

強化学習とは?手法やAIロボットなどの活用事例を紹介
最終更新日:2024/03/01
 強化学習とは?
強化学習とは?
強化学習とは、機械学習における学習アルゴリズムの1つです。
エージェントと呼ばれるAIやシステムが、環境と呼ばれるデータを用いて試行錯誤して学び、報酬を最大化する学習手法です。
強化学習はすでに、家庭用ゲームのAI機能や自動運転車の制御に用いられており、今後はさらなる社会への発展に寄与することが期待されています。本記事では、強化学習に関する概念だけではなく、仕組みや実例について詳しく解説していきます。
機械学習について詳しく知りたい方は以下の記事もご覧ください。
強化学習とは?

強化学習とは、機械学習のアルゴリズムのひとつであり、「システム自身が試行錯誤を繰り返して最適なシステム制御を実現していく仕組み」のことを指します。機械学習には、教師あり学習や教師なし学習のように、明確なデータをもとにした学習方法も存在しますが、強化学習の場合は明確なデータをもとにするわけではありません。
プログラム自体が与えられた環境の観測を行い、一連の行動結果を踏まえた上で、より価値のある行動を学習していくという仕組みです。そして、その行動についての評価も自ら更新していきます。さまざまな行動を試しながら、より価値のある行動を探していくという点を踏まえると、人間の動作に近いものといえるかもしれません。
そんな強化学習ですが、この概念自体は近年のAIブームよりも前から存在していました。強化学習の原型といえるものは、機械の自律的制御を実現する「最適制御」の研究が行われていた1950年代から存在していたのです。なお、1990年代には強化学習の生みの親とされるリチャード・サットン教授(カナダ・アルバータ大学)を中心としたチームにより研究が進められていたといいます。
このように、強化学習の原型といえるものは古くから存在していたわけですが、そこに飛躍的な進歩をもたらしたのが「深層強化学習」というものです。これは、従来の強化学習に深層学習(ディープラーニング)を応用したものであり、強化学習を軸として稼働するAIが世間に広まるきっかけとなりました。
強化学習と深層学習の違いについて詳しく知りたい方は以下の記事もご覧ください。
強化学習の手法
強化学習には、Q-Learning、SARSA、モンテカルロ法という3つのアルゴリズムが存在します。それぞれのアルゴリズムにどのような特徴があるのか、詳しく見ていきましょう。
Q-Learning
3つの手法の中で一番多く用いられているのが、Q-Learning(Q学習)です。強化学習について勉強していく際は、まずQ-Learningから学ぶことになるでしょう。
Q-Learningは、Q関数という行動価値関数を学習し、制御を行っていく仕組みです。行動価値関数Q(a|s)は、状態s(t)において行動aを行った場合、その先の報酬はどれくらいもらえるかの予想を出力していきます。
Q関数に行動「右に押す」と「左に押す」を入力した場合の出力を比較し、より報酬が多いほうを選択すると、CartPoleが立ち続けることになるわけです。
SARSA
SARSAは、Q関数を学習するという点ではQ-Learningと同じですが、学習の仕方に違いがあります。「実際に行動した結果」を用いて、期待値の見積もりを置き換えていくのが特徴です。
そのため、現在の価値を更新するには、再度エージェントが行動を行わなくてはなりません。
モンテカルロ法
モンテカルロ法は、Q値の更新において「次の時点のQ値」を使用しないという点が特徴です。何かしらの報酬が得られるまで行動を行い、報酬値を把握します。そして、辿ってきた状態・行動に対して、報酬を分配するという仕組みです。
ディープラーニングの発達で登場した深層強化学習とは
ディープラーニングの発達に伴い、現在は強化学習においてもディープラーニングが積極的に活用され始めています。ディープラーニングの発達によって登場したのが深層強化学習と呼ばれる技術です。
これまでは、Q関数を表すために表を使用するのが一般的となっていました。表のサイズは「状態sを離散化した数」×「行動の種類」という計算によってに決まるため、限りがあります。
しかし、ディープラーニングを用いたDQN(Deep Q-Network 、Deep Q-Learning Network)が実用化されたことで、これまで以上に複雑なゲームや制御問題を解決できるようになったのです。このディープラーニングを活用した強化学習のことを「深層強化学習」と呼びます。
強化学習でできること

