

異常検知とは?AI・機械学習手法や活用事例を紹介
最終更新日:2026/01/26
 異常検知とは?
異常検知とは?
AI・人工知能の技術が進歩したことにより、近年は多くの企業が業務にAIを導入するなどして、商品やサービスの向上を図っている状況です。特にAIは大量のデータを分析し、予測することを得意としているため、そのような業務をすべてAIに置き換えている企業も決して少なくありません。
そんな、大量のデータを扱う現代だからこそ、データの異常を検出する技術にも注目が集まっています。扱うデータの量が増えていけば、当然その中に異常なデータが含まれる可能性も増していくからです。今回は、そんな異常データの検出を行う「異常検知」について詳しくご紹介していきますので、ぜひ参考にしてみてください。
AIソリューションについて詳しく知りたい方は以下の記事もご覧ください。
AIソリューションの種類と事例を一覧に比較・紹介!
異常検知とは

異常検知とは、大量のデータから通常とは異なるもの(異常)を検出することをいいます。大量のデータのなかから法則性や傾向を見出す技術であるデータマイニングを利用してデータセット中の他のデータと照らし合わせを行い、一致していないものを識別していくという仕組みです。
そんな異常検知ですが、用途によっては「故障検知」「不正使用検知」といった呼ばれ方をすることもあります。そのため、これらを別物として捉えてしまう方もいますが、これらはすべて「他の大量のデータとは異なる振る舞いをみせるデータを検出する技術」であることに変わりはないため、すべて同じものと捉えて問題ありません。
なお、最近の異常検知では、メールや文書、動画、画像、Webサイトのログといった「非構造化データ」が用いられるケースが多くなっています。そのため、実際のビジネスにおいて活用していくためには、データ分析に関する知識や経験が必要です。また、異常検知では膨大なデータの傾向や法則性を学習する必要があることから、機械学習との親和性が高いことも特徴となります。
異常検知の主な手法
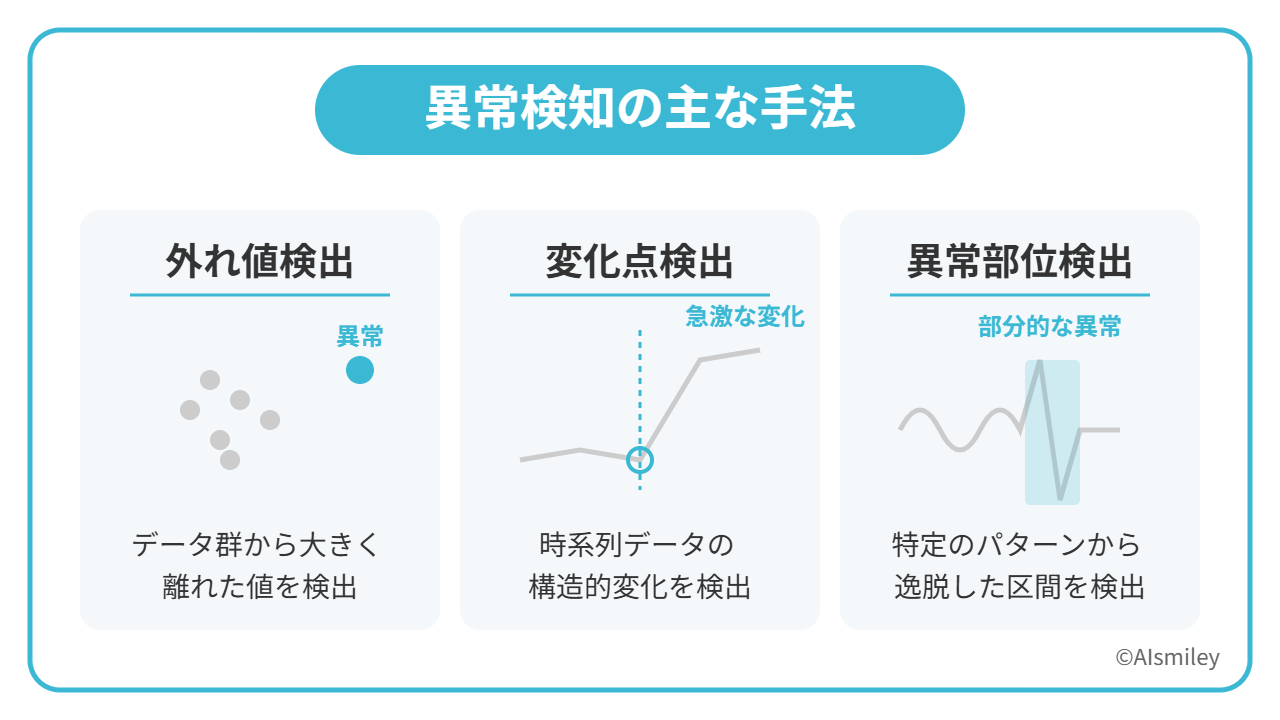
異常検知を行う方法にはいくつかの種類が存在します。大きく分けると、以下の3種類です。
- 外れ値検出
- 変化点検出
- 異常部位検出
外れ値検出
外れ値検出とは、データを記録する際に生じてしまった人為的なミスなど、全体から大きく外れているデータを検出する方法のことです。他の大半のデータとは値が大きく異なるため、機械学習によって過去のデータを積み重ねていくことで、より精度を高められるようになります。
変化点検出
変化点検出とは、データの構造や性質などといった時系列データのパターンが急激に変化する部分を検出する方法のことです。例えばWebサイトにおいて、特定のワードでのアクセスが、ある時期を境に急激に増加するケースなどがあります。この場合のアクセスが急激に増加する「境目」を検知できるのが、この変化点検出というわけです。
異常部位検出
異常部位検出とは、不正行為や不審行為など、通常とは明らかに違う動きを検出するための方法です。例えば、我々人間の心拍数は一定のリズムであることが大半ですが、急激な心拍数の変化(異常部位)だけを検出したい場合などには、この方法が活用できます。
異常検知に使われる機械学習モデル

