

生成AI

最終更新日:2024/02/08

あらゆる領域において導入が進むAI(人工知能)は、私たちの生活に必要不可欠な存在となりつつあります。業務効率化(業務負担削減)や生産性向上、そして人手不足解消を実現できるというメリットもあり、AIの導入は加速していくことが予測されます。
このようなAIを取り巻く状況の中で、注目を集めている技術が機械学習やディープラーニングを活用した「画像認識」です。今回は、「機械学習を活用した画像認識アリゴリズム」を中心に、画像認識について詳しく見ていきましょう。
画像認識について詳しく知りたい方は以下の記事もご覧ください。
画像認識とは?AIを使った仕組みや最新の活用事例を紹介

コンピューターや機械が「画像に何が写っているのか」を認識したり分析したりする技術のことを画像認識と呼びます。最近では機械学習を活用した画像認識も多くなってきているため、数多くのパターンを試しながら、見分けるルールを自動的に探すことも可能です。
「ディープラーニング」や「機械学習」といった言葉を聞くと、大量のデータと高性能なサーバーが必要になるというイメージを持たれるかもしれませんが、実は個人のPCでも画像認識を学んだり実践したりすることができます。たとえば、大量に用意した写真の中から、自動で「動物の写真」「風景の写真」といったカテゴリ別に分類する機能を実現することも可能なのです。
また、自宅に設置したカメラで飼っているペットを見守りたい場合などにも画像認識は活用できます。留守中にペットが「ご飯をたべたこと」を飼い主のスマートフォンに通知させるサービスなどが提供されていますが、まさに画像認識が活用されている事例です。
さらに、バーコードリーダーにおける読み取りの速度・精度向上にも、画像認識は活用されています。より正確かつスピーディーにバーコードを読み取る上でも、画像認識の技術は非常に重要視されているのです。
ちなみに、最近では画像認識のクラウドサービスも多くなってきており、より多くの企業が手軽に画像認識を活用できるようになりつつあります。代表的なものとして、以下のようなサービスが挙げられるでしょう。
Watson Visual Recognition は、IBMのWatson技術を活用した画像認識機能が搭載されているサービスです。IBM Cloud のライト・アカウントを持っていれば、一定の範囲内を無料で使用することができます。また、オリジナルの機械学習モデルを WEBブラウザから簡単に作ることができる点は、Watson Visual Recognitionの大きな魅力といえるでしょう。
そんなWatson Visual Recognitionでは、以下のような学習済みのモデルが用意されており、画像の認識、分析を手軽に行うことができます。
たとえば、「顔認識モデル」では、数多くの顔画像の中から特定の人物の顔だけを抽出することができます。そのため、顔認証システムによる「顔パスシステム」などを実現することができます。
一般的に、画像認識のサービスを導入した直後の段階では十分な学習データが蓄積されていないため、一定の蓄積期間が必要となるケースが多い傾向にあります。しかし、Watson Visual Recognitionは、Watsonがすでに大量のデータを学習しているため、導入直後から画像に映ったもの、情景の分析・認識を行うことが可能です。データの蓄積期間が必要なく、誰でも手軽に導入に踏み切ることができる点は、大きな魅力といえるでしょう。
Amazon Rekognitionは、AWSで利用することができる画像・動画分析サービスです。機械学習に関する専門知識を持っていない人でも、手軽に画像認識やビデオ分析機能を実現することができます。
そんなAmazon Rekognitionの特徴としては、画像に写っている物体の認識やシーン分析、テキスト抽出、顔検出といった多様な機能が搭載されている点が挙げられるでしょう。たとえば、物体認識の場合、「人が何人映っているか」「その映像内にいる人物が、対象とする人物と一致しているか」といった判定を行うことが可能です。また、顔検出であれば、年齢、性別、笑顔度などを推定したり、髭の有無、めがねの有無を判定したりすることもできます。
一般的に、機械学習の処理を手作業で実装するためには、専門知識が欠かせません。また、大量の学習データセットも必要になります。しかし、Amazon Rekognitionのシステムの場合、専門知識を持っていない人でも簡単に使用できるようセットアップされており、学習データも既に準備されているのです。そのため、AIに関する専門知識を持つ従業員が在籍していない企業でも導入しやすいサービスといえるでしょう。
Computer Vision APIは、Azureで利用することができる画像認識サービスです。代表的な機能である「画像解析」に加え、「画像内のテキスト読み取り」「画像からの手書き文字の読み取り」「著名人の認識」「ほぼリアルタイムでの動画分析」「サムネイル生成」などを行うことができます。
そんなComputer Vision APIを活用すれば、オフィスやストアといった物理的な空間において、人々がどのように移動するかを正しく把握することが可能です。さらに、空間分析機能を使用することによって、「部屋の中にいる人数の把握」「経路追跡」「小売ディスプレイの前で滞在した時間」「列に並んだ時間」などを判別することができるアプリを作成することもできます。
組織の物理空間を最大限に活用したい企業にとって、大きなサポートを得られるサービスといえるでしょう。

