

生成AI

最終更新日:2024/02/29
 データ分析とは?
データ分析とは?
データ分析とは、ビジネスや科学などの分野で重要な役割を果たす技術です。データ分析によって、過去のデータから有用な知見を得ることができ、今後の戦略や意思決定のための重要な情報を提供することができます。本記事では、データ分析の基礎知識からビッグデータ分析や機械学習まで、徹底的に解説していきます。
AIについて詳しく知りたい方はこちらの記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
データ分析とは、ビジネスや科学などの分野で、データを収集・整理し、その中から有用な情報を抽出することです。データ分析は、過去のデータを基に、将来の予測や戦略立案に活用されます。
データ分析には、以下のような種類があります。
それぞれ解説します。
記述統計学とは、データを集計し、その特徴を表すための統計学の分野です。
観測データを具体例を通して図解で分かりやすく解説し、その性質や傾向を明らかにします。
身近な例で説明すると、Aクラスの身長を平均値やヒストグラムにしてまとめたり、グラフ化して分かりやすく表現することが挙げられます。
統計学の基礎部分では、度数分布や平均値・分散・相関などのデータそのものの特徴を調査する記述統計が触れられますが、実際は推定や検定をするための下準備だけでなく、そのデータを調べることでビジネスや研究の現場で問題解決に役立ちます。
また、記述統計学は推測統計学と対比されることが多いです。
推測統計学は、母集団から一部のデータ(標本)を抽出し、そのデータの特徴から母集団の特性を推測する手法です。
推測統計学には、標本から母集団の特性を推定する「推定」と、母集団の仮説を検証する「検定」の2つの手法があります。
例えば、母集団の全てを調査するのに手間や費用がかかる場合、標本調査を実施し、その標本から母集団のデータを統計学的に推測することが多くあります。
推測統計学の発展により、標本から得られた推定値の誤差の評価や統計的仮説検定が客観的に行えるようになりました。
「機械学習」とは、大量のデータを用いて、機械自身が学習し、未知のデータに対しても適切な判断を行うことができるようにする人工知能の一分野です。
機械学習の学習方法には以下のような種類があります。
機械学習は、金融工学や画像処理、自動運転、生物学など、様々な分野に影響を与え始めています。
また、ディープラーニングと呼ばれる技術の登場によって、人の脳機能を模したモデルの構築が可能になり、機械翻訳や音声認識の精度が向上しています。
代表的なアルゴリズムとしては、決定木やランダムフォレスト、ニューラルネットワークなどがあります。
ビッグデータ分析とは、膨大な量のデータを扱うことに特化した手法です。ビッグデータ分析は、データの可視化や機械学習など、他の分析手法を組み合わせて行うことがほとんどです。
また、ビッグデータ分析は、ツールの選択に加えて、データの品質や分析手法の選択、分析結果の解釈なども重要な要素となります。
活用目的は、業務の効率化、基礎研究・学術研究、顧客分析など様々なことを目的としています。
データ分析に必要なスキルとしては、以下のようなものが挙げられます。
これらのスキルを身につけるためには、専門書やオンラインコース、実際に手を動かすことが必要です。
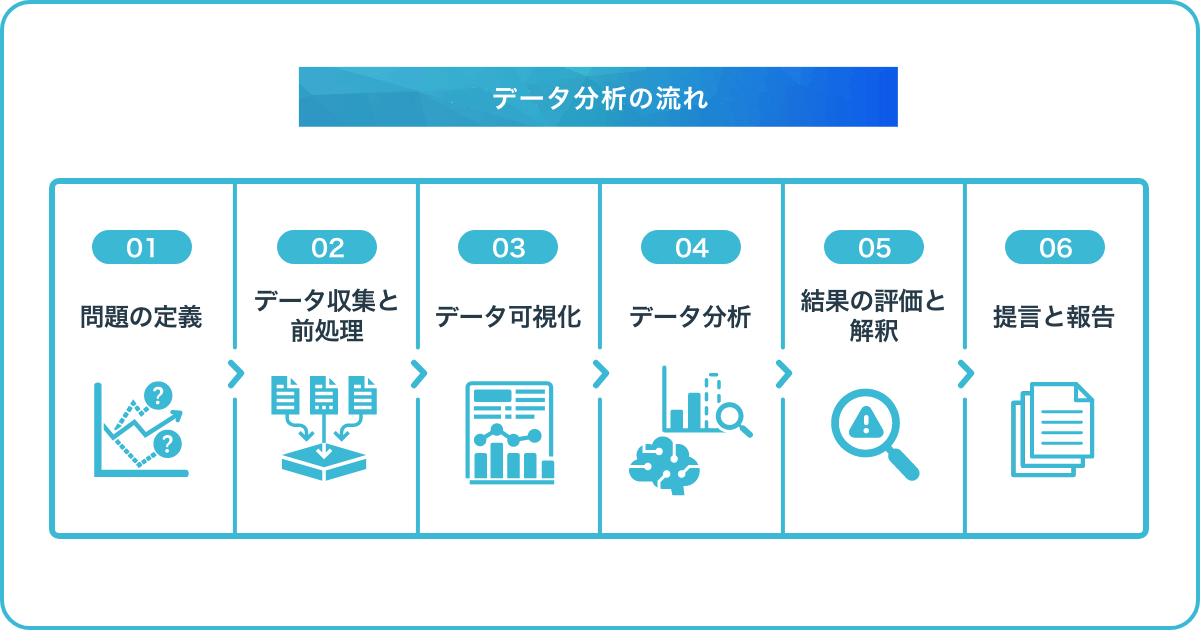
データ分析を行う際には、以下のような流れで行うのが一般的です。
まずは、データ分析を行う目的や問題を明確にすることが重要です。
