

Llama 4 とは?Meta 最新AIの3モデルの特徴や性能・安全性を徹底解説
最終更新日:2025/07/18
 Llama 4の特徴・性能・安全性解説
Llama 4の特徴・性能・安全性解説
2025年4月5日、Meta AI は最新AIモデル「Llama 4」を発表しました。ネイティブマルチモーダル対応とMoEアーキテクチャが採用された3種類のモデルが登場し、より高品質なユーザー体験が可能になりました。
本記事では、Llama 4の特徴や仕組み、競合他社のベンチマーク比較、安全性への対策などについて詳しく解説します。最新AIモデルがもたらす未来の可能性や影響についても触れていますので、ぜひご覧ください。
Llama 4 とは

Llama 4 とは、Meta AI社が2025年4月5日に公開した最新の大規模言語モデル(LLM)シリーズです。同社としては初のネイティブマルチモーダルモデルで、テキストや画像、動画、音声といった異なるデータ形式を統合的に処理できます。
シリーズには、後述する3種類のモデルがあり、それぞれで性能や応用範囲が異なります。現在Llama 4 は、Messenger や WhatsApp など同社のサービスに組み込まれている他、公式サイトや Hugging Face 上でモデルの重みデータが無償提供されています。
Llama 4 シリーズ 3つのモデル
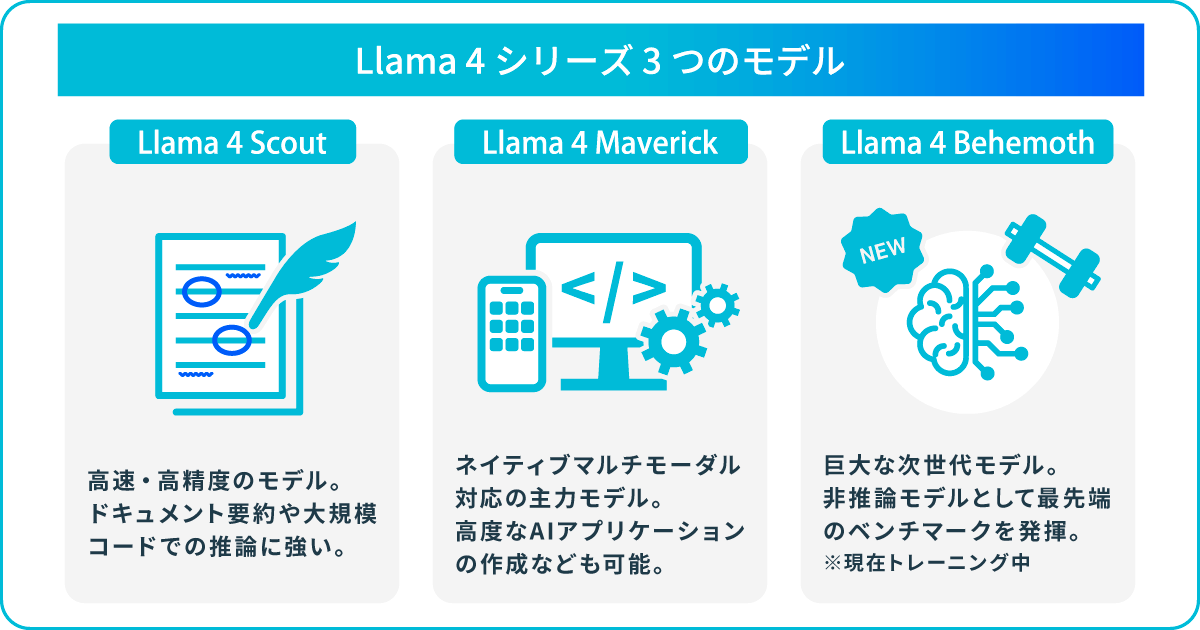
Llama 4 シリーズには、「Llama 4 Scout」「Llama 4 Maverick」「Llama 4 Behemoth」という3つのモデルがあり、それぞれで異なる性能や特性を持ち合わせています。ここでは、それぞれの特徴を紹介します。
Llama 4 Scout:強力かつ小規模なモデル
「Llama 4 Scout」は、3つのうち最も小規模でありながらも強力なモデルです。スペックの詳細は以下の通りです。
- 17B(170億)のアクティブパラメータ
- 16のエキスパート
- 合計109Bのパラメータ
- 1,000万トークンのコンテキスト長
NVIDIA H100 GPU(80GB)に収まるサイズでありながら、コンテキストウィンドウ(入力文脈長)は業界最長の1,000万トークンと膨大で、約20時間超の動画に相当する情報量を一度に処理できます。
また、256Kのコンテキスト長で学習されており、高度な長さの一般化機能が強化されています。複数ドキュメントの要約や大規模コードベースの推論といった用途で能力を発揮します。
Llama 4 Maverick:ネイティブマルチモーダル対応の主力モデル
「Llama 4 Maverick」は、シリーズの中核的な位置づけの大規模モデルです。一般的なLLMとして、Llama 3.3 70B よりも高品質かつ低コストなソリューションを提供できます。スペック詳細は以下の通りです。
- 17B(170億)のアクティブパラメータ
- 128のエキスパート
- 合計400B(4,000億)のパラメータ
- 100万トークンのコンテキスト長
画像とテキストの処理能力が高く、少ない計算リソースで業界トップクラスの性能を達成するよう設計されています。Scout 同様にマルチモーダル対応ですが、より大規模な専門家を採用することで複雑なタスクにも対応可能です。
高度な推論やコーディングに特化しており、ベンチマーク評価ではGPT-4 相当の性能を超える結果を示した点も見逃せません。クリエイティブライティングや画像理解といったシーンでの活躍が期待できます。
Llama 4 Behemoth:巨大な次世代モデル
「Llama 4 Behemoth」は、シリーズの最上位モデルとしてリリースされた次世代モデルで、現在も開発中です。一部の報道によると、現時点で報道されているモデルのスペックは以下の通りです。
- 288B(2,880億)のアクティブパラメータ
- 16のエキスパート
- 合計約2T(2兆)のパラメータ
特筆すべきは約2Tを超える巨大なパラメータ数で、現時点ではLLMの世界最高水準です。また、前述の Scout と Maverick の教師モデルとして設計されており、コディスティレーション手法(共蒸留)により小規模モデルへの知識伝達にも活用されます。
Llama 4 の主な特徴