次の4つが画像認識を実現させるための機械学習アルゴリズムの代表例となります。それぞれのアルゴリズムの役割を見てみましょう。
物体識別(物体認識)とは、対象の物体と同一の物体が画像内に存在するかどうかを検証する技術のことです。画像に映っている物体のカテゴリを特定するなど、画像に含まれている物体の情報を抽出することができます。この物体識別(物体認識)においては、「物体検出」という技術が重要視されており、物体識別と物体検出はそれぞれ区別して使用されます。
物体検出は、画像に含まれる物体の位置を検出するための技術であるため、物体認識とは実行方法が異なります。ただし、対象となる物体の特徴を抽出する際には、当然その物体の「位置」も重要になるため、併用されるケースも少なくありません。
人間の場合、画像を見て「物の位置」「それが何であるか」の判断を素早く行うことができます。しかし、コンピューターにとって「認識」と「検出」は別であるため、物体検出では「検出」が行われるということです。
セグメンテーション(セマンティックセグメンテーション)とは、画像のピクセルを「どの物体クラスに属するか」という基準で分類していくやり方のことです。画像内のすべてのピクセルをクラスに分類していきます。もし、同クラス内に重なりがある場合には「同クラスの領域」として認識することになるため、物体ごとの認識やカウントは行えません。
姿勢推定とは、静止画から人体の関節点を学習していくことで、他の静止画や動画からリアルタイムに関節点を結んだ人間の姿勢を検出することができるようになるというモデルです。「人体検出」と呼ばれることも少なくありません。この姿勢推定の代表的な活用事例として挙げられるのは、自動運転技術です。また、最近では技術が進歩したことで、スポーツやセキュリティ分野での活用も多く見られるようになりました。
従来は、人と人が重なってしまったり、身体の一部が隠れてしまったりすることで、人間の関節点を検出できないというケースも多かったといいます。ただ、最近では奥行きも推測しながら、重なり合った関節点を正確に検出できるようになったため、より多くの分野での活用が進んでいくでしょう。

以下の機械学習によって画像認識が実現します。それぞれの機械学習の特徴を見ていきましょう。
ロジスティック回帰とは、多変量解析の手法の一つであり、1958年に考案された古典的な手法です。主に、線形分離不可能な分類問題において用いられます。代表的な多変量解析手法としては、目的変数が数量データである重回帰分析が挙げられますが、ロジスティック回帰は重回帰分析とは異なり、目的変数は多群のカテゴリデータであり、説明変数は数量データとなります。そのため、ロジスティック回帰は判別分析と同じように、量的変数から質的変数を予測していくことが可能です。
ランダムフォレストとは、アンサンブル学習のバギングを基本として、複数の少しずつ異なる決定木を集めたものです。決定木単体では過学習してしまうという欠点があり、ランダムフォレストはこの問題に対応する方法の1つです。ランダムに元のデータからサンプリングしているため、各決定木はそれぞれのデータを過学習している状態で構築されます。
異なった方向に過学習している決定木を複数作り、その結果の平均値を取ることで過学習の度合いを減らすという考え方です。
ブースティングとは、逐次的に弱学習器を構築するアンサンブル学習のアルゴリズムです。学習データを一部使用して、最後に合併させるという点はバギングと同じですが、ブースティングでは以前使用したデータを再利用し、ブーストしていきます。そのため、バギングのように並列処理を行うことはできません。
SVM(サポートベクターマシン)とは、機械学習モデルの一種であり、非常に強力なアルゴリズムでもあります。教師あり学習において、分類と回帰を扱うことが可能ですが、主に分類のタスクで用いられるのが一般的です。そんなSVMの重要なポイントとしては、「マージン最大化とカーネル法によって非線形データを扱うことができる」という点が挙げられるでしょう。
また、データの次元が大きくなってしまっても識別精度が高い点や、最適化すべきパラメータが少ない点などは、SVMの大きなメリットといえるでしょう。ただし、学習データの増加に伴い計算量が膨大になる点や、2クラス分類に特化している点、スケーリングが必要になる点などはデメリットといえます。

