

生成AI

最終更新日:2024/02/27
 オートエンコーダの役割と必要性
オートエンコーダの役割と必要性
オートエンコーダは、AI(人工知能)技術でも使われているニューラルネットワークの1つで、現在広く知られるようになったディープラーニング(深層学習)にも採用されています。AIシステムの発展において重要な役割を果たした画期的な技術です。
この記事では、オートエンコーダの意味から仕組み、活用方法まで詳しく解説します。AIを使ったサービス開発を検討する際に、知っておきたい知識をまとめていますので、ぜひお役立てください。
ディープラーニングについて詳しく知りたい方は以下の記事もご覧ください。
ディープラーニングとは?仕組みやできること、実用例をわかりやすく紹介
まず、オートエンコーダの定義や意味について解説します。AI技術の発展に大きく貢献したとされる画期的手法「オートエンコーダ」とはどういったものなのか理解しておきましょう。
オートエンコーダ(AutoEncoder)とは、日本語で「自己符号化器」と呼ばれるニューラルネットワークの1つです。2006年に、カナダのコンピュータ科学及び認知心理学研究者のジェフリー・ヒントン氏らによって提唱されました。
オートエンコーダには、教師なし学習と呼ばれる機械学習方法を用いるのが一般的です。もとは、次元削減や特徴抽出といった小さい次元に落とし込む作業を効率的に行うために開発されましたが、近年はデータ生成や異常検知などの用途でも用いられています。
オートエンコードがどのように機能するのか、仕組みを見ていきましょう。オートエンコーダは、入力層・中間層・出力層というノードと、それらを結ぶエッジが作る多層で構成されています。
まず、データを受け取るのは入力層のノードです。入力データが中間層で圧縮される際、データの重要度にあわせて点数がつけられ(重みづけ)、点数が低いデータは除外(エンコード)されます。次のステップでは、出力層に移る時も重み付けが行われ、複数のエッジから受け取ったデータの合計が最終的な値として出力(デコード)される流れです。
オートエンコーダでは、基本的に入力データと一致するデータを出力させることを目的としています。一般的なオートエンコードでは、入力データを圧縮したい次元数のニューロンを中間層に用意し、出力層では入力データを再現する出力値を出すことが可能です。

ここで、オートエンコーダを理解する上で欠かせない「ニューラルネットワーク」について解説します。AI技術の中核と言っても過言ではないニューラルネットワークについて理解しておきましょう。
