

生成AI

最終更新日:2026/01/26
 自然言語処理(NLP)とは?
自然言語処理(NLP)とは?
自然言語処理(NLP)とは、人間が日常的に使う日本語や英語などの「言葉」をコンピュータが理解・解析・生成できるようにするための技術の総称です。近年、自然言語処理の技術は、大規模言語モデル(LLM)の登場などにより急速に進化し、機械翻訳やチャットボット、文章要約など身近なサービスの質を大きく高めています。
本記事では、自然言語処理の基本的な仕組みや代表的なモデル・手法を解説するとともに、ビジネスでの活用事例や自然言語処理AIサービスもご紹介します。
AIソリューションについて詳しく知りたい方は以下の記事もご覧ください。
AIソリューションの種類と事例を一覧に比較・紹介!
2025年、自然言語処理分野は大きな転換点を迎えています。OpenAIは8月にGPT-5、11月にGPT-5.1をリリースし、推論能力と会話の自然さが大幅に向上しました。
Googleも11月18日にGemini 3を発表し、AIモデルの性能を人間の評価によって比較するベンチマーク「LMArena」で史上初の1500点超えを達成するなど、推論タスクで世界最高水準の性能を示しています。こうした大規模言語モデルの進化に加え、テキストだけでなく画像・音声・動画を統合的に処理する「マルチモーダルAI」の実用化が加速。医療、金融、法務など専門分野に特化したモデルの開発も進んでいます。
国内では、3月に長崎で開催された言語処理学会第31回年次大会(NLP2025)に過去最多の2,309名が参加し、777件の研究発表が行われるなど、NLP技術への関心の高まりを示しました。

自然言語処理(NLP:Natural Language Processing)は、人間が日常的に使用している言語、つまり自然言語をコンピュータで処理・理解・生成するための技術分野です。自然言語とは、英語や日本語のように人間社会で自然に発展してきた言語のことを指し、プログラミング言語のような人工的に作られた言語とは区別されます。
自然言語処理は、テキストや音声といった人間のコミュニケーション手段をコンピュータが理解し、適切に処理できるようにすることを目的としています。具体的な応用例として、機械翻訳、音声認識、テキスト要約、感情分析、チャットボット、質問応答システムなどがあります。
これらの技術は、企業の顧客サービス、医療診断支援、教育支援、情報検索など、私たちの日常生活や産業界で幅広く活用されています。
自然言語処理は人間の言葉を機械が理解できる形式に変換し、その意味や文脈を解析する技術であり、形態素解析や構文解析などの手法を用いて言語を処理します。一方、機械学習(ML)はデータから規則やパターンを自動的に学習し、予測や判断を行う技術です。
自然言語処理と機械学習は、現在のAI技術の中でも特に密接に結びついた分野です。自然言語処理では、機械学習の手法を活用してテキストの分類や意味理解の精度を向上させ、機械学習は自然言語処理によって変換された言語データを基に学習を行います。