異常検知システムを作成する際には、いくつかの機械学習モデルについて理解した上で取り組んでいくことが大切になります。それぞれの特徴を理解していなければ、異常検知のシステムに合ったモデルを選択できないからです。そのため、ここからは5つの機械学習モデルの特徴をご紹介していきますので、ぜひ参考にしてみてください。
- 教師あり学習
- 教師なし学習
- 半教師あり学習
- 強化学習
- 生成モデル
教師あり学習
教師あり学習とは、正解が用意されたデータを用いて機械学習を行うモデルです。教師あり学習には、「学習処理」と「判定処理」という2つのプロセスがあります。大量の学習データに「正常」「不良」といった判定ラベルを付けることで、AIに学習させていきます
ただし、一度学習させただけで認識精度が完璧になるわけではありません。人間と同じように、繰り返しトレーニングをしていくことで認識の精度を高めていくというものです。
教師なし学習
教師なし学習とは、正解となるデータがない状態で機械学習を行うモデルです。教師なし学習も事前に学習を行うという点においては教師あり学習と一緒です。ただ、教師あり学習と大きく異なるのは、「正常・不良といったラベルを付けることなく、大量のデータを読み込んでいく」という点にあります。そして、大量のデータを読み込んでいくことによって、次第にAIが自律的に認識を行うようになるわけです。
半教師あり学習
半教師あり学習は、教師あり学習と教師なし学習の中間的な特徴を持ち、「一部のデータにだけラベルを付ける」という作業をすることで、ラベルなしのデータを生かしていく機械学習モデルです。アルゴリズムとしては、混合ガウスモデルやブーストラップ法といったものが存在します。
基本的に、半教師あり学習のラベル付きデータだけでは疎かになってしまう部分が存在するわけですが、それをラベルなしのデータが補っていくことが可能です。
強化学習
強化学習とは、AIが試行錯誤を繰り返しながら最適な行動パターンを学習していく機械学習モデルです。その一例としては、試行錯誤を繰り返し、膨らんだ利益を獲得する方法などが挙げられます。そのため、株取引などの分野で活躍するケースが多い傾向にあり、異常検知ではあまり用いられることがありません。
生成モデル
生成モデルとは、学習済みのデータと似たデータを新たに生成できる機械学習モデルです。外れ値の検出を行うことができ、データをサンプリングできるという点が大きな特徴といえます。異常検知の分野でいうと、正常なデータのみを学習する必要があるケースにおいては重要な役割を果たす学習モデルです。
異常検知に使われる機械学習手法

