

生成AI

最終更新日:2026/05/29
 ランダムフォレストについて解説
ランダムフォレストについて解説
ランダムフォレストは、主に分類(判別)や回帰といった目的で活用されているアルゴリズムの1つです。精度が高い点が特徴で、機械学習において必修とされていますが、詳しく知らない人もいるのではないでしょうか。
この記事では、ランダムフォレストの仕組みやメリット・デメリット、活用事例について紹介します。AI技術による機械学習を活用したシステム開発や研究を検討している方は、ぜひ参考にしてください。
機械学習について詳しく知りたい方は以下の記事もご覧ください。
アンサンブル学習について詳しく知りたい方は以下の記事もご覧ください。
アンサンブル学習とは?スタッキングやブースティングの手法も解説
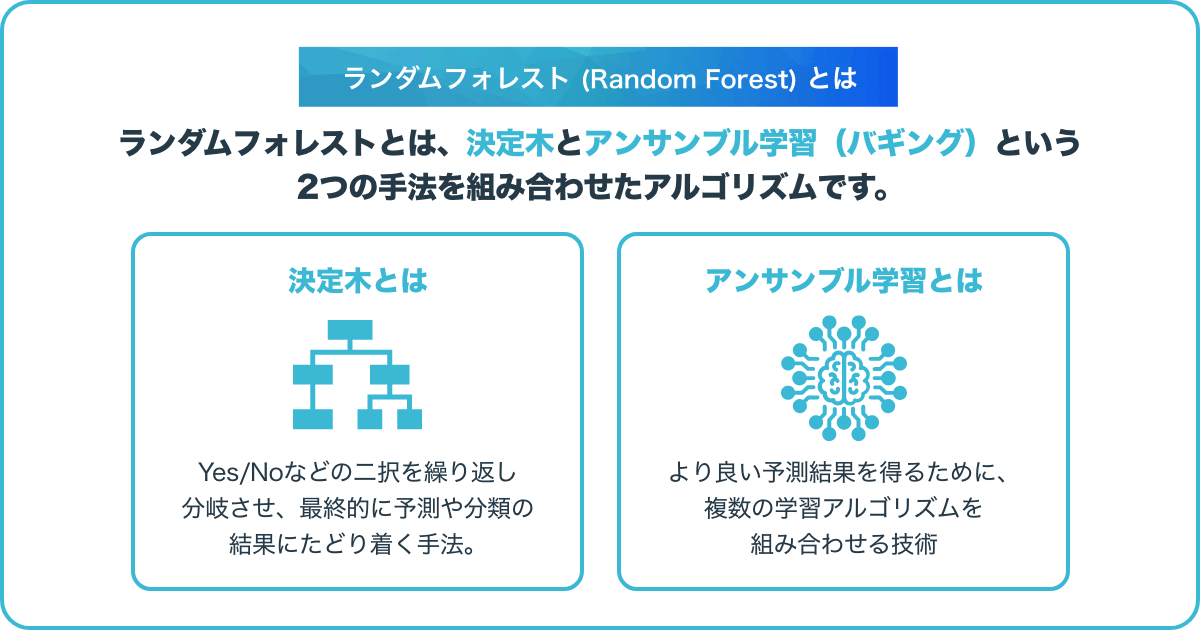
ランダムフォレスト(Random Forest)とは、「決定木」と「アンサンブル学習(バギング)」という2つの手法を組み合わせたアルゴリズムです。機械学習の「分類」「回帰」といった用途で用いられます。
「決定木」単体で使うよりも高い精度を出せる点が特徴です。なお、ランダムフォレストをさらに多層化したアルゴリズムは「ディープ・フォレスト(Deep Forest)」と呼ばれます。
「決定木」とは、「予測」「判別」「分類」といった目的で用いられる手法です。Yes/Noなど二者択一の質問を階層構造的につなげて、1つずつ答えていくことで最終的に正解にたどり着ける仕組みを持ちます。この階層構造が木の枝のように見えることから、「決定木」という名前が付きました。
ランダムフォレストでは、多数の決定木を集めて、組み合わせることで精度を高めています。決定木を集める方法が、次に説明する「アンサンブル学習」です。
ランダムフォレストで重要な要素のもう1つ「アンサンブル学習」とは、より良い予測結果を得るために、複数の学習アルゴリズムを組み合わせる技術です。ウク数の単一モデルを用いて強力なモデルを構築するため、高精度な結果が期待できます。
「分類」の場合は複数の学習器の多数決で決まり、「回帰」では複数の学習器の平均を取るのが一般的です。アンサンブル学習においてよく用いられる手法には「バギング」と「ブースティング」の2種類があります。
