

生成AI

最終更新日:2024/06/24

近年はさまざまな分野で積極的にAI(人工知能)が導入されており、少子高齢化が進む日本が抱える人手不足問題を解消するための手段として、非常に重要な役割を担っています。特に、Amazon EchoやLINE Clovaといったスマートスピーカーは、家庭でも多く使用されていることから、その注目度は高いのではないでしょうか。
これらのスマートスピーカーやチャットボットは、自然言語処理というAI技術によって成り立っています。その中でも、Googleが2018年に発表した「BERT」という手法は非常に革新的なものだったことから、大きな注目を集めたのです。
そこで今回は、Googleが誇る「BERT」の特徴について詳しくご紹介していきますので、ぜひ参考にしてみてください。
自然言語処理について詳しく知りたい方は以下の記事もご覧ください。
自然言語処理とは?できること、種類、活用事例を解説!

BERTとは、Bidirectional Encoder Representations from Transformersを略した自然言語処理モデルであり、2018年10月にGoogle社のJacob Devlin氏らが発表したことで、大きな注目を集めました。日本語では「Transformerによる双方向のエンコード表現」と訳されています。
一般的に、翻訳や文書分類、質問応答といった自然言語処理における仕事の分野を「(自然言語処理)タスク」と呼びます。BERTは、この「タスク」において2018年当時の最高スコアを叩き出したことで注目されたわけです。
BERTの特徴として、「文脈を読めるようになったこと」が挙げられます。Transformerと呼ばれるアーキテクチャ(構造)を組み込むことによって、文章を文頭・文末の双方向から学習し、文脈を読めるようになったのです。