異常検知に使われる機械学習手法は、下記のようにさまざまな種類が存在します。具体的にどのような種類が存在します。
- ホテリング理論
- K近傍法(k-NN)
- 単純ベイズ法(ナイーブベイズ)
- 局所外れ値因子法(lof法)
- 主成分分析(PCA)
- サポートベクターマシン(SVM)
- マージン最大化
- カーネル法
- ロジスティック回帰
- ニューラルネットワーク
上記のように異常検知に使われる機械学習手法にはさまざまな種類がありますが、なかでもホテリング理論やk近傍法(k-NN)は代表的な手法であるといえます。
ホテリング理論
ホテリング理論とは、統計的な異常値を見つける場合に利用する手法のことです。観測対象となるデータの値を計算した上で、「それが本当に異常値なのか」を導き出していきます。ただ、外れ値が多く存在している場合においては、ホテリング理論では「それが異常値なのかどうか」を判断することが難しい傾向にあります。
また、ホテリング理論では、正規分布を設定した上で計算を行っていくわけですが、正規分布の値が変化するような「時系列に沿ったもの」の場合、異常値を判断することはできません。
さらにホテリング理論はデータが単一の正規分布から発生していると仮定しているので、正規分布から著しく外れている場合、分布が複数の山を持つ場合などは異常値を正しく判断できなくなることにも注意が必要です。
k近傍法(k-NN)
k近傍法とは、時系列に対するデータに対して距離を定め、その距離から「異常値なのかどうか」を判断するという方法です。一例として、k近傍法を利用して外れ値の検知を行う場合には、主に以下のような方法が主体となります。
1.時系列に基づくデータセットから、特定の範囲のデータを切り取る
2.異常値までの距離を計算し、その距離の近さによって「異常値かどうか」を判断する
k近傍法を利用する場合は、「どの距離にあるものが異常値に該当するのか」を定め、そのルールに沿って判断を行います。そのため、「どの部分からデータを取り出すのか」「異常値となるポイントはどこからか」といった点を学習するためにも、異常値の調整が欠かせません。
また、k近傍法を利用する場合には、時系列データを「訓練データ」と「テストデータ」の2つに分けて、異常であるかを判断していく方法もあります。特定の期間を定め、「時系列データ」と「訓練データ」それぞれの類似度を計算し、2つの平均数値を異常値と判断します。
単純ベイズ法(ナイーブベイズ)
単純ベイズ法とは、あるデータがどのカテゴリーに属しているのかを判定するための機械学習手法です。「ナイーブベイズ」と呼ばれることもあります。単純な確率モデルをもとに、「次の式で定義される事後確率が最大となるクラスに観測データを分類していく」というベイズの識別規則に沿って予測するのが特徴です。そのため、比較的単純なアルゴリズムといえます。
局所外れ値因子法(lof法)
局所外れ値因子法とは、あるデータの集まりの中から外れ値を見つけ出していく外れ値検知アルゴリズムのことです。「lof法」と呼ばれることもあります。原論文は2000年の発表なので、最新の技術というわけではありませんが、現在においても実務に耐えうる検知性能を誇っており、シンプルな実装であることもメリットとされています。
lof法では、空間におけるデータの密度に着目していくのが特徴です。「自身の点から近傍 k 個の点とどれくらい密になっているか」を示す指標、「局所密度 (Local density) 」に注目していきます。ここでいう k 近傍は、「ある点から最も距離が近い k 個の点」のことです。
主成分分析(PCA)
主成分分析(PCA)は、教師なし学習の種類の一つです。さまざまな種類のデータを集約する手法のことを指します。たとえば、人が感じる味をデータ化する際には「甘み」「苦味」「酸味」「コク」といったさまざまな種類のデータを扱うことになります。
主成分分析では、もとの情報を損なってしまうことを避けながら、集約されたデータで表現を行うことが可能です。主成分分析においてデータが出力された際、そのデータが何を示しているかという点に関しては、人が解釈を与えなければなりません。
そのため、アンケートの各項目の評価を集計し、総合的な評価を示していくといった活用方法が一つの有効な活用方法です。
サポートベクターマシン(SVM)
サポートベクターマシン(SVM/Support Vector Machine)とは、機械学習モデルの中でも特に有名なアルゴリズムの1種です。機械学習の種類のうち、「教師あり学習」における「分類」のタスクで主に使用されています。少ない教師データを使ってスピーディな計算が可能で、高い汎化性があることなど使い勝手が良いことなどが特徴です。