「バギング(Bagging)」とは、「ブートストラップ(Bootstrap Aggregating)」というテクニックを用いて、複数のモデルを並列的に学習させる手法です。ブートストラップは、元データから一部のデータを復元抽出してサンプリングします。
複製されたデータセットごとに学習器を生成し、それらを使って「分類」であれば多数決を、「回帰」であれば平均を出して最終的な予測を行う仕組みです。ランダムフォレストは、バギングをベースに、異なる決定木を多数集めたものを指します。
ブースティングとは、複数のモデルを使い、学習を直列的に進めていく手法です。バギングのように学習器を複製するのではなく、前に作ったモデルの結果を参考に次のモデルを構築する、というフローを続けます。
1つずつ順番に学習器を生成するため、バギングよりも時間を要しますが、バギングに比べて高い精度が期待できるでしょう。
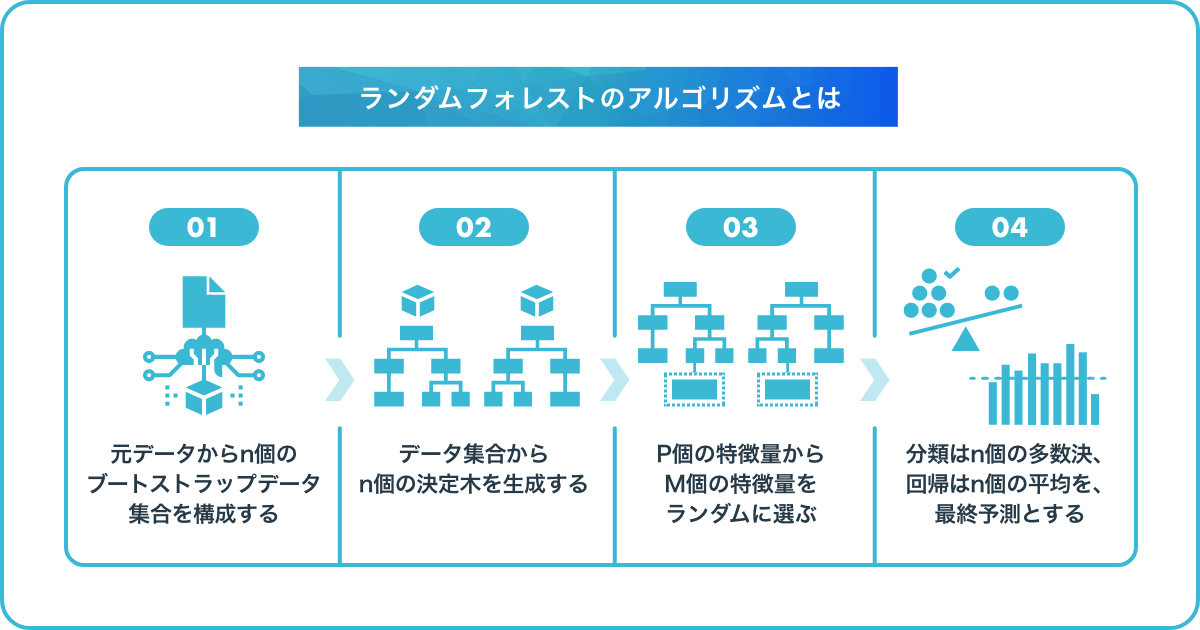
ランダムフォレストを理解する上で必須となる用語を押さえたところで、ランダムフォレストのアルゴリズムについて見ていきましょう。
ランダムフォレストのおおまかなアルゴリズムは、以下の通りです。
アンサンブル学習では、モデル間の相関が低いほど予測値の精度が高まるため、3つ目のステップでは一部の特徴量しか使用しません。それぞれ異なる方向に過学習している決定木を集めて、その結果の平均を取れば過学習の度合いを減らせる、という考え方を採用しています。
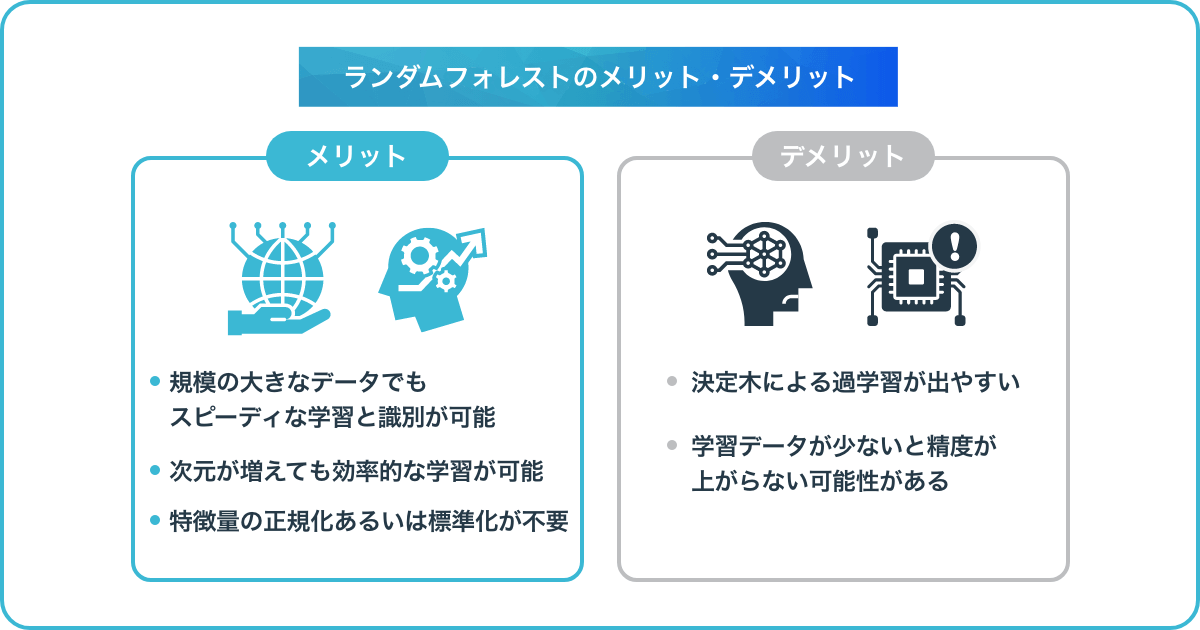
ここで、ランダムフォレストのメリット・デメリットをまとめます。
【メリット】
・規模の大きなデータでもスピーディな学習と識別が可能
・次元が増えても効率的な学習が可能
・特徴量の正規化あるいは標準化が不要
【デメリット】
・決定木による過学習が出やすい
・学習データが少ないと精度が上がらない可能性がある

ランダムフォレストの代表的な活用シーンに、商品やサービスのマーケティングが挙げられます。例えば、来店者のうち、特定の条件を満たした優良顧客を絞り込む目的で、ランダムフォレストを応用することが可能です。
「1回の買い物で3万円以上購入する優良顧客を増やす」という目標を決めたとします。一般的には店舗スタッフが条件に合う人を自分で探し出す必要があり、時間がかかってしまうでしょう。
