

生成AI

最終更新日:2025/12/02
 パナソニックHD LaViDaを開発
パナソニックHD LaViDaを開発
パナソニックHDとPRDCAは、UCLAの研究者らと共同で、拡散モデルを用いたマルチモーダルAI「LaViDa」を開発しました。
このニュースのポイント
パナソニックホールディングス株式会社と、パナソニックR&Dカンパニー オブ アメリカ(PRDCA)は、UCLAの研究者らと共同で、拡散モデルを用いたマルチモーダルAI「LaViDa」を開発しました。
近年、マルチモーダルAIは、大規模言語モデルの成功を受け、モデルの大規模化によって性能を高めてきました。しかし、従来の自己回帰型による文章生成では文章量が増えるにつれ、生成時間が増加することが課題でした。
今回開発された「LaViDa」では、文章の生成を拡散モデルで行うことで生成のスピードを可変にすることが可能になり、既存の自己回帰型手法と同等精度で、約2倍の高速化を達成しました。
この技術は、先進性が国際的に認められ、AI・MLのトップカンファレンスであるNeurIPS 2025に採択されました。2025年12月3日から2025年12月5日までアメリカ、サンディエゴで開催される本会議で発表されます。
パナソニックHDとPRDCAは、マルチモーダルAIにおける拡散モデルの研究を進めています。近年、文章やコード生成に拡散モデルを用いる手法が登場し、従来の自己回帰型モデルより高速で、詩のような構造的制約のある文章生成にも適しているとして注目されています。
一方、画像と言語を扱うマルチモーダルAIでは、これまで自己回帰型が主流で、拡散モデルの導入は進んでいませんでした。
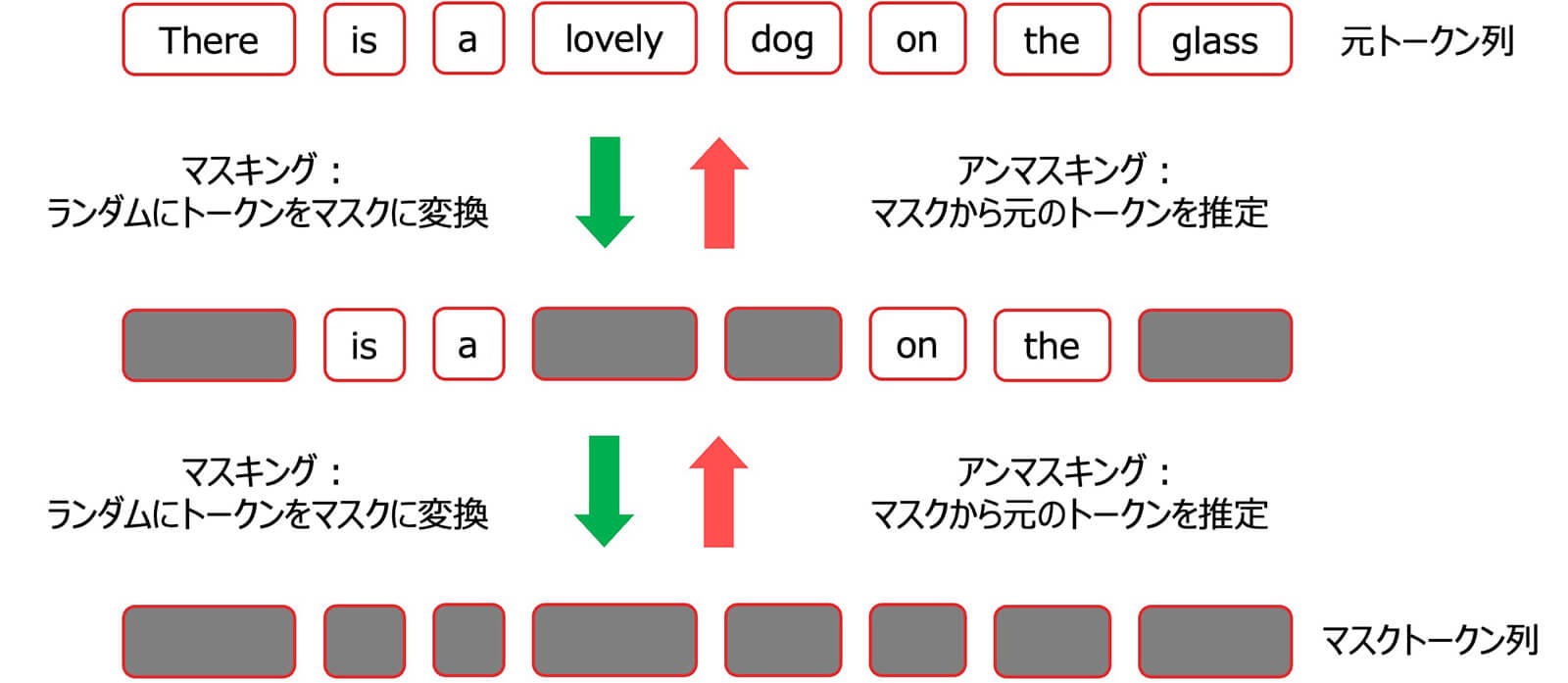
拡散モデルを用いて文章のような離散的なデータを生成する仕組みは、文章を構成する各トークンをランダムにマスクトークンに置き換えるマスキング処理と、マスクトークンから元のトークンを復元するアンマスキング処理から構成されます。
しかし、自己回帰型のマルチモーダルAIモデルを拡散モデルにそのまま置き換えただけでは、毎回のトークン生成に要するアテンション計算が重くなってしまったり、画像の説明文にとって重要な単語が学習されない可能性が高いという二つの課題が現れます。
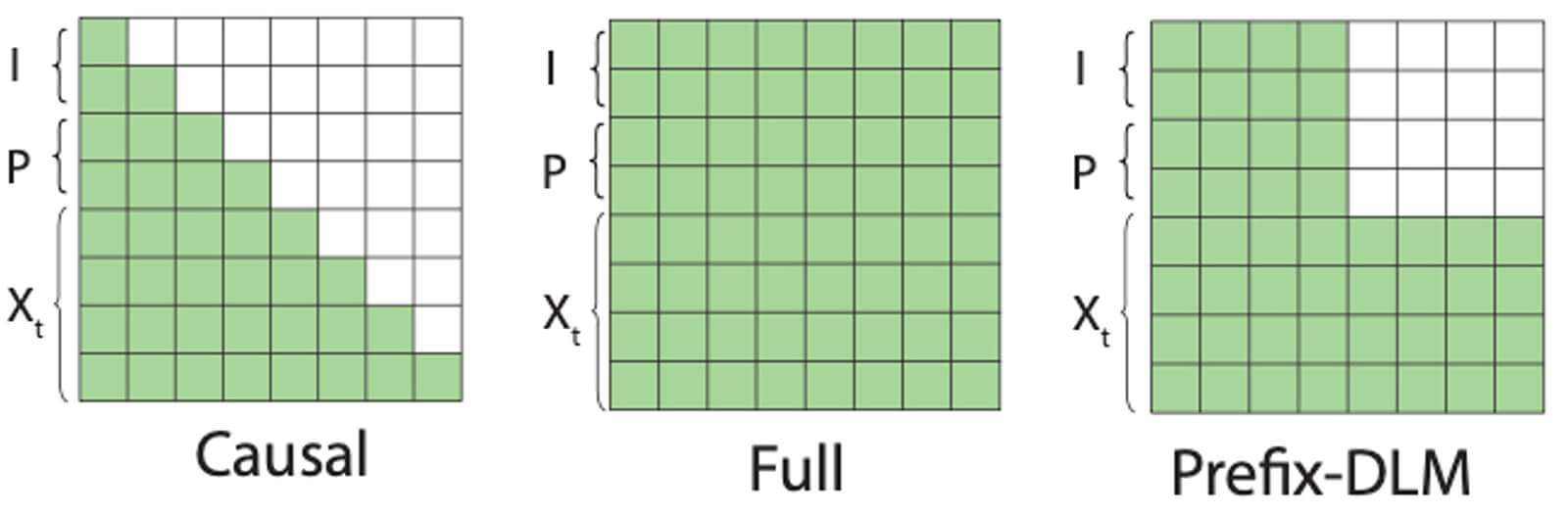