そもそも自然言語処理とは何なのかというと、私たちが使用している言葉(自然言語)をコンピューターによって処理させる技術のことを指します。なお、自然言語と対比する言葉として挙げられるのが人工言語です。人工言語は一般的に「プログラミング言語」といわれているのですが、これら2つの言語の大きな違いとしては「曖昧性」が挙げられるでしょう。
たとえば、「黒い目の大きな猫」という言葉があったとします。この場合、「目が黒くて、大きな猫」「目の大きな、黒い猫」という2通りの解釈ができるわけです。自然言語には、こういった「曖昧性」があることが特徴といえます。
一方、「5+7=12」といった計算式などには曖昧性が存在しません。プログラミング言語は、コンピューターの制御を確実に行うためのプログラムを記述する言語であるため、自然言語のような曖昧性は一切存在していないのです。そして、こういった曖昧性のある自然言語を、機械学習や深層学習を行うAIによって処理していくことを自然言語処理と呼ぶわけです。
なお、以下の記事では、自然言語処理についてより詳しくご紹介していますので、あわせてご覧ください。
GoogleがBERTを導入した背景としては、多様化する検索クエリに対応しなければならなかったこと」が挙げられるでしょう。また、検索エンジンはもちろんのこと、コンピューターやデバイスを声で操作することができるVUI(Voice User Interface)などが普及され始めたことも、BERT導入の背景として考えられます。
たとえば、「今日の天気を調べてもらう」「メモを読んでもらう」といった自然言語の命令は、どうしても長文となって複雑化しやすい傾向にありました。そのため、文脈を正しく読めるモデルに対する需要が高まっていたのです。
また、自然言語の命令をタスクに応用させるためには、構造ごと修正しなければなりませんでしたが、BERTであれば必要はありません。容易に別のタスクに応用できるだけでなく、学習データの不足についても克服していることから、大きな注目を集めたのです。
では、Googleが発表したBERTは、どのような仕組みで成り立っているのでしょうか。ここからは、BERTの仕組みについて詳しく見ていきましょう。
そもそも自然言語処理は「分散表現」という、単語を高次元のベクトルに置き換える技術を活用することで入力される仕組みです。単語データの並びのことは「シーケンス」といい、これはいわゆる文章に該当します。
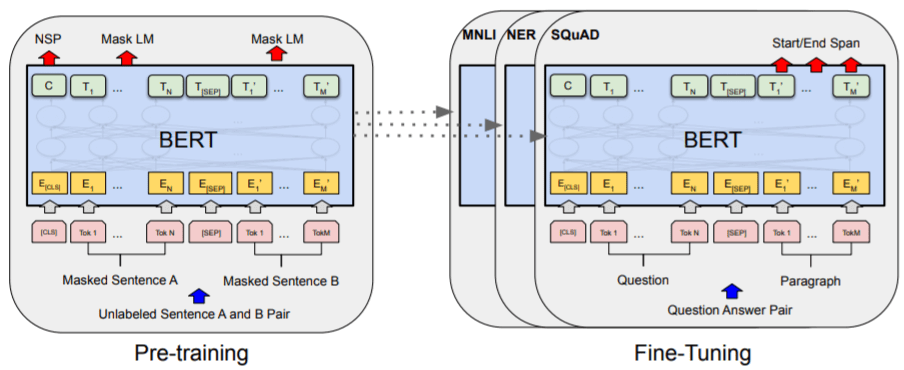 参考:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
参考:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERTは、既に入力されたシーケンスを元に別のシーケンスを予測する事前学習モデルであり、入力されたラベル(名前)が付与されていない分散表現をTransformerが処理を行い、学習していきます。実際には、TransformerがMasked Language ModelとNext Sentence Predictionという2つの手法を同時進行で進めていき、学習するという仕組みです。
このMasked Language ModelとNext Sentence Predictionについて、詳しく見ていきましょう。
BERTが発表される前に存在していた一般的な自然言語処理モデルの場合、文章を単一方向からしか処理することはできませんでした。そのため、目的とした単語の前の文章データから予測する必要があったわけです。
しかし、BERTの場合は、文頭・文末の双方向からTransformerによって学習していくため、これまでの手法よりも精度が格段に向上しています。そして、それを実現しているのがMasked Language Modelなのです。
具体的な処理の仕組みとしては、入力した文章の15%の単語を、確率的に別の単語で置き換えていくことで、文脈から置き換える前の単語を予測していくというものです。選択された15%の単語のうち、80%は[MASK]に置き換えるマスク変換となります。そして、10%をランダムな別の単語に変換し、残りの10%はそのままの単語となるわけです。このような形で置換された単語を周りの文脈から当てるタスクを解くことによって、単語に対応するための文脈情報を学習していくことになります。
Masked Language Modelの場合、単語に関する学習はできるものの、文単位の学習までは行うことができません。そのため、二つの入力された文に対して「その二つの文が隣り合っているのか」を当てるように学習します。
これによって、2つの文の関係性を学習することができるのです。Next Sentence Predictionによって、BERTは「文章も考慮した広範的な自然言語処理モデル」として機能することが可能になるのです。
Next Sentence Predictionの具体的な仕組みとしては、片方の文を50%の確率で他の文に置き換えた上で、それらの文が隣り合っているのか、それとも隣り合っていないのかを判別し、学習するというものです。
では、実際にBERTが導入されたことによって、どのようなことが実現されるようになったのでしょうか。BERTの特徴を詳しく見ていきましょう。
BERTが発表されるまでは、主にELMo、OpenAI GPTといった言語処理モデルが活用されていました。ELMoは双方向モデルであり、OpenAI GPTは未来の単語のみを予測する単一方向モデルです。そのため、文脈を読むことまでは不可能でした。