では、強化学習によって具体的に何ができるようになるのでしょうか。ここからは、強化学習でできることについて詳しく見ていきましょう。
ゲーム
アーケードゲーム「ブロック崩し」は多くの方が一度はプレイしたことがあるのではないでしょうか。このゲームでは、強化学習を使用するAIが人間を上回るスコアを記録しています。Atariという会社が出していたブロック崩しゲームを、DeepMind社が開発したAI(強化学習を使用)に学習させたところ、49本のゲームのうち半分以上で、人間と匹敵するスコアもしくは人間を上回るスコアを記録したのです。さまざまな行動を試しながら、より価値のある行動を探していったからこそ得られた結果といえるでしょう。
自動運転

自動車における自動運転も、強化学習が活用されている分野のひとつです。Prefferd Networks社という日本の企業が行っている研究では、自動車の幅に対して道の幅が狭く、車が密集している交差点のような難しい状況下において、強化学習でどれだけ運転の精度を高められるかという実験が行われています。
この技術を用いることにより、前後左右のすべての方向を集中してみることが可能になるため、前方向と同じように後方向にも躊躇なく移動することができるそうです。
エレベーターの制御システム
近年は高層ビルが増加していることもあり、エレベーターの制御は極めて重要な役割を担っています。ただし、エレベーターの安全性を高めるのはもちろんのこと、エレベーターの利便性を高めることも、良いエレベーター制御システムの条件のひとつです。そのため、客の待ち時間が長くなってしまうエレベーターの制御システムは高く評価できません。
特に、デパートやオフィスビル、タワーマンションといった、毎日大勢の人々が乗り降りする場所には欠かせない条件といえるでしょう。エレベーターは簡単に増設することもできませんから、台数と定員を変えずに待ち時間を短くする必要があるのです。
そこで活用されるのが、強化学習です。数理的な手法で割り当てを行うにしても限界があるため、強化学習によって過去の経験にもとづいた最適な選択肢を選ぶことで、より柔軟にエレベーターを稼働させることが可能になります。もちろん、日々の運行履歴も学習していくため、新たな学習データを追加した上で、より最適な判断方法にアップデートしていくことも可能なのです。
そのため、エレベーターの待ち時間が長くなってしまっている建物などは、特に強化学習を導入するメリットが大きいといえるでしょう。
強化学習の具体例・活用事例
強化学習は、さまざまな分野で活用され始めています。具体的にどのような場所で強化学習が活用されているのか、その事例を見ていきましょう。
AlphaGo

強化学習の代表的な活用事例として挙げられるのが、2016年に登場した囲碁AIの「AlphaGo」です。プロ棋士に勝利をしたことで大きな話題を呼びました。
そんなAlphaGoには、Googleが開発したディープラーニングと強化学習を組み合わせた深層強化学習が活用されています。囲碁だけでなくさまざまなゲームにおいて圧倒的な強さを発揮しており、もはや深層強化学習の知名度を高めるきっかけとなった存在と言っても過言ではありません。
AlphaGoには、「モンテカルロ木探索」と呼ばれる探索型AIが搭載されています。このAIは、「統計的に勝つ確率の高い一手」を算出することを目的としたもので、囲碁のように「明らかな正解が存在するケース」に対応可能です。
ただし、モンテカルロ木探索は、ある程度盤面の選択肢が絞り込まれた状況でなければ使用することができません。そのため、「盤面評価」と「戦術予測」を実行する「深層強化学習を搭載したAI」を活用し、分析を進めていくわけです。
そんな優れたAIを搭載するAlphaGoですが、現在は進化版として「AlphaZero」というものも登場しています。この「AlphaZero」は、AlphaGOを破ることにも成功しており、チェスや将棋といった別の種目にも対応していることから大きな注目を集めているのです。今後どのレベルまで成長を続けるのか、期待を寄せられています。
広告の最適化
レコメンドサービスやレビュー管理サービスなどを提供している「ナビプラス」では、自動最適化機能に強化学習を活用しています。
ナビプラスが提供するサービスの一つに「NaviPlusレコメンド」というものがあります。このサービスは、Webサイトのパーソナライゼーション強化を支援することが目的です。
そのWebサイトにとって最適なレコメンドを実現するためには、一連の行動結果を踏まえた上で、より価値のある行動を学習していく仕組みが欠かせません。その仕組みを実現することができるのが、強化学習なのです。
たとえば広告を表示させるとき、「AとBどちらが高いクリック率を実現できるか」という点においては、初めから正解が存在するわけではありません。実際に試しながらデータを収集していく必要があります。
「実際に試して得られる報酬を最大化するための戦略」を練る上で、強化学習は非常に重要な役割を担っているのです。
コンテンツのレコメンド

