

生成AI

最終更新日:2025/08/25
 ローカルLLMについて詳しく解説
ローカルLLMについて詳しく解説
ChatGPTをはじめ、多くのテキスト生成AIが、ビジネスや生活に浸透してきました。「自分でもAIアプリを作成したいけれど、外部にデータを送信することが少し不安。」「自分のPCやローカル環境でLLMを動かしてみたい」と思っている人はいませんか?
ローカルLLMはセキュリティやプライバシーを自分の手でしっかりと守れる反面、スペックが足りるか、セットアップがスムーズにいくかなど不安に感じることも多いでしょう。
この記事では、ローカルLLMを導入するメリットからおすすめのローカルLLMまで詳しく解説します。
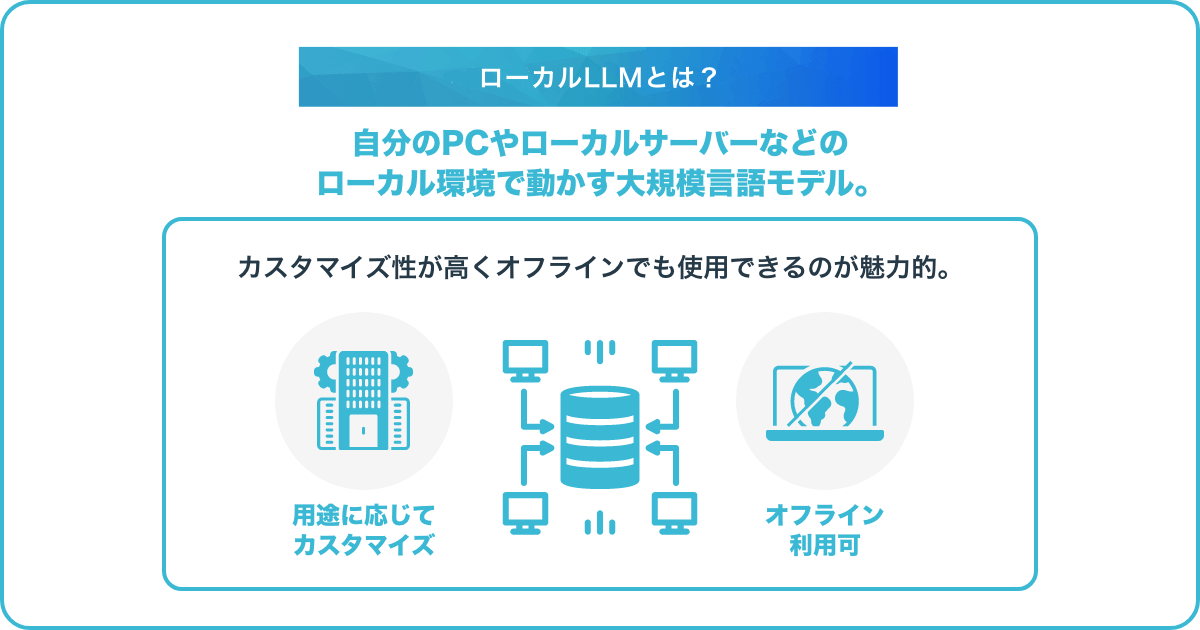
ローカルLLMとは、自分のPCやローカルサーバーなどのローカル環境で動かす大規模言語モデルを指します。LLMとは大規模言語モデルを指し、ローカルLLMはすべて手元の環境で処理されるため、生成したい文章や質問のデータが外部サーバーへ送信されません。特に厳格な情報セキュリティ要件に対応しやすい点が特徴です。
クラウド環境で動かす大規模言語モデル(ホステッドLLM)とローカルLLMの違いは以下の通りです。
| 項目 | ホステッドLLM | ローカルLLM |
| 実行環境 | クラウド(OpenAI、Anthropicなど) | PC、ローカルサーバー |
| インターネット接続 | 必要 | 不要(完全オフラインも可能) |
| セットアップ | 簡単(APIキー取得のみ) | 難易度が高い(モデルDL・環境構築が必要) |
| プライバシー | データが外部サーバーに送信される | データはローカルサーバー内で処理する |
| カスタマイズ性 | 低い(APIの仕様に依存する) | 高い(ファインチューニングができる) |
| コスト | 使用量に応じたランニングコストがかかる | PCやサーバーなどのイニシャルコスト、電気代などのランニングコストが両方かかる |
| 利用できるモデル | 高性能な最新モデルが中心 | 軽量モデルが中心 |
ローカルLLMはコストやセットアップの難易度は高くなるものの、カスタマイズ性が高くオフラインでも使用できる点がメリットです。
一方ホステッドLLMはカスタマイズ性こそ低いものの、すぐに使える手軽さや、最新かつ大規模なモデルを使える点が魅力的です。
自分がLLMをどのように活用したいかを考慮して選択しましょう。
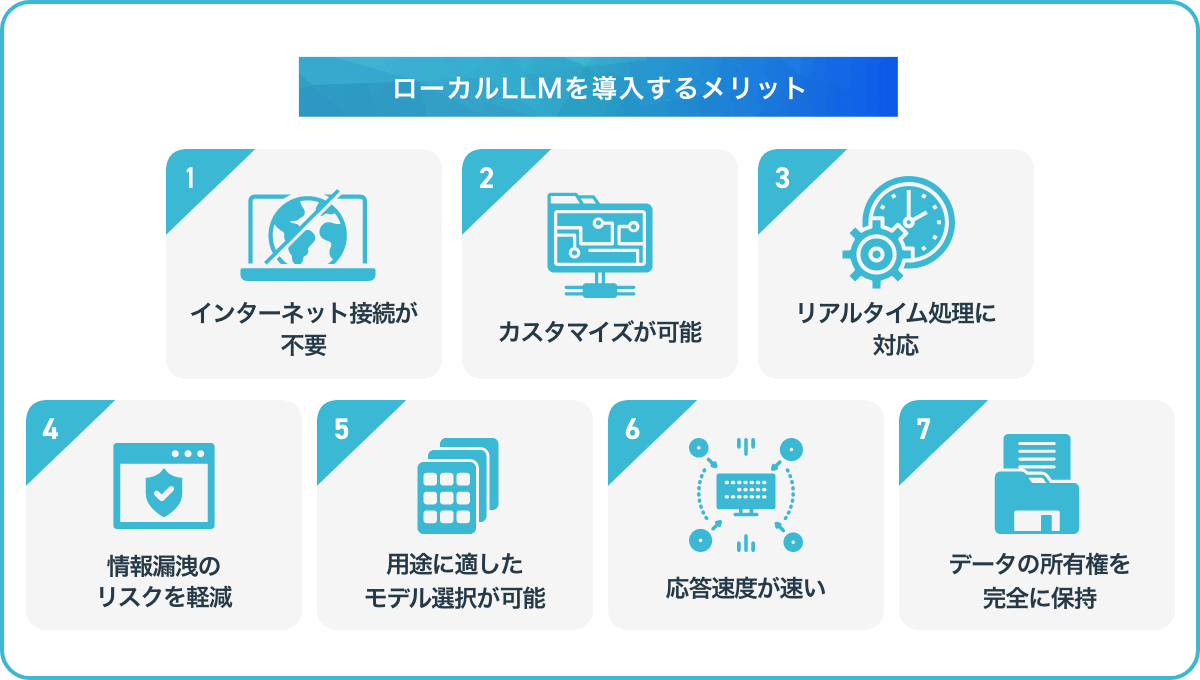
ローカルLLMを導入するメリットは以下の通りです。
| 項目 | 概要 |
| インターネット接続が不要 | 接続が不安定な場所や、セキュリティ要件が厳しい環境でも利用可能 |
| カスタマイズが可能 | 業務やプロジェクトに合わせて最適なモデル設計ができる |
| リアルタイム処理に対応 | クラウドを介さないため、処理速度が速く即時応答できる |