例えば、企業の売り上げ低迷や顧客離れなどの問題があった場合、その原因を分析することが目的となります。
次に、分析に必要なデータを収集し、必要に応じて前処理を行います。
例えば、顧客の購入履歴やアンケート結果などのデータを収集し、欠損値の処理や異常値の除去などを行います。
データ可視化によって、データの傾向や特徴を把握することができます。
例えば、顧客の年齢層や性別、購入履歴などのデータをヒストグラムや散布図、棒グラフなどを用いて可視化し、分析に備えます。
データ分析には、様々な手法があります。
例えば、記述統計学や推測統計学、機械学習などが挙げられます。ここでは、機械学習の例を紹介します。顧客の購入履歴から、どのような商品を購入する傾向があるかを予測するモデルを構築することで、売上アップの施策を立案することができます。
分析結果を評価し、解釈することが重要です。
分析結果が問題の解決に役立つかどうか、説明可能かどうかを慎重に評価しましょう。
例えば、機械学習による予測結果について、正確性や予測に用いた要素の解釈などが含まれます。
最後に、分析結果をもとに、提言や報告書を作成することがあります。
提言や報告書は、問題解決に向けた具体的なアクションプランを示すことが求められるため、分析結果の詳細な説明や、アクションプランに沿った具体的な施策の提案が必要となります。
例えば、顧客離れが原因で売り上げが低迷している場合、分析結果から顧客にとって魅力的な商品やサービスを提供することが重要であるというアクションプランを示すことができます。
また、そのためには、商品ラインナップの見直しや、新商品の開発、顧客満足度を向上させる施策などが必要であることを提言することができます。
以上が、一般的なデータ分析の流れとなります。データ分析に取り組む際には、このような流れに従って、スムーズに分析を進めることが重要です。

アソシエーション分析は、大量のデータの中から有益な情報を見つけ出す「データマイニング」の一種であり、主にPOSレジデータやECサイトの購買データなどを用いて、消費者の購買行動の中にある関連性を見つけ出す分析手法です。
アソシエーション分析には、バスケット分析などの手法があり、顧客の購入履歴を調べることで、消費活動の法則性を見出そうとする考え方です。また、消費者の嗜好を分析することにより、効果的なマーケティング施策を打つことができます。
アソシエーション分析は、ビッグデータのデータマイニングにおける「もしこうだったら、こうなるであろう」という関連性を見つけ出す手法であり、多くの事例に適用することができます。
アソシエーション分析は下記記事で詳しく解説しております。
アソシエーション分析とは?指標・ルール生成例・分析の注意点を解説
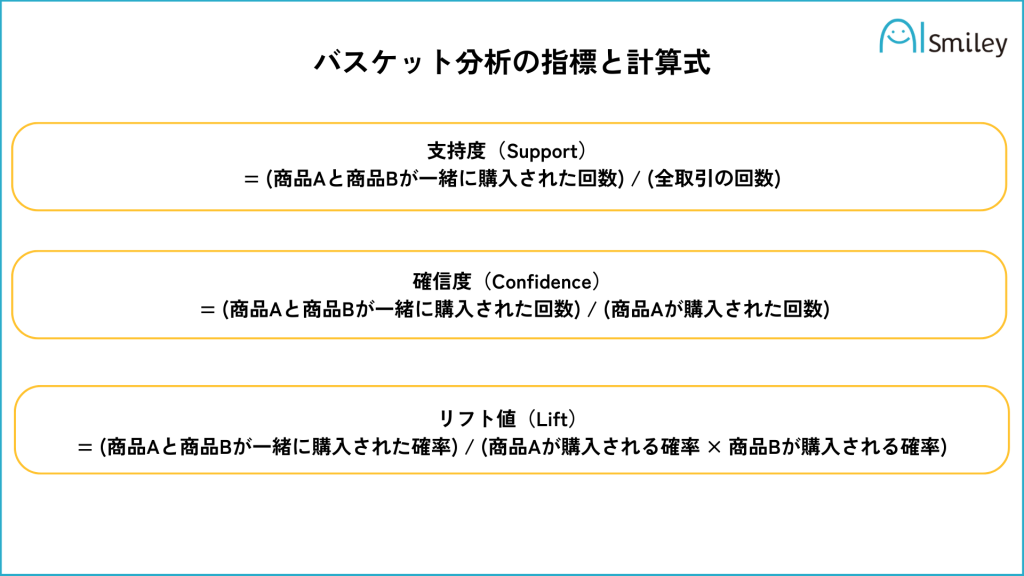
バスケット分析とは、小売店やECサイトなどでの買い物かご(バスケット)の中身を解析し、どの商品とどの商品が一緒に購入されやすいかを調べるマーケティング分析手法です。
バスケット分析の評価指標には、以下の4つがあります。
支持度は、ある商品の組み合わせがデータセット全体の中でどれくらいの割合で出現するかを示す指標です。高い支持度を持つ組み合わせは、より一般的であると考えられます。
計算式:支持度 = (商品Aと商品Bが一緒に購入された回数) / (全取引の回数)
確信度は、ある商品Aを購入した顧客が、商品Bも購入する確率を示す指標です。高い確信度を持つ組み合わせは、商品Aを購入する顧客が商品Bも購入する可能性が高いと考えられます。
計算式:確信度 = (商品Aと商品Bが一緒に購入された回数) / (商品Aが購入された回数)
