い翻訳が可能になりました。
また、Googleの翻訳アプリには、カメラを文章にかざすだけで別の言語に自動翻訳する機能が搭載されています。これも画像認識技術によって実現されたものです。こうした技術の進化により、言語の壁は今後ますます低くなっていくでしょう。

→ ECサイト運営、小売業、ファッション業界など、商品検索の改善を検討している方向けの活用事例です。
Eコマースの世界的大手、中国のアリババ・グループは、早くからオンライン通販サイトに画像認識技術を取り入れています。
アリババの通販サイトである「淘宝(タオバオ)」や「天猫(Tmall)」では、欲しい商品の写真をアップロードすると、サイトに掲載されている膨大な商品の中から類似商品のものを検索することが可能です。
アリババによると、Eコマースプラットフォームに関するユーザーのクレームは、 ひとつは「欲しいアイテムを見つけるのが困難」、もうひとつは「アイテムが豊富すぎて混乱する」の2つに集約されるといいます。そのため、自分の欲しい商品写真をアップロードするだけで類似商品を探し出すことができる画像検索は、こうしたユーザーのクレームを解決する手段として極めて有効なものといえるでしょう。
この技術を支えているのは、機械学習とディープラーニングを活用したアリババ独自の画像検索エンジン「Image Search」です。アリババは2009年に画像認識や文字認識を研究する研究所、図像和美研究団を自社内に設立し、人工知能による商品検索アルゴリズムを開発しています。
→ 事務作業の自動化、RPA導入を検討している方向けの活用事例です。
VBAを用いて、Excel作業をマクロ実行で効率化することは一般的ですが、画像認識を活用すれば「特定の画像が現れたらその画像を自動でクリックする」といったPC操作の自動化も可能になります。「UWSC」というパソコンのキーボード・マウス操作を自動化するソフトを使えば、PCによる画像の自動クリックを実現可能です。
複雑な自動化処理を行うためには知識と経験が必要になりますが、普段行なっている程度の単純な作業であれば、比較的簡単に自動化できます。この「UWSC」を用いた自動化も、簡単に設定できますので、画像認識による自動クリックを実現したい方は、ぜひ試してみてはいかがでしょうか。
 外観検査AIカオスマップを公開!製造業で導入進む104サービスをまとめました
外観検査AIカオスマップを公開!製造業で導入進む104サービスをまとめました
→ 製造業の品質管理担当者、検査工程の自動化を検討している方向けの活用事例です。
目視検査の人手不足解消、検査精度の向上、検査スピードの向上といった課題に対応できます。画像認識技術を活用すれば、製造業などの外観検査の自動化や高精度化が可能になり、より高い精度で部品の品質を維持できるようになります。
画像認識を用いた外観検査の仕組みは、以下の通りです。
検査対象が静止状態の場合には写真データを活用し、検査対象が動いている場合には撮影データを活用します。取得する画像の精度は、自動検査の精度にも大きな影響を与えるため、検査対象として相応しい「高精度の画像」を撮影することが重要です。
検査対象に合わせて適切な画像処理を施していきます。目的に合わせて適切な情報を抽出できるよう、画像データをフィルター処理するのが一般的です。さまざまな処理方法が存在しますが、代表的なものとしては「ノイズ除去」「明るさ調整」「エッジ強調」「コントラスト調整」などが挙げられます。
取得した画像をもとに、検査対象のどこに、どのような異常項目が存在しているのかを自動で特定していきます。一般的な外観検査システムの場合、「色」「周囲との色の違い」「大きさ」「形」といったモデルルータをもとに、検査対象項目に応じた判定ロジックを用いて特定していくという流れです。
 SCM改革!AIを活用したサプライチェーン最適化カオスマップ!小売・物流・製造業必見!
SCM改革!AIを活用したサプライチェーン最適化カオスマップ!小売・物流・製造業必見!