こうした課題を解決するため、パナソニックHDは計算量削減のために入力画像と質問文のトークンのアテンション計算から解答文のトークンを排除する工夫を導入しました
拡散モデルでは全てのトークンを参照してアテンションマップを計算する必要がありますが、パナソニックHDが提案する「Prefix-DLM」では画像トークンと質問文のトークンのアテンション計算から解答文のトークンを排除することで、計算を効率化しています。

画像の説明文にとって重要な単語が学習されない可能性が高いという課題に関しては、学習時に同じ文章に対してお互いのマスクするトークンが被らないような相補的な2通りのマスキングを用意して両方のアンマスキングを学習させ、文章の全てのトークンが必ず学習されるようにしています。
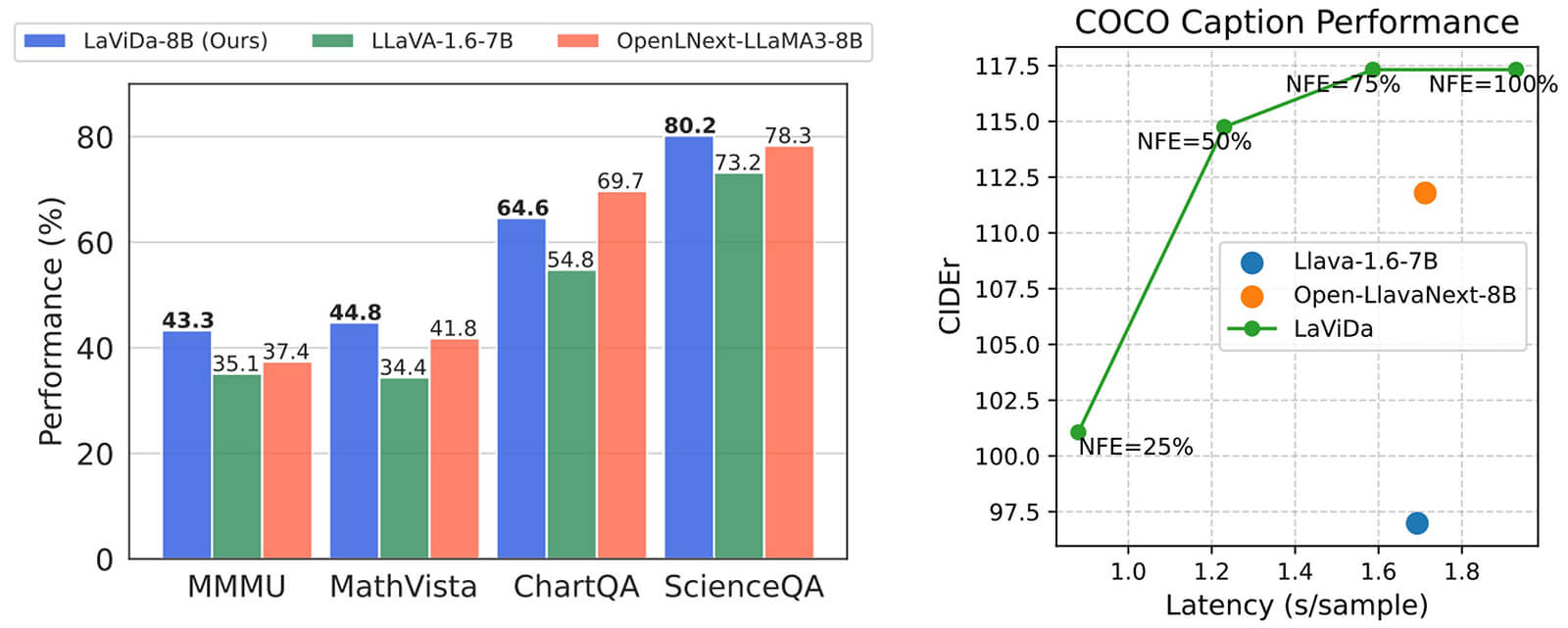
評価実験では、自然画像のQ&Aタスクから、数学、科学の証明問題、またチャートやグラフが多数含まれるドキュメントの内容理解などさまざまな形式のデータセットを用いて有効性を検証しました。
