

生成AI

最終更新日:2026/04/06
 音声認識について解説
音声認識について解説
音声認識とは、人が話した音声をコンピューターが解析してテキストデータへ変換する技術です。
SiriやGoogle音声アシスタントなどの音声入力をはじめ、会議の文字起こしや議事録作成、ボイスボットなど、さまざまな場面で活用されています。
本記事では、音声認識の基本的な仕組みから、AIとの関係、活用例、最新サービス、導入時の比較ポイントまでをわかりやすく解説します。
音声認識について詳しく知りたい方は以下の記事もご覧ください。
音声認識とは?AIを使った仕組みや特徴をわかりやすく解説!無料製品や事例も紹介!
音声認識とは、人の発話をコンピューターが認識し、文字データとして出力する技術です。
英語では Speech Recognition や Automatic Speech Recognition(ASR) と呼ばれます。
身近な例としては、スマートフォンの音声入力や、オンライン会議ツールの字幕表示、動画の自動字幕生成などがあります。企業では、会議や商談の文字起こし、コールセンター業務、ボイスボット、医療現場の記録支援など、実務での活用も進んでいます。
音声認識は、あくまで音声を文字に変換する技術そのものを指します。
一方、音声アシスタントは、音声認識に加えて、意味の理解、検索、操作実行、音声応答などを組み合わせた仕組みです。
つまり、
という違いがあります。
混同されやすい技術として、話者認識があります。
音声認識は何を話したかを認識する技術ですが、話者認識は誰が話したかを識別する技術です
会議の議事録作成や通話分析などでは、音声認識と話者認識を組み合わせることで、より実用的な活用が可能になります。

現在の音声認識システムは、大きく従来型のパイプライン方式とEnd-to-End型の2つに分けて考えるとわかりやすいでしょう。
従来型の方式では、まず音声を分析して特徴を取り出し、その情報をもとに音素や単語を推定し、最後に文脈に合う文章へ変換していきます。この流れの中では、音響モデル、発音辞書、言語モデルなどを組み合わせて音声を文字にしていました。DNN-HMM型は、この従来型の音声認識に深層学習を取り入れ、認識精度を高めた代表的な方式です。
一方、近年主流になっているのが、音声から直接テキストを出力するEnd-to-End型です。従来のように複数の工程を明確に分けるのではなく、モデル全体で一体的に学習することで、高精度化や多言語対応、ノイズ耐性の向上が進みました。
現在は、Transformer系アーキテクチャや大規模事前学習モデルの影響を受けた音声認識も広がっています。Google Cloud は “latest” モデルや Chirp 3 を、最新世代の多言語ASRモデルとして案内しています。
音響分析とは、マイクに入力された音声を分析し、コンピューターが扱えるデータに変換する作業のことです。AIは、人間と同じように生の録音データから音声を認識することはできません。そのため、AIが認識できるようにデジタル化し、ノイズの除去まで行う必要があります。
そして、AIは音響分析によって抽出されたデータをもとに音声認識を進めていきます。
音響モデルとは、データ化された音声を蓄積した学習データと照らし合わせて、音の区切り(音素)を抽出する作業です。音素は「音声を発した際に観測される音波の最小構成要素」であり、日本語であれば母音(アイウエオ)、擬音(ン)、子音(23種類)の3つから成り立っています。
例えば、「こんばんは」から音素を抽出すると「k-o-N-b-a-N-w-a」に分解されます。ただし、音響モデルではあくまで音素への分解が行われるだけですので、適切なテキストを出力するには、後述する言語モデルが必要です。