| 情報漏洩のリスクを軽減 | データを外部に送信しないため、セキュリティが向上する |
| 用途に適したモデル選択が可能 | タスクに最適なモデルを自分で選べる柔軟性がある |
| 応答速度が速い | ローカル処理によるスピーディな動作でネットワーク遅延も発生しない |
| データの所有権を完全に保持 | すべてのデータを管理・統制できる |
上記のメリットが魅力的であると感じる場合は、クラウド型ではなくローカルLLMの導入を前向きに検討してみましょう。
ローカルLLMを動作させるために必要なマシンスペックの目安は次の通りです。
| パーツ | 軽量モデル(例:Phi-2、Mistral) | 中型モデル(例:LLaMA 2 7B) | 高性能モデル例:LLaMA 2 13B、Mixtral) |
| CPU | Intel Core i5 / Ryzen 5 以上 | Intel Core i7 / Ryzen 7 以上 | Intel Core i9 / Ryzen 9 推奨 |
| GPU | VRAM 12GB以上 | VRAM 24GB以上 | VRAM 24GB以上推奨 |
| RAM(メモリ) | 16GB以上 | 32GB以上 | 64GB以上 |
| ストレージ | SSD 500GB以上 | SSD 1TB以上 | SSD 2TB以上(M.2推奨) |
| 電源 | 600W程度 | 750W以上 | 850W〜1000W(安定性重視) |
| 冷却システム | 空冷 | 空冷または簡易水冷 | 水冷推奨(特にGPU温度に注意) |
| PCケース | ミドルタワー | ミドル~フルタワー | フルタワー推奨(放熱と拡張性のため) |
比較的軽量モデルであれば、一般的なPCでも動作しますが、高性能モデルになるとややマシン性能が高くないと動かない可能性があるので注意してください。
モデルの種類や使用目的、最適化状況によって必要なスペックは変わるため、環境や用途に合わせて検討してください。

使用する目的別におすすめのモデルをご紹介します。
Gemma3はGoogle DeepMindが開発した、質問応答や要約、推論など、幅広い生成タスクに対応する高性能モデルです。
オープンソースでKaggleとHugging Face からダウンロードできます。
Gemma3の主な機能は次の通りです。
| 項目 | 概要 |
| マルチモーダル機能 | テキストや画像など複数の形式のデータを入力して理解、分析できる |
| 入力コンテキストの上限 | 128,000トークンのコンテキスト(文脈や背景情報)を入力できるため、より多くのデータを分析したり、複雑な課題を解決したりできる |
| 関数呼び出し機能 | プログラミングインターフェースを操作するための自然言語インターフェースを構築できる |
| サポート言語 | 140を超える言語をサポートしているため、自分が普段使っている言語で作業できるだけではなく、AIアプリケーションの言語機能を拡張することもできる |