→ 物流業・倉庫業の方、EC事業者で出荷作業の効率化を検討している方向けの活用事例です。検品時間の短縮、ヒューマンエラーの削減、人手不足の解消といった課題に対応できます。
物流には、物を移動させる業務だけでなく、そのプロセスとなる包装や保管といった業務も含まれます。そのため、倉庫への入庫作業なども物流に該当します。
その倉庫への入庫作業においては、これまで人の目で商品のパッケージやタグなどを確認しなければならず、さらにその商品名や型番などを倉庫管理システムに入力する作業も、人が行っていました。
しかし、最近ではAIの画像認識技術を活用したシステムが積極的に導入され始めており、この一連の業務の大幅な効率化を実現しました。具体的には、人間による目視とシステム入力作業を自動化させることで、検品業務を半分以下の時間で実施できるようになりました。

→ セキュリティ担当者、施設管理者、イベント運営者向けの活用事例です。不審者の早期発見、監視業務の効率化、インシデント対応の迅速化といった課題に対応できます。
画像認識技術は、セキュリティ強化という側面でも積極的に活用され始めています。その具体的な事例としては、以下のようなものが挙げられます。
車両種別の判別では、AIを活用し、防犯カメラに写っている自動車の画像から車種を割り出していきます。
各メーカーの車の画像データをAIに学習させることで、より高い精度での判別が可能になりました。画像認識モデルの技術の進化により、多少画像が不鮮明であっても車のタイプや車種、年式などを判別できるようになりました。できるようになるという点は、画像認識モデルの技術の進化によるメリットといえるでしょう。
大規模なイベントなどでは、どうしても人の目が届かないエリアが出てきてしまいます。そのため、画像認識モデルを搭載した防犯カメラを活用してイベント会場全体を監視することで、イベントでの不審点の抽出を高精度で実行できます。
実際、2019年には、警視庁による実証実験も行われており、その実験では会場内外に設置された防犯カメラが捉えた映像の中から不審と思われる点を自動的に探り、発見していくという検証が行われました。この実験は、コンサートやスポーツ大会、会議といった大規模なイベントを想定しており、過去に欧米で発生したテロのデータも利用しテロリストが取ると考えられる行動の特性についてもAIに学習させていくそうです。また、この実験では過去に欧米で発生したテロのデータも利用していくことを検討しています。
最近ではAIの処理をクラウドではなくデバイスで行うエッジAIの活用も進んでいます。
→ 小売業・商業施設の運営者、イベント会場の管理者向けの活用事例です。来客数の把握、混雑予測、店舗オペレーションの最適化といった課題に対応できます。
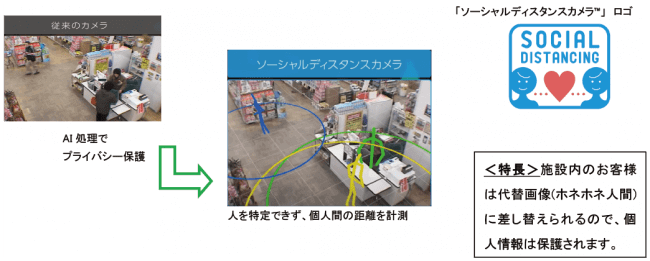
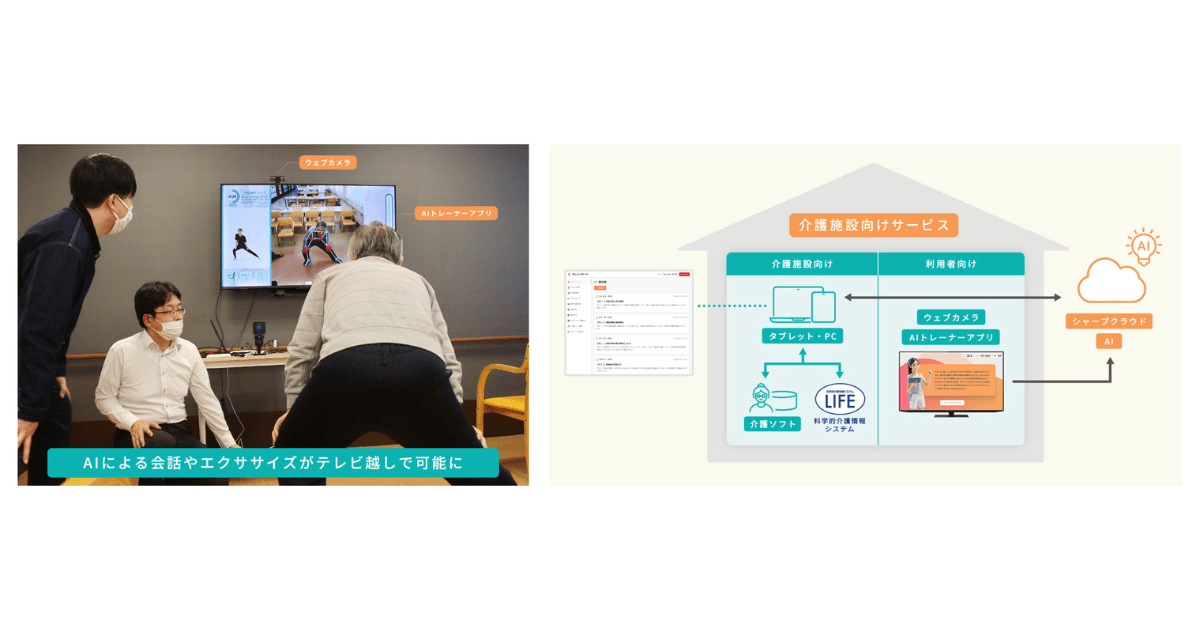
昨今は新型コロナウイルスの感染拡大に伴い、ソーシャルディスタンスが重視されるようになりました。そのような中で、いわゆる「3密」を避けるための手段に画像認識が有効活用され始めています。画像認識技術は、施設内の人数カウントや混雑状況の可視化にも活用されています。その事例として挙げられるのが、アースアイズ株式会社(本社:東京都港区)と日商エレクトロニクス株式会社(本社:東京都千代田区)が販売している「ソーシャルディスタンスカメラ™」です。
