

VLMとは?LLMとの違いから仕組み、生成AIのビジネス活用例まで解説
最終更新日:2026/06/19
 VLMとは?LLMとの違いなど解説
VLMとは?LLMとの違いなど解説
近年急速に発展しているVLM(視覚言語モデル)は、画像認識と言語理解を融合させた革新的なAI技術です。
本記事では、VLMの基本概念からLLM(大規模言語モデル)との違い、その仕組みと実際のビジネス応用まで徹底解説します。
AI技術の最前線に立ちたい企業担当者や、画像認識技術の可能性を模索するマーケティング責任者にとって、VLMの導入方法や活用事例を知ることで、競合他社との差別化や業務効率化を実現するヒントが得られるでしょう。
VLM(視覚言語モデル)の基本概念とLLMとの相違点

VLM(視覚言語モデル)は画像を理解し言語で表現できるAIモデルで、LLM(大規模言語モデル)とは根本的に異なります。LLMがテキストのみを処理するのに対し、VLMは視覚情報と言語を統合して処理します。
この違いにより、VLMは画像認識、物体検出、シーン理解などのタスクで優れた性能を発揮し、マルチモーダル処理が可能になります。
GPT-4VやGemini、Claude 3 Opusなどの最新モデルは、この視覚言語処理能力を活用して、画像内容の詳細な説明や分析を行えるようになりました。企業がこれらの違いを理解することで、ビジネスニーズに最適なAIソリューションを選択できるようになります。
VLMとは何か?AIにおける役割の解説
VLM(Vision-Language Model)とは、画像や動画などの視覚情報とテキストなどの言語情報を同時に処理できる革新的なAI技術です。
従来のAIモデルが単一のデータタイプに特化していたのに対し、VLMは複数の情報形式を横断的に理解・処理できる点が大きな特徴となっています。
近年のGPT-4VやGemini、Claude 3 Opusなどの登場により、VLMは急速に進化しています。この背景には以下の要因があります。
- 大規模な事前学習モデルの発展
- 計算資源の飛躍的な向上
- マルチモーダルデータセットの充実
VLMが解決できる課題は多岐にわたります。例えば、製造業での製品検査において、VLMは画像から不良品を検出するだけでなく、その原因を自然言語で説明できます。
また、医療分野では、X線画像やMRI画像を分析し、医師向けに詳細な所見を生成できます。
さらに、小売業では商品画像から詳細な説明文を自動生成し、ECサイトのコンテンツ制作を効率化できます。
このように、VLMは人間の認知プロセスに近い形で情報を処理することで、より直感的で高度なAIアプリケーションの実現に貢献しています。
LLMとの明確な違いとは?機能とデータで比較
VLMとLLM(大規模言語モデル)の最も顕著な違いは、扱うデータの種類にあります。LLMがテキストのみを処理するのに対し、VLMは画像とテキストの両方を理解できます。
この違いは単なる入力形式の問題ではなく、モデルの構造と能力に根本的な差をもたらしています。
以下に両者の主な違いを比較してみましょう。
- 入力データ
LLM:テキストのみ
VLM:画像とテキスト - 得意なタスク
LLM:文章生成、要約、翻訳、質問応答(テキストベース)
VLM:画像認識、画像説明生成、視覚的質問応答、画像内容に基づく推論 - モデル構造
LLM:トランスフォーマーベースの言語処理に特化
VLM:画像エンコーダーと言語モデルを組み合わせた複合構造
興味深いのは、VLMはLLMに対立するものではなく、むしろLLMを拡張した技術だという点です。多くのVLMは、既存のLLMに視覚情報を処理する能力を追加する形で開発されています。例えばGPT-4Vは、GPT-4に視覚機能を追加したものです。
両者は相互補完的な関係にあり、VLMはLLMの言語理解能力を基盤としながら、視覚情報という新たな次元を追加しています。
これにより、AIが人間のように「見て理解する」能力を獲得し、より自然なマルチモーダルなコミュニケーションが可能になっています。
| 特徴 | VLM(視覚言語モデル) | LLM(大規模言語モデル) |
|---|---|---|
| 扱えるデータ | 画像、動画、テキスト | テキスト |
| 主な機能 |
|
|
| 代表的なモデル | CLIP,DALL-E | GPT-3,BERT |
VLMを支える技術:その仕組みとアーキテクチャ

