

個人情報抽出用のデータセット・AIモデル・ソースコードが無償公開
最終更新日:2024/02/14
 個人情報抽出用データセット公開
個人情報抽出用データセット公開
Nishikaが、文中から個人情報を機械学習により自動で抽出するためのデータセット・高精度AIモデル・ソースコードの提供を開始しました。
このAIニュースのポイント
- Nishikaが文中から個人情報を自動抽出するためのデータセット・AIモデル・ソースコードを公開
- 個人情報に相当する文言を人名・組織名・地名などの種類別に抽出できる
- 無償公開により、日本語における自然言語処理技術のさらなる発展を期待
Nishikaは、文章の中から氏名や組織名、地名などの個人情報を機械学習により自動で抽出するためのデータセット・高精度AIモデル(学習済みモデル)・ソースコードの提供を開始しました。公開期間は2022年10月31日までです。

Nishikaは2021年1月に、判例文の中から個人情報に相当する文言を、人名・組織名・地名など種類別に抽出することを目的としたAI開発コンペティションを開催。同コンペティションでは個人情報の抽出精度を200名以上の参加者が競い合いました。最終的に1位となったAIモデルは、人名では91.4%、組織名・施設名は81.4%の高精度での個人情報抽出を実現しています。
適切な個人情報管理の重要性は年々増しており、様々な文章の中から個人情報の有無を把握することや、正確に抽出することが必要な場面も増えています。このようなタスクには、AI・機械学習の活用による作業効率化が最適です。一方で、個人情報などの固有表現抽出を行うAI開発に一般利用できるデータセットは限られています。
そこでNishikaは、日本語における自然言語処理技術のさらなる発展のためにコンペティションで用いた日本語個人情報抽出向けデータセット、優勝モデルおよびそのソースコードの公開を決めました。同社は、学術領域に限らず民間における研究・プロダクト開発にも広く利用されることを期待しています。
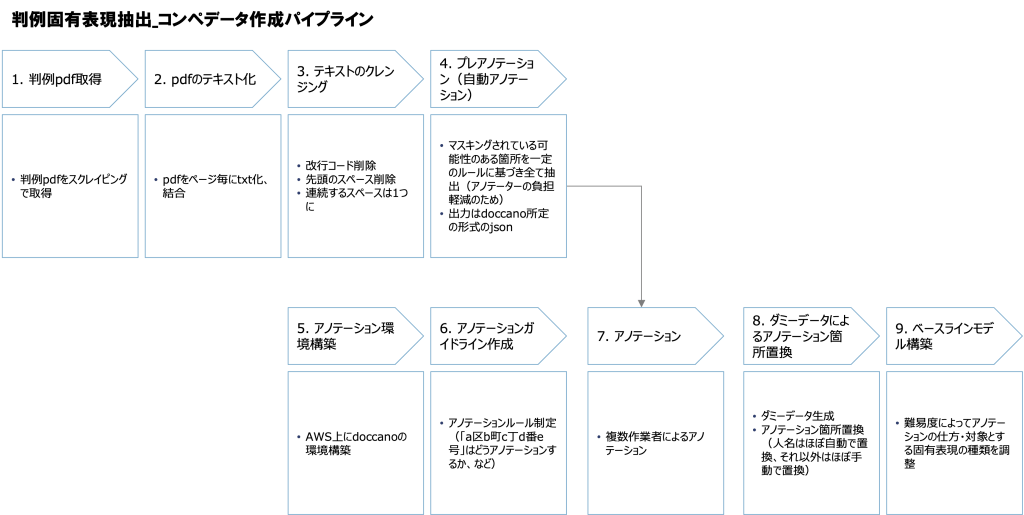
データセットには、約200の判例文に27,000超の個人情報(人名、組織名・施設名・役職名、地名、時間、その他商品名等)へのラベルが付与されています。Nishikaが収集した判例文のpdfデータをテキスト化し、クレンジング後にテキストアノテーションツールdoccanoを用いて原文のマスキング箇所に対してアノテーションを実施。その後、架空の名称でアノテーション箇所を置換することで、これらのデータが作成されています。アノテーションは、人名、組織名・施設名・役職名、地名、時間、その他の5種類です。
AIモデル・ソースコードには、Nishikaが過去に開催したAI開発コンペティションにて、1位を獲得したモデルが使われています。個人情報の抽出を91.4%の精度で抽出可能であり、特に人名は94.5%、組織名・施設名は81.4%の高精度で抽出可能です。
精度の高いデータセット、AIモデル・ソースコードを商用利用したい方は、ぜひサービスを利用してみてはいかがでしょうか。公開期間は2022年10月31日までです。
出典:PR TIMES
- AIサービス
- 自然言語処理-NLP-
- AIモデル作成
- アノテーション
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
チャットボット

AI-OCR

フィジカルAI

生成AI
チャットボット
AI-OCR
フィジカルAI








FOLLOW US
SNSをフォローして、最新情報をチェックできます!

PKSHA InfinityのAI議事録作成ツール「YOMEL」…

NECとJR東日本、「みどりの窓口AI対応サービス」の実現に向け…

2026年上半期トレンドワードランキングをPR TIMESが公開…

OpenAI、グローバルパートナープログラム「OpenAI Pa…

Anthropic、米政府の輸出規制解除により「Fable 5」と「Mythos 5」の提供を再開

Anthropic、新モデル「Claude Sonnet 5」発表。「Opus 4.8」に迫る性能を低価格で実現

アイスマイリー、7/8(水)から3日間「バックオフィス World 2026 夏 東京」に出展 ブース予約でAmazonギフト1,500円分プレゼント!

Noetraと産総研、NEDO「AIロボット・フィジカルAIを見据えたマルチモーダル基盤モデル開発事業」に採択

NTT、LVLMの推論根拠を説明できるマルチモーダルXAI技術を確立。追加学習コストなしで運用可能
OpenAI、次世代AIモデル「GPT-5.6」シリーズの限定プレビュー開始。3種類のモデルを公開
AI製品・ソリューションの掲載を
希望される企業様はこちら