

スパコン「富岳」、大規模言語モデルの分散並列学習手法の研究開発を開始
最終更新日:2024/01/17
 スパコン富岳、新研究開発を開始
スパコン富岳、新研究開発を開始
東京工業大学、東北大学、富士通、理化学研究所は5月22日、スーパーコンピュータ「富岳」の政策対応枠を活用して、大規模言語モデル(LLM)の分散並列学習手法の研究開発を開始すると発表しました。
このAIニュースのポイント
- 「富岳」は、理化学研究所と富士通が2014年から開発を進め、2021年3月に完成したスーパーコンピュータ
- 今回の研究開発は富岳の超大規模な並列計算環境において、LLMの学習を効率良く実行する技術となる
- 研究結果は「GitHub」や「Hugging Face」を通じて公開予定、また今後は名古屋大学やサイバーエージェントとの連携も検討
国立大学法人東京工業大学、国立大学法人東北大学、富士通株式会社、国立研究開発法人理化学研究所は5月22日、「富岳」政策対応枠において、スーパーコンピュータ「富岳」を活用した大規模言語モデル(LLM)の分散並列学習手法の研究開発を開始すると発表しました。
ChatGPTに代表される大規模深層学習モデル(基盤モデル)は、インターネットやスマートフォンのように社会全体のあり方を変える革新的な技術であり、Society5.0における研究開発、経済社会、安全保障などのあらゆる側面から基盤技術として期待される一方で、基盤モデルの性能を高めるためには大量データを効率的に処理する高性能計算資源が不可欠です。
そこで東京工業大学、東北大学、富士通、理化学研究所の4者は、今後この研究開発の成果物を公開することで、アカデミアや企業が幅広く使える大規模言語モデルの構築環境を整え、国内におけるAIの研究力向上に貢献し、学術および産業の両面で「富岳」の活用価値を高めることを目指します。今回開発する大規模言語モデル分散並列学習手法は、スーパーコンピュータ「富岳」の超大規模な並列計算環境において、大規模言語モデル学習を効率良く実行する技術となります。
今後4者は、日本の研究者やエンジニアが大規模言語モデルの開発に活用できるように、今回の「富岳」政策対応枠で得られた研究成果を、2024年度に「GitHub」や「Hugging Face」を通じて公開する予定です。また、多くの研究者や技術者が基盤モデルの改善や新たな応用研究に参画することで、効率的な方法が創出され、次世代の革新的な研究やビジネスの成果に繋がることが期待されます。
さらに今後は、ものづくりをはじめとする産業分野などへの応用を想定した、マルチモーダル化のためのデータ生成手法および学習手法の開発を行う名古屋大学や、大規模言語モデル構築のためのデータおよび技術提供を行うサイバーエージェントとの連携も今後検討していくと発表しています。
出典:富士通株式会社
- AIサービス
- AI研究開発
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI














FOLLOW US
SNSをフォローして、最新情報をチェックできます!