サポートベクターマシンは、ディープラーニングが浸透する前の2000年〜2010年頃にかけて注目を集めました。現在は、Pythonのライブラリを用いた実装により、幅広いシーンで採用されています。
サポートベクターマシン(SVM)の特徴や仕組みを理解するために重要となるのが、後述する「マージン最大化」と「カーネル法」という2つの手法です。
マージン最大化
サポートベクターマシン(SVM)が高精度でクラス分類などのタスクを実行するために、「マージン最大化」と呼ばれる考え方を用いています。「マージン」とは、クラスの分類基準となる境界と、各データとの距離のことです。
「マージン最大化」は、このマージンを最大化すること、つまり2つのサポートベクトルから最も遠い位置に境界線を設定することを意味します。マージンが小さい場合、データが少し変動するだけで境界を超えてしまうため、分類結果が変わりやすく、誤判定のリスクが出てきます。
そこでSVMでは、マージンが最大となる境界線を引き、2つのクラス両方ともから離れているデータの正しい分類を目指します。マージン最大化により、SVMは深層学習(ディープラーニング)で使用されるニューラルネットワークよりも少ないデータで、高い汎用性を出すことが可能です。
カーネル法
サポートベクターマシン(SVM)のもう1つの重要な要素である「カーネル法」は、クラスの境界線が直線では表せない「非線形データ」を分類する手法です。非線形の特徴量をデータ表現に加えることで次元を増やせるため、高精度な分類を実行できます。
上と下、右と左というように直線的な境界線で分類できるデータの場合は、先述した「マージン最大化」を用いることで効率的に分類可能です。とはいえ、実際の現場ではシンプルなデータばかりではなく、AというデータがBというデータを囲むドーナツ状などのケースも考えられます。そこで、2次元(平面)データを3次元などの高次元空間へと拡張し、平面でしか表現できなかったデータを立体的に表現することで「平面による分離」を追加するのです。一般的な次元拡張では計算量が膨大かつ複雑になりがちですが、カーネル法では困難な計算を回避してタスクを実行できます。
ロジスティック回帰
ロジスティック回帰分析とは、多変量解析の一つで、ある特定の事象が起きる確率を分析するものです。具体的には、複数の価格帯、複数のカラー、ネット・実店舗など販売箇所などの要素から顧客がもっとも商品を購入する可能性が高い要素を分析する、機能限定版の無料試用ができるシステムで、限定する機能の内容によって購入する可能性が変わるかどうかを分析するといったことが可能です。
また、マーケティング以外にも日常生活から見る病気になる確率、気象観測などさまざまな場面でロジスティック回帰分析は利用されています。ロジスティック回帰分析の最大の特徴としては、エクセルのような表計算ソフトで一定の訓練を積めば比較的容易に分析作業が行える点です。データアナリストやデータサイエンティストのような専門家ではなくても分析が行えることも、大きな注目を集める理由の一つであると考えられます。
ニューラルネットワーク
ニューラルネットワーク(Neural Network)とは、脳の神経細胞(ニューロン)が持つ回路網を模した数理モデルです。脳内神経のネットワークで行われている情報処理の仕組みを、計算式に落とし込み、人工ニューロン(パーセプトロン)を使って数学的にモデル化したものを指します。ニューラルネットワークはデータから学習できるため、音声や映像、制御システムにおけるデータ識別・分類やパターン認識に向いている点が特徴です。また、時系列予測やモデリングにも活用できるので、未来の予測といった場面でも採用されています。
具体的なニューラルネットワークのプロセスを知る上では、大きく分けて「入力」「伝播」「出力」の3工程を把握することが大切です。まず「入力」の段階では、入力層に画像、ビデオ、音声、テキストなどのデータを入力します。次の「伝播」のステップでは、次の層に伝達されますが、伝播での処理は主に2つです。
1つ目は前の層のノードの出力値と、それに対応する重みの値を掛け合わせて計算値を算出し「重みづけ和」として和を計算します。2つ目は、計算された重みづけ和を活性化関数に通し、出てきた値を最終的な出力値として、次の層に伝達する処理です。ネットワーク内の出力層に到達するまで伝播処理が続きます。最後の「出力」で、出力層によって出力されるというプロセスです。出力層の結果は、ニューラルネットワークの学習に用いられる場合もあります。
異常検知を導入するメリット