この「ソーシャルディスタンスカメラ™」は、AIカメラの3D空間認識技術(画像認識技術)によって施設内外の人数を認識したり、人と人の距離を認識したりして、混雑レベルを可視化します。「ソーシャルディスタンスカメラ™」が導入されている施設の利用者(顧客)は、スマホなどから混雑レベルをチェックできます。施設内の混雑状況を把握した上で訪問するかどうかを判断できるため、店舗側だけでなく施設の利用者にとっても非常に大きなメリットがあるといえるでしょう。
このような混雑可視化技術は、イベント会場での来場者管理、商業施設での来客分析、交通機関での混雑予測など、さまざまな場面で活用されています。タイムリーに混雑状況を把握できる仕組みは、顧客体験の向上や運営効率化に大きく貢献しています。
特に、スーパーマーケットやドラッグストア、コンビニエンスストアなど、生活に欠かせない日用品が販売されている店舗に関しては、「絶対に3密を避けたい」と考えている人でも訪れなければならないケースがあるかもしれません。そのような場合、タイムリーに混雑状況を把握できる仕組みが存在するかどうかという点は、その店舗や施設への信頼度にも大きな影響を与えてしまう可能性があるでしょう。
「ソーシャルディスタンスカメラ™」の具体的な仕様イメージとしては、300坪ほどの小売店であれば、メインとなる通路3箇所程度に「ソーシャルディスタンスカメラ™」を設置することで人の密集レベルを可視化することが可能になります。設置されたAIカメラが人と人の距離のデータを解析して、ホームページや責任者のスマホなどに「密集レベル」として通知するという仕組みです。
また、出入り口にもAIカメラを設置しておけば人数カウントを行うことができるため、混雑予測なども高精度に予測することができます。最近では、この人数カウントを効率的に行えるカウントアプリも増えています。来店客数の把握や混雑予測が求められる小売店などにとって、これまで3密になりがちだった小売店などは、顧客が安心して来店できる環境を整える必要があり、密集レベルを可視化できるAIカメラには大きなメリットがあるといえるのではないでしょうか。
→ マーケティング担当者、店舗開発担当者向けの活用事例です。顧客属性の把握、購買行動の分析、店舗レイアウトの最適化といった課題に対応できます。
属性分析や行動解析といった観点でも、画像認識は有効活用されています。その代表例として挙げられるのが、JR東日本駅構内のオンライン接客です。
これは、Idein株式会社が提供するAIカメラ「Actcast」と、シスコシステムズ合同会社が提供するWeb会議システム「Webex」を組み合わせることで、オフラインとオンラインが融合した新たな購買体験が実現できるというものです。
具体的には、AIカメラを活用してJRE MALL Meetに来店する人数を把握したり、顧客の属性分析を行ったり、JRE MALL Meetに設置されているサイネージや商品の視認率の計測を行ったりします。
また、新たな取り組みとして、ビジネスチャットツール「Slack」と連携したことでも大きな注目を集めました。顧客が店舗に来店すると、オンライン接客の担当者にSlackで通知が飛ぶ仕組みで、よりスムーズなオンライン接客が実現できます。

昨今は少子高齢化に伴う人手不足が深刻化していて、スーパーやコンビニでは「無人レジ」が少しずつ導入され始めています。その一例として挙げられるのが、大手コンビニチェーンのローソンです。