VLMの背後には、複雑かつ洗練された技術的アーキテクチャが存在します。
これらのモデルは、画像認識のための畳み込みニューラルネットワーク(CNN)や最近ではTransformerベースのビジョンモデルと、自然言語処理のための言語モデルを組み合わせた構造を持っています。
両者を橋渡しするのがマルチモーダルエンコーダーデコーダーシステムであり、画像の視覚的特徴を言語モデルが理解できる形式に変換します。
この統合アプローチにより、VLMは画像を「見て」その内容を言語で表現できるようになるのです。
VLMのモデル構造:画像情報を言語に変換するプロセス
VLMのモデル構造は、主に3つの重要な要素から構成されています。まず「画像エンコーダー」(多くの場合CLIPなどのモデル)が画像を数値ベクトルに変換します。
次に「言語モデル」(VicunaやLLaMAなどのLLM)がテキスト処理を担当します。
そして両者を繋ぐ「プロジェクション層」が画像特徴量を言語モデルが理解できる形式に変換します。この3層構造により、VLMは視覚情報を言語情報として処理できるのです。
実際の処理フローを見てみましょう。
- 画像が入力されると、エンコーダーがそれを高次元ベクトル(例:768次元)に変換
- プロジェクション層がこのベクトルを言語モデルの埋め込み空間に投影
- 言語モデルが画像特徴と追加のテキストプロンプトを組み合わせて回答を生成
例えばLLaVAモデルでは、CLIPビジョンエンコーダーが画像特徴を抽出し、線形層がこれをVicunaのトークン埋め込み空間に変換します。
この統合アプローチにより、「この画像に何が写っていますか?」といった質問に対して、画像内容を正確に言語化できるのです。
VLMの優れた点は、画像と言語の深い関連性を学習し、視覚情報を自然言語として表現できることにあります。
VLMの学習手法:ゼロショット学習の優位性
VLMの学習手法は大きく分けて3種類あります。まず「教師あり学習」では、画像とそれに対応する正確なラベルやキャプションのペアを大量に使用し、モデルに正しい関連付けを学習させます。
次に「教師なし学習」では、ラベルのないデータからパターンを見つけ出し、画像の特徴を自律的に学習します。さらに「強化学習」では、モデルの出力に対するフィードバックを基に、より適切な応答ができるよう調整していきます。
中でも特筆すべきは「ゼロショット学習」の能力です。これは事前学習の段階で見たことのない新しい概念や物体に対しても、追加学習なしで認識・理解できる能力を指します。
例えば以下のようなケースです。
- 新製品の認識:トレーニングデータに含まれていない新商品でも識別可能
- 未知のシナリオ対応:学習していない状況でも適切な判断ができる
- 言語間の転移:ある言語で学習した概念を他言語でも理解できる
このゼロショット能力により、ビジネス現場では常に変化する環境に柔軟に対応できます。新しい製品カテゴリが登場しても、システム全体を再学習させる必要がなく、迅速な市場投入が可能になります。
また、グローバル展開においても、各国の特殊性に合わせた対応が容易になるため、導入コストと時間を大幅に削減できるのです。
VLMが拓くビジネスの可能性と具体的な応用例

