

GPT-Realtime-2とは?OpenAI新音声3モデルの違い・料金・使い分けを徹底解説
最終更新日:2026/06/24

OpenAIは2026年5月、Realtime API向けに音声インテリジェンスを大きく前進させる新モデル3種を一挙に公開しました。
中核となる「GPT-Realtime-2」はGPT-5クラスの推論能力を備えた音声対話モデルで、リアルタイム音声翻訳に特化した「GPT-Realtime-Translate」、低遅延の文字起こしに特化した「GPT-Realtime-Whisper」とあわせて発表されています。
本記事では、これら3モデルの明確な違いや料金コストの比較、業務シナリオに応じた最適な使い分けを徹底解説します。さらに、前世代からの移行手順や日本語環境で導入する際の注意点まで網羅しているため、自社システムへのスムーズな実装イメージがすぐに湧くようになります。
GPT-Realtime-2とは?
画像引用元:OpenAI公式:Advancing voice intelligence with new models in the API
まず、GPT-Realtime-2とはどのようなAIモデルであるか、概略や発表の背景を紹介します。
GPT-Realtime-2の概略
「GPT-Realtime-2」は、OpenAIがRealtime API向けに提供する、GPT-5クラスの推論能力を備えたリアルタイム音声対話モデルです。最大の特徴は、音声入力を一旦テキストに変換せずに、音声のまま直接処理して音声で応答する「speech-to-speech(音声→音声)」方式を採用している点にあります。
従来の音声AIの多くは 音声認識(STT)→言語モデル(LLM)→音声合成(TTS)という多段階のパイプラインを経由していました。
GPT-Realtime-2はこのパイプラインを介さず音声を直接処理するため、レイテンシ(応答までの遅延時間)を抑えやすく、笑い声や口調といった非言語的なニュアンスも保ったまま会話を進められます。「話しかけたら返事をする」だけの音声AIから、「聞き取り・推論・ツール呼び出しを通じて行動する」音声インターフェースへと進化したモデルです。
【参考】OpenAI公式:Advancing voice intelligence with new models in the API
Realtime APIとは
Realtime APIは、OpenAIが提供する双方向音声をリアルタイムでやり取りするためのAPIです。今回紹介する3モデルは、いずれもRealtime APIを経由して利用します。
用途に応じて、以下3種類の接続方式に対応しています。
| 接続方式 | 説明 |
|---|---|
| WebRTC | ブラウザ間でリアルタイムに音声・映像を送受信するためのプロトコル。ブラウザ/モバイルアプリの音声UI向け |
| WebSocket | 双方向の通信セッションを維持するためのプロトコル。サーバーサイドからのAPI連携向け |
| SIP(Session Initiation Protocol) | 電話システムで呼制御に使われるプロトコル。既存の電話・コンタクトセンター基盤との統合向け |