たとえば、機械翻訳システムでは、まず自然言語処理が文章を文の区切りや単語ごとに分け、「この単語は名詞」「ここは主語」のように解析します。
その上で、機械学習が大量の例文から「この言い回しは日本語だとこう訳すことが多い」というパターンを学び、自然な翻訳文を作ります。このように、両技術は相互に補完し合いながら、より高度な言語理解と処理を可能にしています。
自然言語処理が注目される主要な背景として以下が挙げられます。
テキストデータの増大は、SNSやビジネスコミュニケーションツールの普及、企業のペーパーレス化推進により、デジタル化されたテキストデータが急増していることを指します。
次に、BERTやGPTシリーズなどの汎用言語モデルの進化により、高度な文章生成や文脈理解が可能になり、より実用的なアプリケーションの開発が可能になりました。
第三に、企業におけるDXの推進があります。人手不足や生産性向上の必要性から、問い合わせ対応や文書処理など「言葉」を扱う業務のデジタル化が進んでおり、それを支える基盤技術として自然言語処理への期待が高まっています。
これらの要因が相まって、自然言語処理技術への注目が高まっているのです。
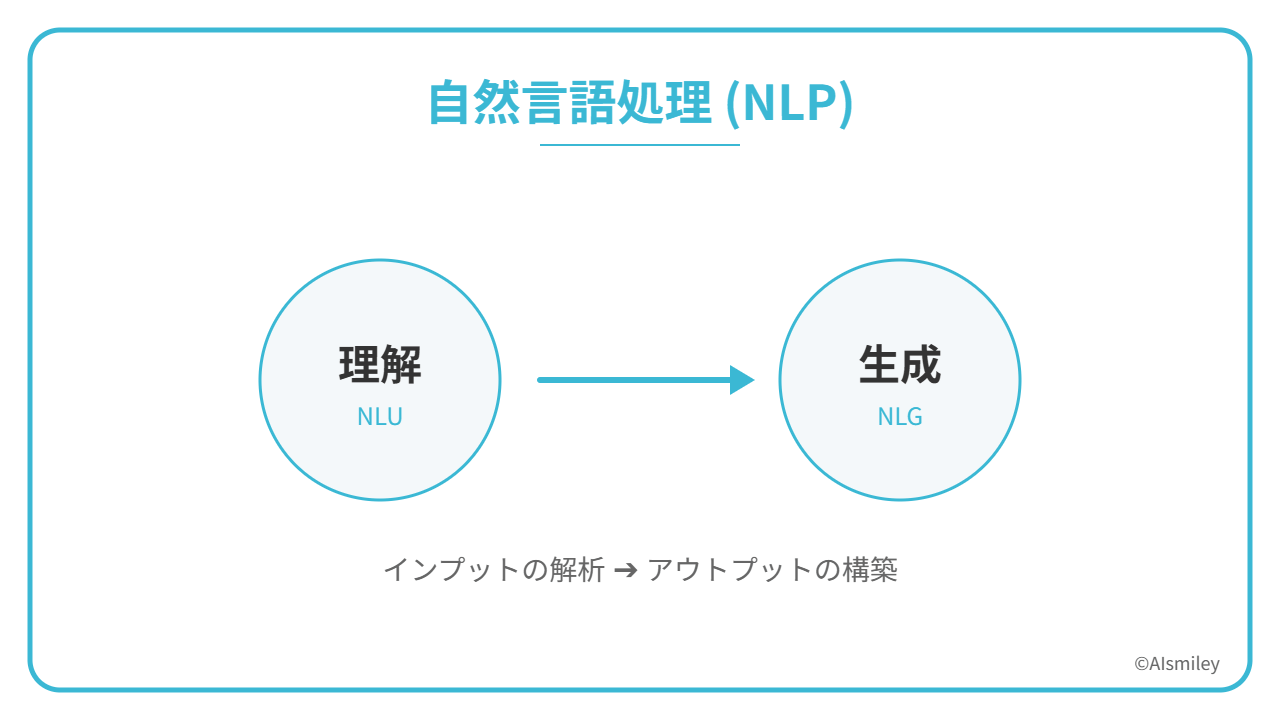
自然言語処理の種類は、「自然言語理解(NLU)」と「自然言語生成(NLG)」の2種類に分けることができます。それぞれにどのような特徴があるのでしょうか。詳しくみていきましょう。
自然言語理解とは、自然言語処理の内の一分野であり、「テキストや音声の構文(文の文法的構造)、意味(文が意図する意味)解析を使用することで文の意味を判別していく技術」です。
自然言語理解は、関連する「オントロジー」も構築していくことが特徴として挙げられます。オントロジーとは、語と句の間の関係を指定するデータ構造のことです。人間は、日常会話においてごく自然にこのオントロジーを行っていますが、機械が人間と同じようにさまざまなテキストの意味を理解するためには、これらの分析を組み合わせなければなりません。
自然言語生成(NLG)も、自然言語処理の一分野です。自然言語生成はコンピュータが文章を生成できるようにしている点が大きな特徴といえます。
自然言語生成は、あるデータ入力に基づき、人間の言語によってテキスト応答を生成していくプロセスを指します。ここでテキストが生成されたら、音声合成サービスを介して音声の形式に変換していくことも可能です。自然言語生成 には、テキストの要約機能も含まれます。これは、情報の整合性を保ちながら入力された文書の要約を生成する仕組みで、AI によって可能になった革新的技術として大きな注目を集めています。
従来の自然言語生成(NLG)システムは、あらかじめ用意した「本日の売上は◯◯円です」のようなテンプレートの空欄に、データベースから取得した数値や文字列を当てはめる方式が主流でした。
しかし近年は、再帰型ニューラルネットワーク(RNN)やトランスフォーマーといった深層学習モデルが利用できるようになり、テンプレートに頼らず、文の構成や言い回しも含めてリアルタイムに文章を生成できるようになってきました。
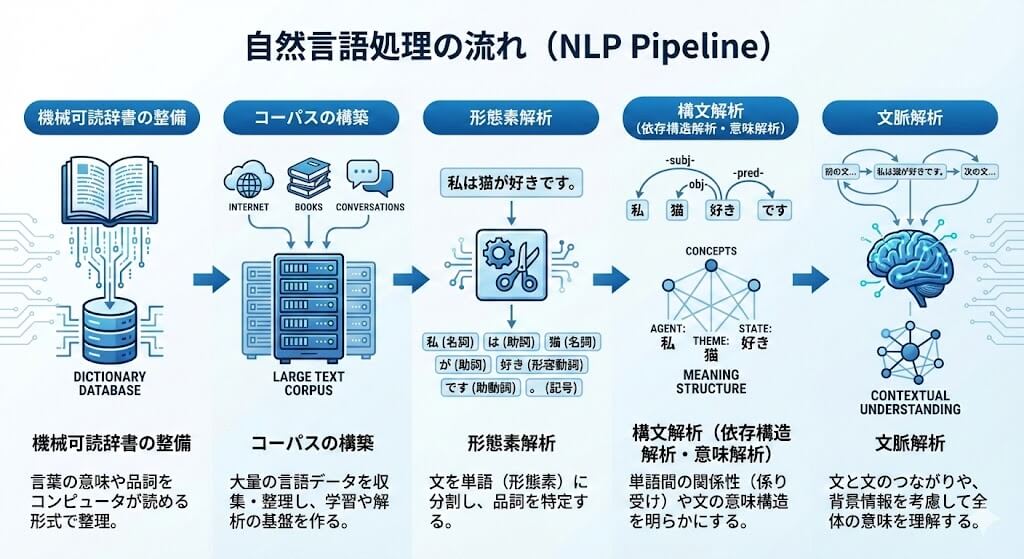