リコーとライズ・コンサルティング・グループ、AI実装・活用を一貫…
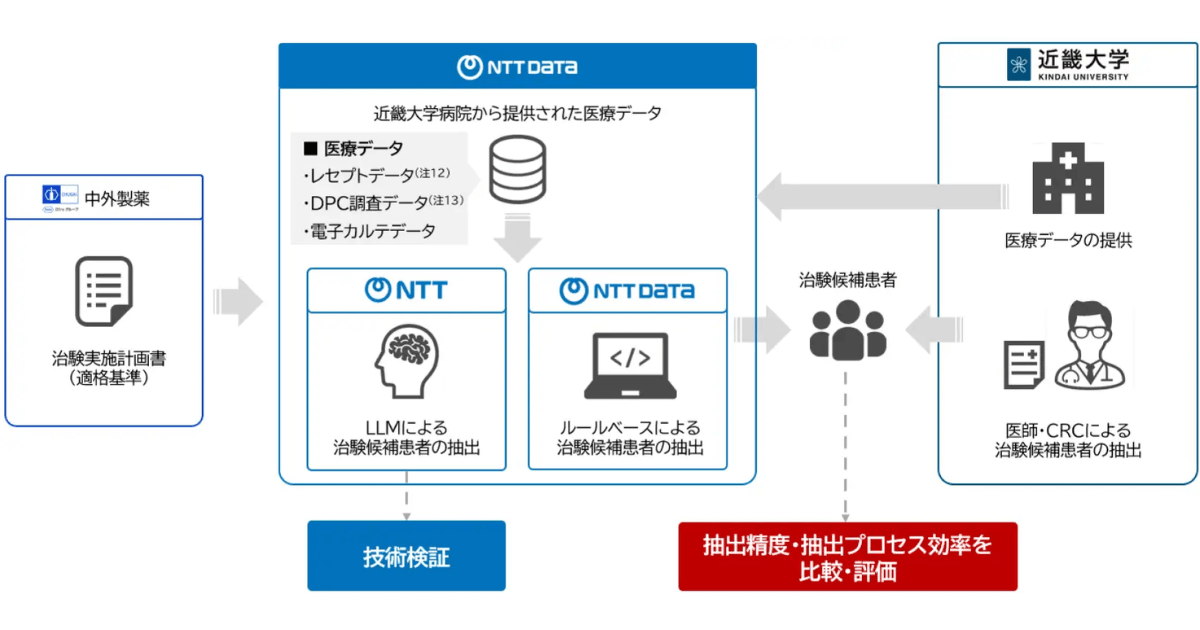
近畿大学病院など4者、リアルワールドデータとLLMを用いた共同研…
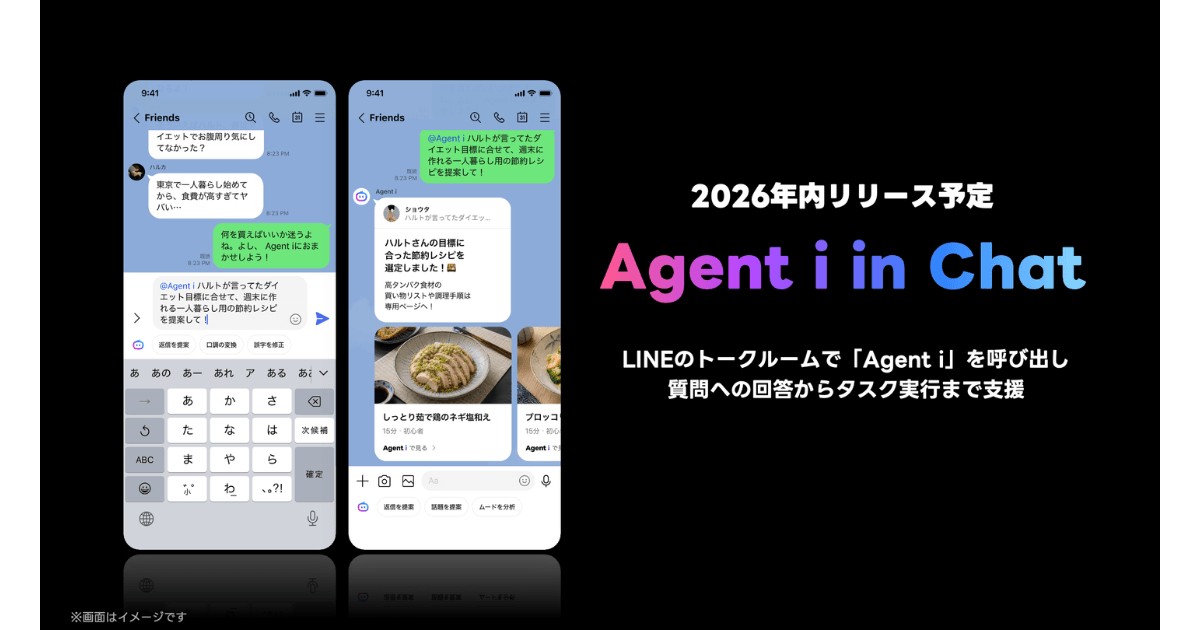
LINEヤフー、「LINE」新機能「Agent i in cha…
Sakana AI、「Sakana Chat」に翻訳機能を追加。…
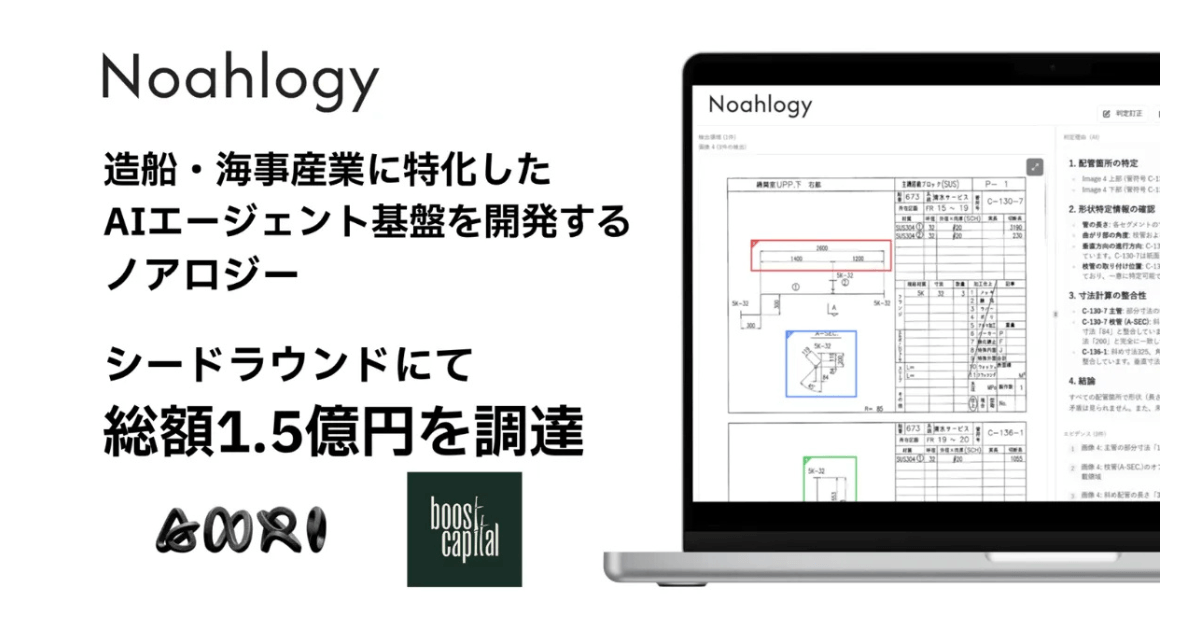
Noahlogy、シードラウンドで総額1.5億円を調達。海事産業のAIネイティブ化を加速