ブラウザベースの音声アプリならWebRTC、サーバー間の連携が中心ならWebSocket、コールセンターなど電話網と統合するならSIPが基本的な選択基準です。
なお、Realtime API自体は2025年8月にベータを卒業し、本番運用前提の一般提供(GA:General Availability)へすでに移行しています。その際に新音声「Cedar」「Marin」も追加されました。今回の3モデルは、このGA済みのRealtime API上で動作します。
3モデルが発表された背景
OpenAIは2026年5月7日(米国時間/日本時間5月8日)、Realtime API向けの新しい音声モデル群を発表しました。同時に公開されたのは、「GPT-Realtime-2」「GPT-Realtime-Translate」「GPT-Realtime-Whisper」の3モデルです。
この3モデルが同時に投入された背景には、音声がソフトウェア操作の自然なインターフェースになりつつある現状が挙げられます。実用的な音声体験には、速い応答や自然な声だけでなく、ユーザーの意図の理解・文脈の維持・割り込みへの対応・ツールの活用といった多くの要素が求められます。
今回のリリースは、こうした要件に応える形で、リアルタイム音声を「応答するだけ」の仕組みから、聞き取り・推論・翻訳・文字起こしを行い、必要に応じて行動する音声インターフェースへと押し上げることを狙ったものです。
すでにGA化されているRealtime APIに対話・翻訳・文字起こしの3モデルが加わったことで、音声API群を業務システムへ本格的に組み込む選択肢が広がりました。
【参考】OpenAI Realtime API ドキュメント
新しい3つの音声モデルを解説
ここからは、今回公開された3モデルがそれぞれ何をするモデルなのかを個別に確認します。
3モデルは互いに置き換え合うものではなく、対話・翻訳・文字起こしと、それぞれ異なる役割を担うモデルとして設計されています。
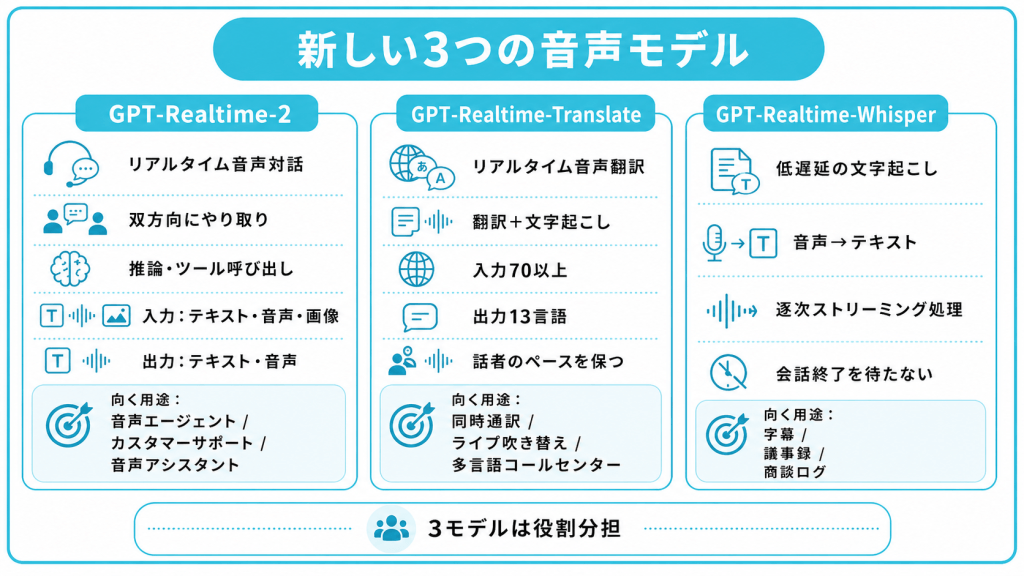
GPT-Realtime-2
GPT-Realtime-2は、リアルタイムの音声対話を担う中核モデルです。会話を途切れさせることなく、要求に対して推論→ツール呼び出し→修正・中断への対応→応答を行います。入力はテキスト・音声・画像、出力はテキスト・音声に対応します。
位置づけとしては、3モデルのなかで唯一ユーザーと双方向にやり取りしてタスクを完遂する役割を担うフラッグシップの推論モデルです。音声カスタマーサポート・業務エージェント・音声アシスタントなど、会話そのものを成立させる必要がある用途に向いています。
GPT-Realtime-Translate
GPT-Realtime-Translateは、多言語対応のライブ音声体験を構築するための専用モデルです。ユーザーが好きな言語で話すと、その音声は話者のペースを保ったままリアルタイムに翻訳され、文字起こしも同時に表示されます。
対応する入力言語は70以上、出力言語は13言語(日本語を含む)です。発話のリズムや文脈の切り替わり、地域特有のアクセントや専門用語を含む会話でも、遅延を抑えながら意味を保つことを目指しています。同時通訳・ライブ吹き替え・多言語コールセンターなど、異なる言語の話者をつなぐ用途に最適です。