自然言語処理は、前処理から最終的な文脈理解に至るまで、いくつかの段階を順に踏んで進みます。
具体的な流れは、以下のとおりです。
機械可読辞書とは、「コンピュータが単語の集まりである語彙(ごい)を扱えるようにするための辞書データ」のことです。書き言葉に関する情報を、機械が正しく読み込めるように整理したデータ形式であり、コンピュータが文字列を単語として認識するための基盤となります。
コーパスとは、コンピューターが言語を分析・学習するために集められた、大量の文章データの集合のことです。このコーパスの分析を行うことで、状況に適した言葉の意味、使い方を理解することができるようになります。最近では、コンピュータ自体の処理性能や記憶容量も高まっており、より大規模なコーパスを利用して言語処理を行うことができるようになっています。
特に近年では多くのスマホユーザーがSNSによる情報発信を行っており、日々大量の言葉を用いたやりとりが行われている状況です。こういったSNSのデータを収集していくことで、より一層大規模なコーパスを作成することができるようになるかもしれません。
機械可読辞書とコーパスなどの用意が完了すると、次に行われるのが形態素解析という作業です。「形態素」は言語学の用語であり、意味を持つ表現要素の最小単位のことです。これだけでは意味が分からない方も多いかと思いますので、「黒い目の大きい金魚」という言葉を用いて解説していきます。
この「黒い目の大きい金魚」というフレーズは、「黒い」「目」「の」「大きい」「金魚」という形態素で分割できます。このように分割していく作業を「形態素解析」と呼びます。形態素解析を行うことで文字列を単語ごとに分割し、それぞれの形態素に「形容詞」「名詞」「助詞」といった品詞を適切に割り当てていくことが可能になります。ただし、どれくらい詳細な品詞を割り当てるかどうかは形態素解析を行うツールの仕様や設定方針によって異なるため、一概には言えません。
構文解析とは、形態素解析で分割された語同士が、文の中でどのような関係にあるか(どの語がどの語に係るか)を調べる工程のことです。日本語の構文解析では、形態素解析によって分割された単語同士の関連性を解析した上で、「文節間の係り受け構造を見つけてツリー化(図式化)していくこと」が主な目的となっています。
ここでは、構文構造を求める代表的な手法である「依存構造解析」と、その結果を用いて意味を解釈する「意味解析」について説明します。
依存構造とは、単語や文節間における「修飾・被修飾関係」「係り受け関係」などの依存関係をもとに、文章の構造を表したものです。単語・文節を接点とするツリーによって表現されます。文章内における「単語間の係り受け関係」を調べた上で、「どの単語がどの単語に係るのか」を構文的に解析していく作業です。日本語の構文的依存構造関係について出力していく構文解析器(parser)としては、CaboChaやKNPなどが挙げられます。
意味解析とは、構文解析された文章内の意味を解釈していく工程のことです。日本語の場合、ひとつの文章を、複数の意味として解釈できるケースも少なくありません。たとえば、「私は冷たいビールとメロンが好きだ。」