VLMは単なる技術革新ではなく、ビジネスプロセスを根本から変革する可能性を秘めています。画像認識と言語理解の融合により、これまで人間の判断が必要だった視覚的タスクを自動化できるようになりました。
小売業では商品認識による在庫管理の効率化、医療分野ではX線画像の診断支援、製造業では品質検査の自動化など、業種を問わず幅広い応用が進んでいます。
特に注目すべきは、VLMの「見て理解する」能力が、カスタマーサービスや意思決定支援にもたらす変革です。
多様な業界でのVLM活用事例
VLMの活用事例は業界を問わず急速に広がっています。製造業では、生産ラインの異常検知において大きな変革が起きています。
例えば、機械設備の画像をVLMが分析し、異常箇所を特定するだけでなく、その原因と最適な対処法までテキストで出力できるようになりました。これにより保守担当者の作業効率が30%以上向上したという報告もあります。
医療分野では、X線やMRI画像の診断支援ツールとしての活用が進んでいます。医師が見落としがちな微細な異常をVLMが検出し、その医学的意義を説明することで、診断精度の向上に貢献しています。
特に地方の医療過疎地域では、専門医の不足を補う役割も果たしています。
小売・Eコマース業界では以下のような活用が進んでいます。
- 商品画像からの自動タグ付け・カテゴリ分類
- 顧客が撮影した画像からの類似商品推奨
- ビジュアル検索機能の精度向上
また、農業分野では作物の病害虫診断、建設業では現場の安全性確認、金融業では不正検知など、VLMの応用範囲は驚くほど多岐にわたっています。各業界特有の課題に対して、画像理解と言語処理の融合という強みを活かした解決策を提供しているのです。
VLM導入がもたらすビジネス上のメリット
VLM(視覚言語モデル)をビジネスに導入することで、企業は複数の面で大きな恩恵を受けられます。第一に、画像とテキスト情報を同時に処理できるため、製造現場や小売店舗など様々な環境で柔軟な対応が可能です。
例えば、商品の外観検査や在庫管理において、従来は人間の目視に頼っていた作業を自動化できるようになります。
次に、VLMの優れた特性として、以下のようなメリットが挙げられます。
- コスト削減効果
新しい製品カテゴリや分類が追加されても、モデルの再学習が不要なため、継続的な運用コストを大幅に削減できます。 - 業務効率の向上
画像認識と言語理解を組み合わせることで、マニュアル確認や問い合わせ対応などの業務が迅速化されます。 - 顧客体験の向上
視覚的な情報を言語化する能力により、ECサイトでの商品検索や推薦の精度が向上します。
さらに、VLMは従来のAIシステムでは難しかった「見たものを説明する」という人間的な能力を持つため、トレーニングやナレッジ共有の場面でも活躍します。
例えば、熟練作業者の技術を視覚的に捉え、言語化して伝承することも可能になるでしょう。
このように、VLMの導入は単なる業務自動化を超えて、組織の知的資産の活用方法を根本から変革する可能性を秘めています。
VLMをビジネスに導入するための具体的なステップ

