

生成AI

最終更新日:2024/03/06
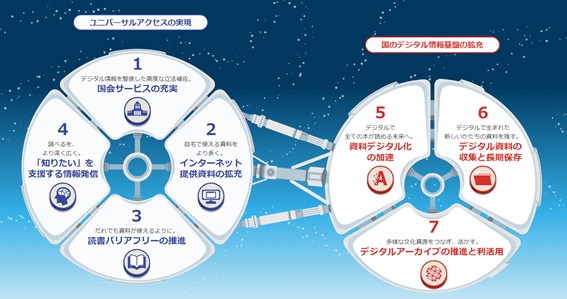 国立国会図書館でOCRを活用
国立国会図書館でOCRを活用
国立国会図書館から委託を受けた「OCR処理プログラムの研究開発」が完了したことを、モルフォAIソリューションズが発表しました。
このAIニュースのポイント
株式会社モルフォAIソリューションズは、国立国会図書館からの「OCR処理プログラム研究開発」委託事業の完了を発表しました。
このOCR処理プログラムの開発により、国立国会図書館デジタルコレクション上で提供される資料画像において、本文テキストデータの作成を行えるようになりました。また、凸版印刷株式会社の協力により約1,300万文字のOCR学習用データセットを構築しています。
これにより、多様なレイアウト・文字種に対応できるようになり、既存のOCRサービスが対応できなかった明治期~昭和期までの複雑な資料のテキスト化が可能になりました。たとえば、戦前の旧かな文字を多用した文章でもスムーズなテキスト化ができます。

このほか、OCR処理プログラムの精度も向上しています。市販OCRでは、明治期~昭和初期の近代書籍・雑誌において、読み取り精度が約40%しかありませんでした。今回開発されたOCR処理プログラムでは、90%以上の読み取り精度を実現しています。
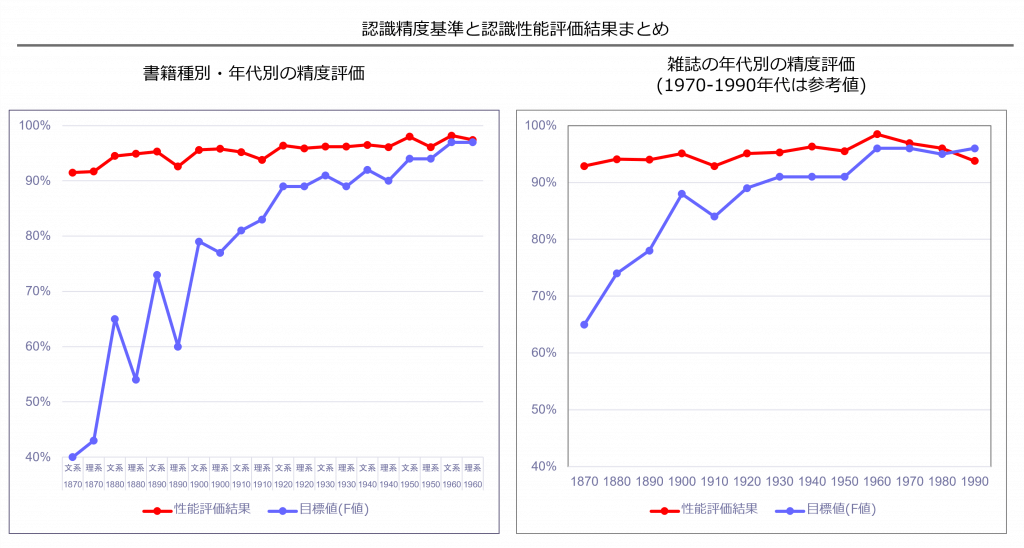
学習用データを用意すれば追加学習も可能で、今後国立国会図書館がデジタル化する資料の全文テキストデータ作成に使用されます。プログラムのほかに、開発に用いた機械学習用データセット(著作権保護期間が満了したデジタル化資料から作成した分のみ)も近々に公開予定です。
このOCR処理プログラムの活用により、国立国会図書館に収蔵されている数々の貴重な資料がより幅広い分野で活用されることが期待されています。
出典:PR TIMES
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。















FOLLOW US
SNSをフォローして、最新情報をチェックできます!






AI製品・ソリューションの掲載を
希望される企業様はこちら