コンテンツのレコメンドにも、強化学習は活用されています。例えばNetflixでは、「流行」「視聴率」「ストーリー性」「離脱率」といったさまざまなデータをAIに学習させ、ユーザーごとに最適なコンテンツをレコメンドする仕組みとなっているのです。
そのため、「ユーザーが満足しそうなコンテンツ」が優先的に表示されるようになり、より満足度を高めやすい環境が実現されています。Netflixではオリジナル作品の制作にも力を注いでいるため、今後データが蓄積されることによって、よりユーザーに適した作品が増加していくことも期待できるでしょう。
強化学習に限らず、AIや人工知能でできることを詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能ができること、できないこと。人間にしかできない仕事は?
強化学習に適しているプログラミング言語、Python
強化学習などの機械学習を行う際、プログラミングは避けては通れません。強化学習においては、Pythonが適しているプログラミング言語だと考えられています。
本章では、Pythonが強化学習に適しているプログラミング言語だと考えられている理由について確認しましょう。
読みやすさと書きやすさ
Pythonは構文のシンプルさと可読性の高さが特徴的なプログラミング言語です。
強化学習は複雑なアルゴリズムを組み合わせることが求められます。そのため、簡潔に表現できるPythonの直感的な構文は、強化学習の実装に向いています。
豊富なライブラリ
Pythonは機械学習や強化学習に必要なライブラリが非常に充実しています。
よく用いられるPythonのライブラリは以下の通りです。
- NumPy
- Pandas
- Matplotlib
- Seabor
- TensorFlow
- PyTorch
これらのライブラリを利用することで、複雑な計算や処理を簡単に効率的に行うことができます。多様なライブラリにより、アルゴリズムを構築しやすいという点でPythonは強化学習に向いていると考えられています。
広範なコミュニティサポート
Pythonは特定の地域だけではなく、世界中で広く使われている言語です。
そのため、Pythonによる機械学習や強化学習の実装例も多く、学習の参考にすることができます。また、質問や問題が発生した際には、多くの質問サイトでも解答を得ることができます。
このような幅広いサポートが既に整っているため、強化学習においてPythonが適しているプログラミング言語だと考えられています。
pythonの学習について詳しく学びたい人は以下の記事もご覧ください。
【初心者向け】Pythonは独学できる?学習の流れとおすすめの勉強法
強化学習の発展で期待される未来
強化学習が本格的にビジネスに活用されるようになるのは、もう少し先の話かもしれません。しかし、機械学習の手法の中でも最先端であり、特に注目を集めている存在であることも事実です。今後どのような進化を遂げていくか、ますます目が離せません。
AIについて詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
よくある質問
強化学習とは?
強化学習とは、機械学習のアルゴリズムのひとつであり、「システム自身が試行錯誤を繰り返して最適なシステム制御を実現していく仕組み」のことを指します。機械学習には、教師あり学習や教師なし学習のように、明確なデータをもとにした学習方法も存在しますが、強化学習の場合は明確なデータをもとにするわけではありません。
強化学習の手法は何がある?
強化学習には、Q-Learning、SARSA、モンテカルロ法という3つのアルゴリズムが存在します。
強化学習でできることは?
強化学習でできることの例として、以下が挙げられます。
- ゲーム
- 自動運転
- エレベーターの制御システム
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
ChatGPT連携サービス