従来は、数千人、数千時間の人間の声を統計的に処理した学習データを用いる統計的手法が中心でしたが、その後は深層学習を活用したモデルが普及し、認識精度が大きく向上しました。
言語モデルとは、単語群を文章化する作業です。
例えば、「こんにちは。今日は寒いですね。」という文章は、もともと「こんにちは」「今日は」「寒いですね」といった単語群で成り立っています。
これらを認識させるためにN-gramなどの統計的な手法が多く使われてきましたが、近年はニューラルネットワークやTransformer系モデルの活用が進んでいます。IBM も Transformer が音声認識で高い性能を示していると説明しています。
音響モデルによって抽出された音素の並びを組み合わせて、単語として構成していく際における「データベース」の役割を担っています。
例えば、「今日はいい天気ですね」という言葉を音素へ分解すると「ky-o-u-w-a-i-i-t-e-N-k-i-d-e-s-u-n-e」となります。
これらの音素を発音辞書に照らし合わせて連結することで「今日は」「いい」「天気」「ですね」という単語に変換され、「今日はいい天気ですね」というテキストが出力されます。
特に従来型の音声認識システムでは、音響モデルと言語モデルをつなぐ重要な要素として使われてきました。
言語モデルの手法として、主に「隠れマルコフモデル」「N-gram」の2種類が用いられています。
隠れマルコフモデルは、特定の単語の後にくる次の単語を確率で推定するための手法で、推定する単語は分析した膨大な量の日本語データから導き出されます。
例えば「私は」の後に続く言葉の確率が「楽しい(60%)」「苦しい(20%)」、「楽しい」に続く言葉が「です(70%)」「が(20%)」「よ(10%)」というように、現在の状態から次の状態に遷移する方法を定義します。
一度遷移した先から戻らないモデル(Left-to-Right HMM)と戻れるモデル(Ergodic-HMM)があり、言語モデルではErgodic-HMM が用いられることが少なくありません。
N-gramは、連続する単語や文字のまとまりを用いる手法です。「今日はいい天気です」をn=3(3-gram)の単語で区切る場合、次の3つの3-gramが含まれていると考えられます。
また、n=5の文字で区切る場合には、以下の5-gramが存在します。
このように、n-gramは文字や単語を単位とした繋がりから文字列を推測します。
音響分析→音響モデル→言語モデルの過程を経て、最終的に自然な文章と判断された結果がテキストとして出力されます。
ただし、実際の精度は音質・雑音・専門用語・話者数などによって左右されるため、必要に応じて辞書登録やカスタマイズ、再学習を行いながら改善していくことが重要です。
Azure Speech でも、Custom Speech による独自データのアップロードやモデル比較、デプロイが案内されています。

音声認識システムとして広がりつつある手法が「End-to-End型」で、従来の音声認識システムに比べシンプルな構造で音声のテキスト化できます。
従来の音声認識では音響分析・音響モデル・発音辞書・言語モデルといった複数の工程を組み合わせて最終的にテキストを出力していました。一方のEnd-to-End型は、こうした処理の多くを一体的に学習したモデルで扱うことで、音声から直接テキストを出力しやすくなっています。
従来型は、細かく制御しやすい一方で、各モジュールの誤差が積み重なりやすいという課題がありました。End-to-End型は構造を比較的シンプルにしやすく、モデル全体で最適化しやすいため、認識精度の向上や多言語対応、ノイズへの強さにつながっています。