| モデルサイズと精度レベルの選択 | タスクとコンピューティングリソースに最適なモデルサイズ(10 億、40 億、120 億、270 億)と精度レベルを選択できる |
Gemma3はローカルLLMを幅広い複数のタスクで活用したい人におすすめです。
参考:Google AI for Developers「Gemma 3 モデルの概要」
Mistral NeMoは2024 年 7 月にMistral AIがリリースした、多言語対応に長けたオープンソースのモデルです。
Mistral NeMoには以下の特徴があります。
Mistral NeMoは多言語対応が求められるチャットボットやグローバル向けAIサービスの開発に適しており、海外展開を視野に入れている開発者や企業におすすめです。
日本語対応は、Mistral-Nemo-Japanese-Instruct-2408として、cyberagentから展開されています。
参考:cyberagent/Mistral-Nemo-Japanese-Instruct-2408 · Hugging Face
CyberAgentLM3は2024年7月に株式会社サイバーエージェントがリリースした、オリジナルの日本語大規模言語モデルです。
株式会社サイバーエージェントは日本語LLMの研究開発に継続的に取り組んでおり、2023年5月に初代「CyberAgentLM」、同年11月に改良版の「CyberAgentLM2」をリリースしました。
そして2024年7月、さらに進化した最新版「CyberAgentLM3」が登場しました。
Nejumi LLM リーダーボード3において、CyberAgentLM3は700億パラメータのMeta-Llama-3-70B-Instructと同等の性能と高く評価されています。
Nejumi LLM リーダーボード3は、日本語での性能評価に特化したベンチマークで、国内LLMの比較に広く活用されています。
CyberAgentLM3は以下のようなスペックを持ち、Hugging faceよりダウンロード可能です。
| 項目 | 詳細 |
| モデルサイズ | 225億パラメータ(22B) |
| コンテキストの長さ | 16384 |
| モデルの種類 | Transformer-based Language Model |
| 言語 | 日本語、英語 |
| ライセンス | Apache-2.0 |
CyberAgentLM3は日本語の自然な理解と出力に強みがあるため、国内向けのチャットボットや文章生成ツールなど、精度の高い日本語処理を求めるアプリケーション開発をしたい人におすすめです。
参考:Hugging face「calm3-22b-chat」
参考:CyberAgent「独自の日本語LLM(大規模言語モデル)のバージョン3を一般公開 ―225億パラメータの商用利用可能なモデルを提供―」
Qwen2-72B-Instructは、2024年6月29日にQwenグループがリリースした、マルチモーダル対応の大規模言語モデルです。