GPT-Realtime-Whisper
GPT-Realtime-Whisperは、低遅延でのストリーミング文字起こしに特化した音声認識モデルです。リアルタイムで音声をテキスト化できるため、字幕や議事録の作成などを、より速く自然な形で実現できます。
これまでのWhisperモデル群は、基本的にバッチ処理(一定区切りの音声ファイルをまとめて処理する方式)を前提とした構成だったのに対し、GPT-Realtime-Whisperは音声データが入力された端から逐次的に文字起こしを実行するように再設計されています。
会話の終了を待たずにテキスト化が完了するため、ライブ字幕・議事録・商談ログといった会話を文字情報として残す・即時表示する用途で活用できます。
3つのモデルを比較
3モデルの役割を押さえたところで、ここではどれを選ぶかを判断するために、横並びで比較し、料金と使い分けまで紹介します。
3モデルの比較
| 項目 | GPT-Realtime-2 | GPT-Realtime-Translate | GPT-Realtime-Whisper |
|---|---|---|---|
| 主な用途 | 音声対話エージェント/カスタマーサポート | リアルタイム音声翻訳 | ストリーミング文字起こし |
| モデルタイプ | speech-to-speech(音声→音声) | 音声翻訳(音声→音声+テキスト) | ストリーミング音声認識(音声→テキスト) |
| 対応言語 | 多言語対応(日本語含む) | 入力70以上/出力13言語(日本語含む) | 多言語対応 |
| コンテキスト長 | 128,000トークン | – | – |
| 最大出力トークン数 | 32,000トークン | – | – |
| 接続方式 | WebRTC・WebSocket・SIP | Realtime API経由 | Realtime API経由 |
GPT-Realtime-2のみが「100万トークン単位」のトークン課金、TranslateとWhisperは「1分単位」の分課金です。
トークンとは、モデル内部で文字列を扱う最小単位で、日本語の場合は1文字あたりおおむね1〜3トークンが目安となります。
【参考】GPT-Realtime-2 モデルページ(OpenAI)
3モデルの料金体系とコスト
OpenAIが公表している3モデルの料金は、2026年5月時点で以下のとおりです。
| モデル名 | 課金単位 | 料金(目安) |
|---|---|---|
| GPT-Realtime-2 | 100万トークン | 音声入力:32ドル 音声出力:64ドル キャッシュ済み入力:0.40ドル |
| GPT-Realtime-Translate | 1分 | 0.034ドル |
| GPT-Realtime-Whisper | 1分 | 0.017ドル |
分課金の2モデルは稼働時間から見積もりやすいのが利点です。たとえばGPT-Realtime-Whisperで1時間の会議を文字起こしするなら0.017ドル×60分でおおよそ1ドル前後、GPT-Realtime-Translateで1時間の同時通訳を行うなら0.034ドル×60分でおおよそ2ドル前後が目安になります。