Llama 4 の技術や仕組みを踏まえた主な特徴について解説します。
効率性の高いMoEアーキテクチャ
Llama 4 では、MoE(Mixture of Experts)アーキテクチャ方式を採用しています。MoEは、多数の専門家をサブモデルとして連携させ、ユーザーのクエリに応じて必要な専門家だけを稼働させる仕組みです。
Llama 4 Maverick では、総パラメータ約4,000億のうち、推論時に実際に使用されるアクティブパラメータは約170億に抑えられています。全パラメータをメモリに保持しつつ、活性化されるパラメータを限定することで、推論効率の向上とモデル提供コストの低減を実現しています。
iRoPEアーキテクチャによるコンテキスト処理の拡大
iRoPE アーキテクチャの導入により、1,000万トークンという前例のない長大なコンテキストが可能となりました。iRoPE(interleaved Rotary Position Embeddings)は、回転位置埋め込み(RoPE)をアテンション層と組み合わせることで、超文脈の推論性能を確立しています。
また、推論時にはアテンションの温度調整(スケーリング)を行い、極端に長い入力に対しても、安定した性能を維持できる点が特徴です。従来が分割が必要だった長大ドキュメントの解析や大規模コードベースの理解、複雑なストーリー生成などを一括処理できるようになりました。
優れたネイティブマルチモーダル能力
Llama 4 シリーズは、テキストだけでなく画像や動画など複数のデータ形式を統合的に処理できるネイティブマルチモーダル仕様です。前述したMoEアーキテクチャによって、各タスクに最適な専門家モデルだけを活性化するため、リソースを効率的に使いつつ高品質な出力を実現しています。
Llama 4 のマルチモーダル能力におけるポイントについて詳しく見ていきましょう。
視覚エンコーダ(MetaCLIP)の改良
Llama 4 では、視覚情報の処理に特化した MetaCLIP エンコーダを導入しています。エンコーダを別途訓練することで、LLMの文脈理解に適した形で視覚情報を橋渡しするよう設計されています。
その結果、画像キャプションの生成や画像に関する質問応答において、従来よりも高い精度と一貫性を実現することに成功しました。
テキストと画像の統合処理
視覚とテキストがシームレスに連携できるため、マルチモーダルタスク全般における性能が向上しています。関連性の高い複数の画像入力を、同時かつシームレスに処理できるようトレーニングされており、優れた推論能力を発揮します。
テキストトークンと視覚トークンを、同一のモデルバックボーン上で共同事前学習することで、膨大なデータに含まれる多様な特徴を一貫して取り込める仕様です。
新トレーニングMetaPの導入
Llama 4では、新たに「MetaP(Meta’s Progressive Pretraining)」という事前学習手法を導入し、モデルの学習困難性を解消しています。小規模モデルやシンプルなデータセットで安定的にトレーニングを開始し、段階的にモデルの深さや幅、学習トークン数を拡大していく方法です。
バッチサイズやモデルサイズが異なる環境でも、学習効率や初期化スケールが適切に引き継がれるため、高い性能が一貫して得られるようになっています。
Llama 4 ベンチマーク評価と他社モデルとの比較
Llama 4シリーズは多くのベンチマークテストにおいて、主要な競合モデルを上回る非常に高い性能を示しています。以下は、公式サイトで公開されているベンチマークスコアの比較表です。
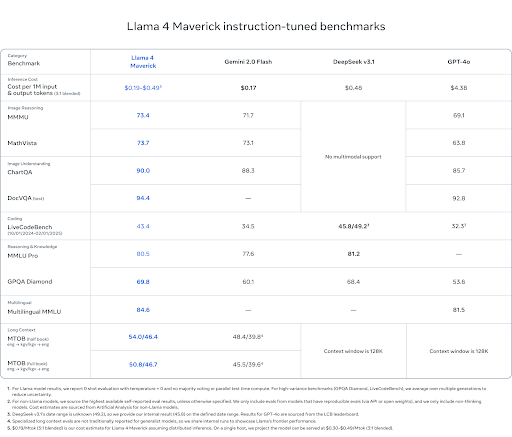
参照:Meta AI
評価全般において、Llama 4 Maverick は、Open AI の GPT-4o や Claude Sonnet 3.7、Gemini 2.0 Flash といった他社の最先端モデルを上回っています。また、Maverick は、アクティブパラメータを半分以下に抑えた状態でも、コーディングや推論タスクにおいて DeepSeek v3 と同等の結果を示しました。
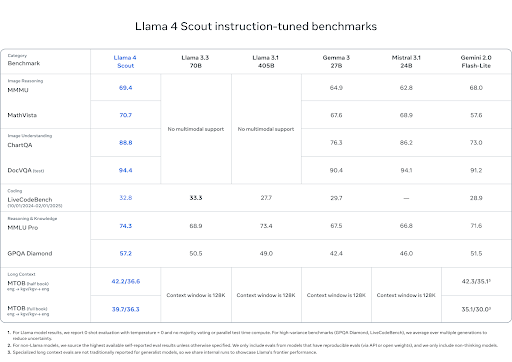
参照:Meta AI
また、Llama 4 Scout は、Gemini 2.0 Flash-Lite など同クラスの他社モデルを多くのベンチマークで上回っています。特に、論理的推論や複雑なプログラミング課題の処理、マルチリンガル能力で優れた結果を出しています。ただし、特定のコーディング用途でのスコアは控えめなため、用途に応じたモデル選択が必要です。
Llama 4 の使い方