チャットボット

AI-OCR

生成AI
ChatGPT連携サービス
チャットボット
AI-OCR








FOLLOW US
SNSをフォローして、最新情報をチェックできます!
清水建設、鉄筋の加工・組立作業に「フィジカルAI」導入。スイスM…

Sakana AI、マルチエージェント基盤「Sakana Fug…
Microsoft、「Copilot Cowork」一般提供を開…
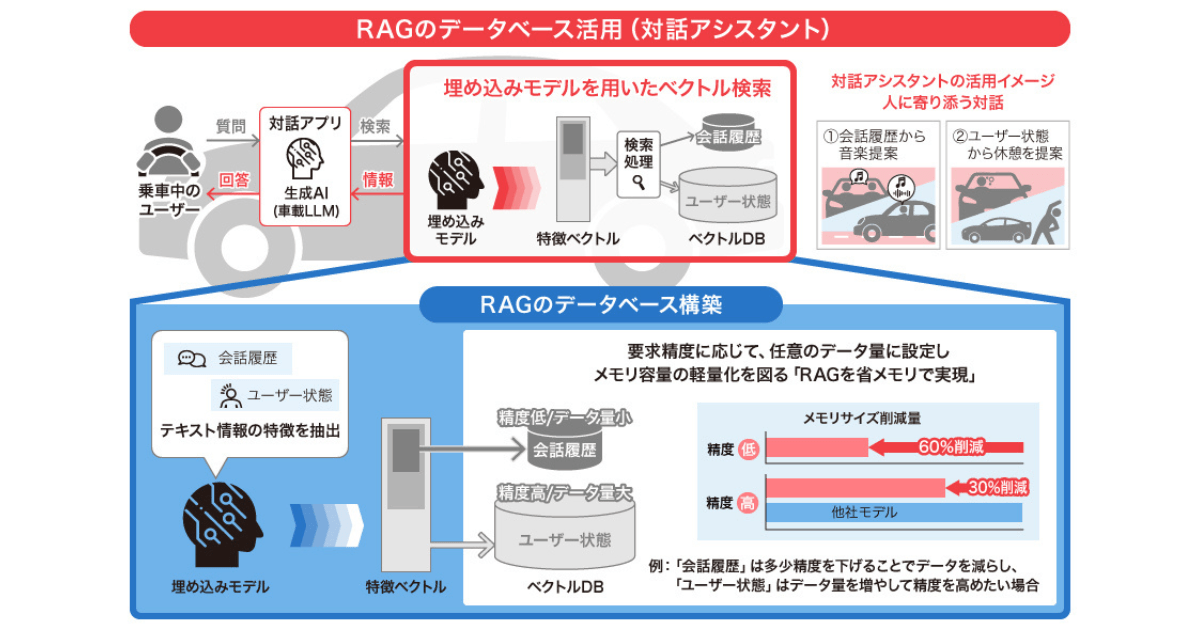
デンソーテン、独自の埋め込みモデル学習技術により車載エッジでRA…

ポケモンカードAIエージェント開発コンテスト「ポケカABC」開催。松尾研・ポケモン・HEROZが共催

Preferred Networks、国産生成AI基盤モデル「PLaMo 3.0 Prime」を正式提供開始。

DCON2026優勝チームは「豊田工業高専」評価額は5億6000万円!

Sapeetの「SAPI ロープレ」、明治の高栄養食品営業部門に正式導入

ロート製薬、フィジカルAI活用の「ヒューマノイド開発プロジェクト」始動
名古屋市、生成AIや自動架電を活用した国民健康保険料催告業務の効率化に関する実証を実施
AI製品・ソリューションの掲載を
希望される企業様はこちら