画像認識では以下のディープラーニングも活用されています。それぞれの活用方法を見ていきましょう。
GPUとは、Graphics Processing Unitを略した言葉のことであり、日本語では「画像処理装置」と呼ばれています。私たちが耳にすることが多いCPUは、Central Processing Unitを略した言葉であり、日本語では「中央処理(演算)装置」と呼ばれているため、これら2つは「画像」か「中央」か、という違いしかありません。
分かりやすく表現すれば、GPUは画像処理に特化している装置であり、CPUは何でもこなせる司令塔のような装置といえるでしょう。最近ではGPGPUの活用も進んでいます。
画像認識では、「CNN(畳み込みニューラルネットワーク)」というネットワークモデルが頻繁に使用されます。このニューラルネットワークは、人間の脳内の神経回路網を表したニューラルネットワークの発展版であり、画像のピクセルデータを人間が抽象ベクトルに変換することなく、画像データのままの状態で特徴を抽出させるという特徴があります。
そんな畳み込みニューラルネットワークでは、初めに画像データの一部分にフィルターをかけて演算し、その領域のスライドを繰り返していく「畳み込み」を行って特徴マップの生成を行います。この処理を行うことで、画像が持っている局所的な特徴の抽出が可能になるのです。
なお、畳み込みニューラルネットワークの中でも特に注目を集めている存在として、GoogLeNetが挙げられます。GoogLeNetは、2014年に行われた画像分類チャレンジコンテスト「ISLVRC-2014」で優勝したモデルです。22層という多くの層を持った「事前学習済みの畳み込みニューラルネットワーク」として大きな注目を集めています。
VAE(変分オートエンコーダ)とは、ディープラーニング(深層学習)のモデルの一つです。通常のオートエンコーダの場合、教師なし学習の一つであるため、学習時の入力データは訓練データのみとなり、教師データは利用しません。
大きく異なる点としては、通常のオートエンコーダの潜在変数zに確率分布、通常「z∼N(0,1)z∼N(0,1)」を仮定したところが挙げられます。通常のオートエンコーダーの場合、何かしら潜在変数zにデータを押し込めていますが、その構造まではよくわかりません。その点、VAE(変分オートエンコーダ)は潜在変数zを確率分布という構造に押し込むことが可能です。
GAN(敵対的生成ネットワーク)とは、生成モデルの一種であり、データから特徴を学習することによって実在しないデータを生成したり、存在するデータの特徴に沿って変換したりすることができます。そんなGAN(敵対的生成ネットワーク)は、正解データを与えずに特徴を学習していく「教師なし学習」の一つとして大きな注目を集めており、アーキテクチャの柔軟性が高いことから、アイデア次第ではより多様な領域にも活用していくことが可能です。最近では、応用研究や理論的研究も積極的に進められているため、今後さらに発展していく可能性が高いでしょう。
画像認識を実現するために、よく使われているライブラリについて、それぞれの特徴を見ていきましょう。
OpenCVは、インテル社が開発した画像解析フリーソフトです。正式名称は「Intel Open Source Computer Vision Library」といい、オープンソースのC/C++ライブラリ集となっています。コンピューター・ビジョンに必要となるさまざまな機能が搭載されています。
画像認識ライブラリーの「OpenCV」と、小型のシングルボードコンピューター「Raspberry Pi」を活用することで、画像認識を行うプログラムを作成することが可能です。具体的には、「Raspberry Pi」にカメラモジュールを接続して画像撮影し、「OpenCV」があらかじめ準備した機械学習結果データを参照して「捉えた画像が人の顔かどうか」を判別していくというものになります。
たとえば、人の顔と目を枠で囲んで撮影するプログラムであったり、人の顔を判別したときにシャッターを切るプログラムであったり、動画内で顔に追従して枠を表示させるプログラムだったりと、さまざまなカスタマイズの余地があるでしょう。
TensorFlowは、圧倒的な利用者数を誇るフレームワークです。Googleが2015年に開発した機械学習のソフトウェアライブラリであり、巨大なコミュニティとしても知られています。また、ライブラリが豊富で高速処理できる点も大きな特徴です。
TensorFlowの大きな特徴としては、ニューラルネットワークの構築が行える点、訓練ができるシステムの要求に応えられる点が挙げられるでしょう。ニューラルネットワークは、我々人間の脳内にある神経細胞(ニューロン)のつながりを数式的なモデルで表したものであり、ニューラルネットワークを使用することで機械も人間と同じような論理的思考や学習を行えるようになります。
Pillowは、画像処理ライブラリの一つであり、主にリサイズやトリミングといった基本的な処理を行いたい場合に用いられます。処理の内容によって異なりますが、画像認識などの高度な画像処理を行うことができるOpenCVと比較すると、単純な操作で画像処理を行うことが可能です。
PyTorch(パイトーチ)とは、Facebookが主な開発を担当したPython向けの機械学習ライブラリです。コードが書きやすく、使いやすいという特徴があり、開発者からも支持を得ています。そんなPyTorchは、2016年に初版が公開されてから少しずつ注目度を高めており、最近ではPythonの機械学習ライブとして高い人気を誇るライブラリに成長しました。
このPythonを利用するメリットとしては、直感的にコードを書けることが挙げられるでしょう。Pythonの機械学習プロセスで多く利用されるライブラリ「Numpy」と操作方法が似ており、目視しやすいため、PythonエンジニアであればすぐにPyTorchを使いこなすことができるでしょう。
また、参照リソースが豊富であるというメリットもあります。コミュニティが活発であるため、操作方法や実装する上で必要な情報を簡単に入手することが可能です。
さらに、「define by run」という点も大きなメリットといえます。define by runとは、動的なニューラルネットワーク構築のことであり、データを入力した際に定義する手法の一つです。「データを流しながら計算グラフの構築を行えるアルゴリズム」と考えれば分かりやすいでしょう。
scikit-imageとは、画像処理に特化したPython 画像ライブラリのことです。基本的な画像変換や特徴抽出など、OpenCVと似たような機能が多く搭載されています。scikit-imageを利用するメリットとしては、「NumPy」「SciPy」「Pandas」「Matplotlib」といった他のライブラリとやり取りしやすい点が挙げられるでしょう。
また、ドキュメントが充実していることや、機械学習ライブラリの「scikit-learn」と組み合わせやすいことなども大きなメリットといえます。そのため、画像処理と機械学習アルゴリズムを組み合わせたい場合には、OpenCVではなくScikit-imageのほうがおすすめといえるでしょう。