リフト値は、商品Aと商品Bの関連性を評価する指標で、商品Aと商品Bが独立している場合の確信度に対する比率を示します。リフト値が1より大きい場合、商品Aと商品Bの関連性が高いと考えられ、1より小さい場合、関連性が低いと考えられます。
計算式:リフト値 = (商品Aと商品Bが一緒に購入された確率) / (商品Aが購入される確率 × 商品Bが購入される確率)
全体の支持度は、ある商品の組み合わせが全体の購買データに対してどれだけの割合で現れるかを示す指標で、単純に支持度と呼ばれることもあります。支持度と同じ意味です。
特にリフト値は、単純な商品の購買頻度では把握できない相関関係を見つけ出すことができ、有用な指標とされています。
バスケット分析には、商品単体かカテゴリーごとに分析するかによって結果が異なるため、目的に応じて適切な組み合わせを意識することが重要です。
また、バスケット分析はデータマイニングの代表的な手法であり、アソシエーション分析の一つでもあります。
バスケット分析を活用することで、商品の推奨やセット販売、売り場のレイアウト改善などの施策を立案することができます。
クロス集計とは、複数の質問項目の回答結果を交差させ、それぞれの項目の組み合わせごとの回答数を可視化する統計的な手法の一つです。
アンケートやネットリサーチで得られた大量のデータを活用する際に使用されます。
クロス集計を行う際には、回答者数の確認や仮説を基に分析することが重要です。
アンケート調査の回答データをクロス集計することで、属性などのグループごとの回答傾向などが可視化され、分析軸に合わせて回答データを集計することができます。
因子分析とは、多変量解析の手法の一つで、観測された複数の変数を潜在的な共通因子と独自因子に分解することによって、変数間の関係を明らかにする手法です。
心理学においては、パーソナリティの特性論的研究などに用いられることが多いです。
具体的には、複数の質問項目に対して因子分析を行い、潜在的な因子を抽出することで、その因子によって質問項目がどのように分類されるかを明らかにすることができます。
因子分析によって得られた因子は、観測された変数を説明することができるため、因子分析の結果はデータ解釈や仮説検証に有用です。
因子分析を行う際には、因子数を決める必要があります。
因子数の決め方には、事前に因子同士の関係性や数にある程度の仮説があり、その仮説に基づいて因子の数を設定する方法と、統計ソフトを使って定量的に因子の数を決定する二つの方法があります。
因子分析を行う際には、因子の名前は分析者の主観でつけられるため、注意が必要です。
クラスター分析とは、与えられたデータを似た特性を持つグループに分類する手法であり、データマイニングやマーケティングなどの分野で広く用いられています。
クラスター分析には、階層的に分類する階層型手法と、あらかじめ決めたクラスター数に分類する非階層型手法があり、ウォード法やK平均法などが代表的な手法として知られています。
階層的手法の一つである階層クラスター分析は、データ同士の統合過程をデンドログラムで視覚化でき、グループがどのように形成されたかを把握しやすいというメリットがあります。クラスター分析において、データ同士の類似度は距離によって測定されます。また、クラスター分析を行うにあたっては、クラスター間の距離やサンプル間の距離などをどのように選択するかが重要であることが指摘されています。
クラスタリングについて詳しく知りたい方は下記の記事もご覧ください。
クラスタリングとは?分類との違いやメリット・手法・事例を紹介!