Llama 4 Scout と Llama 4 Maverick は、主要なクラウドサービス上で利用可能です。手以下のプラットフォームでクラウド経由で試せます。
- Groq Cloudの無料トライアル
- together.ai、fireworks.ai などの有料サービス
Hugging Face で Pythonライブラリからインポートし、ローカルまたはクラウド上の推論環境で呼び出すこともできます。ローカル環境にダウンロードする場合、高性能なGPU環境が必要なため個人のパソコンで動かす際には注意が必要です。
メモリ・ハードウェアの要件
Llama 4 シリーズはモデルごとに必要なGPUリソースが異なります。各モデルの導入に必要とされる要件は以下の通りです。
Llama 4 Scout
- 80GBのVRAMを備えたNVIDIA H100 などを推奨
- INT4量子化を用いるとメモリ消費が約1/8に削減され、一般的なハイエンドGPU(RTX 4090 など)でも動作可能
Llama 4 Maverick
- 複数のH100を搭載したDGX相当のマルチGPU環境が必要
ローカル環境での Llama 4 導入を検討する際は、必要なGPU台数やVRAM量に加えて、リアルタイム推論やバッチ処理などモデルの利用形態も考慮し、最適な構成を選択することが重要です。
Llama 4 の安全性
Meta AIは、誰でも手軽に利用できる最新モデルを開発しながらも、深刻なリスクやAIが抱える課題への対策にも注力しています。ここでは、Llama 4 のリスクヘッジと安全性の確保について解説します。
セーフガード
Llama 4 では、開発者向けの利用ガイド(Developer Use Guide: AI Protections)に沿ったシステムレベルのセーフガードをオープンソース化しています。主なツールは以下の通りです。
- Llama Guard:ハザードタクソノミーに基づく入出力安全性検出モデル
- Prompt Guard:ジェイルブレイクやプロンプトインジェクションを分類・検知するモデル
- CyberSecEval:生成AIのサイバーセキュリティリスクを評価・軽減するフレームワーク
上記ツールを活用することで、有害な入力や出力を事前に検知・遮断し、より安全なAI運用が実現します。
トレーニングのミティゲーション
事前トレーニングの段階で、大規模データセットから有害なコンテンツや誤情報を排除するために高度なフィルタリングを実施しています。また、脆弱性のある領域において安全例を追加学習し、望ましくない出力を学習しないようにミティゲーションを徹底しています。
専門家がラベル付けした安全データを混合することで、初期学習の段階から不適切な出力を抑制するよう設計されており、学習データの偏りや有害情報の影響が最小限に抑えられています。
バイアス問題への取り組み
Llama 4 では、インターネット上の訓練データに起因する政治的・社会的バイアスを軽減して、中立的な応答を実現することを目指しています。実際に、議論の余地があるトピックへの応答拒否率や拒否するプロンプトの偏りの割合が低減したことが確認されました。
また、強い政治的傾向を示す応答の割合も、Llama 3.3 の半分程度まで改善されており、多様な視点をバランスよく表現できるモデルへと進化しています。
Llama 4 の今後の展望とAIの可能性
Llama 4は、オープンエコシステムの一環として、公式サイトやHugging Face、GitHub Models上でモデル重みと推論コードが無償提供されています。また、Azure AI FoundryやAzure Databricks などのクラウドプラットフォームでも利用可能です。
さらには、WhatsApp、MessengerなどにLlama 4搭載のAIアシスタント機能が組み込まれ、一般ユーザーが手軽に使える環境が整備されています。Meta AI は引き続き Llama モデルと製品の両方を研究し、プロトタイプを開発していく意向を示しています。
まとめ
Llama 4は、Meta AIによるオープンソース型AIの画期的なモデルです。MoEアーキテクチャとネイティブマルチモーダルを備えた同社初めてのモデルで、iRoPE技術による最大1,000万トークンという圧倒的な長文脈処理能力をはじめ多彩な高度技術が導入されています。
計算効率と推論速度が大幅に改善され、3タイプのうち、最もコンパクトな「Llama 4 Scout」でも従来のLlamaシリーズを凌駕する計算効率と推論速度を打ち出しています。Meta AI は、最新モデルの検証・改善とともに、安全性や倫理面でも厳格なセーフガードを実装し、より中立で安全なAI利用を推進しています。
アイスマイリーでは、生成AIサービス比較と企業一覧を無料配布しています。自社に最適な生成AIサービスの導入・運用に向けて、この機会にぜひご利用ください。
よくある質問
Llama 4 のライセンスは?
Llama 4 はオープンソースではありますが、いくつかの制限事項が定められています。Meta AI の公式ドキュメントによると、以下のようなチェック項目があります。
- 商用利用は原則として可能(使用や複製、配布、派生物の作成)
- 適用される法律・規制の遵守
- 月間アクティブユーザー7億人を超えている企業は許可が必要
- 利用の際には上記の項目についてよく確認しましょう。
Llama 4 に必要なスペックは?
Llama 4シリーズを適切に活用するためには、モデルに応じたスペックを準備する必要があります。各モデルごとのおおまかな環境要件は、以下の通りです。
- Llama 4 Scout:FP16の場合はNVIDIA H100 GPU(VRAM 80GB)1基を推奨。INT4量子化を用いることで、必要メモリが8~10GB程度まで削減されるため、RTX 4090 などハイエンドGPUでも運用可
- Llama 4 Maverick:複数のNVIDIA H100 GPU 推奨。INT4量子化を使用しても約200GB程度のVRAMが必要なため、マルチGPU構成が現実的
DXトレンドマガジン
メールマガジン登録
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。