近年ではTransformer系アーキテクチャや大規模事前学習モデルの影響を受けた音声認識も広がっており、Google Cloud は Chirp 3 を最新世代の多言語ASRモデルとして提供しています。
ディープラーニング(深層学習)を行うAIと音声認識を組み合わせることで、音声認識の精度はさらに高まっています。実際にどのような場面で音声認識が活躍するのか、例をいくつか見ていきましょう。
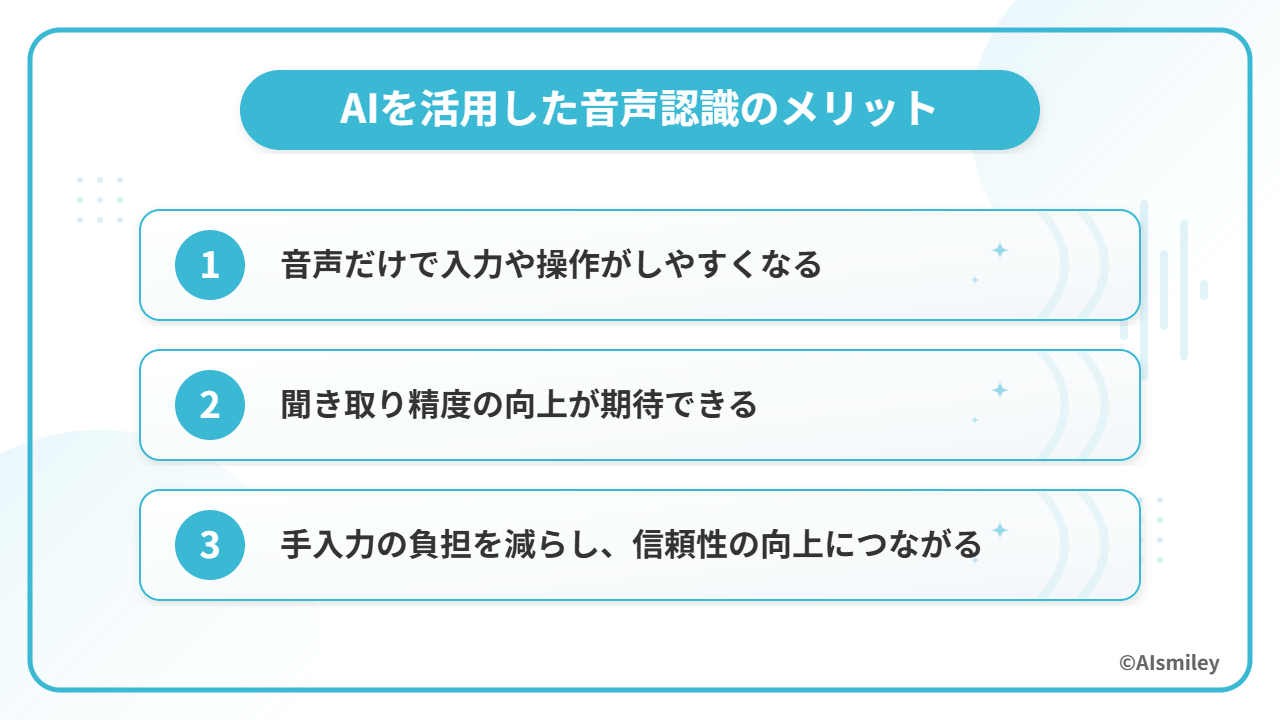
AIを活用した音声認識では、文字入力だけでなく、アプリの操作やコマンド実行、検索などを音声だけで行えるようになります。
キーボード入力が難しい場面やハンズフリーで操作したい場面との相性が良く、現場業務や移動中の利用にも向いています。
また、プログラミング言語「Python(パイソン)」のカンファレンスなどでは、講演者の発音を正しく理解して音声認識したAIがプログラミングコードを入力するといった使い方もされています。
空港や駅のターミナルのような、大声で話す人が周囲にいる環境では、多くの人の声が入り混じる中で正確に声を聞き取り、適切な回答を示すことが難しいのが現実です。
しかし、AIの活用によって、人間では聞き取るのが難しいような状況下においても正確に音を聞き分けられるようになります。さらに近年進歩を続ける音声認識では、深層学習や大規模学習モデルの進化によって、雑音環境や話し方のばらつきへの耐性が向上しています。
OpenAI は次世代の speech-to-text モデルについて、アクセント、ノイズ、話速の違いがある環境でも精度と信頼性が高いと説明しています。
データ入力・通話記録・会議記録などを自動化することで、手作業の負担を減らしつつ記録の抜け漏れ防止にもつながります。
特に、リアルタイム文字起こしやバッチ文字起こしを業務に組み込めば、議事録作成や通話記録の効率化を進めやすくなります。Azure Speech も、会議字幕、通話文字起こし、医療記録、動画字幕などを代表的なユースケースとして案内しています。
AIを活用した音声認識であれば、データ入力を自動化させるだけなく、その精度も高められるため、企業としての信頼性向上につなげられるでしょう。また、人の手による作業が必要なくなるため、人手不足という問題を抱える企業の「業務効率化」にも大きく貢献します。
AIにより音声認識システムは目覚ましい進歩を遂げ、あらゆる場面で活躍を見せるようになりました。一方で、技術的に発展途上であるため、まだまだ多くの課題やデメリットを抱えています。
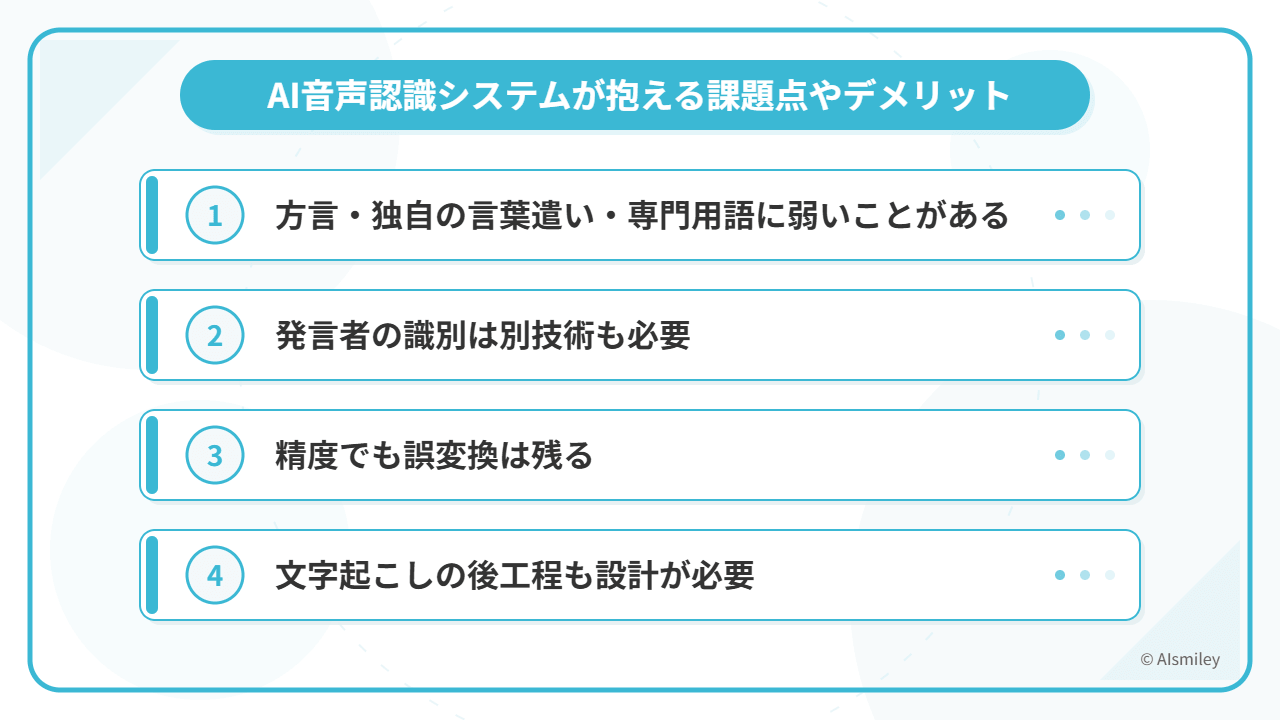
標準語への対応は大きく進んでいますが、方言・スラング・業界用語・若者言葉・社内独自の表現などでは、今でも誤認識が起こることがあります。
そのため、実運用では辞書登録やカスタムモデル、用語チューニングが重要になります。Azure Speech も、Custom Speech による精度改善を案内しています。
独自の言葉遣いへ正確に対応していくためには、一定の時間が必要です。今後、音声認識技術の発展と非頻出単語の学習が進むことで、より精度が上がると考えられます。
音声認識は「何を話したか」を文字にする技術ですが、「誰が話したか」を区別するには話者分離や話者認識の仕組みが必要です。これらは、事前に登録した生体データに基づく解析を行う方式と、音声処理アルゴリズムによって話者を区別する方式に分類されます。
前者は限定された状況下でしか利用できないため、一般向けのサービスではなかなか利用できません。後者は技術開発が進んでおり、今後多くのサービスへの導入が期待されています。