Eコマースの世界的大手、中国のアリババ・グループは、早くからオンライン通販サイトに画像認識技術を取り入れています。
アリババの通販サイトである「淘宝(タオバオ)」や「天猫(Tmall)」では、欲しい商品の写真をアップロードすると、サイトに掲載されている膨大な商品の中から類似のものを検索することが可能です。
アリババによると、Eコマースプラットフォームに関するユーザーのクレームは大きく2つに集約されるといい、一つは「欲しいアイテムを見つけるのが困難」、もう一つは「アイテムが豊富すぎて混乱する」というものだといいます。そのため、自分の欲しい商品写真をアップロードするだけで類似商品を探し出すことができる画像検索は、こうしたユーザーのクレームを解決する手段として極めて有効なものといえるでしょう。
ちなみに、この技術を支えているのは、機械学習とディープラーニングを活用したアリババ独自の画像検索エンジン「Image Search」というものです。アリババは2009年に画像認識や文字認識を研究する研究所、図像和美研究団を自社内に設立しており、人工知能による商品検索アルゴリズムを開発しています。

農業において特に負担の大きい「収穫」や「仕分け」といった作業の自動化を図るAIにも画像認識技術が活用されており、注目を集めています。そのAIが注目を集めるきっかけとなったのは、静岡県湖西市の農家、小池誠氏のAIを活用した取り組みでした。
小池氏は、もともと自動車部品メーカーでソフトウェアエンジニアとして勤めていた経歴の持ち主であり、その経験を活かしてキュウリの仕分けを行う機械を自作したといいます。ここで注目すべきなのは、この機械にAIが搭載されているという点です。ディープラーニングによる画像認識技術を用いることによって、本来であれば膨大な時間が必要となるキュウリの仕分け作業を自動で選別できるようになったのです。
その仕組みとしては、はじめにベテランが仕分けたキュウリの画像を教師データとしてAIに学習させ、AIがキュウリの等級を見分けていくというもの。使い方も非常にシンプルで、アクリル板の上にキュウリを乗せるとカメラが自動で撮影を行い、その画像データから「長さ」「太さ」「曲がり具合」などを解析して出荷基準を満たすか判別していきます。
はじめから高い精度で見分けられたわけではないそうですが、改良を重ねることで8割程度の正答率まで高めることができたといいます。最終的な選別は小池氏が行っているため、あくまでもサポート役という位置付けではありますが、このAIを導入したことによって作業効率は4割ほど高まっているそうです。
蓄積するデータの量が増えるにつれて判別の精度も高めていくことができますから、今後さらにこのAIの正答率も高まっていくでしょう。

