

生成AI

最終更新日:2024/02/14
 個人情報抽出用データセット公開
個人情報抽出用データセット公開
Nishikaが、文中から個人情報を機械学習により自動で抽出するためのデータセット・高精度AIモデル・ソースコードの提供を開始しました。
このAIニュースのポイント
Nishikaは、文章の中から氏名や組織名、地名などの個人情報を機械学習により自動で抽出するためのデータセット・高精度AIモデル(学習済みモデル)・ソースコードの提供を開始しました。公開期間は2022年10月31日までです。

Nishikaは2021年1月に、判例文の中から個人情報に相当する文言を、人名・組織名・地名など種類別に抽出することを目的としたAI開発コンペティションを開催。同コンペティションでは個人情報の抽出精度を200名以上の参加者が競い合いました。最終的に1位となったAIモデルは、人名では91.4%、組織名・施設名は81.4%の高精度での個人情報抽出を実現しています。
適切な個人情報管理の重要性は年々増しており、様々な文章の中から個人情報の有無を把握することや、正確に抽出することが必要な場面も増えています。このようなタスクには、AI・機械学習の活用による作業効率化が最適です。一方で、個人情報などの固有表現抽出を行うAI開発に一般利用できるデータセットは限られています。
そこでNishikaは、日本語における自然言語処理技術のさらなる発展のためにコンペティションで用いた日本語個人情報抽出向けデータセット、優勝モデルおよびそのソースコードの公開を決めました。同社は、学術領域に限らず民間における研究・プロダクト開発にも広く利用されることを期待しています。
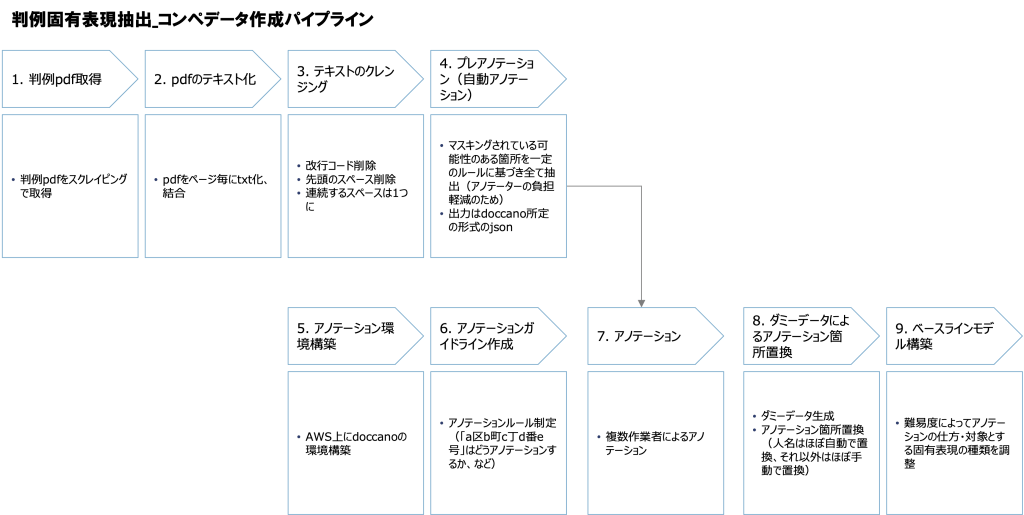
データセットには、約200の判例文に27,000超の個人情報(人名、組織名・施設名・役職名、地名、時間、その他商品名等)へのラベルが付与されています。Nishikaが収集した判例文のpdfデータをテキスト化し、クレンジング後にテキストアノテーションツールdoccanoを用いて原文のマスキング箇所に対してアノテーションを実施。その後、架空の名称でアノテーション箇所を置換することで、これらのデータが作成されています。アノテーションは、人名、組織名・施設名・役職名、地名、時間、その他の5種類です。
AIモデル・ソースコードには、Nishikaが過去に開催したAI開発コンペティションにて、1位を獲得したモデルが使われています。個人情報の抽出を91.4%の精度で抽出可能であり、特に人名は94.5%、組織名・施設名は81.4%の高精度で抽出可能です。
精度の高いデータセット、AIモデル・ソースコードを商用利用したい方は、ぜひサービスを利用してみてはいかがでしょうか。公開期間は2022年10月31日までです。
出典:PR TIMES
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!










AI製品・ソリューションの掲載を
希望される企業様はこちら