この文章の場合、「私は|冷たい|ビールとメロン|が好きだ。」という解釈であればどちらも「冷たい」と認識できます。しかし、「私は|冷たいビール|と|メロン|が好きだ。」という解釈であれば、メロンが冷たいかどうかは言及されていないことになります。このように複数の解釈ができる文章において、正しい解釈を選択するために必要となるのが意味解析です。意味解析においては、「意味」という概念を持たない機械に対して自然言語文の意味を適切に伝え、理解させなければなりません。
日本語は、ひとつの単語が複数の意味を持つことも多いため、他の単語とのつながりを踏まえた上で、適切な候補を選び出す必要があります。その候補を絞り込む作業は、非常に難易度が高い処理といえます。
文脈解析とは、文章の繋がり(文脈)を考えていく工程のことです。複数の文に対して「文同士のつながり」を解析するためには、文章の背景など複雑な情報も必要になります。意味解析よりもさらに難易度は高いものの、近年は大規模言語モデル(LLM)などの発展により、チャットボットや要約、質問応答システムなどで文脈を踏まえた処理が実用レベルで行われるようになってきています。
自然言語処理は、既にさまざまな分野で活用されています。以下はその一例です。
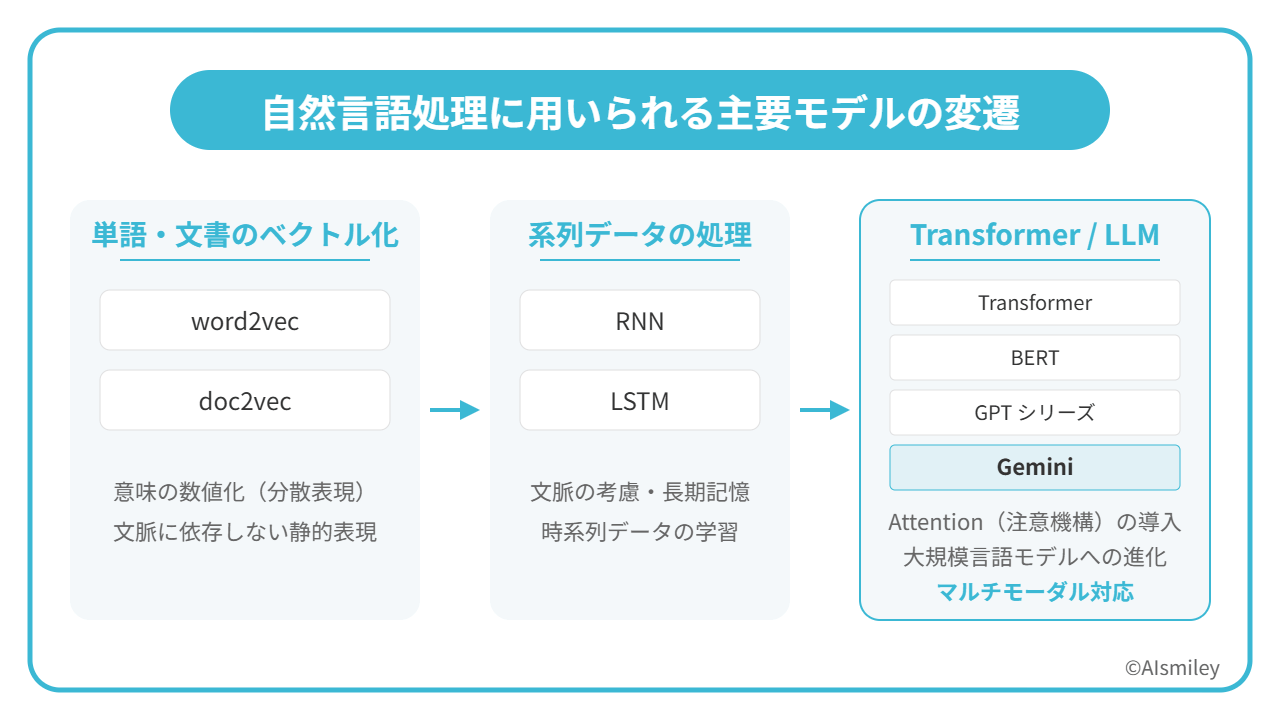
自然言語処理におけるモデルとは、人間の言語を理解・処理するためのアルゴリズムや数理的な枠組みのことを指します。代表的なものとして、GoogleのBERTは文脈を双方向から学習することで高精度な言語理解を実現し、OpenAIのGPTシリーズは膨大なパラメータを用いて自然な文章生成を可能にしています。これらのモデルは、それぞれ特定の言語処理タスクで優れた性能を発揮しています。
 参考:”Efficient Estimation of Word Representations in Vector Space” Tomas Mikolov [2013]
参考:”Efficient Estimation of Word Representations in Vector Space” Tomas Mikolov [2013]
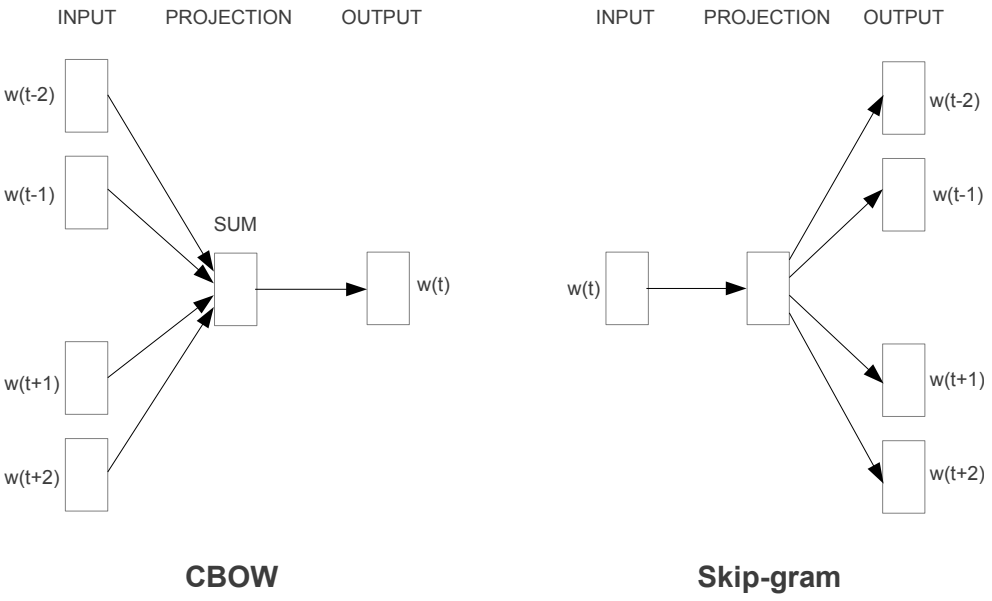
word2vecとは、テキスト処理を行うためのニューラルネットワークのことです。膨大な量のテキストデータを解析し、単語の意味をベクトル化することによって、単語の意味の類似性を見つけたり、単語同士の意味を足し引きしたりすることが可能になります。このword2vecは、TensorFlowなどのソフトウェアライブラリで手軽に試すことができるのも大きな特徴のひとつです。
word2vecの仕組みを簡単に説明します。
たとえば「ぶどう、パイナップル、果物、ジュース」という単語をベクトル化し、以下のような数値になったとします。
ぶどう:8
パイナップル:6
果物:7
ジュース:3