ニューラルネットワークとは、人間の脳神経細胞(ニューロン)のネットワーク構造を模した数学モデルのことです。互いに接続した複数のノードによる多層で構築されています。
ニューラルネットワークでは、膨大な量の正解データを学習させることで、人間の脳と同じように音声や画像のパターンを認識可能です。ただ、生物学的脳とは異なり、ネットワーク内の要素の接続方法や接続強度、重みなどの条件によってデータの伝達方法は定義され、定義以外の伝達はできません。
データから学習するという特性を活かて、ニューラルネットワークはパターン認識やデータ分類、時系列データを基にした未来予測といった用途で活用されています。
ニューラルネットワークの歴史は80年以上に上ります。オートエンコーダについて理解を深めるために、ここではニューラルネットワークがどのように登場し、発展、進化してきたのか、変遷の歴史を見ていきましょう。
1943年に人間の脳神経を模範としたモデルが提唱されたのが、ニューラルネットワークの始まりです。1957年、「パーセプトロン」と呼ばれるニューラルネットワークが登場し、AIブームを巻き起こしました。ただ、複雑な問題を解くことが難しく、実用性に欠けるという課題が残ります。
1986年、誤差逆伝播法の開発とともにパーセプトロンから進化した「マルチレイヤーパーセプトロン」が用いられます。マルチレイヤーパーセプトロンでは複雑な学習も可能となり、画期的な技術として注目を集めましたが、利用可能なデータが少なく、学習精度が向上しない時期が続きました。
その後、再びAIブームをもたらすきっかけとなったのが、2006年のオートエンコーダ技術です。オートエンコーダとマルチニューラルネットワークを用いる学習方法は「ディープラーニング」と呼ばれ、昨今のAI技術の発展と浸透を大きく支えています。

オートエンコーダが重要視される背景には、多層で構成されるニューラルネットワークを正常かつ効率的に機能させるために解決すべき課題がありました。ここでは、オートエンコーダの役割と必要性について、2つの観点から見ていきましょう。
オートエンコーダは、勾配消失を解決することを目的として開発されました。ニューラルネットワークでは層を重ねることにより、複雑な処理を実行しています。ただし、予測と正解の誤差を利用して学習する誤差逆伝播法では、層が増えるとともに、誤差は少なくなるため、層が多すぎると逆に精度が落ちてしまうのです。これを勾配消失と呼びます。
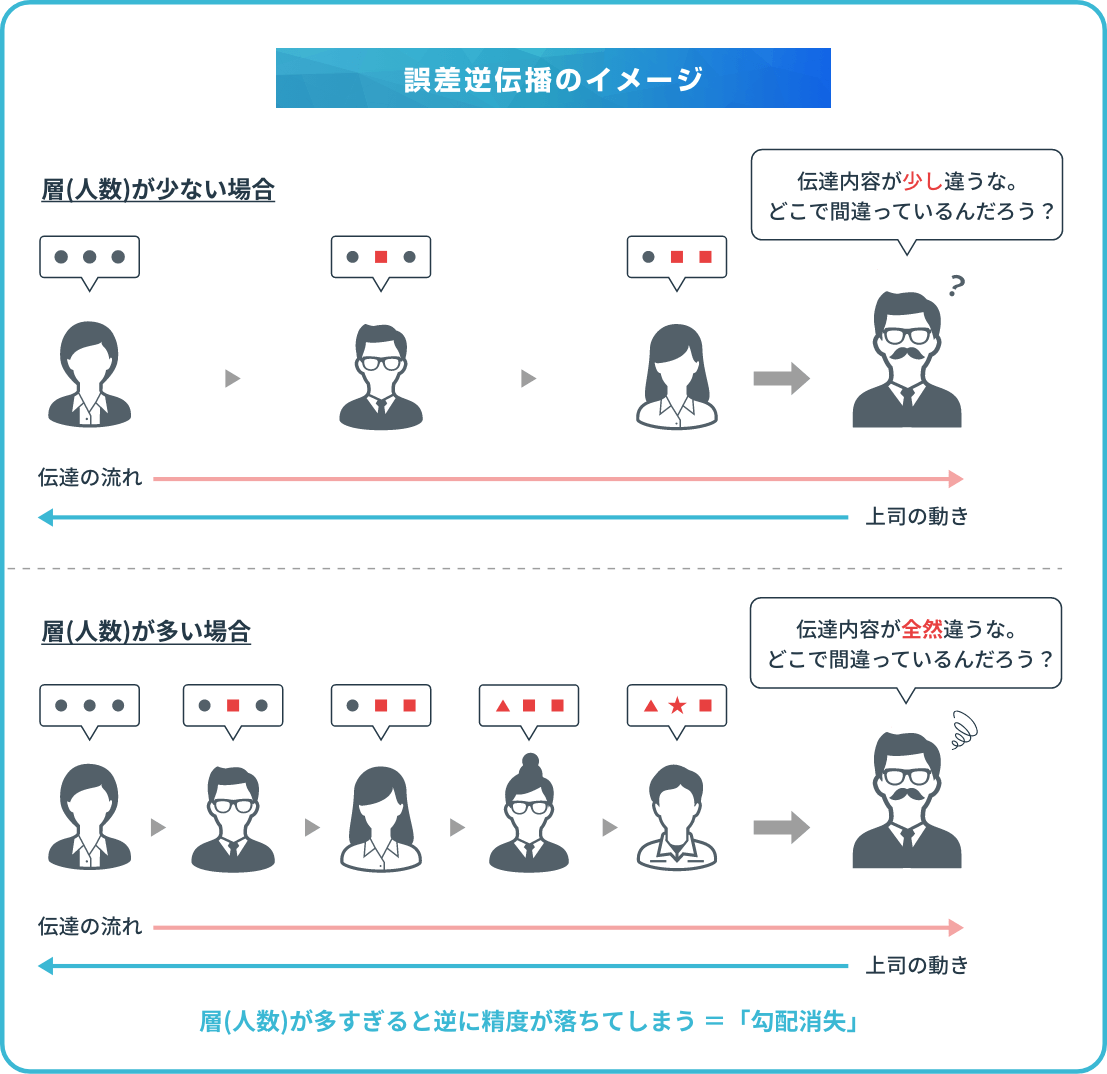