NFEは、拡散モデルの1回のステップでどれぐらいの割合のトークンを生成するかを表す指標です。NFEが下がると生成に必要なステップ数が減少して速度が速くなる一方、性能は減少する傾向を示します。
「LaViDa」は、いずれのデータセットにおいても既存の自己回帰手法を上回る性能を獲得しました。また生成効率においても既存の自己回帰手法より高速に文章生成を行えることを確認しています。
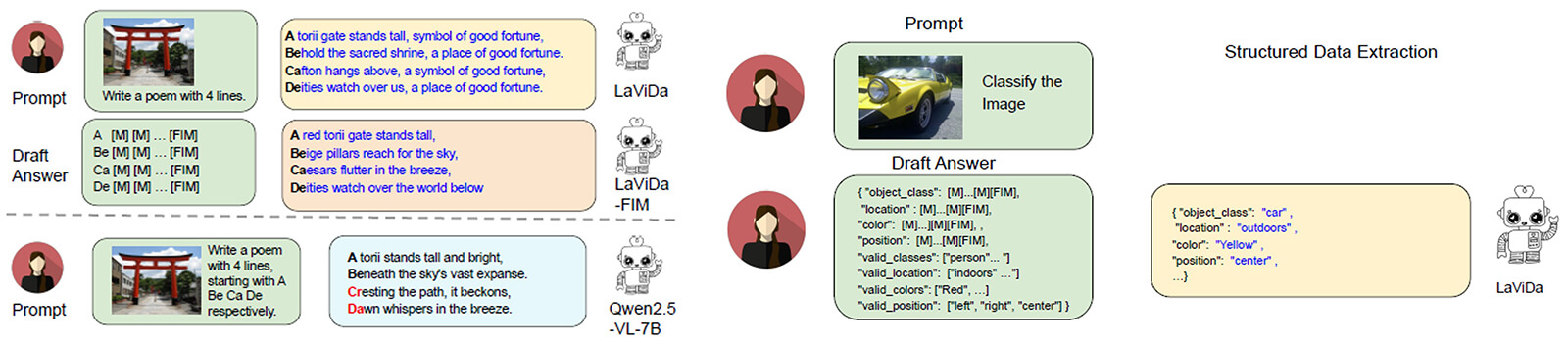
従来の自己回帰型の手法ではプロンプトの中に細かくルールを指定する必要があり、誤認識が起きやすい原因となっていましたが、「LaViDa」ではアンマスキングの仕組みを使うことで、構造的制約のある文章でも高精度に生成することが可能です。
パナソニックHDは、「今後も、AIの社会実装を加速し、顧客のくらしやしごとの現場へのお役立ちに貢献するAI技術の研究・開発を推進します」とコメントしています。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!
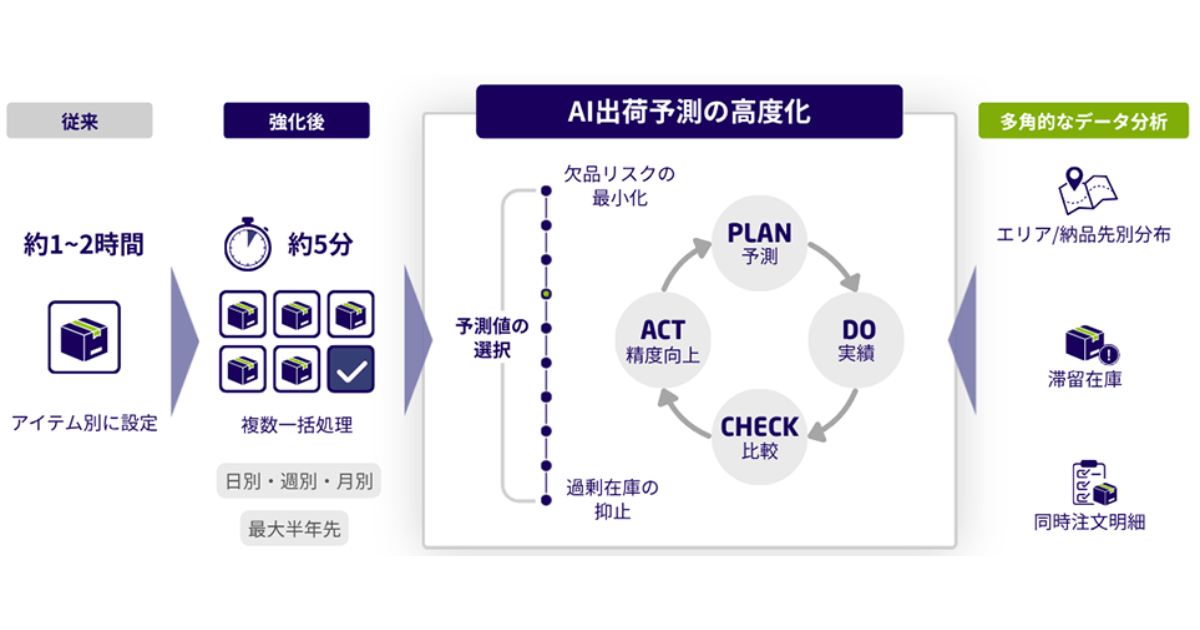




AI製品・ソリューションの掲載を
希望される企業様はこちら