AI・人工知能記事カテゴリ一覧
AI・人工知能サービス
- AIエージェント
- LLM
- AI研究開発
- ChatGPT
- 画像生成AI
- 生成AI
- RAG
- DX推進
- おすすめAI企業
- チャットボット
- ボイスボット
- 音声認識・翻訳・通訳
- 画像認識・画像解析
- 顔認証
- AI-OCR
- 外観検査
- 異常検知・予知保全
- 自然言語処理-NLP-
- 検索システム
- 感情認識・感情解析
- AIモデル作成
- 需要予測・ダイナミックプライシング
- AI人材育成・教育
- アノテーション
- AI学習データ作成
- エッジAI
- IoT
- JDLA
- G検定
- E資格
- PoC検証
- RPAツール
- Salesforce Einstein
- Watson(ワトソン)
- Web接客ツール
- サプライチェーン
- メタバース
- AR・VR・デジタルツイン
- MI
- スマートファクトリー
- データ活用・分析
- 機械学習
- ディープラーニング
- 強化学習
- テレワーク・リモートワーク
- マーケテイングオートメーション・MAツール
- マッチング
- レコメンド
- ロボット
- 予測
- 広告・クリエイティブ
- 営業支援・インサイドセールス
- 省人化
- 議事録自動作成
- 配送ルート最適化
- 非接触AI
業態業種別AI導入活用事例
今注目のカテゴリー
ChatGPT連携サービス