そこでオートエンコーダで学習させたものを、ニューラルネットワークの初期値として用いて事前学習を行うことで、勾配消失による学習速度低下を防止することが可能です。
勾配消失を解消する手順としては、まず多層構造を複数の単層に分割して、それぞれに事前学習を行います。続いて、分割前の構造を想定して入力層から順に教師なし学習を実行した後、中間層と同じサイズの訓練用隠れ層を1つ用意したら、圧縮・出力させる訓練を実施。この作業をすべての層で繰り返し、学習させた層で元のネットワークを構築します。ここで新しい層を追加し、学習させることで勾配消失を防止できるのです。
過学習は、特定のデータに適合しすぎて、評価データに対応できなくなる状況です。訓練データを完全に記憶してしまうことで、学習データだけに最適する状態が生まれます。その結果、汎用性が失われ、未知のデータを扱う実際の技術としては使用できません。
解決策として、適切な良いタイミングで学習を止める、学習データ数を増やすといった対策法の他に、オートエンコーダが役立ちます。オートエンコーダでは入力値の次元を圧縮し、復元する処理を行うため、圧縮された荒いデータは過学習を予防することが可能です。
オートエンコーダが登場して以来、さまざまな形式へと進化しています。ここでは、オートエンコーダの主な4つの種類について解説するので、それぞれの特徴や違いを理解していきましょう。
積層オートエンコーダ(Stacked Autoencoder)とは、オートエンコーダを何層にも重ねた多層構造を持つものです。中間層を次の入力層とし、1層ずつエンコードとデコードを交互に実施して学習しながら、初期値を最適解に近づけていきます。最後に1層目からすべてつなげて元々のネットワークを再構築し、得られた重みを初期値として設定、全体を通して重みを微調整(ファインチューニング)する流れです。
この方法では、多層化によってより複雑で高度な特徴量抽出を実現しています。現在はニューラルネットワーク技術の発展により、積層オートエンコーダのメリットをカバーできる他の種類がメジャーとなってきたため、現在は出番が少なめです。
変分オートエンコーダ(Variational Autoencoder/VAE)とは、オートエンコーダのデコーダに変数を混ぜて、入力とは異なる出力を行うものです。生成モデルとしても知られています。データの圧縮と復元に加えて、入力データを圧縮して得られる特徴ベクトル(潜在変数)を、確率変数として表すことが可能です。
従来のオートエンコーダでは、次元削減後の特徴ベクトルには制約はなく、空間上でデータがどのように表現されているかはわかりませんでした。そこで変分オートエンコーダでは、正規分布という制約を設けてデータの潜在空間上での分布に連続性を持たせています。よって、似た潜在変数から似たデータを生成することが可能です。