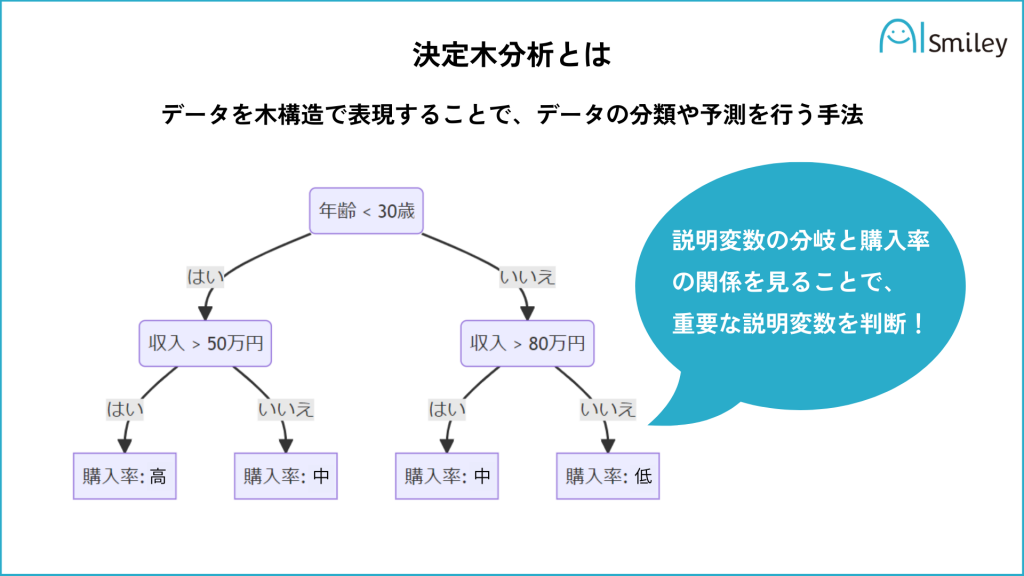
決定木分析は、データを木構造で表現することで、データの分類や予測を行う手法です。データマイニングの手法の一つであり、機械学習において、分類・回帰の問題に用いられることが多いです。
例えば、ビジネスにおいては、顧客の購買履歴から、顧客の属性や嗜好を分析し、ターゲット層の特定やマーケティング戦略の立案に役立てることができます。
決定木分析は、データを分類するために、各説明変数の重要度を評価します。そのため、決定木分析を用いたモデルから得られる知見は、ビジネス分野に限定されず、医療分野や金融分野などにも応用されています。また、決定木分析は比較的汎用性が高い分析であるため、分析の専門知識がなくても扱えることが特徴です。
一方で、決定木分析は分類性能が低いという欠点があります。また、決定木分析の結果は、学習データに過剰適合する傾向があり、汎化性能が低いという問題もあるので注意が必要です。
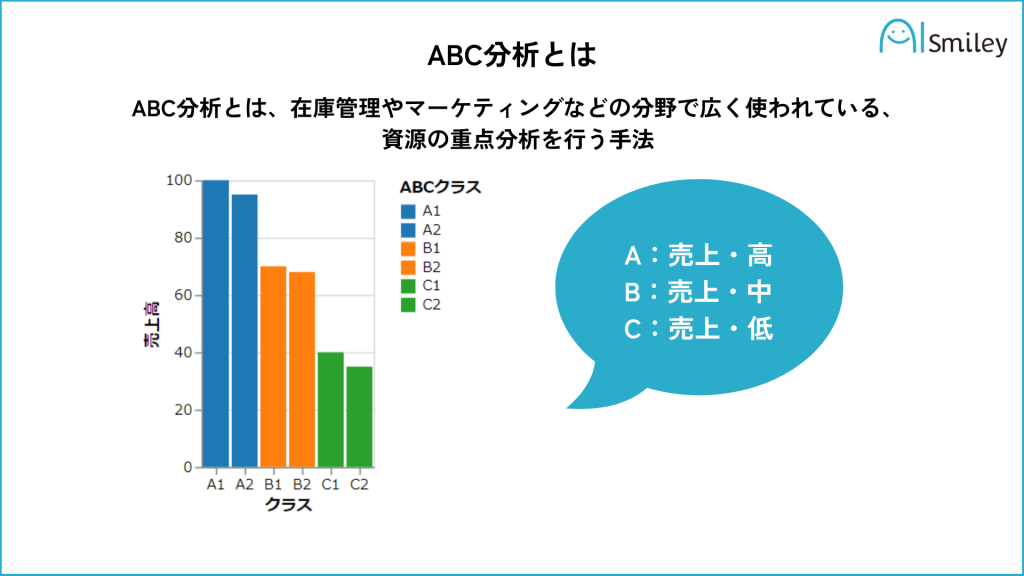
ABC分析とは、在庫管理やマーケティングなどの分野で広く使われている、資源の重点分析を行う手法です。
売上高、コスト、在庫などの指標を基に、優先度を決定して管理するためのフレームワークで、製品やサービスを優先度に応じて分類し、資源の配分や経営方針の決定に役立ちます。
ABC分析は、多くの場合、以下のように分類します。
このように分類することでそれぞれに適切な管理策が立てられます。
ABC分析は、在庫管理や商品の調達、マーケティング戦略の決定などに活用されるため、ビジネスにおいては非常に重要な手法とされています。
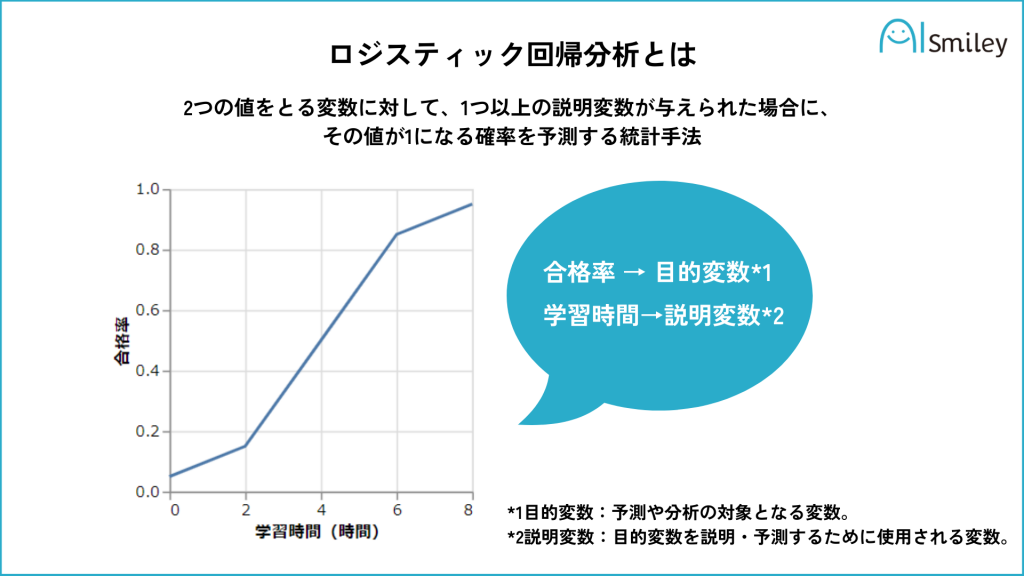
ロジスティック回帰分析は、2つの値をとる変数に対して、1つ以上の説明変数が与えられた場合に、その値が1になる確率を予測する統計手法のことです。
例えば、ある製品を買うか買わないか、ある人が病気になるかならないかなどを予測する際に用いられ、病気の発症率や迷惑メールか否かの判定など、さまざまな分野で活用されています。
ロジスティック回帰分析では、オッズ比がよく用いられ、この値を解釈することで説明変数が目的変数にどのように影響を与えるかを評価することができます。
ロジスティック回帰分析は下記記事で詳しく解説しております。
ロジスティック回帰分析とは?特徴や活用シーンを解説
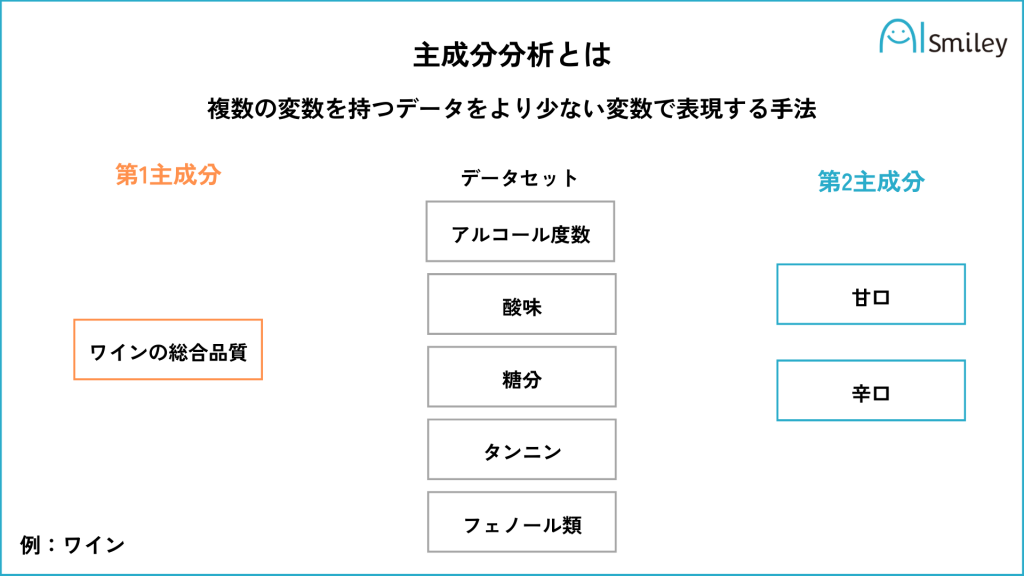
主成分分析は、複数の変数を持つデータをより少ない変数で表現する手法です。主成分分析をすることで、多くの変数で表されたデータを、より少ない変数で表すことができます。
主成分分析では、元のデータの情報をなるべく損なわずに、できるだけ少ない主成分で表現することを目的とします。主成分は、元のデータの変数の線形結合で表されます。