テキストと画像の両方を入力でき、より柔軟にAIアプリケーションの開発ができます。
Qwen2-72B-Instructには以下のような特徴があり、Hugging faceからダウンロードできます。
| 項目 | 詳細 |
| モデルサイズ | 720億パラメータ(72B) |
| 対応形式 | テキスト+画像(マルチモーダル) |
| 学習データ | 高品質な多言語・多形式データをベースに構築 |
| 指示追従能力(指示や問いかけにどれだけ正確に応えられるかを表す能力) | Instructチューニング済みで、対話形式の指示に高精度で応答 |
Qwen2-72B-Instructは最新で複数の形式のデータ(テキスト・画像・音声など)によってトレーニングをしたため、マルチモーダル対応ができるLLMになりました。
Qwen2-72B-Instructは、テキストと画像の両方を活用したAIアプリケーションを開発したい人におすすめです。
参考:Hugging face「Qwen2-72B-Instruct」
Phi-4はMicrosoft Researchが2024年12月12日にリリースしたオープンソースの大規模言語モデルで、軽量で高度な推論性能を備えています。
Phi-4は次のような特徴を持ち、Hugging faceからダウンロードできます。
| 項目 | 詳細 |
| モデルサイズ | 140億パラメータ(14B) |
| アーキテクチャ | デコーダーオンリーのTransformer構造 |
| 入力形式 | テキスト(チャット形式が最適) |
| コンテキスト長 | 最大16Kトークン |
| トレーニングデータ | 約9.8兆トークン、2024年6月以前のオフラインデータ |
| トレーニングGPU | H100-80G × 1920枚 |
| トレーニング期間 | 21日間 |
| 出力 | 入力に応じたテキスト生成 |
| 対応言語 | 英語が中心 |
Phi-4は、メモリ・計算リソースが限られた環境でローカルLLMを活用したい人におすすめです。
本記事ではローカルLLMについて解説しました。自分のPCやローカルサーバーなどのローカル環境で動かせる大規模言語モデルであり、情報セキュリティを確保しつつ、AI活用を進めたい人にとっては魅力的な選択肢です。
本記事を参考に、ぜひ自分のニーズに合った形でローカルLLMを導入してみてください。
アイスマイリーでは、生成AIサービス比較と企業一覧を無料配布しています。自社に最適な生成AIサービスの導入・運用を検討している方はぜひダウンロードしてください。
生成AI のサービス比較と企業一覧(LLM・大規模言語モデル)
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。



















FOLLOW US
SNSをフォローして、最新情報をチェックできます!










AI製品・ソリューションの掲載を
希望される企業様はこちら