

Embedding(埋め込み表現)とは?意味や種類・LLMやRAGでの必要性・活用事例を紹介
最終更新日:2025/01/16
 Embeddingとは?
Embeddingとは?
本記事では、AIや機械学習の世界で注目を集めるEmbeddingについて、その基本から応用まで詳しく解説します。Embeddingの概念を理解し、活用方法を学ぶことで、自然言語処理や画像認識などの分野でより効果的なAIモデルの開発が可能になります。データサイエンティストやAI開発者はもちろん、AIビジネスに関わる方々の業務おいてお役立ていただければ幸いです。
Embedding(埋め込み表現)とは?

Embedding(埋め込み表現)は、テキストや画像、音声などの様々なデータを、コンピュータが扱いやすい数値ベクトルに変換する技術です。
例えば、「犬」という単語を[0.2, 0.5, -0.1]のような数値の並びで表現します。この変換により、データの意味や特徴を数学的に捉えることが可能になります。
Embeddingの大きな利点は、似たような意味や特徴を持つデータが、ベクトル空間上で近い位置に配置されることです。これにより、コサイン類似度などの計算を用いて、データ間の類似性を簡単に測ることができます。
例えば「犬」と「猫」のEmbeddingベクトルは近い位置にあり、高い類似度を示します。一方、「犬」と「自動車」のベクトルは離れた位置にあり、低い類似度となります。このような特性を活かし、Embeddingは検索システムや推薦システム、自然言語処理タスクなど、幅広い分野で活用されています。
LLMやRAGでEmbeddingを行う理由

LLM(大規模言語モデル)や、RAG(検索拡張生成)システムでEmbeddingを行う主な理由は、非構造化データを効率的に処理し、意味的関連性を抽出するためです。
Embeddingは、テキストや画像などの複雑なデータを低次元の密ベクトルに変換することで、コンピューターが扱いやすい形式に変換します。これにより、LLMやRAGシステムは大量のデータを高速に処理し、関連性の高い情報を素早く検索できるようになります。
また、Embeddingは意味的に近い概念を近い位置に配置するため、類似性の計算や関連性の判断が容易になります。さらに、次元削減によってデータの本質的な特徴を捉えることができ、ノイズの影響を軽減しつつ、計算効率を向上させることができます。これらの利点により、LLMやRAGシステムはより正確で文脈に即した応答を生成することが可能となり、自然言語処理タスクの性能向上に大きく貢献しています。
Embeddingの種類とモデル