主成分分析を実行することで、データの相関関係や構造を把握することができます。また、主成分分析によって得られた主成分得点は、元の変数を使った解釈にも用いることができます。
主成分分析は、アンケート調査や市場調査などで有効な分析手法の一つです。特に、商品やサービスの評価分析や顧客満足度が高い店舗の特定に役立ちます。
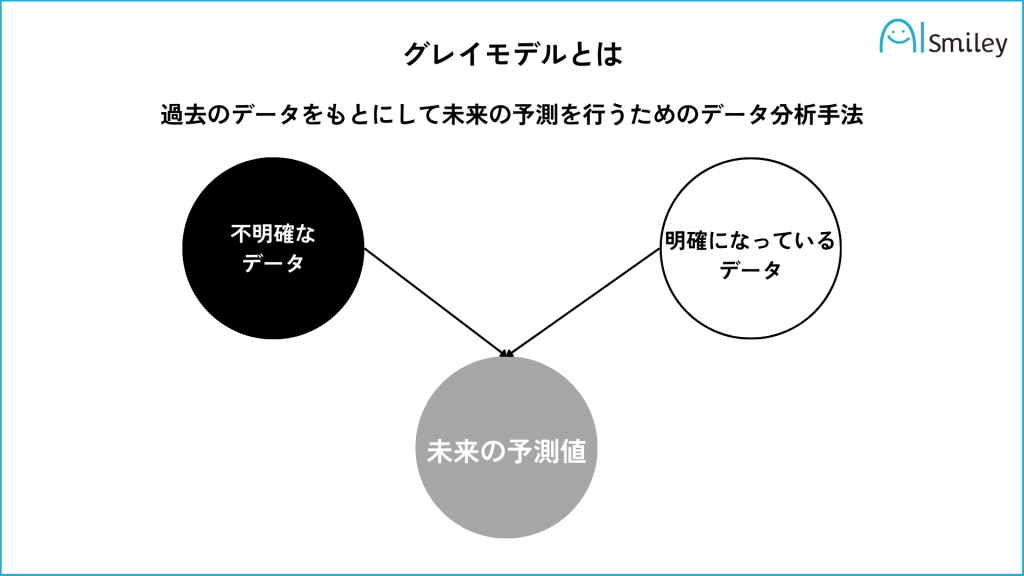
「グレイモデル」とは、過去のデータをもとにして未来の予測を行うためのデータ分析手法の一つです。具体的には、データの色を以下のように定義して灰色データ(未来の予測値)を予測する手法です。
グレイモデルは過去のデータから未来を予測するため、予測の精度は高いとされています。
グレイモデルは、ABC分析とも関連しており、ビッグデータから必要な情報を抽出する際に役立ちます。また、リスクマネジメントなどの様々な分野でも利用されており、他の分析手法と組み合わせて利用されることが多いです。
「時系列分析」とは、時間経過と共に変化するデータを分析する手法です。この分析は、過去のデータを使って未来を予測するために、金融やマーケティングなど多くの分野で使われます。時系列データの例には、株価や天気予報、人口統計などがあります。
この分析の目的は、データの長期的な傾向や周期的な変化を調べ、未来の値を予測することです。
時系列分析は過去のデータが未来に影響を与える点を考慮し、一方、回帰分析は異なるデータ間の関係を分析します。
分析プロセスは、以下の7ステップから成り立ちます。
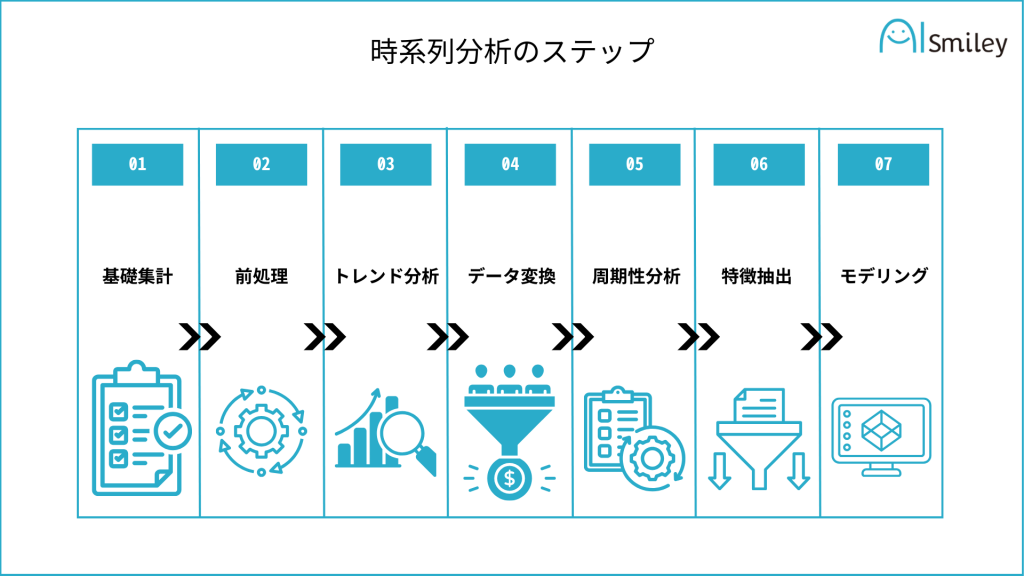
時系列モデリングには、自己回帰モデルや機械学習などが使われます。
「判別分析」とは、データを分類するための効果的な手法です。
この分析は、例えば見込み客の中から購入意欲の高い人を特定する際などに有効です。
利用率としては、ビジネスや教育分野での利用が多く、顧客のリピート率の判定、広告のターゲット設定、商品をおすすめする際などに使われます。
また、判別分析にはマハラノビス距離や線形判別関数といった方法があり、データを2つのグループに分けるのに役立ちます。
判別分析は、既知のカテゴリーに基づいてデータを分類する「教師あり分析」の一形態です。
「コレスポンデンス分析」とは、ブランドや製品間の関係を視覚的に比較するための分析手法です。
この方法は、データを行と列の行列に配置し、相関が最大になるようにスコアを割り当てます。分析の目的は、項目間の相関を明確にすることです。
また、適用範囲が広く、カテゴリや頻度データなど様々なデータを扱うことができます。性・年代別の集計データや、ブランドとイメージ間の関係など、多様な分析が可能です。
特にマーケティングやブランド分析でよく使われるこの手法は、データの解釈にあたっては注意が必要です。軸の意味付け、カテゴリ間の位置関係、目盛りの一致、固有値の考慮など、詳細な分析が求められます。

エクセルは、データ分析において利用される最も一般的なツールの1つです。ここでは、エクセルを使用したデータ分析の基本的な使い方と活用法について紹介します。