畳み込みオートエンコーダ(Convolutional Autoencoder/CAE)は、エンコーダ、デコーダ部分の全結合層の代わりに、畳み込みニューラルネットワーク(CNN)を用いたオートエンコーダです。畳み込みニューラルネットワークは、入力層と出力層の間に入力データの特徴を捉える「畳み込み層」と、特徴への依存性を軽減する「プーリング層」を加えたニューラルネットワークモデルを指します。
畳み込み層によって、エッジやテクスチャなど空間的な特徴まで抽出できるようになりました。畳み込みニューラルネットワークは、画像の処理に多く利用されています。
条件付き変分オートエンコーダ(Conditional Variational Autoencoder/CVAE)とは、先述の変分オートエンコーダを拡張したものです。変分オートエンコーダでは、潜在変数を変えると出力クラスも変わってしまう可能性がありました。そこで条件付き変分オートエンコーダでは、エンコーダ、デコーダともにラベル情報を入力することで、出力クラスを指定できる上、潜在変数も自由に調整可能です。
ラベルの入力方法は、デコーダで1次元の潜在変数ベクトルに結合する方法や、足し合わせる方法などがあります。ラベル情報を学習に含めることで、学習後に指定したラベルのデータを生成することも可能です。

ここからは、オートエンコーダの活用事例を紹介します。多彩な種類が存在するオートエンコーダが、どのようなシーンや用途で活用できるのか見ていきましょう。
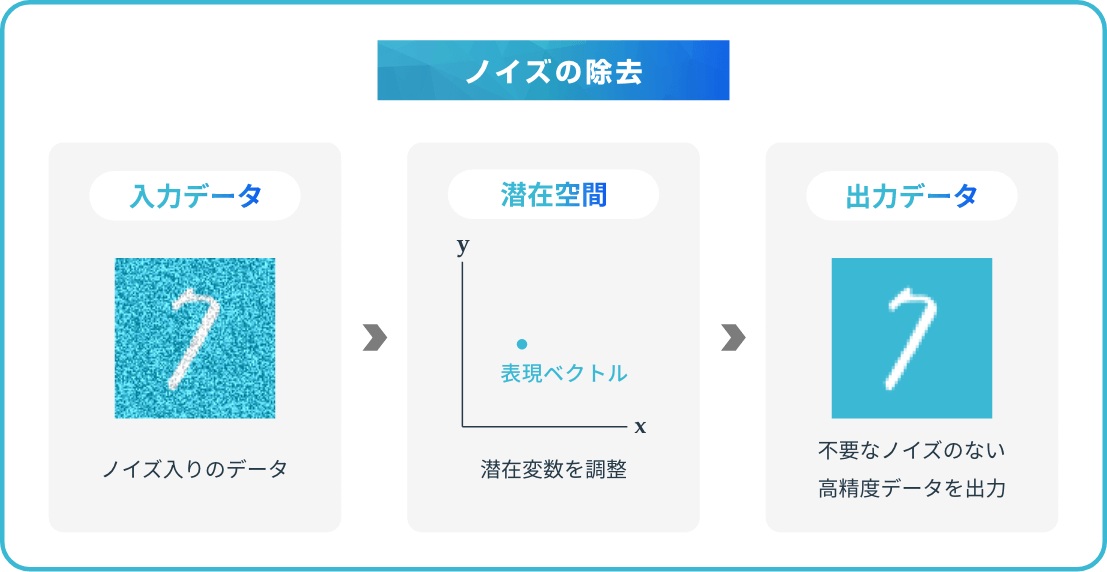
入力データの不必要な部分を除去する「ノイズ除去(デノイジングオートエンコーダ)」は、オートエンコーダによって実現している技術の1つです。最初にノイズ入りのデータをオートエンコーダに入力し、ノイズを除いたデータを正解データとして教師あり学習を実行します。学習後にデータを入力することで、不要なノイズのない高精度データを出力することが可能です。
オートエンコーダによってノイズ除去された出力データは、他の機械学習方法にも活用できます。ノイズのないデータは、特に分類精度を高める上で必須です。
「クラスタリング(分類)」とは、名前の通り特徴によってデータを分類することです。オートエンコーダのエンコード部分が持つ特徴抽出の機能を用いることで、入力値を特徴ごとにグループ分け(クラスタリング)できます。