一方、GPT-Realtime-2はトークン課金のため、発話の長さ・推論強度・ツール呼び出しの頻度によってコストが変動します。
定型のシステムプロンプトや社内ドキュメントを繰り返し使う場合は、大きく割り引かれるキャッシュ済み入力(0.40ドル/100万トークン)の活用が、コストを抑えるうえで有効です。
なお、音声入力時はテキスト換算ではなく音声時間に応じたトークン数で課金される点にも留意してください。また上表のGPT-Realtime-2の金額は音声分のみで、テキスト入力・画像入力・テキスト出力にはそれぞれ別の料金が設定されています。
料金は更新頻度が高いため、本番運用前にはOpenAI公式のAPI Pricingで最新値を必ず確認してください。
3モデルの場面別使い分け
3モデルを選ぶ際の基本的な考え方は次のとおりです。
| 目的・ニーズ | 推奨モデル |
|---|---|
|
GPT-Realtime-2 |
|
GPT-Realtime-Translate |
|
GPT-Realtime-Whisper |
実運用では、3モデルを組み合わせるシナリオも現実的です。
たとえば多言語コールセンターでは、入力音声をGPT-Realtime-Translateで翻訳しつつ、GPT-Realtime-Whisperで全文ログを取り、エスカレーション時にGPT-Realtime-2による対話エージェントが応対に加わる、といった構成が想定されます。
GPT-Realtime-2の主な進化点3つ
ここまでは3モデル全体の役割と選び方を紹介してきました。
ここからは中核モデルであるGPT-Realtime-2に絞り、前世代のGPT-Realtime-1.5から何が変わったのかという時系列の差分を、推論能力・コンテキスト・エージェント向け機能の3つの観点で掘り下げます。
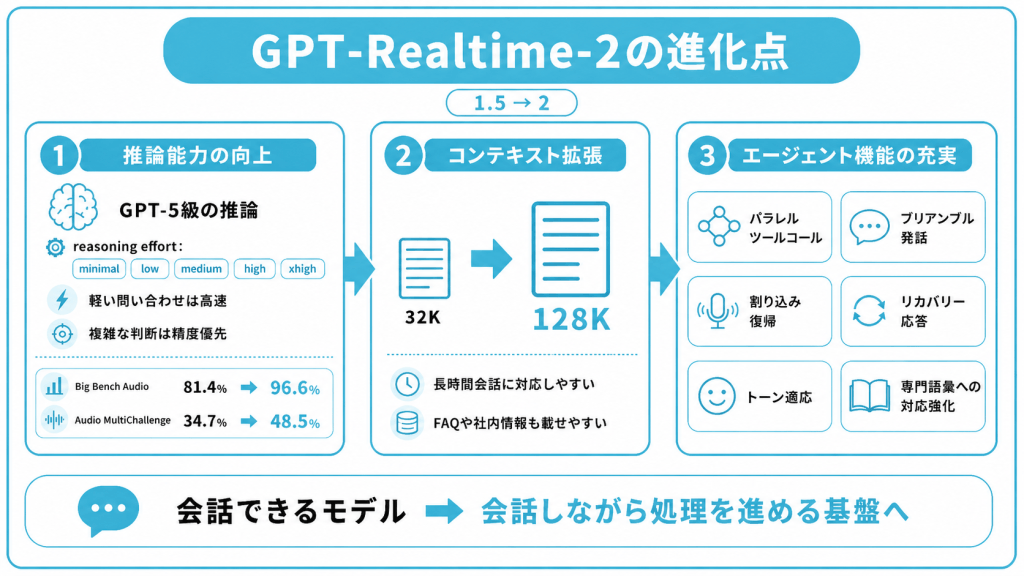
推論能力の向上
OpenAIはGPT-Realtime-2を、Realtime API初のGPT-5クラスの推論モデルと位置づけています。speech-to-speech方式を維持したまま推論深度を引き上げた点が、前世代との最大の違いです。
推論強度は、reasoning effortパラメータ(推論にどれだけ計算資源を割くかを決める設定値)により、minimal/low(既定)/medium/high/xhighの5段階から選択できます。
OpenAIは、業種名で固定的に割り当てるのではなく、タスクの複雑さ・応答速度の要件・失敗時の影響度をふまえて選ぶ考え方を示しています。おおまかな目安は次のとおりです。
| 推論強度 | 用途の目安 |
|---|---|
| minimal〜low | 低レイテンシを優先したい単純な操作や、注文確認・一般的な問い合わせ対応 |
| medium | 複数ステップの診断やテクニカルサポートなど、ある程度の判断を要する場面 |
| high〜xhigh | 高い正確さや慎重な判断が求められ、追加のレイテンシ・コストを許容できる場面(複雑な計画立案や重要なトリアージなど) |
タスクの性質に応じて推論強度を切り替えることで、軽い問い合わせは速く安く、複雑な相談は精度優先で処理する、といったコスト最適化が現実的になっています。