エクセルを使用したデータ分析の基本的な流れは以下の通りです。
エクセルを使ったデータ分析の活用法には以下のようなものがあります。
以上が、エクセルを使ったデータ分析の基本的な使い方と活用法についての紹介です。エクセルは、初心者でも簡単に扱えるツールですので、データ分析の入門としてもおすすめです。

Pythonは、データ分析において広く使用されるプログラミング言語の1つです。ここでは、Pythonを使用したデータ分析の基本的な流れと活用法について紹介します。
Pythonを使用したデータ分析の基本的な流れは以下の通りです。
Pythonを使ったデータ分析の活用法には以下のようなものがあります。
以上が、Pythonを使用したデータ分析の基本的な使い方と活用法についての紹介です。Pythonは、多くのライブラリがあるため、データ分析に非常に便利です。
Pythonを使ったデータ分析の実例として、CSVファイルからデータを読み込んで、平均や中央値を計算し、グラフにプロットする方法を紹介します。ここでは、PandasとMatplotlibというライブラリを使用します。
まず、PandasとMatplotlibというライブラリをインストールします。コマンドプロンプトまたはターミナルで以下のコマンドを実行してください。
pip install pandas matplotlib
CSVファイルを用意します。例えば、以下のようなデータをsample_data.csvという名前で保存します。
Date,Value
2022-01-01,100
2022-01-02,110
2022-01-03,105
2022-01-04,120
2022-01-05,115
以下のプログラムをdata_analysis.pyという名前で保存します。
import pandas as pd
import matplotlib.pyplot as plt
# CSVファイルを読み込む
data = pd.read_csv('sample_data.csv')
# 基本統計量を計算する
mean = data['Value'].mean()
median = data['Value'].median()
print("平均:", mean)
print("中央値:", median)
# グラフにプロットする
plt.plot(data['Date'], data['Value'])
plt.xlabel('Date')
plt.ylabel('Value')
plt.title('Sample Data')
plt.show()
コマンドプロンプトまたはターミナルで以下のコマンドを実行して、プログラムを実行します。
python data_analysis.py
このプログラムを実行すると、CSVファイルからデータを読み込んで、平均値と中央値を計算し、グラフにプロットします。プログラムの出力には、計算された平均値と中央値が表示され、グラフが表示されます。