VLMをビジネスに導入するには体系的なアプローチが不可欠です。まずは自社の課題を明確にし、それにVLMがどう貢献できるかを見極めましょう。
次に、適切なVLMソリューションの選定と、必要なデータ・インフラの準備を進めます。
導入前のパイロットプロジェクトでは、小規模な実証実験を行い、効果測定の指標を設定することが重要です。そして段階的な展開と継続的な改善サイクルを確立することで、ビジネス価値を最大化できます。
以下のH3セクションでは、導入前の準備と具体的なプロジェクトの進め方について詳しく解説していきます。
VLM導入前に考慮すべき課題と対策
VLM導入を検討する際には、まず3つの主要な課題を理解しておく必要があります。
1つ目はデータの品質です。VLMは学習データの質に大きく依存するため、偏りのあるデータセットは不正確な結果を生み出す恐れがあります。
2つ目は技術的知見の不足です。多くの企業ではAI専門家が限られており、VLMの適切な実装・運用が困難になることがあります。
3つ目はコスト面の課題で、高性能なGPUなどのハードウェア投資や、モデルのトレーニング・メンテナンスにかかる継続的なコストが障壁となります。
これらの課題に対しては、以下のような対策が効果的です。
- データ品質の問題:多様で代表的なデータセットの構築、データクレンジングプロセスの確立
- 技術的知見:外部専門家との協業、段階的な技術移転計画の策定
- コスト管理:クラウドベースのソリューション活用、ROI分析に基づく投資判断
また、VLMの出力評価が難しいという点も見過ごせません。生成された結果の品質や正確性を客観的に測定するためには、人手による確認プロセスの確立や、業務に即した明確な評価基準の設定が重要です。
これらの課題と対策を事前に検討することで、VLM導入プロジェクトの成功確率を高めることができます。
| 課題 | 具体的な内容 | 対策例 |
|---|---|---|
| データの品質と準備 | モデルの精度は学習データの質と量に大きく依存する。偏ったデータはバイアスのある出力を生む |
|
| 技術的な理解と体制 | VLMの高度な仕組みを正しく理解し、調整できる専門知識が必要 |
|
| コスト | 学習には高性能な計算リソースや大規模なデータセットの準備が必要 |
|
VLM導入プロジェクトの進め方
VLM導入プロジェクトを成功させるには、段階的なアプローチが不可欠です。
まず、「目的の明確化」から始めましょう。画像認識によって解決したい具体的な業務課題を特定し、KPIを設定します。
次に「データ準備フェーズ」に移ります。高品質な画像データセットの収集と、必要に応じたアノテーション(ラベル付け)を行います。この段階でデータの偏りがないか確認することが重要です。
第三段階は「モデル選定とカスタマイズ」です。
①既存のVLMモデルから最適なものを選ぶ
②必要に応じてファインチューニングを行う
③自社データでの追加学習を検討する
といったステップを踏みます。続いて「検証と評価」フェーズでは、限定環境でのパイロット運用を通じて精度や使い勝手をテストします。
最後に「本格展開と継続的改善」へと進みます。導入後も定期的にモデルのパフォーマンスを評価し、新たなデータで更新していくことが長期的な成功の鍵となります。
なお、社内にAI専門知識が不足している場合は、経験豊富な外部パートナーと協業することで、導入プロセスをスムーズに進められるでしょう。
まとめ
VLM(視覚言語モデル)は、画像認識と言語理解を融合させた革新的なAI技術として、ビジネスに新たな可能性をもたらします。
従来のLLMとは異なり、視覚情報を理解・処理できる点が最大の強みです。その独自のアーキテクチャと学習手法により、多様な業界での活用が進んでいます。VLMの導入には課題もありますが、適切なステップを踏むことで、業務効率化やユーザー体験の向上など、具体的な成果につながります。
今後のビジネス競争力を高めるために、VLMの可能性を積極的に探求してみてはいかがでしょうか。
アイスマイリーでは、生成AI のサービス比較と企業一覧を無料配布しています。課題や目的に応じたサービスを比較検討できますので、ぜひこの機会にお問い合わせください。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- 生成AI
- ChatGPT
- Gemini
- Claude
- LLM
- AI研究開発
- 画像生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
- GPU
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI












FOLLOW US
SNSをフォローして、最新情報をチェックできます!

Google、「Gemini」新モデル「3.6 Flash」「3…

安川電機、「エージェンティック・ロボットシステム」開発。AIロボ…

富士フイルムBI、複合機の保守プロセスを効率化するAI搭載「統合…

Anthropic、最新AIモデル「Claude Opus 5」…

日立製作所、「Claude Mythos Preview」を用いた重要インフラソフトウェアでのセキュリティ検証効果を発表
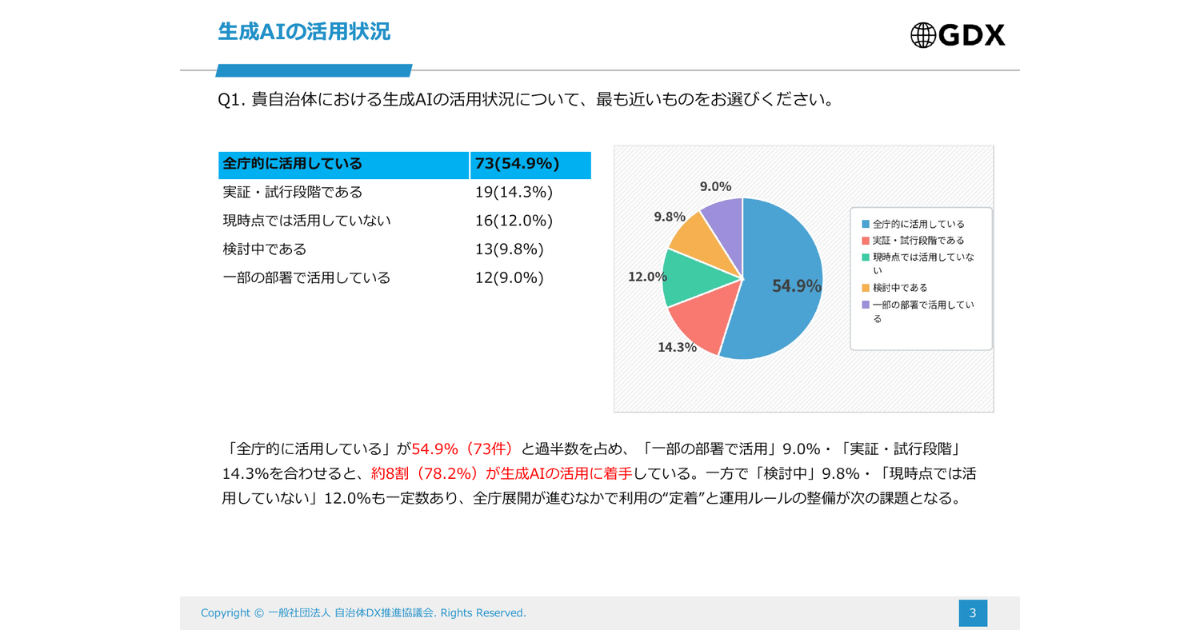
自治体の78.2%が生成AI活用に着手。活用の課題は「職員のリテラシー不足」が82.7%で最多