性能面でも前世代から明確に向上しており、OpenAIの公式発表によれば、GPT-Realtime-2はGPT-Realtime-1.5と比べて、音声推論を測るBig Bench Audioで15.2ポイント、マルチターン会話での指示遵守を測るAudio MultiChallengeで13.8ポイント改善しています。
| ベンチマーク | GPT-Realtime-2 | GPT-Realtime-1.5 |
|---|---|---|
| Big Bench Audio(high) | 96.6% | 81.4% |
| Audio MultiChallenge(xhigh) | 48.5% | 34.7% |
なお、これらのベンチマークはそれぞれ第三者機関(Big Bench AudioはArtificial Analysis、Audio MultiChallengeはScale AI)が開発・公開しており、OpenAIはこれらを用いて自社モデルを評価しています。
【参考】Big Bench Audio(Artificial Analysis) / Audio MultiChallenge(Scale AI)
コンテキストの拡張
コンテキストウィンドウ(モデルが一度に扱える入出力の最大トークン数)は、前世代の32,000トークンから128,000トークンへ4倍に拡張されました。
前世代では数十分の会話で履歴を切り詰める必要がありましたが、128Kあれば1〜2時間規模の長時間サポート通話や、社内ナレッジ・FAQをプロンプトに同梱するといった用途でも、履歴を切り詰めずに会話を継続しやすくなりました。
エージェント向け機能の充実
GPT-Realtime-2は単に音声モデルとして賢くなっただけではなく、業務エージェントとして組み込むための機能群も大きく強化されました。前世代から追加・強化された主な機能は次のとおりです。
パラレルツールコール(Parallel Tool Calls)
複数の関数・API・データベースを同時並行で呼び出し可能。「在庫を確認しつつ配送日を計算し、顧客プロファイルも参照する」といった処理を直列ではなく並列で実行できる機能です。
プリアンブル発話
ツール呼び出し中の沈黙を埋めるために「ちょっと確認しますね」「少々お待ちください」といったつなぎ発話を自動生成できます。
割り込み復帰(interruption recovery)
ユーザーが途中で話をさえぎっても、文脈を維持したまま会話を再開する機能です。
リカバリー応答
ツール呼び出しに失敗した際も無言にならず、「今その処理で問題が発生しています」と状況を音声で伝えてくれます。
トーン適応
問題解決中は落ち着いた口調・苛立っているユーザーには共感的な口調・解決時には明るい口調と文脈に応じて声色やテンポを調整してくれます。
専門語彙への対応強化
医療用語・固有名詞・業界特有の用語の保持精度が向上しています。
これらの機能により、GPT-Realtime-2は会話できるモデルから会話しながら処理を進めるエージェント基盤へと進化しています。
【参考】OpenAI公式:Advancing voice intelligence with new models in the API
3モデルの活用シーン
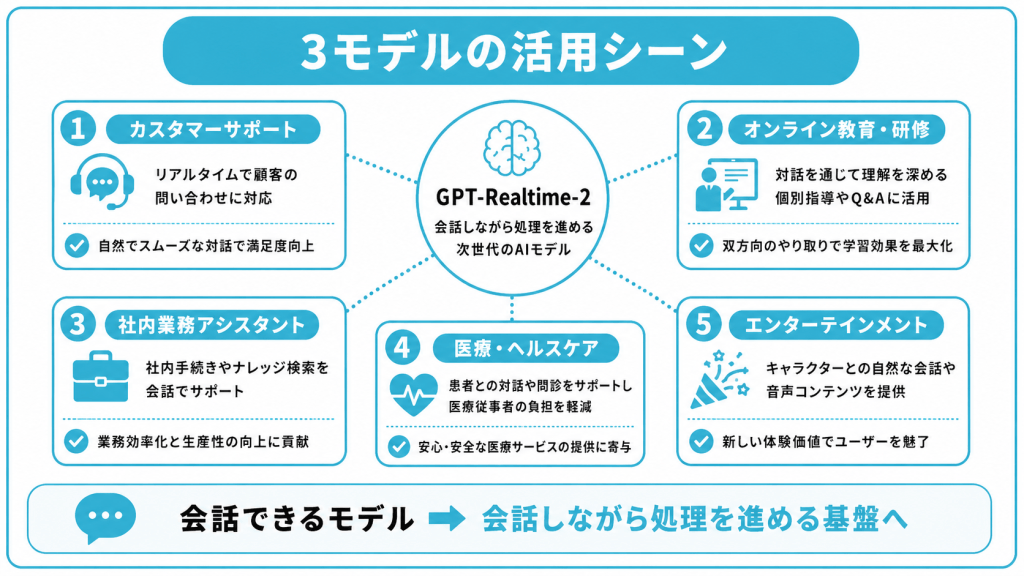