ローソンでは、画像認識AIの活用によって無人レジ化を進める取り組みを行っています。AIに「来店した客の属性」「購入した商品」「手に取った商品」などの情報を学習させることで、発注や在庫管理の精度向上につなげていくのが狙いです。また、収集したデータをマーケティング分析に活用していくことも可能になります。
店内の案内に関しては「デジタルサイネージ」と「コンシェルジュロボット」によって行われ、おすすめ商品の案内などもロボットに任せられます。
現段階では一部のローソンでしか導入されていませんが、近年はコンビニ業界の人手不足が問題視されていますので、今後全国的に無人レジ化が広がっていく可能性も少なくないでしょう。
ローソンの他にも画像認識を活用したAIレジの普及が進んでいます。

自動運転とは、その名の通り「自身で操作を行うことなく自動車が勝手に走ってくれる技術」のことです。自動車に乗り込み、搭載されているAIに目的地を告げるだけで、自動車が勝手に出発してくれるので、人間がハンドル操作を行う必要はありません。
とはいえ、現時点ではまだ自動運転車が多く普及されているわけではないため、「自動運転車なんて不安で仕方ない」と思われる方も多いでしょう。確かに自動運転技術は決して完璧なものではなく、死亡事故を起こした事例も存在します。しかし、人間による運転と比べれば、はるかに安全なものになっているのです。
運転席に座った状態の人間の視野にはいくつかの死角が存在するため、その部分を確実に把握することはできません。もちろんドアミラーやバックミラーを使ってある程度の死角を解消することはできますが、それでも視認できない部分が多数あります。
では、完全には見えていない部分があるにも関わらず、なぜ大半の人は自動車を走らせることができているのでしょうか。それは、「その場所が死角になる前に『なにもないこと』を把握(記憶)しているから」に他なりません。つまり、若干ではあるものの、過去の情報を頼りに運転しているということです。
一方の自動運転車は、センサーや画像認識AIなどによって自動車周辺の情報をリアルタイムに把握しながら走行します。自動車周辺に障害物が存在しないかどうか、いわばリアルタイムで目視しながら走行しているわけです。当然、記憶を頼りに運転する場合と目視しながら運転する場合では、後者の方が安全性は高くなります。
何より、人間は見ている方向以外の視覚情報を拾うことはできませんが、自動運転車はセンサーや画像認識によって全方向の視覚情報を拾うことができるのです。こういった点を踏まえれば自動運転車のほうが高い安全性であることがお分かりいただけるのではないでしょうか。
最近では、SNSマーケティングにも画像認識技術が積極的に活用され始めています。SNSマーケティングへの活用と言われてもあまりイメージが湧かないかもしれませんが、一例としては「ユーザーデータの抽出による分析」が挙げられるでしょう。
これまで、SNSマーケティングにおいて分析をする際は、テキストからさまざまな分析を行っていくのが一般的でした。しかし、画像認識技術を活用すれば、テキストだけでなく画像や動画からもさまざまな情報を得ることが可能になります。また、メインの被写体だけでなく、背景に映り込んだ景色や別の被写体データなどからもユーザーデータを抽出できるようになるため、より細かな分析を行えるようになるのです。