異常検知を導入することで、以下の4つのメリットが期待できます。
- 人件費の削減に繋がる
- 人的リソースをコア業務に集中させられる
- ヒューマンエラーを防止できる
- 業務の属人化の予防ができる
これまで人間がチェックしていた作業を異常検知システムが行うことで、チェック作業の負担軽減やヒューマンエラーの防止が可能です。加えて、空いた時間でコア業務に注力したり、属人化を予防したりするメリットにもつながります。
人件費の削減に繋がる
異常検知を導入することによって得られる最大のメリットと言っても過言ではないのが、人件費を削減できるという点です。これまでは、人の目によって検知する体制を整えなければなりませんでした。また、人の目によるチェック作業にはミスが生じる可能性もあるため、複数の従業員によるダブルチェックなど、手間をかける必要もあったのです。
その点、異常検知システムを導入すれば、すべてのチェック作業をシステムに代行させられるため、大幅な人件費削減につなげることができます。
人的リソースをコア業務に集中させられる
人的リソースをコア業務に集中させられる点もメリットです。チェック作業を異常検知システムに代行させることで、これまで従業員が行っていたチェック作業が不要となり、業務時間に余裕が生まれます。
AIやロボットに代行することのできない「人間が力を注ぐ必要のある業務」にフォーカスできるようになるため、さらなる生産性向上が期待できるのです。
ヒューマンエラーを防止できる
人の目によるチェック作業では、ミスや見落としが生じるケースも少なくありません。また、経験や体調によって、チェックの精度に差が生まれてしまうことも多いのです。
その点、異常検知システムを活用すれば、常に一定のパフォーマンスを発揮することができます。当然、人間のように体調によってパフォーマンスが低下する心配もありません。そのため、24時間365日体制で、高精度な異常検知を維持できるのです。ヒューマンエラーを防止できれば、ミスが発生したときのように業務がストップすることもないため、さらなる生産性向上も期待できます。
業務の属人化の予防ができる
近年は、少子高齢化に伴う人手不足問題が深刻化しており、属人化も課題となっています。属人化とは特定の業務やノウハウが特定の人しかわからず、情報が共有されていない状態を指します。ベテランの従業員が培ってきたスキル・経験などを若手の従業員に継承することも難しくなってきている状況であり、異常検知の分野においても「高い精度でチェックを行うための技術」を若い人材に受け渡していく環境を構築するのは難しくなりつつあるのです。
だからこそ、最近では業務の属人化を防ぐことが重要視され始めています。異常検知システムは、まさにその「属人化防止」という観点でも大きな役割を果たす存在といえます。
異常検知の活用事例
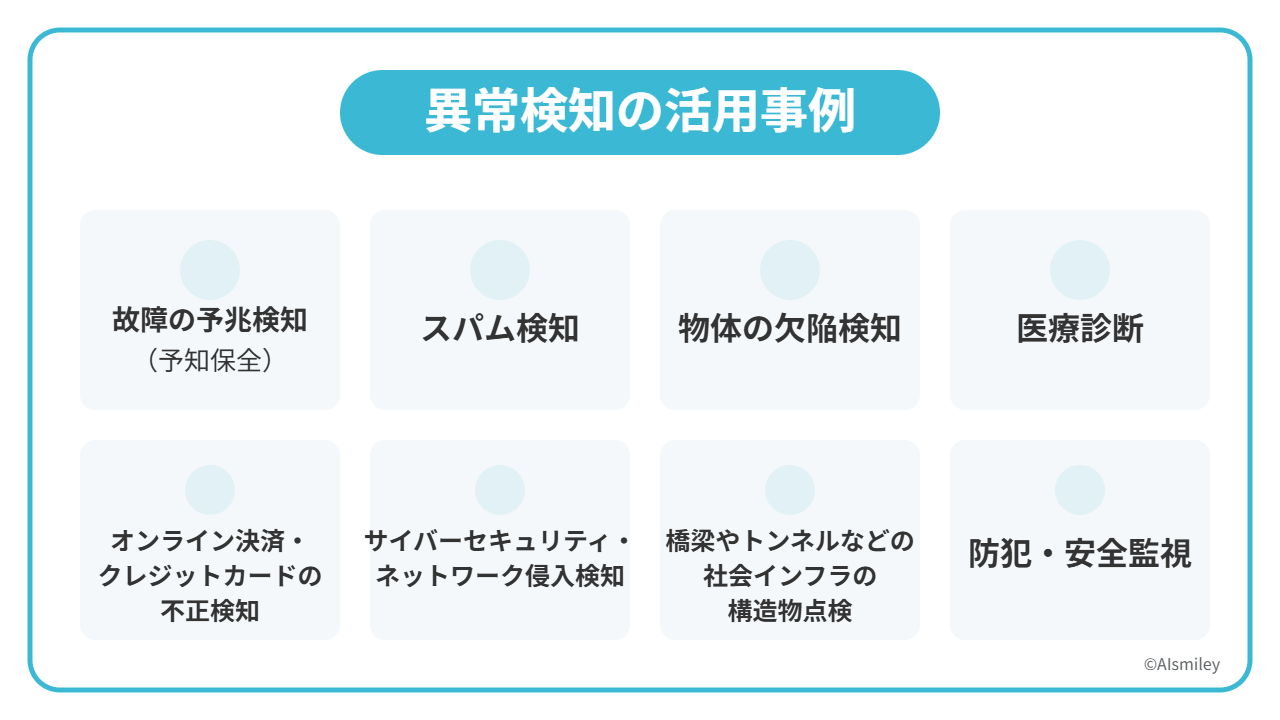
異常検知は、さまざまな場所で活用され始めています。実際にどのような場所で活用されているのか、その事例を詳しくみていきましょう。
故障の予兆検知(予知保全)
異常検知のシステムは、工場にある機械や設備の故障を予知し、その機械や設備を最適な状態で管理するための予兆検知(予知保全)でも活用されています。製造現場における設備の停止は、生産計画の狂いや莫大な損失を招きます。従来のメンテナンスは、一定期間ごとに部品を交換する「定期保全」が主流でしたが、AIを活用した異常検知により、壊れる前に予兆を捉えて修理する「予知保全」が可能になりました。
具体的には、回転機器(モーターやポンプ)に振動、温度、電流などのセンサーを設置し、正常稼働時のデータをAIに学習させます。稼働中にセンサー値が「正常なパターン」からわずかでも外れた場合、AIがそれを異常予兆として検知し、アラートを発します。これにより、突発的な故障によるライン停止(ダウンタイム)を最小限に抑え、部品寿命を最大限に活用することでメンテナンスコストの最適化を実現しています。
最近では、AIの活用によって異音を検知異音検知し、スピーディーに予知保全を進めていくことができるシステムなども多くなってきており、「故障の予兆検知」という分野も著しい発展を見せている状況なのです。