また、BERTが導入される前のGoogle検索では、「to」のような「文と文の関係を結ぶ言葉」を処理することはできなかったといいます。Googleが紹介している一例を見てみましょう。
・検索ワード:「2019 brazil traveler to usa need a visa(2019年 アメリカへのブラジル旅行者はビザが必要)」
上記のような検索ワードの場合、検索者が知りたいのは「ブラジルからの旅行者はアメリカに行く際にビザが必要なのか」であることがわかります。しかし、BERTが導入される前は「to」を処理できないため、「ブラジルへのアメリカ人旅行者」と解釈してしまうこともあり、ニーズとは一致しない検索結果まで表示されてしまうことがあったのです。
しかし、BERTが導入されてからは、「アメリカへのブラジル人旅行者」と正しく解釈できるようになったため、「アメリカ大使館がブラジル人旅行者向けに公開しているビザ情報のページ」がしっかりと上位に表示されるようになりました。
BERTには、汎用性が高いという特徴もあります。これまでのタスク処理モデルの場合、特定のタスクだけに対応していました。しかし、BERTであれば、モデルの構造を修正することなく、さまざまなタスクに応用させることが可能です。
既存のタスク処理モデルの前に接続(転移学習)させるだけで、簡単に自然言語処理の精度を高められるようになりました。
これまで存在していたモデルとは異なり、BERTは「ラベルが付与されていないデータセット」でも処理することができます。現在、自然言語処理タスクを目的とした「ラベルが付与されたデータセット」は少ないため、入手が困難な状況です。
また、ラベルを付与するためには時間と労力もかかります。その点、現代では、ラベルが付与されていないデータが大量に存在するため、獲得も容易です。そのため、BERTは「データが少なくても始められる」という点で評価されています。
rinna株式会社は、製品開発のための実験過程で、日本語に特化したGPT-2とBERTの事前学習モデルを開発しました。日本語の自然言語処理(NLP)の研究・開発コミュニティに貢献するために、開発した事前学習モデルとその学習を再現するためのソースコードを、GitHubおよびNLPモデルライブラリHuggingFaceにMITライセンスのオープンソースとして公開します。
rinna社は、2021年4月に日本語に特化した中規模サイズのGPT-2(GPT2-medium)を公開し、反響を呼びました。そして今回、モデルサイズが異なる2つのGPT-2(GPT2-small, GPT2-xsmall)を公開。モデルサイズの違いはパフォーマンスとコストのトレードオフであり、研究者や開発者が最善のモデル選択をすることが可能となります。また、GPT2-mediumも、学習データと学習時間を増やし、より高性能なモデルへとアップデートされています。
さらに、GPT-2に加え、BERTを改良したモデルであるRoBERTaも公開。 GPT-2とBERTの公開により利用者は目的に合わせたモデル選択や、追加学習により多様なタスクへの応用が可能となります。
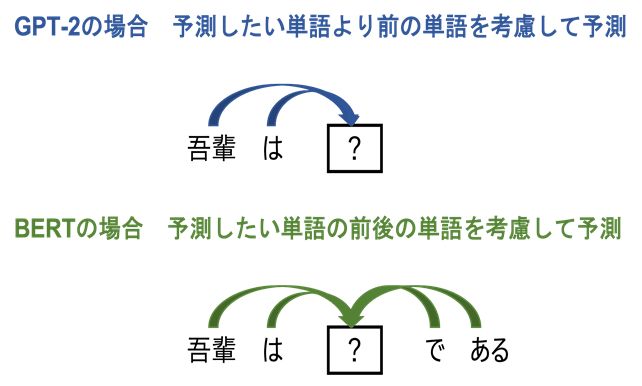
言語モデルは、会話や文章の「人間が使う言葉」を確率としてモデル化したものです。優れた言語モデルとは、確率を正確に推定できるものを指します。たとえば、 “確率(吾輩は猫である)>確率(吾輩が猫である)” と推定できるのが、言語モデルの能力です。
GPT-2は、単語の確率の組み合わせから文の確率を計算する言語モデルです。たとえば、“確率(吾輩は猫である)=確率(吾輩)×確率(は|吾輩)×確率(猫|吾輩,は)×確率(で|吾輩,は,猫)×確率(ある|吾輩,は,猫,で)” のような方法で推定を行います。この性質を用いて、GPT-2は「吾輩は」という単語を入力したとき、次にくる単語として確率が高い「猫」を予測することができます。
今回、rinna社が公開した日本語GPT-2は、一般的な日本語テキストの特徴を有した高度な日本語文章を自動生成できます。例として、「本日はご参加ありがとうございました。誰も到達していない人工知能の高みへ、ともに」という講演後のメールを想定した文章をGPT-2に入力として続きの文章を自動生成すると、入力文章の文脈を考慮した文章が生成されます。
さまざまな特徴、魅力が存在するBERTですが、実際にどのような場所で活用されているのでしょうか。ここからは、BERTの活用事例について見ていきましょう。
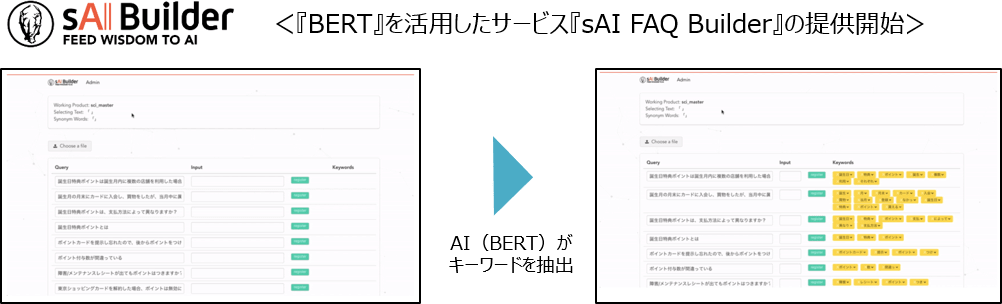 参考:自然言語処理AI「BERT」を国内初の製品化 サイシード「sAI FAQ Builder」
参考:自然言語処理AI「BERT」を国内初の製品化 サイシード「sAI FAQ Builder」
国内で初めてBERTを活用し、製品化された事例として、サイシードによるFAQデータ作成サービス「sAI FAQ builder」があります。「sAI FAQ builder」とは、AIの活用によって「ユーザーの疑問に関連しそうなタグ」が提示されるというサービスです。
提示されたタグの中から、自身の疑問と関連性のあるタグを直感的に選ぶことにより、目的とする疑問の回答にたどり着くことができます。検索時に必要となるタグの付与も自動化され、FAQデータをアップロードすると自動でタグの付与が行われる仕組みです。