3モデルが組み合わさることで、これまで音声AIでは扱いにくかった業務領域が一段と現実的になってきています。OpenAIの公式発表や早期テストの事例をもとに、想定される活用シーンをまとめました。
カスタマーサポート
対話モデル(GPT-Realtime-2)を一次対応に据え、文字起こしモデル(GPT-Realtime-Whisper)で対話履歴を全文ログ化し、翻訳モデル(GPT-Realtime-Translate)で海外顧客の応対を多言語化する構成が可能です。
通信大手のDeutsche Telekomも、カスタマーサポートや多言語コミュニケーションの分野で早期テストに参加していることが公表されています。
通訳
GPT-Realtime-Translateを用いて、ウェビナー・社内グローバル会議・海外向けライブイベントなどでの同時通訳が想定されます。動画プラットフォームのVimeoなども早期利用者として名前が挙がっており、コンテンツ配信領域での応用も模索されています。
字幕
GPT-Realtime-Whisperは、会議・授業・放送・イベントといった「進行中の発話をすぐにテキスト化したい」場面で効果を発揮します。会話の終了を待たずに字幕を生成できるため、視聴者への即時情報提供や、アクセシビリティ向上に直結します。
議事録
GPT-Realtime-Whisperで会話を逐次文字起こしし、要約やメモを会話と並行して生成することで、議事録作成の負荷を削減できます。生成されたテキストは、後続の業務プロセスの自動化や、検索可能なログとしての保管にもそのまま生かせます。
業務エージェント
GPT-Realtime-2のパラレルツールコールと長いコンテキストを活かして、複数条件を一度の音声指示で処理する業務エージェントが構築しやすくなっています。
OpenAIが公開する早期事例では、不動産情報プラットフォームのZillowが、「特定エリア内」「大通りを避ける」「予算枠内」「土曜日の内見」といった複合条件を音声で受け取り、データベース検索とスケジュール調整までを自動化するアシスタントを開発しています。
プロンプト最適化後には、最難関タスクの達成率が69%から95%へ向上したとされます。旅行領域では、Pricelineがフライト検索から遅延時の予約変更、現地での翻訳対応までを音声で完結させる構想に取り組んでいます。
【参考】Advancing voice intelligence with new models in the API | OpenAI
GPT-Realtime-2利用時の注意点
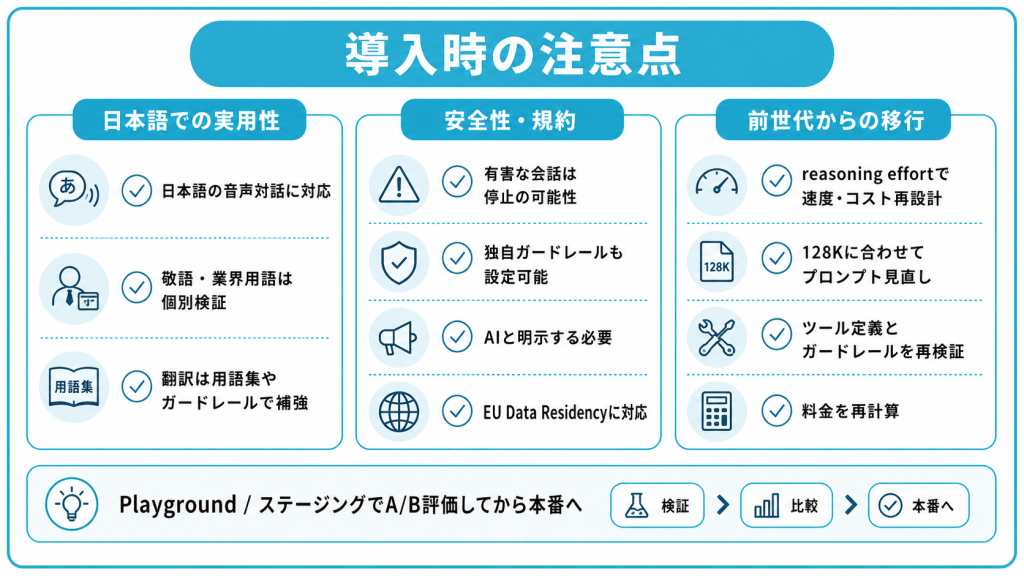
3モデルはいずれも本番運用を前提に提供されていますが、日本語環境で導入する際の注意点を事前に整理しておきましょう。
日本語での実用性
GPT-Realtime-2はマルチリンガル対応で、日本語での音声対話も可能です。
ただし、Big Bench AudioやAudio MultiChallengeといったベンチマークは英語ベースの評価が中心であり、日本語固有の表現・敬語・業界用語に対する精度については、自社のユースケースで個別に検証する必要があります。