クラスタリングに使われるのは、正解データのラベルを付けない教師なし学習です。先述した変分オートエンコーダにより、正解と不正解それぞれの特徴を備えたものに分けられます。また、不正解に複数のパターンがあるケースでは、対応する数分のグループが作られるので、正解とどのように異なるかという情報まで判別することが可能です。
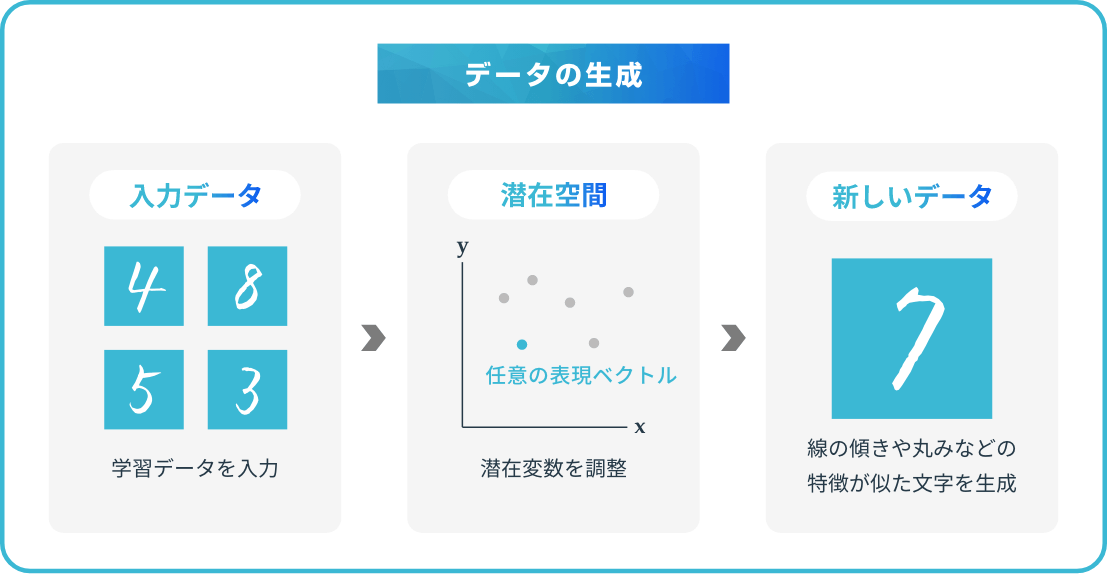
オートエンコーダは、学習データを入力すると、まだ存在しないデータを出力する「データの生成」にも採用されています。条件付き変分オートエンコーダのような生成モデルを使って潜在変数を調整し、学習データのいずれとも合致しない新たなデータ生成することが可能です。
例えば、誰かが書いた数字の画像を入力すると、他の人が書いたかのような新しい画像を生成できます。この場合、入力データの潜在変数を使うため、クラスによらず線の傾きや丸みなどの特徴が似た文字が作られるでしょう。
「異常検知」とは、入力データが正常か異常かを判断して、異常を検知する処理のことです。正常データのみを必要とする教師なし学習をオートエンコーダに実行させることで、正常データに含まれる特徴を学習し、正確に復元します。
ソニービズがリリースした異常検知機能は、オートエンコーダによる教師なし学習を活用した事例です。自社のAI画像判定ソリューションに、正常品の画像を学習させるだけで不良品を判別するAI機能が備わっており、不良品の判断理由を含めて特定できると期待されています。
詳しくはこちらの記事をご覧ください。

オートエンコーダは、AI技術をサポートするニューラルネットワークの1つとして重要な役割を担っています。従来のニューラルネットワークにおける勾配消失や過学習といった課題を解消するために開発されたものの、現在はデータ生成や異常検知といった用途でも利用されており、さらなるニーズの拡大が見込まれるでしょう。
オートエンコーダによるデータの次元削減や圧縮という働きは、ディープラーニングやAI技術において欠かせない知識です。この機会に理解を深め、自社に最適なAIシステムの研究開発に活用していきましょう。
機械学習について詳しく知りたい方は以下の記事もご覧ください。
機械学習とは何か?種類や仕組みをわかりやすく簡単に説明
AIについて詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。

















FOLLOW US
SNSをフォローして、最新情報をチェックできます!








AI製品・ソリューションの掲載を
希望される企業様はこちら