会議や複数人通話の文字起こしでは、話者分離の精度が使い勝手に大きく影響します。OpenAI の Audio API でも diarize 対応モデルが案内されています。
近年のモデルは高性能ですが、騒音、複数人発話、固有名詞、音質の悪い録音などでは誤変換が発生します。契約、医療、法務など正確性が重視される用途では、人による確認を前提にした運用が必要です。
最近は文字起こしだけでなく、要約、議事録整形、タスク抽出まで求められるケースが増えています。音声認識単体ではなく、生成AIやナレッジ活用と組み合わせた運用設計が重要になります。

深層学習や大規模モデルの進化によって、音声認識の精度は大きく向上しています。
その結果、音声認識は単なる文字起こし技術にとどまらず、以下のようにさまざまな場面で活用されるようになりました。
会議や商談、インタビューなどの内容を記録する議事録は、正確かつスピーディーに作成することが求められます。
手作業での文字起こしや要点整理には時間がかかり、担当者によって品質に差が出ることもあります。
最近では、AIを活用した音声認識によって会議音声を自動で文字起こしし、その後に要約やタスク抽出まで行えるツールも増えています。
社内会議の議事録作成、商談の記録管理、インタビューの文字起こしなど、会話内容を資産として活用したい業務は、音声AIを最も導入しやすい領域といえます。
この分野では、Microsoft Azureが提供するリアルタイムの会議字幕表示や、録音データの一括テキスト化(バッチ文字起こし)機能が、主要な活用シーンとして推奨されています。これらの技術を活用することで、手作業による膨大な書き起こし時間を削減し、情報の共有と管理を劇的に効率化することが可能です。
音声認識は、翻訳と組み合わせることで、多言語コミュニケーションの支援にも活用できます。
従来は通訳者を介して行っていたやり取りも、現在は音声認識+機械翻訳を組み合わせることで、よりスムーズに進めやすくなっています。
海外拠点との会議や外国人顧客への接客、複数言語が飛び交う同時通訳シーンでは、リアルタイム翻訳を備えた音声AIの活用が急速に広がっています。
この分野では、Microsoft Azureが提供する音声翻訳(Speech Translation)機能や、Google Cloudの最新多言語AIモデル「Chirp 3」などが代表的です。これらの高度な技術により、言葉の壁を感じさせない、きわめて自然でタイムラグの少ない多言語コミュニケーションが実現しています。
音声認識を活用して、電話応対そのものを自動化するのが「ボイスボット(対話型AI)」です。
これはユーザーの話した内容をAIが理解し、合成音声で返答することで、電話での自動応答を実現する仕組みです。最近では、単なる機械的なガイダンス(IVR)に留まらず、音声認識と生成AIを高度に組み合わせた「より自然な対話型AI」へと進化しています。
例えば OpenAI は、次世代の音声モデル(audio models)や Realtime APIを提供しており、人間と話しているかのような「タイムラグのない音声エージェント」の構築が可能になっています。
問い合わせ件数が多い企業においては、まずボイスボットが一次対応を自動で行い、複雑な内容のみを有人オペレーターへシームレスに引き継ぐ設計が効果的です。これにより、現場の業務負荷を大幅に軽減しながら、24時間365日の迅速な顧客対応を実現し、サービス品質の向上に大きく貢献します。
ただし、導入には一定のコストが必要です。初期費用数万、月額はプランにより5~50万円程度とされていますが、10件までは無料、1コールごとの費用設定がある場合など、利用したい件数によっては低額での利用も可能です。