Embeddingは、さまざまなデータ型に適用できる汎用的な手法です。テキスト、画像、音声、グラフなど、多岐にわたるデータを数値ベクトルに変換することができます。
各データ型に応じて、適切なEmbeddingモデルが存在します。例えば、テキストデータには単語や文章のEmbeddingモデルが、画像データにはCNNベースのモデルが用いられます。これらのモデルを使用することで、異なる種類のデータを統一的に扱うことが可能となり、機械学習や情報検索などの分野で幅広く活用されています。
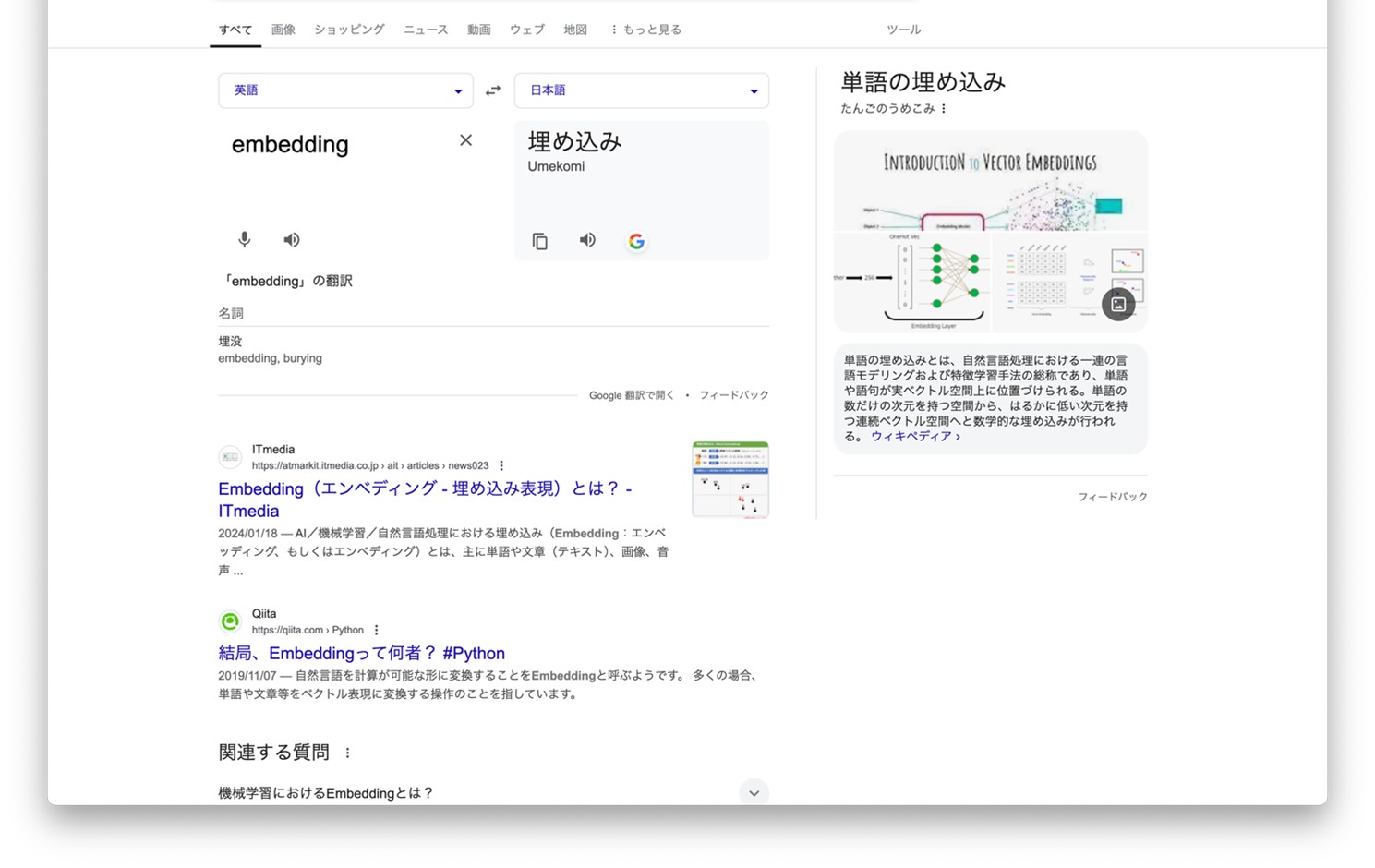
単語Embedding
単語Embeddingは、自然言語処理の基礎となる技術で、単語を数値ベクトルに変換することにより、コンピューターが言葉の意味を理解しやすくします。
代表的なモデルには、以下のようなものがあります。
| 種類 | 特徴 |
| Word2Vec | 単語の前後関係から意味を学習し、類似した単語が近い位置にマッピングされます。 |
| GloVe | 単語の共起情報を活用して、より精度の高い表現を実現します。 |
| ELMo | 文脈を考慮した動的な表現を生成し、多義語の扱いに強みがあります。 |
| FastText | 部分文字列を利用するため、未知語や誤字にも対応できます。 |
これらのモデルは、単語間の意味的関連性を多次元空間上のベクトルとして表現し、単語の類似度や関係性を数学的に計算することを可能にします。
例えば、「王様」-「男性」+「女性」=「女王」のような演算が可能になり、言語の意味構造をコンピューターで扱えるようになります。
文章Embedding
文章Embeddingは、単語Embeddingをさらに発展させ、文や段落全体の意味を数値ベクトルで表現する手法です。
代表的なモデルには、以下のようなものがあります。これらのモデルは、単に単語の羅列としてではなく、文脈や語順を考慮して文全体の意味を捉えることができます。
| 種類 | 特徴 |
| Doc2Vec | 文や段落を固定長のベクトルに変換するモデルです。 |
| Universal Sentence Encoder | 文全体を固定長のベクトルに変換し、類似度計算や文書分類に適しています。 |
| BERT | 事前学習済みの双方向Transformerモデルを使用し、文脈に応じた単語の意味を理解します。 |
| text-embedding-3 | 最新のOpenAIモデルで、より高度な文脈理解と多言語対応が特徴です。 |
これらのモデルにより、文書検索、文書分類、感情分析、質問応答システムなど、様々なNLPタスクの精度向上が可能となります。
画像Embedding
画像Embeddingは、画像の視覚的特徴やセマンティック情報を数値ベクトルに変換する技術です。代表的なモデルは以下の通りです。
| 種類 | 特徴 |
| VGG | 深い構造を持つシンプルな畳み込みネットワークで、画像分類に優れた性能を発揮しますが、計算コストが高いです。 |
| ResNet | 残差学習(skip connections)を導入し、非常に深いネットワークでも効率的に学習可能なモデルです。 |
| Inception | 複数のカーネルサイズを組み合わせたInceptionモジュールで、異なる特徴を同時に抽出する効率的なアーキテクチャです。 |
| EfficientNet | モデルのサイズや深さ、解像度をバランス良くスケールすることで、高い精度と効率を両立した軽量なモデルです。 |
これらのモデルは、畳み込み層やプーリング層を使って画像の特徴を抽出し、最終的に固定長のベクトルを生成します。このプロセスにより、エッジや形状、テクスチャなどの低レベルな視覚特徴から、物体や場面の意味的な情報まで、幅広い特徴を捉えることができます。画像Embeddingは、画像検索、類似画像の発見、画像分類など、様々なタスクに応用されています。
音声Embedding
音声Embeddingは、音声データをベクトル空間に変換する技術です。この手法では、音声の特徴を数値化し、機械学習モデルが理解しやすい形式に変換します。
LSTMやGRUなどの再帰型ニューラルネットワークを用いることで、音声の時系列的な特徴を効果的に捉えることができます。これらのモデルは、音声の周波数、音量、ピッチなどの特性を学習し、それらを低次元のベクトルに圧縮します。音声Embeddingは、話者認識、感情分析、音声合成など、様々な音声関連タスクに活用されています。
特に、音声の文脈や話者の個性を保持しながら、効率的なデータ処理を可能にする点が大きな利点です。また、音声データの関連機能と特性を捉えるため、メル周波数ケプストラム係数(MFCC)やスペクトログラムなどの特徴量抽出技術も併用されることがあります。これにより、音声の音響的特徴をより精密に表現し、高精度な音声処理を実現しています。
グラフEmbedding
グラフEmbeddingは、ネットワーク構造を持つデータを効率的に表現する手法です。ソーシャルネットワークや分子構造、交通網などの複雑なグラフデータを低次元のベクトル空間に変換することで、機械学習モデルで扱いやすくなります。
この手法は、ノード間の関係性や全体的なグラフ構造を保持しながら、各ノードや辺を数値ベクトルとして表現します。グラフEmbeddingの主な用途には、リンク予測、ノード分類、コミュニティ検出などがあります。
例えば、ソーシャルネットワーク分析では、ユーザー間の関係性を予測したり、影響力の高いユーザーを特定したりするのに活用されます。また、生物学の分野では、タンパク質間相互作用ネットワークの解析に応用され、新薬開発に貢献しています。
グラフEmbeddingを用いることで、複雑なネットワーク構造を持つデータに対しても、効果的な分析や予測が可能になります。
Embeddingの活用事例