より細かなターゲッティングを行いたい企業にとって、画像認識技術を用いたマーケティングは有効なものといえるのではないでしょうか。

東京都品川区に本社を置くオルビス株式会社では、現在の肌状態やお手入れ習慣から未来の肌状態を予測して、いま必要なお手入れ方法を提案する「AI 未来肌シミュレーション」というサービスを提供しています。このサービスには、東京都品川区に本社を置くフューチャーアーキテクト株式会社の深層学習、画像認識技術が活用されています。
この「AI 未来肌シミュレーション」は、店舗に設置されているオルビス社独自のスキンチェック機やスマホを活用してAIが現在の肌状態を分析し、10項目の肌スコアを測定するというもの。そして、現在のお手入れ状況や生活習慣などをもとに、5年後、10年後、20年後の肌を予測するという仕組みです。
複雑な美容理論を学習しているため、20兆以上の評価パターンから一人ひとりの肌トラブル進行パターンを導き出し、深層学習による顔画像生成によって未来の肌をシミュレーションできるという点は大きな特徴といえるでしょう。

今回は、画像認識の仕組みや活用事例について詳しくご紹介しました。さまざまな分野で画像認識が活用され始めており、これまで以上に高い精度での「分析」「予測」「効率化」といったものが実現できていることがお分かりいただけたのではないでしょうか。
最近では、カメラと併用することで人間以上の3D(三次元)物体認識を行える「LiDAR」、画像認識や音声認識などを複合的に処理することができる「マルチモーダル」なども実現され始めており、ますます技術レベルは向上しています。
こういった点を踏まえると、今後はよりさまざまな業界で画像認識技術が導入されていくことが予想されます。画像認識技術によってこの社会にどのような変化が生まれるのか、ますます目が離せません。
AIsmileyでは、画像認識サービスの利用料金・初期費用・無料プラン・トライアルの有無などを比較検討することができるカオスマップを無料でお配りしています。より最適なサービスを選択するための比較検討を簡単に行うことができますので、画像認識サービスの導入を検討の際は、ぜひお気軽にご活用ください。
2024/12/13
2024/12/9
2024/12/5
2024/11/5
2024/10/30
2024/10/24
2024/10/10
2024/10/1
2024/9/30
2024/9/25
2024/9/20
2024/9/11
2024/9/10
2024/9/5
2024/9/4
2024/9/3
画像認識技術として最も古いといわれているのは、1940年代に活用され始めた「バーコード」です。バーコードとは、バーとスペースの組み合わせによって、数字や文字を機械が読み取れるように表現したものを指します。
身近な例を挙げると、 無人レジ、車の自動運転、Instagramなどの製品に使われています。
画像認識などをはじめとするAIのプログラミング言語は、Pythonが主流になってきています。 Pythonとは、少ないコードで簡潔にプログラムを書くことができるという特徴があり、専門的なライブラリが豊富にあることも魅力のひとつです。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。















FOLLOW US
SNSをフォローして、最新情報をチェックできます!







AI製品・ソリューションの掲載を
希望される企業様はこちら