

生成AI

最終更新日:2024/05/13
 日本語特化 Llama3 Youko 8B公開
日本語特化 Llama3 Youko 8B公開
rinnaは、日本語特化モデル「Llama 3 Youko 8B」を公開しました。Llama 3の優れた性能が日本語で引き継がれます。
このAIニュースのポイント
rinna株式会社は、Llama 3 8Bに対して日本語データで継続事前学習を行った「Llama 3 Youko 8B」を開発し、Meta Llama 3 Community Licenseで公開したと発表しました。
AI技術の発展の中で、Meta社のLlama 3やMicrosoft社のPhi-3、Apple社のOpenELMといった、高いテキスト生成能力を持った大規模言語モデルが利用しやすいライセンスで公開されてきました。しかし、これらのモデルは英語が学習データの大多数を占め、日本語のテキスト生成は可能であるものの、英語と比較すると十分な性能を発揮することができません。
そこでrinnaは、Llama 2やQwenの日本語事前学習で得られた知見を活かし、英語圏の進展に追随するために、Llama 3の日本語継続事前学習モデル「Llama 3 Youko 8B」を開発・公開しました。
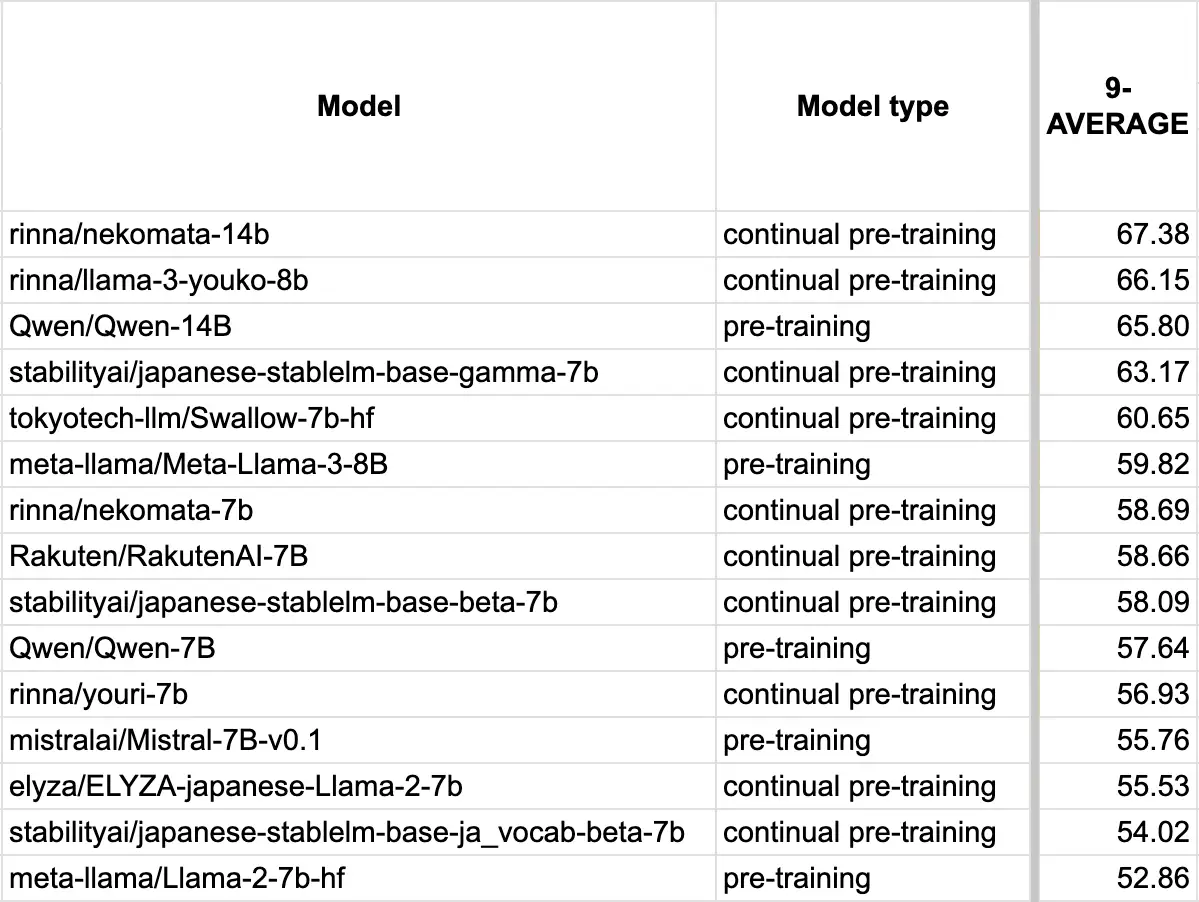
「Llama 3 Youko 8B」は、80億パラメータのLlama 3 8Bに対し、日本語と英語の学習データ220億トークンを用いて継続事前学習したモデルです。名前の由来は、妖怪の「妖狐」からきています。
日本語言語モデルの性能を評価するためのベンチマークの一つである Stability-AI/lm-evaluation-harnessの9タスク平均スコアはLlama 3が59.82であるのに対し、Llama 3 Youko 8Bは66.15となっており、Llama 3の優れた性能を日本語に引き継いでいます。
また、本モデルは汎用的なベースモデルであるため、目的とするタスクで利用する場合には、ファインチューニングやモデルマージを行うことが推奨されています。
rinnaは「今後もAIの社会実装を進めるために研究開発を続け、研究成果の公開や製品への導入を行っていく」とコメントしています。
出典:PR TIMES
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!










AI製品・ソリューションの掲載を
希望される企業様はこちら