画像認識技術を活用したシステムは来店者の情報を可視化することができるという特徴があるため、防犯や本人認証といった目的に加え、マーケティングにも活用され始めています。たとえば、AIが搭載されているカメラを店舗に搭載した場合、顔認証や画像認識の技術によって来店者のさまざまな情報を可視化することができるようになります。その一例としては、以下のような情報が挙げられるでしょう。
主にこれらの情報を可視化することが可能になるため、防犯という観点だけでなく、より売上を向上させるためのマーケティングとして活用していくことができるわけです。これは、AIを搭載しているカメラだからこそ実現できる大きなメリットといえるでしょう。
実際、2017年11月にオープンした東京・上野の商業施設「PARCO_ya(パルコヤ)」では、テナントの約9割にあたる60店舗が店内にAI搭載のカメラを設置しており、撮影した画像をマーケティングに活用しているそうです。画像をAIで分析することにより、来店者数や時間別の推移などが可視化できるようになったため、スタッフの人員体制を効率化したり、商品ラインナップや陳列場所の見直しを行ったりすることができるようになったといいます。
なお、「PARCO_ya(パルコヤ)」を運営しているパルコの発表によると、画像認識技術が売り上げ増に直接的な影響を与えているわけではないものの、8割の来店客の客層が「ターゲット層(30代〜50代の女性)」と一致していることが判ったといいます。想定したターゲット層を集客できているという事実を確認できたことにより、今後どのような戦略を立てていくべきかの判断を明確に行えるようになるため、長期的な利益の増加に貢献していくと考えられるのではないでしょうか。
東京都品川区に本社を置くオルビス株式会社では、現在の肌状態や手入れの習慣から未来の肌状態を予測して、いま必要なお手入れ方法を提案する「AI 未来肌シミュレーション」というサービスを提供しています。このサービスには、東京都品川区に本社を置くフューチャーアーキテクト株式会社の深層学習、画像認識技術が活用されています。
この「AI 未来肌シミュレーション」は、店舗に設置されているオルビス社独自のスキンチェック機やスマホを活用してAIが現在の肌状態を分析し、10項目の肌スコアを測定するというもの。そして、現在のお手入れ状況や生活習慣などをもとに、5年後、10年後、20年後の肌を予測するという仕組みです。
複雑な美容理論を学習しているため、20兆以上の評価パターンから一人ひとりの肌トラブル進行パターンを導き出し、深層学習による顔画像生成によって未来の肌をシミュレーションできるという点は大きな特徴といえるでしょう。
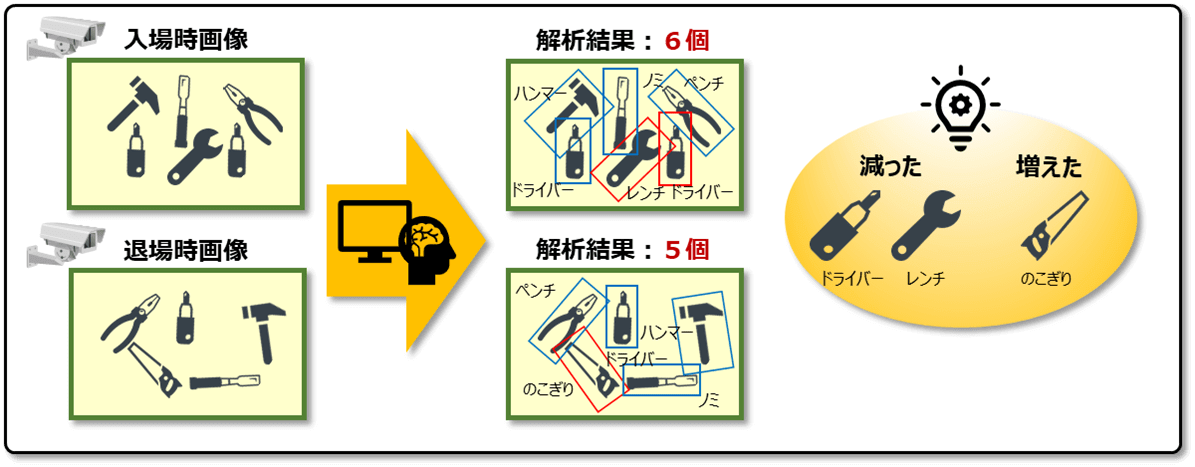
日立ソリューションズでは、画像認識AI(人工知能)技術を活用し、作業現場において作業員が入退場時に所持している物品の差異を自動でチェックできる「持込持出物品チェックAIソフトウェア」を2021年3月10日から販売開始しました。