そこで、ランダムフォレストを用いて、スタッフとの会話の有無や滞在時間といった決定木を使い、来店客を仕分けすることで効率よく該当する顧客を見つけることが可能です。
また、Webサイト上でのアクセス履歴や登録属性を用いるデジタルマーケティングでも、ランダムフォレストが役立ちます。再訪したユーザーには閲覧履歴に近い商品を推奨する、初回限定の割引オファーをポップアップ画面で表示する、といった使い方が可能です。
ここで、ランダムフォレストを実際に活用した事例を紹介します。関西デジタルソフト株式会社は、ランダムフォレストを用いた「毒キノコ検知システムを開発した」と発表しました。
キノコの傘の形や色、表面、ひだの色、匂いなどいくつかの質問に答えると、AIが食べられるキノコかどうかを自動判断できるシステムです。例えば、傘が平らな形をしていて色は茶色、臭いがない場合は「食べても問題ない」、傘が赤色で刺激的な臭いがするものは「毒キノコの可能性が高い」、といった結果を出します。
従来では、新システムの導入には新しいハードウェアが必要でしたが、このシステムは既存PCでも動作可能です。数千種類とされる膨大なキノコに継続的にデータを学習させることで判別精度が上がり、実用性がさらに高まるでしょう。
ランダムフォレストは、Pythonのライブラリである「Scikit-learn」を使って実装することが可能です。ここでは、ランダムフォレストをPythonで実装するための事前準備について解説します。
まずはじめに「Scikit-learn(サイキット・ラーン)」をインストールします。Scikit-learnとは、Pythonの機械学習モデル用ライブラリの1つです。オープンソースで公開されており、個人・商用問わず利用できる上、付属のサンプルデータセットを活用しながら機械学習をすぐに始められます。
Scikit-learnは、Pythonのパッケージ管理ツール(pip)でインストールが可能です。下記コマンドを実行するとインストールできます。
pip install scikit-learn
Scikit-learnのランダムフォレスト用クラスは2つあるので、それぞれの特徴を理解し、適切に使い分けましょう。
1つ目のクラス「RandomForestClassifier」は、分類のためのクラスです。AかB、YesかNoなど二者択一の判別を用いる機械学習で使われます。もう1つの「RandomForestRegressor」は、回帰用のクラスです。数値予測の機械学習などで利用されます。