ボイスボット(対話型AI)は、以下のような企業におすすめです。
音声認識に加えて、テキストを自然な声で読み上げる「音声合成」を組み合わせることで、アクセシビリティの飛躍的な向上に貢献します。
例えば、Webサイトや文書の内容をAIが読み上げる仕組みは、視覚に障がいのある方や、小さな文字を読むのが難しい高齢者の大切なサポートとなります。
最近ではこうした福祉的な支援に留まらず、電子書籍や学習コンテンツ、行政・観光案内、さらには動画制作といった幅広いビジネス領域で音声合成技術が活用されています。
この分野では、Google Cloudが提供する高音質な合成音声(Chirp 3 HD voices)や、短時間の録音から特定の個人の声を再現する技術(Instant Custom Voice)などが注目されています。
このように、音声認識で「聞き取り」、音声合成で「伝える」という一連の体験設計(UX)は、情報の受け取り方をより多様で豊かなものへと変えています。

音声認識システムは、AIの発展により安価で使いやすいシステムへと進化を続けています。
従来は人員による対応が必須であったサービスの音声認識システムへの置き換えが進んでおり、毎日の生活におけるさまざまな場面で音声認識システムに触れる機会が増えてきました。
ここでは、企業による音声認識システムの活用事例を紹介します。
近畿広域圏を放送対象とする放送局「株式会社毎日放送」では、朝の30分ラジオ番組をAIで文字起こししたテキストを作成。朝の忙しい時間に生放送を聞けない方向けに、専門家の提言などの貴重な情報をWEBサイト上に公開しています。
少ないスタッフで番組制作から放映まで対応しなければならないため、文字起こしの時間が取れないことが悩みでした。しかし、精度の高いAI文字起こしを活用し始めてからは、作業時間の大幅な短縮に成功したそうです。
モーターなどの構成部品であるベアリングの中核部品「リテーナー」の世界トップシェアを誇る「中西金属工業株式会社」では、アジア圏への商品販売強化を推進。製品説明を現地語で行うため、AI翻訳を導入しました。
文法上の並びを考慮し、すでに設置済みの英語サイトを基に多言語展開を行った結果、自動翻訳の精度が著しく向上。現地の顧客とのコミュニケーションが活性化した上、海外SEO対策強化も同時に可能となったのです。
事例:アジア圏でのコミュニケーション活性化を実現(中西金属工業株式会社)| AISmiley

AI音声認識サービスは数多くリリースされているため、適切なサービスを選ぶことが大切です。自社が抱える課題に対し有効なAI音声認識サービスを選んで、業務の効率化と利益の最大化を目指しましょう。
ここからは、人気のあるおすすめのAI音声認識サービスを紹介します。
| サービス名 | 主な用途 | 生成AI対応 | リアルタイム対応 | 話者分離 | 翻訳対応 | 向いている企業 |
| AmiVoice Communication Suite | コールセンター、通話記録、応対分析 | あり | あり | 要確認 | 要確認 | コールセンター業務の効率化や応対品質向上を進めたい企業 |
| Nuance 音声認識/対話型AI | 音声対話、議事録、業界特化運用 | あり | 要確認 | 要確認 | 要確認 | 専門用語や独自業務フローに対応したい企業 |
| COTOHA | 文字起こし、翻訳、要約 | あり | 要確認 | 要確認 | あり | 多言語会議や要約まで含めて効率化したい企業 |