この例では、CSVファイルからデータを読み込んで分析しましたが、他のデータソースや分析手法も同様に実装することができます。Pythonを使ったデータ分析の活用法は無限大であり、独自の分析手法やアルゴリズムを実装して、さまざまな問題を解決することができます。
BI(Business Intelligence)ツールとは、企業が持つ膨大なデータを集めて分析・加工し、経営上の意思決定や課題解決に役立てるためのツールのことです。
データ分析においては、BIツールの導入が一般的です。以下に、データ分析に適したBIツールのおすすめを5つ紹介します。
| ツール名 | 特徴 |
| Tableau | ビジュアルな表現が得意で、直感的な操作が可能なBIツールです。データのクリーニングから可視化まで一貫して行えるため、初心者でも扱いやすいと言われています。 |
| FineReport | データ分析から可視化、ダッシュボードの作成まで幅広くカバーすることができるビッグデータ分析ツールです。多彩なグラフや表を利用してデータを分析することができ、使いやすさも高く評価されています。 |
| SAS Visual Analytics | グラフやチャートなどを利用したビジュアルな分析機能が豊富で、ドラッグ&ドロップで簡単に分析処理を設定できます。また、機械学習を用いた予測モデルの構築も可能であり、データサイエンティストがビジネスユーザーに提供するデータ分析の成果物としても活用されています。 |
| Microsoft Power BI | クラウド上で利用できるBIツールで、データの可視化やレポート作成が簡単に行えます。Excelとの連携も可能で、Office365のサブスクリプションに含まれることから、企業での利用が一般的です。 |
| QlikView | 高速なデータ処理ができるBIツールで、大量のデータでもスムーズに分析することができます。データの抽出、分析、可視化が一体となっており、分析の迅速化が可能です。 |
データ分析において、Webスクレイピングツールは非常に重要な役割を果たします。
Webスクレイピングツールを使用することで、Web上に散在する膨大な情報から必要なデータを収集することができます。ここでは、おすすめのWebスクレイピングツール3つを紹介します。
| ツール名 | 特徴 |
| Octoparse | Octoparseは、Webスクレイピングツールとして多くのユーザーに支持されています。視覚的にデータを抽出することができ、AJAXやJavaScriptなどの技術を使用した動的なWebサイトからのデータ収集にも対応しています。また、無料版もあるため初心者でも手軽に使えます。 |
| ScrapeStorm | ScrapeStormは、ポイント&クリックでデータを収集することができる使いやすいWebスクレイピングツールです。多彩なデータ出力形式に対応しているため、収集したデータを様々な用途に活用することができます。また、無料版もあるため初心者でも手軽に使えます。 |