ランダムフォレストは、決定木とアンサンブル学習を組み合わせて、機械学習の分類や回帰を実行するアルゴリズムです。適切な特徴量をより多く盛り込むことができれば、高精度かつ効果的なデータを得られます。
データの規模や次元が増えても迅速な識別が可能なため、マーケティング分野において多く採用されており、Pythonのライブラリで実装できる点も特徴です。データの識別や数値予測に、ランダムフォレストを活用しましょう。
AIについて詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
機械学習について詳しく知りたい方は以下の記事もご覧ください。
機械学習とは?種類や仕組み、活用事例をわかりやすく簡単に説明
AIについて詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
ランダムフォレスト(Random Forest)とは、「決定木」と「アンサンブル学習(バギング)」という2つの手法を組み合わせたアルゴリズムです。 機械学習の「分類」「回帰」といった用途で用いられます。 「決定木」単体で使うよりも高い精度を出せる点が特徴です。
「決定木」とは、「予測」「判別」「分類」といった目的で用いられる手法で、Yes/Noなど二者択一の質問を階層構造的につなげて、1つずつ答えていくことで最終的に正解にたどり着ける仕組みを持ちます。一方で、ランダムフォレストでは、多数の決定木を集めて、組み合わせることで精度を高めています。
ランダムフォレストのメリットは、規模の大きなデータでもスピーディな学習と識別が可能 で、次元が増えても効率的な学習が可能で、特徴量の正規化あるいは標準化が不要なことです。
ランダムフォレストのデメリットは、決定木による過学習が出やすい ことや、学習データが少ないと精度が上がらない可能性があることです。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。













FOLLOW US
SNSをフォローして、最新情報をチェックできます!










AI製品・ソリューションの掲載を
希望される企業様はこちら