スパム検知
異常検知は、スパムの検知にも活用されています。迷惑メールやクレジットカードの不正仕様などが代表的な例として挙げられます。近年は技術が向上してきているため、スパムメールは自動的に迷惑メールボックスへと振り分けられるケースが多いです。
そのため、スパムメールの存在すら知らないという人も多いかもしれません。ただ、これは異常検知システムを活用しているからこそ、適切にスパムメールを自動的に迷惑メールボックスに振り分けることができているのです。
迷惑メールに多く利用されがちな単語、リンクをAIに学習させることによって、より高い精度で振り分けることが可能になっています。
物体の欠陥検知
製造業においては、製品の外観検査が必要不可欠です。外観に欠陥のある製品をそのまま出荷してしまった場合、大きな問題へと発展してしまう可能性があります。そのようなトラブルを避けるために、多くの製造業では外観検査を行うための体制を整えています。
異常検知システムは、そんな物体の欠陥検知にも多く活用されています。正常な製品と異なるポイントをいち早く見つけ出すことによって、より正確に欠陥のある物体を取り除くことができるのです。これまでは目視によるチェックが一般的でしたが、異常検知システムの導入によって業務効率化を実現する企業も多くなってきています。
医療診断
異常検知は、医療の分野でも役に立っています。たとえば、患者の身長・体重・血圧といったデータを読み込み、さらにセンサー等の最新機器を活用することによって、患者の健康状態にかかわるデータをリアルタイムで取得できるようになるのです。
このデータを効率的に収集すれば、医師の判断に役立つデータとして役立てていくことも可能になります。医療の質を高めるという点でも、異常検知は役に立っているのです。
オンライン決済・クレジットカードの不正検知
オンライン決済やクレジットカード取引では、不正利用をいかに早く検知できるかが重要です。AIを活用した異常検知では、過去の膨大な取引データを学習し、利用金額、購入頻度、時間帯、地域、端末情報などから「通常の利用パターン」をモデル化します。そのうえで、急激な高額決済、短時間での連続利用、普段と異なる国やECサイトでの利用といったパターン逸脱を異常として検知します。
教師あり学習による既知の不正検知に加え、教師なし学習を組み合わせることで、未知の不正手口にも対応可能です。不正被害の最小化、利用者保護、金融機関のリスク低減を同時に実現しています。
サイバーセキュリティ・ネットワーク侵入検知
サイバー攻撃が高度化・巧妙化する中、AIによる異常検知はネットワーク侵入対策の中核技術となっています。AIは通信ログ、アクセスログ、認証履歴などを解析し、平常時の通信量や接続先、挙動の傾向を学習します。
その結果、特定IPからの異常なアクセス集中、深夜帯の不審なログイン、通常とは異なるデータ転送量などを早期に検知できます。シグネチャベースでは検知が難しいゼロデイ攻撃や内部不正にも対応できる点が強みです。
橋梁やトンネルなどの社会インフラの構造物点検
老朽化が進む橋梁やトンネルなどの社会インフラでは、AIによる異常検知が点検業務の効率化と高度化に貢献しています。ドローンや車載カメラで撮影した画像、振動・ひずみ・傾斜などのセンサーデータをAIが解析し、ひび割れ、剥離、変形といった異常を検知します。
AIは過去の点検データから正常状態を学習し、微細な劣化の兆候も捉えられるため、目視点検では見逃されやすい初期異常の発見が可能です。これにより、点検コストの削減、作業員の安全確保、計画的な補修による事故防止につながります。
防犯・安全監視
防犯や安全監視の分野でも、AI異常検知の活用が進んでいます。監視カメラ映像をAIがリアルタイム解析し、徘徊、不審な滞留、立ち入り禁止エリアへの侵入、転倒など、通常とは異なる行動を検知します。
従来は人が常時モニタリングする必要がありましたが、AIにより異常時のみアラートを出す運用が可能になります。商業施設、駅、工場、介護施設などで活用され、防犯強化だけでなく事故やトラブルの未然防止にも寄与します。人手不足対策と安全性向上を両立できる点が大きな特長です。
異常検知AIカオスマップでサービスを比較する

