

生成AI

最終更新日:2024/05/31
 OpenAI 最新モデル GPT-4o 発表
OpenAI 最新モデル GPT-4o 発表
OpenAIは13日(米国時間)に、新たなAIモデル「GPT-4o」を発表しました。高速処理で音声・画像・映像を組み合わせた活用がChatGPTで利用可能になります。
このAIニュースのポイント
OpenAIは13日(米国時間)、最新のAIモデル「GPT-4o」を発表しました。テキストはもちろん、音声・画像・映像をシームレスに扱い、自然なテンポでのリアルタイム音声会話が可能になりました。
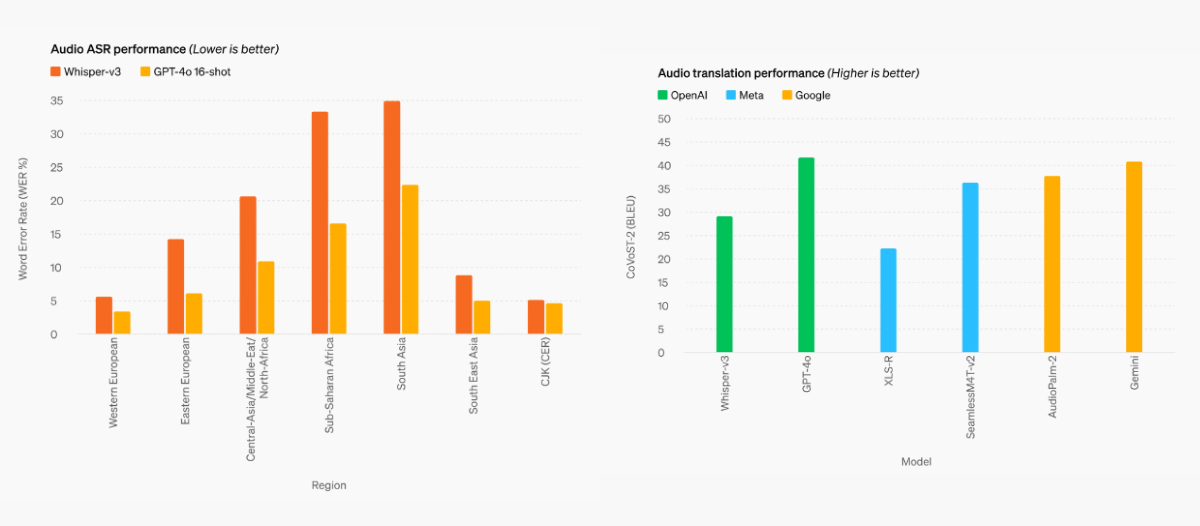
「GPT-4o」は既存モデルと比較して、特に視覚と音声の理解向上が際立っています。音声入力は最短232ミリ秒、平均320ミリ秒で応答可能で、人間の会話の応答時間とほぼ同じとされます。また、会話の割り込みや背景ノイズ、複数の声、声のトーンなど、複雑な対話の要素を理解できるようになりました。
多言語間も高速に理解・応答が可能で、デモでは英語で話した内容をGPT-4oがリアルタイムでイタリア語に翻訳しています。
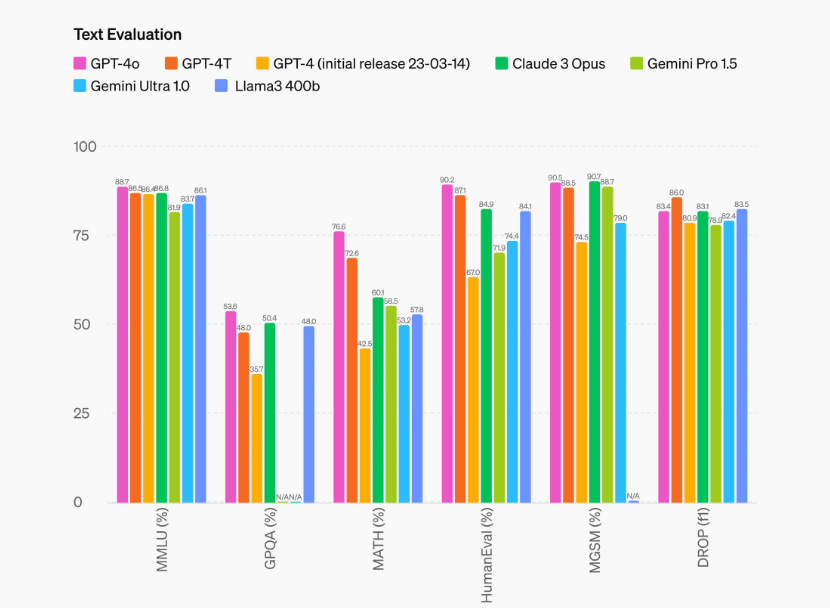
テキストにおいても、「GPT-4o」は英語とコードでGPT-4 Turboの性能に匹敵し、非英語言語のテキストも大幅に改善されています。開発者向けのAPIはGPT-4 Turboと比べて2倍速く、50%安価になり、Rate limitが5倍に引き上げられました。
また、macOS用で新たにデスクトップアプリとして提供が開始されます。発表会では、アプリ内で撮影したスクリーンショットを用いて、コードのレビューや、気温推移グラフの画像を理解し解説する実演が行われました。
「GPT-4o」は無料ユーザーでも利用可能です。有料ユーザーは、時間当たりのメッセージやり取り可能回数が無料ユーザーに比べて5倍に緩和され、企業向けのTeamやEnterpriseユーザーはさらに制限が緩和されます。
音声に関する機能は、これから数週間以内にChatGPT Plus内のアルファ版としてリリースされます。動画認識機能も同様に、段階的にサポートが開始される予定です。
出典:OpenAI
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!







AI製品・ソリューションの掲載を
希望される企業様はこちら