チャットボット

AI-OCR

生成AI
ChatGPT連携サービス
チャットボット
AI-OCR










FOLLOW US
SNSをフォローして、最新情報をチェックできます!

Sakana AI、初の商用プロダクトとなるビジネス向け自律型リ…

クラダシ「Claude」を全社展開。特有業務の自動化の推進および…

日米欧中韓の五大特許庁、東京で五庁長官会合を開催。AI分野の新た…
デンソーテン、独自の埋め込みモデル学習技術により車載エッジでRA…
TBSラジオ、AIで音声CMを生成する「デモCMジェネレーター」を公開。音声広告企画を支援

電通デジタル、OpenAIとdentsu Japanの戦略的連携に続き、ChatGPT広告のパイロット運用を開始

LINEヤフー、Agent iの機能拡大。画像生成機能やパーソナライズ機能を追加
Microsoft、「Copilot Cowork」一般提供を開始。「Claude Cowork」より平均30〜40%低コスト

Preferred Networks、国産生成AI基盤モデル「PLaMo 3.0 Prime」を正式提供開始。

Sakana AI、マルチエージェント基盤「Sakana Fugu」提供開始。一部ベンチマークで「Fable 5」「Mythos Preview」と同等性能
AI製品・ソリューションの掲載を
希望される企業様はこちら