

生成AI

最終更新日:2024/02/07
 ChatGPTの新モデルGPT-4発表
ChatGPTの新モデルGPT-4発表
OpenAIは、大規模マルチモーダルAI「GPT-4」を新たに発表しました。
このAIニュースのポイント
OpenAIは、ディープラーニングのスケーリングアップの取り組みの中で、最新の大規模マルチモーダルである「GPT-4」を発表しました。
GPT-4は、多くの現実世界のシナリオでは人間よりも処理能力が劣りますが、プロフェッショナルや学術的なベンチマークにおいては、人間レベルのパフォーマンスを発揮します。例えば、司法試験を受験させた場合、上位10%程度のスコアを記録しています。一方で、GPT-3.5のスコアは下位10%程度でした。
敵対的学習とChatGPTからの教訓を反復的に取り入れ、GPT-4を学習させるために6ヶ月間を費やした結果、誤分類が大幅に減少しました。
カジュアルな会話では、GPT-3.5とGPT-4の違いは微妙です。しかし、タスクの複雑さが十分な閾値に達すると、GPT-4はGPT-3.5よりも信頼性が高く、創造性があり、より微妙な指示を扱うことが可能になります。
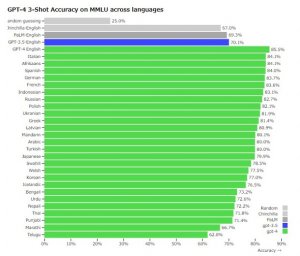
既存の多くのベンチマークは英語で記述されています。他の言語における能力の初期段階の把握のために、57の科目にまたがる14,000の多肢選択問題のスイートであるMMLUベンチマークを、Azure Translateを使用してさまざまな言語に翻訳しました。26言語中24言語で、GPT-4はGPT-3.5のパフォーマンスを上回っていました。
GPT-4は、テキストだけでなくテキストと画像のプロンプトを受け取ることが可能です。テキストのみの設定と並行して、ユーザーは任意の視角または言語タスクを指定できます。テキストと写真、図表、スクリーンショットを含むさまざまなドメインにおいて、テキストのみの入力と同様の能力を発揮します。
依然としてGPT-4は、事実を誤認したり、推論エラーを起こすことがあるので、完全に信頼できるサービスではありません。特にリスクの高い文脈で使用する際に細心の注意が必要です。しかしながら、内部の敵対的事実性評価よって、GPT-3.5よりも40%高いスコアを獲得しています。
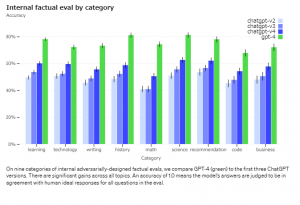
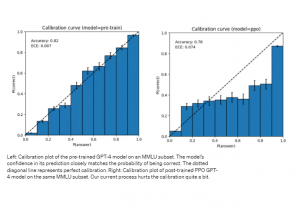
また、GPT-4は、エラーを犯す可能性がある際に、再確認を怠ることがあります。興味深いことに事前に学習済のデータは、高精度に調節されています。
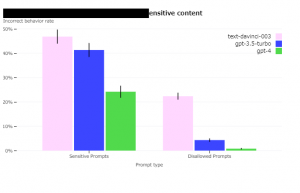
GPT-4は、GPT-3.5と比較し、モデルが許可していないコンテンツのリクエストに応答する傾向が82%減少しました。また、ポリシーに従って機密性の高いリクエストに応答する頻度が29%向上しました。
AIシステムの「トークンあたりのリスク」が増加するにつれて、これらの介入で非常に高い信頼性を達成することが重要になります。現時点では、不正使用の監視などの展開時の安全技術でこれらの制限を補完することが重視されます。
OpenAIは、より良いガイダンスを社会に提供する方法を開発する取り組みを拡大しており、これがこの分野の共通の目標になることを願っています。
出展:OpenAI
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。















FOLLOW US
SNSをフォローして、最新情報をチェックできます!







AI製品・ソリューションの掲載を
希望される企業様はこちら