BERTは、チャットボットでも活用されています。株式会社ユーザーローカルが提供している「サポートチャットボット」という自動応答システムでは、BERTの導入によって、チャットボット構築を自動化することが実現可能になりました。
一般的に、チャットボットが回答を自動化するためには、質問に対する回答のロジックの設定などを行わなければなりません。そのため、システムを稼働させるまでに多くの時間が必要だったのです。
しかし、BERTの活用によって、問い合わせ履歴をもとに構築していくことで、構築期間の圧縮や工数の削減が可能になります。なお、この「サポートチャットボット」を利用する場合には、導入先企業はプログラムの記述などの必要なく、システムを利用することができます。
最近では、広告出稿においてもBERTが活用され始めています。たとえば、飲食業界の場合、リスティング広告や媒体系広告など、さまざまな形式と価格帯の広告が存在します。
これらに適切な広告費用を投入することは決して簡単ではありません。しかし、BERTを搭載したAIを活用すれば、最適な出稿パターンを予測したり、予算配分を最適化したりすることが可能になるのです。
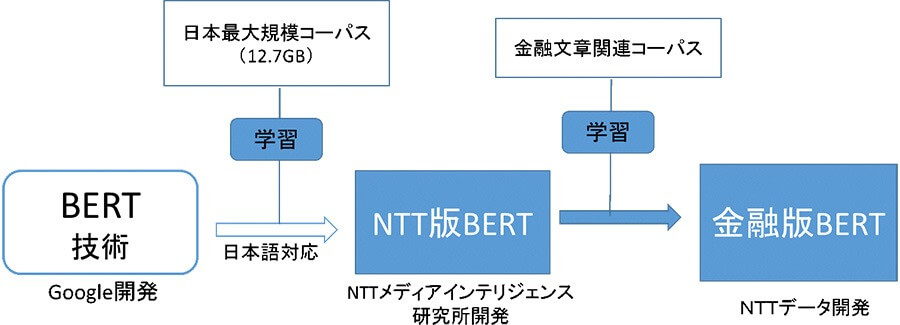 参考:金融業界向け自然言語処理技術の検証開始 | NTTデータ
参考:金融業界向け自然言語処理技術の検証開始 | NTTデータ
近年は、「金融版BERT」という金融文書に特化したBERTの開発も進んでいます。これは、NTT研究所が開発したNTT版BERTをもとに、NTTデータが収集した金融関連文書を学習させたモデルです。
「金融版BERT」は、金融に関連する文書の処理において、高い単語予測精度を実現します。また、チャットボットを活用した問い合わせ対応や、日報からの情報抽出など、幅広い業務への展開が予定されており、期待度が高まっています。
今回は、Googleが誇る自然言語処理モデルの「BERT」についてご紹介しました。すでにさまざまな分野で活用されており、今後の展開にも期待が集まる存在であることがお分かりいただけたのではないでしょうか。
多くの企業が人手不足に陥る現代において、AIによる業務効率化は欠かせません。そのような中で、BERTがどのように価値を発揮していくのか、ますます期待が膨らみます。
AIソリューションについて詳しく知りたい方は以下の記事もご覧ください。
AIソリューションの種類と事例を一覧に比較・紹介!
AIについて詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
BERTとは、Bidirectional Encoder Representations from Transformersを略した自然言語処理モデルであり、2018年10月にGoogle社のJacob Devlin氏らが発表したことで、大きな注目を集めました。日本語では「Transformerによる双方向のエンコード表現」と訳されています。
BERTの特徴として、以下が挙げられます。
BERTの活用事例として、以下が挙げられます。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!







AI製品・ソリューションの掲載を
希望される企業様はこちら