「AI博覧会 Summer 2026」カンファレンス 第2弾スピーカーを発表! チームみらい党首 安野貴博氏が「AI時代のDX戦略」を解説。 デジタル庁のガバメントAI、経営・製造・営業のAI活用事例も公開

Teamsの使い方とは?基本操作・便利機能・生成AI連携を初心者向けに解説

Codex Skillsの使い方とは?SKILL.mdの書き方からおすすめスキル・Claude Code Skillsとの違いまで解説
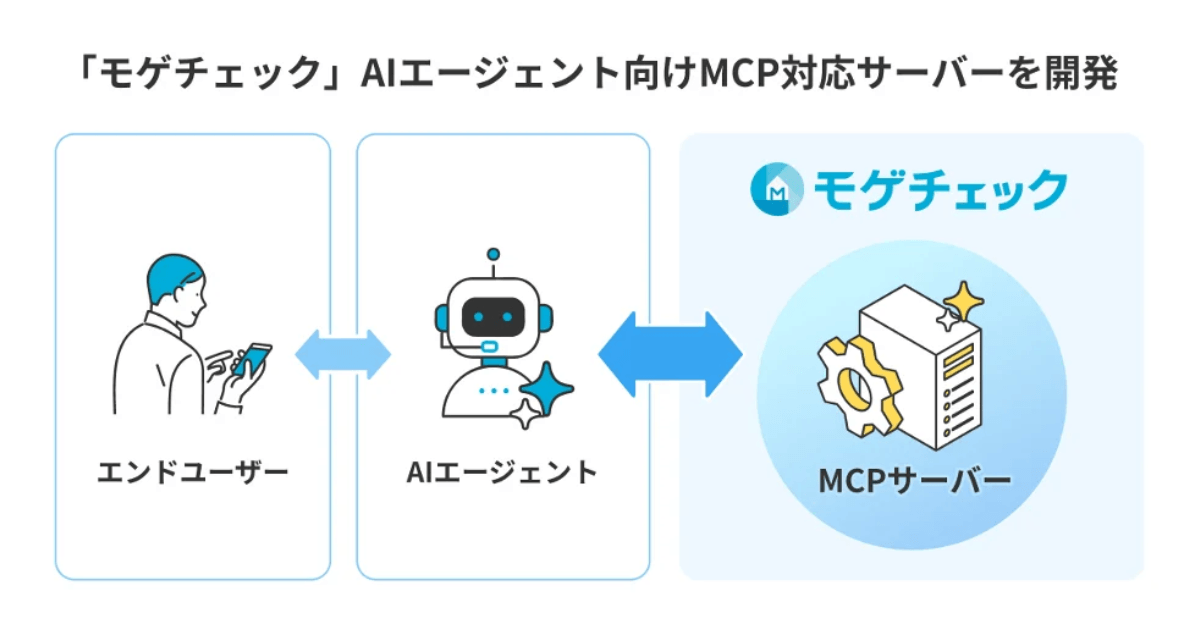
住宅ローン比較診断サービス「モゲチェック」、AIエージェント連携向けMCPサーバーを公開
AI製品・ソリューションの掲載を
希望される企業様はこちら