これは、ベクトル化によって「ぶどう」に最も近いものが「果物」であり、「パイナップル」にもそれなりの類似性があることが示されています。ちなみに、Word2Vecは、大きく分けて2種類の論理的構造(アーキテクチャ)が存在しています。単語周辺の文脈から、その中心となる単語を推測していくCBOW。中心となる単語から、文脈の構成に重要となる要素を推測していくSkip-gramです。
doc2vecとは、任意の長さの文書をベクトル化する技術のことです。文章やテキストに対して、分散表現(Document Embeddings)を獲得することができます。そんなdoc2vecは、特定のタスクに依存されることがありません。そのため、以下の例をはじめとする多くの応用方法が存在します。
また、機械学習のモデルにおける入力には、固定長のベクトルが使用されるケースが多いため、事前にDoc2Vecで前処理を行なった上で、入力ベクトルにするケースも少なくありません。これまでにもBag-of-wordsやLDAなど、文書を固定長の小さなベクトルにするテクニックは存在していましたが、Doc2Vecを利用することで、それらのテクニックを上回る性能を発揮することが報告されています。
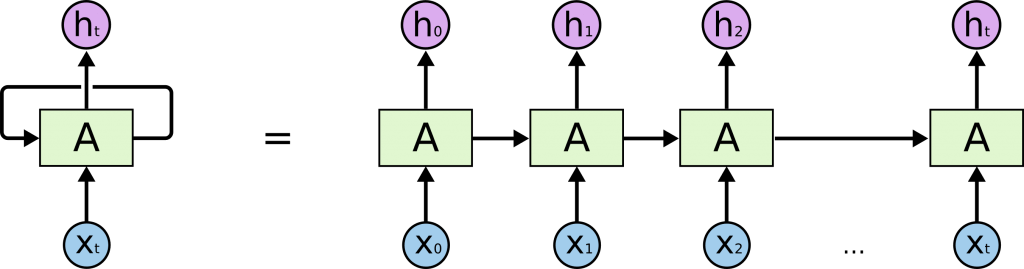 参考:Understanding LSTM Networks
参考:Understanding LSTM Networks
RNNとは、簡単に説明すると「過去のデータを使用できる」という特徴を持ったディープラーニングのことです。2016年9月にGNMTが公表され(深いLSTM=RNN系を採用)、その後Google翻訳に順次適用されました。これがGoogle翻訳の品質向上の主要因の一つと考えられます。
このようなRNNですが、動画や文章といった長い時系列データの場合、ネットワークが時系列長と比べて非常に深くなってしまうのも特徴のひとつです。そのため、情報が上手く伝達されないことも少なくありません。
そのような中で、ある程度の長い時系列データであっても学習できるように考案されたのが、次のLSTMと呼ばれるモデルです。
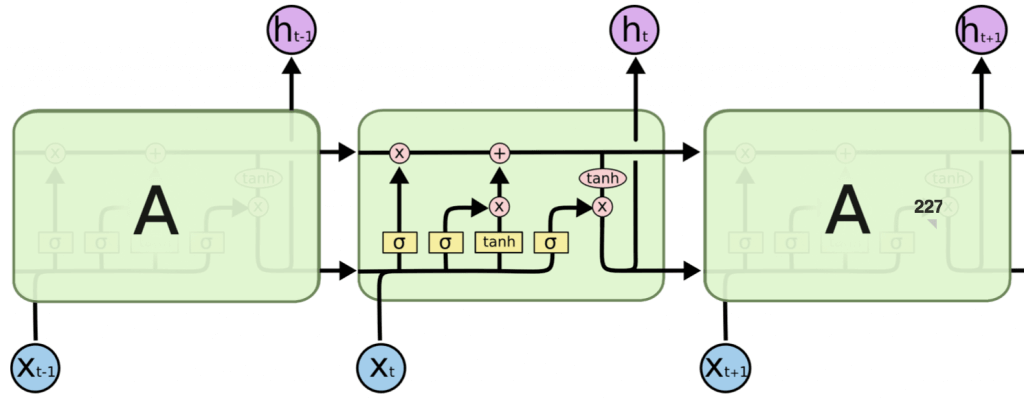 参考:Understanding LSTM Networks
参考:Understanding LSTM Networks
LSTMは、ある程度の長い時系列データでも学習ができるように考案されたモデルであり、「中間層にあるユニットをメモリユニットという要素で置き換えていること」が大きな特徴です。特別な種類のリカレントニューラルネットワークであるため、さまざまなタスクにおいて標準バージョン以上に優れた働きをしてくれます。
LSTMは、長期の依存性という問題を回避できるよう設計されています。「長時間の情報の記憶」に関しては実質的にデフォルトの動作のため、学習に苦労することもありません。
トランスフォーマー(Transformer)とは、自然言語処理タスクにおける強力なネットワークです。2017年に登場した比較的新しいネットワークであり、より素早く情報を集約できる自己注意機構(Self-Attention)を備えていることから注目されています。
