

LINEヤフー、高性能な日本語マルチモーダル基盤モデル「clip-japanese-base-v2」を公開
最終更新日:2025/12/22
 日本語マルチモーダル基盤 公開
日本語マルチモーダル基盤 公開
LINEヤフーのFoundation Models研究開発チームは、日本語マルチモーダル基盤モデル「clip-japanese-base-v2」を公開しました。
このニュースのポイント
- LINEヤフーは、日本語マルチモーダル基盤モデル「clip-japanese-base-v2」を公開
- 「clip-japanese-base」の学習データと学習方法を改善し、高性能化したモデル
- 以前のバージョンと比較し、フィルタリング前の画像サンプル数を18億件増加
LINEヤフー株式会社のFoundation Models研究開発チームは、日本語マルチモーダル基盤モデル「clip-japanese-base-v2」を公開しました。
「CLIP」は、画像と言語の代表的なマルチモーダル基盤で、インターネットから収集した大規模データで学習することで、ゼロショットでの分類や検索が可能です。
今回の「clip-japanese-base-v2」は、同チームが以前に公開した「clip-japanese-base」を、学習データと学習方法を改善し、高性能化したモデルです。
開発にあたって、Common Crawlから収集した日本語の画像・テキストペアデータを主に使用しています。以前のバージョンと比較して、フィルタリング前の画像サンプル数を18億件増加させています。
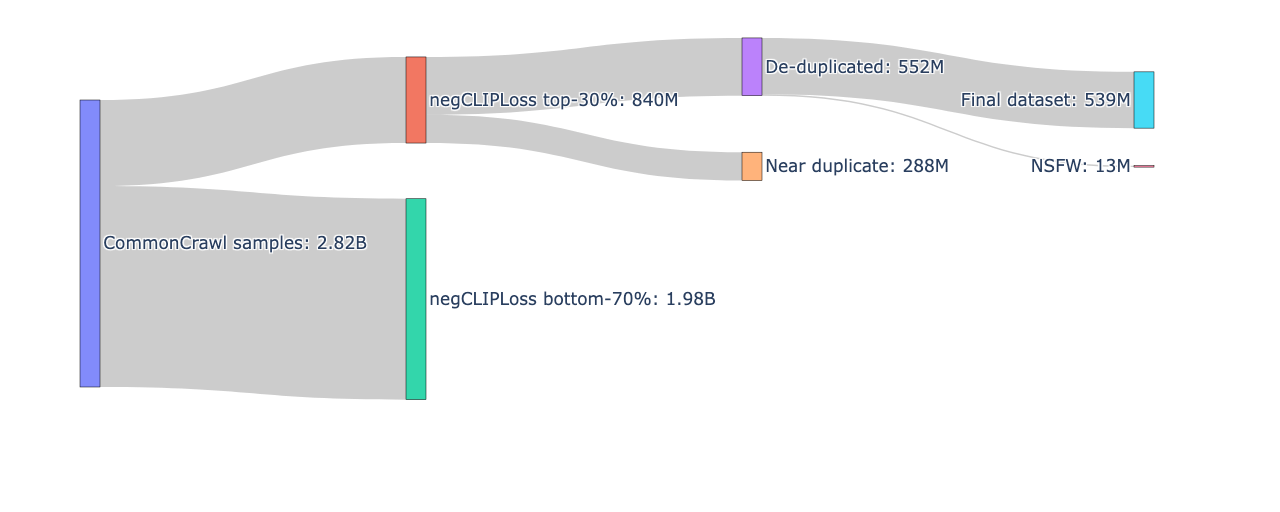
また、画像とテキストが無関係なデータを除去するため、従来のCLIP-scoreに代わりnegCLIPLossという新しい指標を採用し、最終的には5.4億件の高品質な画像・テキストペアを学習データとして使用しています。
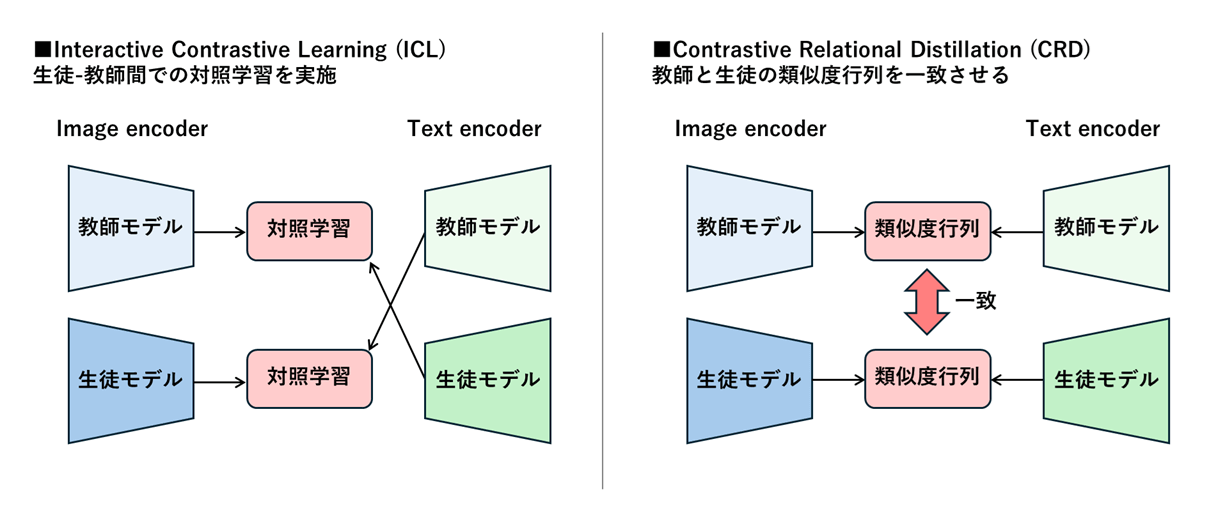
「clip-japanese-base-v2」は、学習データの更新に加え、知識蒸留による高精度化にも取り組んでいます。知識蒸留とは、大規模で高精度なモデル(教師)が持つ知識を、小さく軽量なモデル(生徒)に受け渡し、小さいモデルで高い性能を発揮できるようにする手法です。
先行研究であるCLIP-KDを参考に実験を行った結果、Interactive Contrastive Learning (ICL)と Contrastive Relational Distillation (CRD)の組み合わせが最も有効でした。今回は、CRDに対して独自の改良を加えることで大幅な精度改善に成功しました。
| モデル | パラメータ数 | 平均性能 | ImageNet-1k | Recruit | WAON-Bench | STAIR Captions |
|---|---|---|---|---|---|---|
| clip-japanese-base-v2 (Ours) | 196M | 0.708 | 0.666 | 0.913 | 0.975 | 0.277 |
| clip-japanese-base | 196M | 0.673 | 0.580 | 0.884 | 0.934 | 0.293 |
| waon-siglip2-base-patch16-256 | 375M | 0.664 | 0.555 | 0.872 | 0.951 | 0.276 |
| siglip2-base-patch16-224 | 375M | 0.579 | 0.517 | 0.802 | 0.871 | 0.126 |
| siglip2-so400m-patch14-224 | 1135M | 0.642 | 0.643 | 0.837 | 0.925 | 0.163 |
既存の公開モデルと比較すると、「clip-japanese-base-v2」のモデルパラメータが最も少なく、他の日本語特化やマルチリンガルモデルよりも高い性能を示しています。
LINEヤフーは、「今後も構築したモデルの一部を継続的に公開しますので、今後の展開にもぜひご期待ください」とコメントしています。
出典:LINEヤフー
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
ChatGPT連携サービス