| Import.io | Import.ioは、Webサイトからデータを抽出してデータセットを作成することができるWebスクレイピングツールです。APIとWebhookを使用して、アプリケーションにデータを統合することもできます。データ抽出に特化した機能が充実しているため、ビジネス目的で利用することができます。 |
データ処理とは、データを集め、加工して保存することであり、ビジネスにおいてデータを活用する上で重要な役割を担っています。
以下では、データ処理に使えるツールを3つ紹介します。
| ツール名 | 特徴 |
| Cloud Data Fusion | Cloud Data Fusionは、GCP上で動作するデータ処理ツールであり、ビジュアルなフローでデータ処理が行えます。エディションによって機能が異なりますが、Basicエディションでは120時間まで無料で利用できるため、使い勝手を確認するのにも適しています。 |
| Orange | Orangeは、データ分析に利用できるオープンソースのツールキットです。ビジュアルプログラミング言語により、リンクしたウィジェットを用いてワークフローを作成することができます。Pythonライブラリとしても利用可能で、機械学習、データ視覚化、データマイニングにも対応しています.また、Orangeを利用することで、膨大なデータを分析する際の効率を高めることができます。 |
| Pandas | PandasはPythonのデータ解析ライブラリの1つであり、データフレームなどの独自のデータ構造を提供し、様々なデータ処理機能があります。 |
本記事では、データ分析の基礎知識からビッグデータ分析や機械学習まで、徹底的に解説しました。データ分析は、ビジネスや科学などの分野で重要な役割を果たす技術であり、データから有用な知見を得ることができます。データ分析に必要なスキルや、データ分析の実践方法についても紹介しました。
データ分析は、今後ますます重要性が高まることが予想されます。是非、本記事を参考にして、データ分析の基礎を学び、ビジネスや研究などで活用してみてください。
データ分析には、PythonやRなどのプログラミング言語が使用されることが多いです。また、ExcelやTableauといったビジュアルツールも利用できます。
データ分析を学ぶためには、統計学や機械学習の知識が必要です。また、プログラミングスキルも必要となります。
ビッグデータ分析には、HadoopやSparkといったビッグデータプラットフォームが使用されます。
機械学習には以下のような種類があります。
データ分析によって、ビジネスや科学などの分野で、過去のデータから有用な知見を得ることができます。例えば、どのような要因が売り上げに影響を与えているのか、どのような商品を販売すべきかなどが分かります。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!









AI製品・ソリューションの掲載を
希望される企業様はこちら