今回は、異常検知の仕組みや種類などについて詳しくご紹介しました。AIを用いて生産性向上や業務効率化を図る企業は非常に多くなっていますが、大量のデータを扱うようになるにつれて異常なデータが混ざり込む可能性も増えていくため、異常検知システムは必要不可欠なものになっていくと考えられます。
また、ログやリソースデータを蓄積していくのではなく、調査や分析によって異常検知の精度を高めていくことも極めて重要になります。そのためにも、一人ひとりがAIに関する知識を養い、根本から理解していくことが重要になるのではないでしょうか。
AIsmileyでは、異常検知のAIについて比較検討できるカオスマップを無料でお配りしています。異常検知AIの導入を検討の際は、ぜひお気軽にご活用ください。
AIについて詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
- AIサービス
- 異常検知・予知保全
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI










FOLLOW US
SNSをフォローして、最新情報をチェックできます!

ソフトバンク、株主総会で新AI戦略を発表。次世代社会インフラ構築…

MASC、ヒューマノイドロボット「Unitree G1」導入。「…

静岡県藤枝市、全国初となる国産生成AIの公共活用実証実施。ソフト…
AVITAのAIロープレ「アバトレ」、日本調剤の薬局全国768店…

アイスマイリー、 7/29(水)から3日間「イプロスAI 2026 夏」にブース出展。来場登録・実来場でAmazonギフト500円分プレゼント!

アイスマイリー、7/22(水)から3日間「AI World 2026 夏 東京」に出展 ブース予約でAmazonギフト1,500円分プレゼント!

北海道エアポート、ターンアラウンド管理システム「ApronAI」を新千歳空港の国際線8スポットに導入

防除研究所、AIクマ検知システムの実地検証を開始。広域的な実証検証体制の構築を加速

自動運転レベルとは?0〜5の定義・対応車種・実用化へのロードマップをわかりやすく解説

ADAS(先進運転支援システム)とは?自動運転との違いや機能・義務化の流れまでわかりやすく解説
AI製品・ソリューションの掲載を
希望される企業様はこちら