チャットボット

AI-OCR

生成AI
ChatGPT連携サービス
チャットボット
AI-OCR










FOLLOW US
SNSをフォローして、最新情報をチェックできます!

Sakana AI、初の商用プロダクトとなるビジネス向け自律型リ…

クラダシ「Claude」を全社展開。特有業務の自動化の推進および…

日米欧中韓の五大特許庁、東京で五庁長官会合を開催。AI分野の新た…
デンソーテン、独自の埋め込みモデル学習技術により車載エッジでRA…

カゴメなど5者、AI選果機の共同開発と実証の成果を発表。トマトの廃棄ロスを30%低減

Google Cloud、Nano Banana 2とNano Banana Proの一般提供を開始。動画の内容に合った画像を生成

Preferred Networks、国産生成AI基盤モデル「PLaMo 3.0 Prime」を正式提供開始。

Sakana AI、マルチエージェント基盤「Sakana Fugu」提供開始。一部ベンチマークで「Fable 5」「Mythos Preview」と同等性能

Genki Global Dining Concepts、全生け簀へのAI給餌機導入で国産真鯛の安定供給を強化

三菱重工とPFNが業務提携。ミッションクリティカル領域の国産AI技術の共同開発へ
AI製品・ソリューションの掲載を
希望される企業様はこちら