GPT-Realtime-Translateの出力13言語にも日本語は含まれており、入力・出力の双方で日本語を扱えます。
ただし、ニュアンスを保った翻訳や専門用語の精度が業務に直結する場合は、用語集や追加ガードレールでの補強を前提に設計するのが現実的です。
安全性・規約
Realtime APIには、有害なやり取りを検出する分類器(クラシファイア)が組み込まれており、ポリシー違反が疑われる会話は停止される場合があります。これに加えて、開発者側でもAgents SDKを通じて独自の安全ガードレールを設定できます。
OpenAIの利用ポリシーでは、スパムや詐欺など有害目的での利用が禁止されています。また、ユーザーがAIとやり取りしていることを明示的に伝える義務が課されている点にも注意が必要です。
電話自動応答や音声エージェントを設計する際は、冒頭のアナウンスや画面UIでの明示など、運用面での対応が求められます。EU向けのアプリケーションでは、EU圏内でのデータ保持(EU Data Residency)にも対応しています。
【参考】OpenAI 利用ポリシー
前世代からの移行
すでに前世代のGPT-4o-Realtime-PreviewやGPT-Realtime-1.5を使ったシステムを運用している場合、GPT-Realtime-2への移行にあたっては、次のような観点を確認しておく必要があります。
- 推論強度(reasoning effort)の追加に伴い、レイテンシとコストの設計を見直す
- コンテキストウィンドウ拡張に合わせて、プロンプトを再設計する(長文プロンプトを安全に使えるか)
- パラレルツールコールに合わせて、ツール定義を組み直す
- 既存のシステムプロンプトやガードレールが、新モデルでも意図どおり動くかを検証する
- 料金体系(特にキャッシュ済み入力単価との組み合わせ)を再計算する
価格・性能の双方が大きく動いたアップデートのため、まずはPlaygroundやステージング環境で現行プロンプトとのA/B評価を行ったうえで、本番反映を判断する流れが安全です。
まとめ
今回の3モデルは、Realtime APIを「音声で応答するだけのAPI」から、推論・翻訳・文字起こし・ツール実行を組み合わせた音声インターフェース基盤へと広げるアップデートです。
GPT-Realtime-2は、GPT-5級の推論能力・128Kコンテキスト・パラレルツールコール・プリアンブル発話・トーン制御などを備えた中核モデルです。一方、GPT-Realtime-Translateは70以上の入力言語から13言語へのリアルタイム翻訳を、GPT-Realtime-Whisperは低遅延の逐次文字起こしを担い、それぞれの役割が分かれています。
導入を検討する際は、まず3モデルを「対話/翻訳/文字起こし」のどの軸で使い分けるかを決め、Playgroundで挙動と精度を確認したうえで、Realtime API経由で本実装する手順が一般的です。料金は更新が早いため、本番設計時にはOpenAI公式の最新情報を必ず確認しながら進めてください。
アイスマイリーでは、生成AIのサービス比較と企業一覧を無料配布しています。課題や目的に応じたサービスを比較検討できますので、ぜひこの機会にお問い合わせください。
よくある質問
GPT-Realtime-2は日本語に対応していますか?