Embeddingの活用事例は多岐にわたり、様々な分野でAIの性能向上に貢献しています。
LLMを用いたRAGシステムでは、Embeddingによって関連情報の検索精度が向上し、より適切な回答生成が可能になります。テキスト生成においては、単語や文章のEmbeddingを活用することで、文脈を考慮したより自然で一貫性のある文章を生成できます。
AIモデルの学習においても、Embeddingを用いることで特徴量の抽出が効率化され、モデルの精度向上につながります。AI検索システムでは、クエリと文書のEmbeddingを比較することで、より関連性の高い検索結果を提供できます。音声認識や分類タスクでは、音声のEmbeddingを利用することで、話者の特徴や感情などをより正確に捉えられるようになります。
多言語翻訳においても、異なる言語間の単語や文のEmbeddingを学習することで、より自然な翻訳が可能です。これらの活用事例において、Embeddingは入力データの特徴を効果的に表現し、AIシステムの性能を大きく向上させる重要な役割を果たしています。
Embeddingの作成方法

Embeddingの作成方法は、以下のようなステップで行われます。
- データを準備します。テキストデータの場合、前処理として不要な文字の削除やトークン化を行います。
- 適切なEmbeddingモデルを選択します。
- 事前学習済みモデルを使用するか、タスクに特化したモデルを新たに学習させるかを決定します。
- モデルが決まったら、データをモデルに入力してEmbeddingを生成します。この際、バッチ処理を行うことで効率的に大量のデータを処理できます。
- 生成されたEmbeddingは、ベクトルデータベースに保存します。ここでは、高次元のベクトルを効率的に検索できる特殊なデータベースを使用することが重要です。
- 生成したEmbeddingを実際のアプリケーションにデプロイします。APIを通じてEmbeddingを提供したり、検索システムに組み込んだりします。
各ステップにおいて、データの品質管理やモデルの性能評価、スケーラビリティの確保などに注意を払う必要があります。また、Embeddingの更新方法や、新しいデータの追加方法についても計画を立てておくことが重要です。
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI










FOLLOW US
SNSをフォローして、最新情報をチェックできます!

ソフトバンク、株主総会で新AI戦略を発表。次世代社会インフラ構築…

MASC、ヒューマノイドロボット「Unitree G1」導入。「…

静岡県藤枝市、全国初となる国産生成AIの公共活用実証実施。ソフト…
AVITAのAIロープレ「アバトレ」、日本調剤の薬局全国768店…

ChatGPT Workとは?機能・料金・使い方、Codexとの違いを徹底解説
近畿大学病院など4者、リアルワールドデータとLLMを用いた共同研究を開始。治験候補患者抽出の精度向上と効率化を図る

KUMON、AI活用学習サービスのatama plusをグループ化。教室のグローバル展開や指導者支援を推進

Grok 4.5とは?性能・料金・使い方・他社モデルとの違いを解説

Claudeは画像生成ができない?最新機能と代替手段を徹底解説

アイスマイリー、 7/29(水)から3日間「イプロスAI 2026 夏」にブース出展。来場登録・実来場でAmazonギフト500円分プレゼント!
AI製品・ソリューションの掲載を
希望される企業様はこちら