

生成AI

最終更新日:2024/01/17
 松尾研 日英対応LLMを公開
松尾研 日英対応LLMを公開
東京大学松尾研究室は、100億パラメータサイズの大規模言語モデル「Weblab-10B」を開発し、2023年8月18日にモデルを公開しました。
このAIニュースのポイント
東京大学松尾研究室は、日英の2ヶ国語に対応した100億パラメータサイズの大規模言語モデル「Weblab-10B」を、事前学習と事後学習により開発し、非商用ライセンスでモデルを無料公開しました。

生成サンプル文
近年の大規模言語モデルは、インターネットから収集した大量のテキストデータを学習に用いますが、そのテキストデータの多くは英語などの一部の主要言語で構成されており、現状では日本語など、主要言語以外のテキストデータを大量に収集することに限界がありました。
松尾研究室が今回開発した「Weblab-10B」は、日本語だけでなく英語のデータセットも学習に用いることで、学習データ量を拡張し、言語間の知識転移を行うことで日本語の精度を高めています。
日英2ヶ国語対応の大規模言語モデル開発にあたり、事前学習には代表的な英語のデータセットThe Pileおよび日本語のデータセット Japanese-mC4を、事後学習には、Alpaca(英語)、Alpaca(日本語訳)、Flan 2021(英語)、Flan CoT(英語)、Flan Dialog(英語)の5つのデータセットを使用しています。事後学習の日本語データ比率が低いにも関わらず、日本語のベンチマークであるJGLUE評価値が事前学習時と比べて、66%から78%と大幅に改善し、この数値は国内の公開モデルとしては最高水準の精度を誇ります。
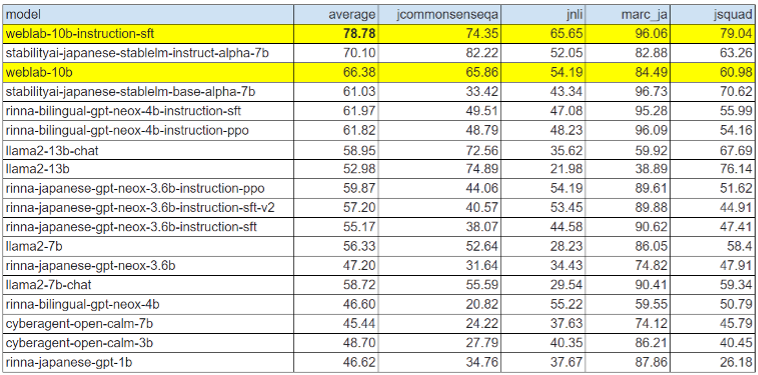
公開されている日本語対応モデルの比較表
松尾研究室は「今後も、Weblab-10Bのさらなる大規模化を進めるとともに、LLMの産業実装に向けた研究を推進していきます」とコメントしています。
出典:東京大学松尾研究室
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!








AI製品・ソリューションの掲載を
希望される企業様はこちら