| Google Cloud Speech-to-Text | 文字起こし、音声アプリ開発、字幕生成 | あり | あり | 一部対応 | 一部対応 | クラウド型で柔軟に組み込みたい企業 |
| Azure Speech | 会議、コールセンター、字幕生成、翻訳 | あり | あり | あり | あり | Microsoft環境と連携しながら幅広く活用したい企業 |
| OpenAI Audio API | 高精度文字起こし、音声エージェント、音声UI | あり | あり | あり | 要確認 | 文字起こしに加え、音声対話や音声エージェントも構築したい企業 |
| AssemblyAI | 文字起こし、話者分離、要約、音声分析 | あり | あり | あり | 要確認 | 音声データの分析や後処理まで自動化したい企業 |
Microsoft Azure AI Speechは、音声認識(Speech-to-Text)、音声合成(Text-to-Speech)、翻訳、話者識別までを網羅した、マイクロソフトが提供する統合的な音声AIサービスです。リアルタイムおよび一括(バッチ)での文字起こしに加え、動画字幕作成やコールセンター分析など、極めて幅広いビジネス用途に対応しています。
最大の特長は、業界用語や専門用語を学習させることができる「カスタムモデル」の柔軟性です。これにより、独自の専門知識が必要な現場でも高い認識精度を維持できます。
また、Microsoft 365などの自社製品や既存の業務システムとの親和性が高く、セキュアなエンタープライズ環境への導入に最適です。料金は1秒単位の従量課金制となっており、利用規模に合わせたコスト管理が可能です。
【こんな課題を抱えている企業におすすめ】
OpenAI Audio APIは、最新の生成AI技術をベースとした音声処理APIです。
現在はgpt-4o-transcribe、gpt-4o-mini-transcribe、gpt-4o-transcribe-diariz系モデルを中心に、高精度な文字起こしや話者分離(Diarization)を提供しています。2025年以降の次世代モデルでは、背景雑音や多様なアクセント、話速の変化に対する耐性がさらに強化され、実環境での信頼性が飛躍的に向上しています。
単なる文字起こしに留まらず、Realtime APIを活用した「音声エージェント(Voice Agents)」の構築に強みを持つのも大きな特徴です。
人間のように自然で低遅延な音声対話インターフェースを実現できるため、次世代のカスタマーサポートや対話型AIアプリケーションの開発を目指す企業に、強力なソリューションを提供します。
【こんな課題を抱えている企業におすすめ】
AssemblyAIは、開発者フレンドリーな設計で急成長している、音声認識に特化したSpeech AIプラットフォームです。ストリーミングによるリアルタイム処理とバッチ処理の両方に対応しており、過酷な雑音環境や多様なアクセント下でも、極めて高い認識精度を維持することを公式サイトで打ち出しています。
最大の特徴は、文字起こしの「後工程」を自動化する豊富な分析機能です。話者分離やタイムスタンプ付与はもちろん、感情分析、自動要約、重要情報のマスキング(PII保護)など、音声データから価値ある情報を抽出するための機能が統合されています。ポッドキャストや動画コンテンツ、通話記録から、単なるテキスト以上のインサイトを得たい企業に最適です。
【こんな課題を抱えている企業におすすめ】
「AmiVoice Communication Suite」は、独自の音声認識エンジン「AmiVoice」を導入したコールセンター向けAIソリューションです。