これまで、高精度かつ学習時間も短い従来のモデルにおいては、RNNやCNNなど用いるのが一般的でした。しかし、トランスフォーマー(Transformer)では、Attentionという機構だけでネットワークを構築している点が大きな特徴といえます。Attentionとは、簡単にいえば「文に含まれる単語の意味を理解する上で、どの単語に注目すれば良いのかを示すスコア」です。
入力されたデータに対してスコアリングを行い、重要性を考慮したベクトル量として出力していきます。たとえば、ある画像データが入力されて画像の説明を出力するとします。この場合、Attention機構は生成済みの単語のコンテキスト情報を前の隠れ層から受け取って「次の画像の注目ポイント」を推論します。
BERTとは、Bidirectional Encoder Representations from Transformersを略した自然言語処理モデルであり、2018年10月にGoogle社のJacob Devlin氏らが発表したことで、大きな注目を集めました。日本語では「Transformerによる双方向のエンコード表現」と訳されています。
一般的に、翻訳や文書分類、質問応答といった自然言語処理における仕事の分野を「(自然言語処理)タスク」と呼びます。BERTは、この「タスク」において2018年当時の最高スコアを叩き出したことで注目されました。
BERTの特徴として、「文脈を読めるようになったこと」が挙げられます。Transformerと呼ばれるアーキテクチャ(構造)を組み込むことによって、文章を文頭・文末の双方向から学習し、文脈を読めるようになったのです。
GPTシリーズ(Generative Pre-trained Transformer)とは、OpenAIが開発した大規模言語モデルです。2020年に発表されたGPT-3は約1,750億個のパラメータを持ち、人間が書いたような自然な文章を生成できることから大きな注目を集めました。
その後、2023年3月にはマルチモーダル対応のGPT-4が発表され、テキストだけでなく画像も入力として処理できるようになりました。2024年5月には処理速度と効率性を向上させたGPT-4oが登場。2025年8月にはGPT-5がリリースされ、推論能力と非推論機能を統合したモデルとして大幅な性能向上を実現しました。2025年11月にはGPT-5.1が発表され、より自然な会話と適応的な推論機能を備えています。
こういった技術で、あたかも人間が書いたような文章を生成できることから、さまざまな場所で活用され始めています。
Geminiは、Googleが開発した最新のマルチモーダル大規模言語モデルです。2023年12月に発表されたGemini 1.0を皮切りに、テキスト、画像、音声、動画、コードなど、複数の形式のデータを統合的に理解・生成できるモデルとして進化を続けています。
2024年にはGemini 1.5が登場し、最大100万トークンという長大なコンテキストウィンドウを実現。2025年8月には画像生成・編集モデル「Nano Banana(Gemini 2.5 Flash Image)」が公開され、会話形式で画像の生成や編集ができる手軽さが話題となりました。同年11月にはGemini 3が発表され、LMArenaで史上初の1500点超えを達成。