近畿大学病院など4者、リアルワールドデータとLLMを用いた共同研究を開始。治験候補患者抽出の精度向上と効率化を図る
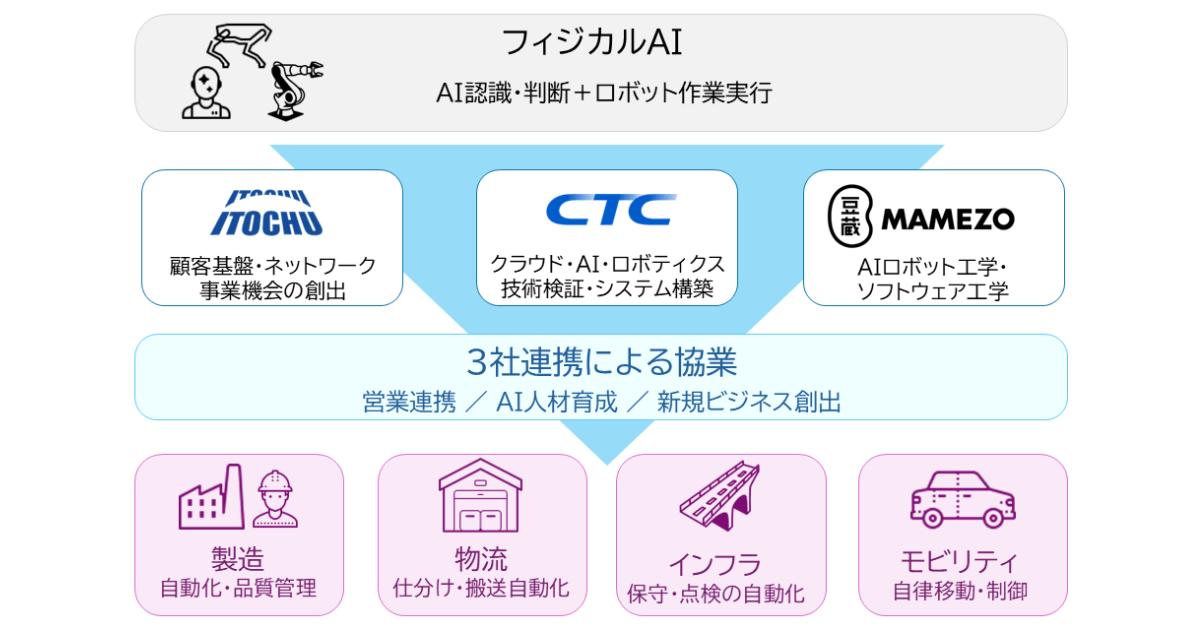
伊藤忠商事・伊藤忠テクノソリューションズ・豆蔵が業務提携。フィジカルAIの社会実装を推進

政府、フィジカルAI領域で10.5兆円規模の官民投資を引き出す方針。「国産マルチモーダル基盤」構築に向け予算編成改革を実施

Anthropic、米政府の輸出規制解除により「Fable 5」と「Mythos 5」の提供を再開

Anthropic、新モデル「Claude Sonnet 5」発表。「Opus 4.8」に迫る性能を低価格で実現
AI製品・ソリューションの掲載を
希望される企業様はこちら