対応しています。GPT-Realtime-2はマルチリンガル対応で、日本語での音声対話が可能です。ただし、公開されているベンチマークは英語ベースの評価が中心のため、日本語の敬語や業界用語に対する精度は、実際のユースケースで個別に検証することをおすすめします。
GPT-Realtime-2はChatGPTのアプリで使えますか?
このモデルはRealtime API向けに提供されており、ChatGPTのアプリ画面で直接利用するものではありません。利用するには、OpenAI APIアカウントを用意し、Realtime API(WebRTC/WebSocket/SIP)経由で自社アプリに組み込むか、まずはPlayground環境でテストします。
3モデルはどう使い分ければよいですか?
双方向の音声対話でタスクを完遂したいならGPT-Realtime-2、異なる言語の話者をつなぎたいならGPT-Realtime-Translate、会話を文字情報として残したい・字幕表示したいならGPT-Realtime-Whisper、が基本の使い分けです。多言語コールセンターのように、3モデルを組み合わせて構成するケースも想定されています。
料金はどれくらいかかりますか?
GPT-Realtime-2は音声入力が100万トークンあたり32ドル、音声出力が100万トークンあたり64ドル(キャッシュ済み入力は0.40ドル)のトークン課金です。GPT-Realtime-Translateは1分あたり0.034ドル、GPT-Realtime-Whisperは1分あたり0.017ドルです。料金は更新頻度が高いため、最新値はOpenAI公式のAPI Pricingで確認してください。
前世代のモデルから移行する際の注意点は?
推論強度の追加に伴うレイテンシ・コスト設計の見直し、128Kへ拡張されたコンテキストを活かすプロンプト設計、パラレルツールコールに合わせたツール定義の組み直し、既存ガードレールの検証、料金の再計算などが必要です。本番反映の前に、Playgroundやステージング環境で現行プロンプトとのA/B評価を行うのが安全です。
- AIサービス
- ChatGPT
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI














FOLLOW US
SNSをフォローして、最新情報をチェックできます!

リコーとライズ・コンサルティング・グループ、AI実装・活用を一貫…
近畿大学病院など4者、リアルワールドデータとLLMを用いた共同研…
LINEヤフー、「LINE」新機能「Agent i in cha…
Sakana AI、「Sakana Chat」に翻訳機能を追加。…

ChatGPTの育て方とは?自分好みに育てる方法とコツを解説

ChatGPTカスタム指示のおすすめ設定例と効果的な書き方を解説

OpenAI、新世代音声モデル「GPT-Live」公開。全二重アーキテクチャ搭載で自然な音声対話を実現

高校生の生成AI活用に関する意識調査を実施。恋愛・人間関係の相談相手は生成AIが44.2%で1位

GPT-Liveとは?OpenAI最新音声モデルの仕組み・使い方・料金を解説

ChatGPTでスライド作成する方法とプロンプトのコツを徹底解説
AI製品・ソリューションの掲載を
希望される企業様はこちら