さらに、Gemini 3の推論能力を活用した画像生成モデル「Nano Banana Pro」も登場しています。なお、Googleは以前PaLM(2022年4月発表、5,400億パラメータ)を開発していましたが、現在はGeminiシリーズに移行しています。

自然言語処理を活用してできることは、主に下表の通りです。
| 活用事例・できること | 概要 | |
|---|---|---|
| 検索エンジン | ユーザーの検索意図を理解し、関連性の高い情報を提供する | |
| エンタープライズサーチ(サーチ) | 企業内の大量の文書やデータから必要な情報を効率的に検索する | |
| 機械翻訳 | 二つの言語から別の言語へ、文脈を考慮して自然な翻訳を行う | |
| 文章要約 | 長文で重要なポイントを保持しながら短く要約する | |
| 対話型AI | AIチャットボット | 人間との対話を通じて質問に回答や問題解決を行う |
| ボイスボット | 音声による対話を通じて自然なコミュニケーションを実現する | |
| テキストマイニング | 大量のテキストデータから有用な情報やパターンを抽出する | |
| VoC分析 | 顧客の声を分析し、傾向や要望を把握する | |
| 感情認識・ネガポジ分析 | 文章から書き手の感情や評価の傾向を分析する | |
| 危険予知 | テキストデータから潜在的なリスクや危険を予測する | |
| 画像生成 | テキストの説明文から関連する画像を自動生成する | |
| メール文・記事作成 | 目的や要求に応じて文章を自動で作成する | |
| プログラミング | 自然言語に基づいてコードやプログラムを生成する | |
| AIスピーカー | 音声コマンドを理解し、適切な処理や操作を行う | |
| 感情認識 | 話者の声や文章から感情状態を判断する | |
| AI-OCRの精度向上 | 文字認識の精度を大幅に向上させる | |
活用事例から見ると、自然言語処理を活用するメリットには以下のようなものが挙げられます。
【自然言語処理の活用メリット】
自然言語処理の活用は、業務効率化、顧客体験向上、価値創造の三つの面で大きなメリットをもたらします。業務面では、エンタープライズサーチやAIチャットボットによる作業の自動化と効率化、24時間対応の実現が可能です。顧客対応においては、チャットボットやVoC分析を活用したリアルタイムの対応と顧客ニーズの把握により、カスタマイズされたサービス提供を実現します。
さらに、テキストマイニングによる意思決定支援や画像生成などのクリエイティブ支援により、新たな価値創造とリスク管理を可能にします。これらの総合的な効果により、企業の生産性向上と競争力強化を実現します。
自然言語処理を活用してできることについては、以下の記事でも詳しく解説しています。あわせて参考にしてみてください。
参考:自然言語処理でできることとは?最新AIで可能なテキスト解析・生成の活用シーンを紹介