この製品では、作業員が作業現場の入場時に持ち込んだ物品の画像を退場時に持ち出す物品の画像と比較することで、置き忘れや、余分な持ち出しなどのチェックを自動化できます。これにより、これまで1個ずつ目視でチェックしていた物品管理作業の自動化が可能になり、現場管理者の業務負担や作業員の入退場待ち時間を低減できます。
ハンマーやドライバー、レンチなどの一般的な工具の画像をすでに学習し、事前学習が不要なAIを活用しているため、企業は製品をすぐに利用できます。自社内の検証環境で行われた実証実験で46件の画像を比較した結果、物品の増減を正確に判定できたそうです。
本ソフトウェアの開発・販売に至った背景としては、建設業や運輸業、製造業などにおいて、新型コロナウイルス感染症拡大の影響や、少子高齢化による作業員不足で業務における省力化、効率向上が急務になっていたことが大きな要因となったそうです。また、近年はAIを活用したデジタルトランスフォーメーションを推進し、生産性向上につなげる動きも広がっています。
さらに、建設や鉄道・飛行機などの点検・保守を行う作業現場では、作業員が持ち込んだ工具の置き忘れが重大な事故につながるケースも少なくありません。そのため、入退場時の物品管理作業が行われています。そこで日立ソリューションズは、これまで現場管理者が目視で行っていた入退場時の物品管理作業を、画像認識AI技術を活用して効率化できる本ソフトウェアの開発・販売に至ったというわけです。
日立ソリューションズが販売するソフトウェアでは、入退場時の画像を比較し、物品の増減を正確に判定することができます。どの物品が増減したかの特定も可能です。これにより、物品管理作業の精度向上と省力化を実現することができます。
また、作業員が使うハンマーやドライバー、レンチなどの一般的な工具を学習済みのAIを活用することで、PCにソフトウェアをインストールするだけですぐに利用できます。さらに、業種特有の物品を判定したい場合は、追加でAIに学習させることが可能です。
今回の記事では、機械学習を活用した画像認識アルゴリズムの詳細について、事例を交えながらご紹介しました。複数の領域で活用され始めている画像認識技術は、今後も活用の幅が広がっていくことが期待されます。画像認識がどのような効果をもたらし、社会にどのような変化が生まれていくのか、ますます目が離せません。
コンピューターや機械が「画像に何が写っているのか」を認識したり分析したりする技術のことを画像認識と呼びます。
画像認識を実現させるための機械学習アルゴリズムの代表例として、以下が挙げられます。
代表的なサービスとして、以下が挙げられます。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!









AI製品・ソリューションの掲載を
希望される企業様はこちら