顧客との電話によるコミュニケーションをAIがリアルタイムに文字起こしし、会話中に頻出するキーワードから適切な案内方針を提案。また、独自の感情解析技術により顧客の勘定の起伏を可視顧客の感情の起伏を可視化。顧客の感情に寄り添った対応に導きます。
膨大な情報から構築されたAIにより、負荷の高いコールセンターの業務軽減を目指せます。サポートセンターの対応品質の低下や対応品質のばらつきに悩む企業におすすめです。
【こんな課題を抱えている企業におすすめ】
AmiVoice Communication Suiteはこちら
Nuance Japanが提供するさまざまな音声ソリューションを組み合せることで、さまざまな形態の音声認識サービスが実現します。
音声対話に必要な「意図理解」「対話内容の管理」「合成音声による会話」「自動文字起こし」と、事業に特化した独自辞書を組み合わせ、AIによる自然な対話を可能とします。
クラウド型、オンプレミス型のいずれにも対応できるため、企業が求める用途に合ったシステム構築が可能。業界独自の専門用語や、独自のルールに沿った対応が必要な企業におすすめできるAI音声認識ツールです。
【こんな課題を抱えている企業におすすめ】

NTTコミュニケーションズが提供する音声解析サービスが「COTOHA」。翻訳から文字起こし、要約文の作成を自動で行うことが可能です。
また、200万語以上の単語を含む辞書群を保持しており、3,000種を超えるといわれる意味属性の分類により、文脈に合った自然な単語選択を実現します。
顧客側で必要な用語を辞書登録すれば、業界や社内文化にあった翻訳・文字起こし環境の整備が可能。海外を含むオンライン会議にまつわる業務の工数を圧縮したい企業に最適のAI音声認識ツールです。
【こんな課題を抱えている企業におすすめ】

「Speech-to-Text」は、Googleが提供するクラウドベースの音声認識サービスです。膨大な量の音声データを学習し続けるAIにより、高品質の文字起こしを実現します。
電話やビデオ、音声ファイルなど、一般に流通するさまざまな音声フォーマットに対応。ブラウザ上から登録不要で利用できるため、誰もが気軽に文字起こしを活用できるのは大きなメリットです。
完全無料で利用できるため、コスト面の使い勝手は抜群。低コストで精度の高い文字起こしツールを利用したい企業におすすめです。
【こんな課題を抱えている企業におすすめ】

AIを活用した音声認識は、文字起こし、議事録作成、翻訳、コールセンター支援、ボイスボットなど、すでに幅広い業務で活用が進んでいます。SiriやGoogleアシスタントのような身近なサービスに加え、近年は企業向けの音声認識サービスも拡大しており、国内の音声認識市場は2025年度に1,165億円規模になる見通しが紹介されています。
こうした背景から、音声認識AIは今後も業務効率化や顧客対応の高度化を支える技術として、さらに活用が広がっていくと考えられます。単なる音声入力ではなく、議事録作成、要約、翻訳、音声エージェントなどへ発展している点も、現在の大きな特徴です。WhisperやAzure Speechのような最新サービスの普及も、この流れを後押ししています。
今後も企業の業務効率化や顧客体験向上を支える技術として、さらに存在感を高めていくでしょう。
アイスマイリーでは、音声認識AIのサービス比較と企業一覧を無料配布しています。課題や目的に応じたサービスを比較検討できますので、ぜひこの機会にお問い合わせください。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。















FOLLOW US
SNSをフォローして、最新情報をチェックできます!







AI製品・ソリューションの掲載を
希望される企業様はこちら