自然言語処理における最大の課題は、人間の言語が持つ本質的な曖昧さにあります。たとえば「大丈夫です」という言葉は、肯定的な返事にも婉曲的な断りにもなり得るように、文脈や状況によって意味が大きく変わります。
また、人間が当たり前のように持っている一般常識をコンピュータに理解させることも大きな課題です。「昨日公園で猫を見た」は自然な文章ですが、「昨日公園でライオンを見た」は通常ではありえない状況であると人間は理解できます。しかし、コンピュータにとってはこのような常識的な判断が難しいのです。
さらに、言語や文化による違いも大きな課題となります。日本語特有の主語の省略や敬語、文化的な背景を必要とする表現、各言語特有の文法構造など、言語ごとに異なる特徴をシステムに適切に理解させる必要があります。
これらの課題に対応するためには、より高度な機械学習モデルの開発と、豊富な文化的コンテキストの学習が必要となります。

自然言語処理(NLP)は現在、様々な大規模言語モデル(LLM)により大きな転換期を迎えています。これらのモデルは、膨大なデータと高度なディープラーニング技術を組み合わせることで、より自然な言語理解と生成を実現しています。特に医療分野では、診断支援やカルテ分析、医療文献の要約など、専門的な知識を必要とする領域での活用が進んでおり、医療従事者の業務効率化に貢献しています。
また、テキストだけでなく画像や音声を組み合わせたマルチモーダルNLPの発展により、OpenAI の DALL·EやMidjourney、Stable Diffusionのような画像生成AI、音声認識と組み合わせた高度な対話システムなど、クリエイティブ分野での活用やより豊かなコミュニケーションが可能になっています。
今後は、さらなるモデルの大規模化と専門分野への適応、マルチモーダル技術の進化により、より幅広い産業での実用化が期待されています。

自然言語処理は、人間の言語をコンピュータが理解・処理する技術として、私たちの生活やビジネスに革新的な変化をもたらしています。AIの発展に伴い、機械翻訳やチャットボット、音声認識など、その応用範囲は着実に広がっています。
今後は、大規模言語モデルの進化やマルチモーダル技術の発展により、より自然で高度な言語処理が可能となり、医療、教育、ビジネスなど様々な分野での活用が期待されます。言語の壁を越え、人とAIのコミュニケーションがより豊かになる未来に向けて、自然言語処理技術は進化を続けていくでしょう。
AISmileyではG検定を取得したコンサルタントによる無料相談を承っております。社内の蓄積したアンケートの分析や過去の技術文書へのアクセスを容易にするなどAIを活用してみませんか?他社の動向や事例集のプレゼントもありますので、お気軽にお問い合わせください。
AIについて詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。















FOLLOW US
SNSをフォローして、最新情報をチェックできます!







AI製品・ソリューションの掲載を
希望される企業様はこちら